



{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度属性学习的交通标志检测
[王方石1  , 王坚
, 王坚1 , 李兵2, 3 , 王博2, 3 ]
, 王坚, 王博|
|


作者简介:王方石(1969-),女,教授,博士. 研究方向:视觉信息处理.E-mail:fshwang@bjtu.edu.cn
为了弥补交通标志底层图像到高层语义之间的鸿沟,本文引入交通标志的形状、颜色、图案内容三种视觉属性,在卷积神经网络(Convolutional neural network, CNN)中加入属性学习(Attribute learning)约束,同时进行交通标志属性学习和分类学习,提出了一种基于深度属性学习的交通标志检测方法。并在公开数据集Sweden traffic sign detection dataset(STSD)和German traffic sign detection dataset(GTSD)上进行的实验结果表明,该方法能够有效地提高交通标志检测的准确率和召回率。
A traffic sign detection method based on deep attribute learning was proposed. To make up the gap between raw image and high level semantics, three visual attributes, including shape, color and pattern, were introduced. Attribute learning was added to train Convolutional Neural Network (CNN), where attribute learning and classification learning were carried out simultaneously. Experimental results on datasets Sweden Traffic Sign Detection Dataset (STSD) and German Traffic Sign Detection Dataset (GTSD) show that the proposed method can effectively improve the precision and recall in terms of traffic sign detection.
近年来, 高级驾驶辅助系统(Advanced driver assistance systems)和无人驾驶技术发展迅速, 其中, 交通标志的检测和识别是其重要组成部分[1]。常见的交通标志有速度限制、减速、停止、人行横道和车道限制等。无人驾驶车辆需要通过检测交通标志以获取前方道路状况信息, 才能减少事故发生的可能性, 增加驾驶的安全性。在现实环境中, 交通标志的检测是一个具有挑战性的任务。人类驾驶员可以很容易地找出并识别交通标志, 是因为交通标志的设计使用了颜色、形状和文本等语义性强、适合人类理解的元素的组合。但对于机器而言, 由于交通标志的种类多、类间区分度不大, 各个国家地区的交通标志不尽相同, 以及因光照、模糊、部分遮挡和背景复杂等因素, 使得难以从复杂场景中定位、准确识别交通标志区域[2, 3, 4, 5]。
本文利用交通标志中不受客观条件影响的共同特性, 设计并实现一个简单、通用和准确的交通标志的检测方法, 对于提高辅助驾驶和无人驾驶安全性具有重要意义。在充分挖掘交通标志牌表面特性和考虑交通标志图案视觉属性的基础上, 本文提出了一种在HSV颜色空间上提取最大稳定极值区域(MSER)以提取交通标志候选区域[1, 4, 5, 6, 7, 8]、利用加入了属性学习约束的卷积神经网络[9, 10, 11]识别交通标志区域的交通标志检测方法, 简记为MH-CAL(MSER on HSV & CNN with attribute learning)。
本文提出的MH-CAL方法的整体结构框架如图1所示。该方法主要流程如下:
(1)提取交通标志候选区域。在图像的HSV颜色空间的三个分量形成的灰度图上, 分别使用MSER提取交通标志候选区域;
(2)交通标志候选区域分类。使用加入了属性学习约束的卷积神经网络提取候选区域特征, 然后通过分类网络(共N+1个输出类, 包括交通标志N个类及非交通标志类)以判断候选区域是否是交通标志区域, 以及交通标志的类别。
(3)交通标志区域确定。在对交通标志区域分类后, 使用非极大抑制算法(Non-maximum suppression, NMS)从重叠候选区域中选出一个最合适的候选区域确定为最终交通标志区域。
需要说明的是, 属性约束网络旨在训练网络时, 其损失(Loss)与分类网络损失共同作用于反向传播过程以优化网络参数。而在测试时, 属性约束网络将被移除。
由于交通标志牌的色调一致、饱和度更高和比周围区域更亮[12, 13], 导致在HSV颜色空间的三个分量(色调Hue, 饱和度Saturation, 亮度Value)分别形成的三个灰度图上, 组成交通标志的图案内部灰度值相近, 且相较于其周围灰度值更高或更低, 而这正是连通域的特点。因此, 可以检测连通域以提取候选区域。为了增加鲁棒性, 本文提出同时在该三个灰度图上检测连通域以提取交通标志候选区域。
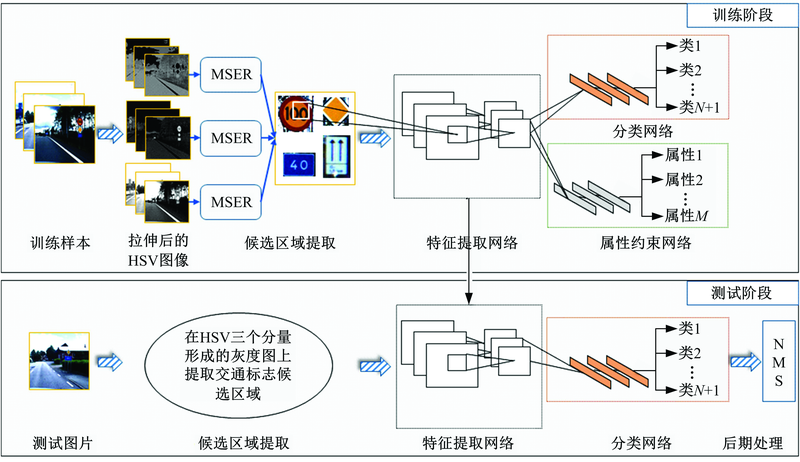 | 图1 本方法整体结构框架Fig.1 Overview of the proposed method |
最大稳定极值区域(MSER)[14]算法旨在检测灰度图中内部具有相近的灰度值、形状任意的区域。通过使用多个阈值将灰度图像二值化后, 提取每幅二值化图像中的连通域, 那些在多个二值化图像中形状基本保持不变的连通域即为MSER。因此, 本文提出在HSV颜色空间的三个分量形成的三个灰度图上, 利用MSER算法检测连通域以定位交通标志候选区域。
本文提出的候选区域提取算法如算法1所示。首先, 将图像IRGB从RBG颜色空间转换到HSV颜色空间得到图像IHSV; 接着, 为了得到图像IHSV的三个通道形成的灰度图IH、IS、IV, 需要对其三个通道分别使用线性对比度拉伸(Linear contrast stretching), 使三个通道像素值的取值范围处于相同的区间[0, 1]; 然后, 分别在灰度图IH、IS、IV上利用MSER检测连通域; 最后, 根据经验, 交通标志长宽比通常不会过大或过小, 所以过滤掉长宽比过大或者过小的连通域, 剩下的连通域对应原图中的区域作为交通标志候选区域, 由分类器识别这些候选区域。
可以看出, 上述方法在HSV颜色空间的三个分量上利用MSER检测连通域以提取交通标志候选区域。该方法并没有考虑标志的具体颜色种类和形状对称等先验信息, 因此方法简单且通用性强。
算法1 候选区域提取算法
Input:RGB图像IRGB, 长宽比阈值t1, t2, 满足t1> t2.
Output:交通标志候选区域框BboxROI.
1 begin
2 将图像IRGB由RBG颜色空间转换到HSV颜色空间得到图像IHSV, 设IHSV三个通道形成的图像分别为IH, IS, IV;
3 I1=IH/360; I2=IS/100; I3=IV/100;
4 ROI=∅;
5 for i=1, 2, 3 do
6 ROI=ROI∪ 在灰度图Ii上使用MSER检测到的连通域;
7 end
> 8 for each roi∈ ROI do
9 if Widthroi/Heightroi> t1 or Widthroi/Heightroi< t2
then ROI=ROI\roi;
10 end
11 获取ROI中的候选区域的位置信息, 保存至BboxROI;
12 end
在提取候选区域后, 需要对候选区域分类以判断候选区域是否是交通标志区域, 以及交通标志的类别。候选区域中通常包含了真实交通标志区域和非交通标志区域。真实交通标志区域通常会有一定的遮挡或形变; 非交通标志区域通常数量较多并且与真实的交通标志区域具有相似的表观特征。因此需要泛化能力强(Strong generalization ability)和容量大(Higher capacity)的分类器, 在准确识别真实交通标志区域的同时, 过滤非交通标志区域。
卷积神经网络由于能够进行特征学习, 且泛化能力强、容量大, 已经被证实是能够理解图片内容、在图像识别、分割、检测、检索上达到最好效果的一类有效的模型[15, 16, 17, 18, 19, 20]。其中, 作为卷积神经网络的一个典型, AlexNet在ImageNet 1000类目标分类任务上取得了当时最好的效果[15]。
然而, 简单的卷积神经网络(如AlexNet)只能学习目标类别这一高层语义信息。对于交通标志分类任务来说, 由于交通标志具有特定的形状、颜色和图案内容, 因此在训练卷积神经网络时, 可以加入这三种视觉属性约束以弥补底层图像到高层语义之前的鸿沟, 提升卷积神经网络的分类性能。故本文引入了交通标志形状、颜色和图案内容三种视觉属性, 并针对不同的交通标志数据集设计了不同的属性标签。如对于一个交通标志数据集D, 若组成交通标志的形状、颜色和图案内容各有
TD=(
本文设计的卷积神经网络的训练网络结构如图2所示。该网络由特征提取网络(AlexNet网络前五层, 包括卷积层、下采样层等)、分类网络、属性约束网络构成。其中, 分类网络和属性约束网络各由三层全连接层组成, 两者共享特征提取网络的输出(即图像的高层特征pool5)。该网络拥有两个损失, 一个是分类网络损失, 另一个是属性约束网络损失。在训练卷积神经网络时, 属性约束网络的损失将和分类网络的损失共同作用于反向传播过程以优化网络各层参数, 通过参数共享的方式同时进行属性学习和分类学习。
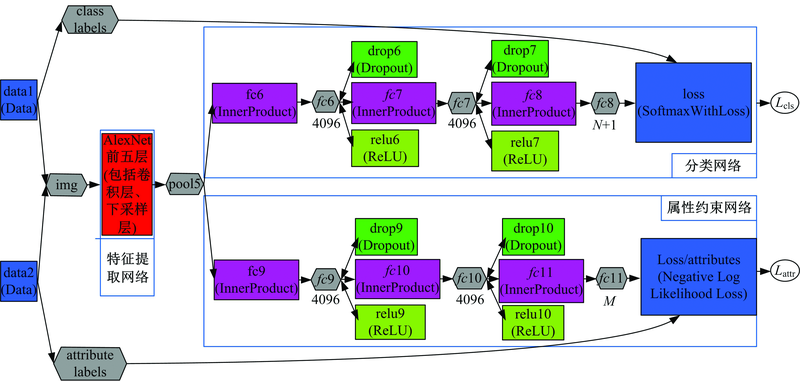 | 图2 本文设计的卷积神经网络的训练网络结构Fig.2 The proposed CNN structure for training |
训练网络时, 假设训练样本集D中共有m个样本、N+1个类别(交通标志N个类及非交通标志类)、M维属性标签。样本i的真实类别为y(i), 形状属性向量为
minL=min(Lcls+λ Lattr)(1)
Lcls=-
Lattr=-
其中, 分类网络的损失函数Lcls为Softmax损失函数, 属性约束网络的损失函数Lattr为负对数似然损失函数(Negative log-likelihood), 1{· }为指示函数, Rcls和Rattr为L2正则化项; p(i)=(
从该目标函数中可以看出, 在训练时, 该网络不仅考虑了交通标志类别信息, 同时也考虑了交通标志的形状、颜色、图案内容三种视觉属性信息, 如此训练后得到的卷积神经网络将具有属性约束特性, 能够有效弥补交通标识底层图像到高层语义之间的鸿沟。需要注意的是, 在测试时, 属性约束网络将被移除, 保留特征提取网络和分类网络, 进而直接得出输入图像的分类结果。
在提取交通标志候选区域过程中, 会出现同一个交通标志被检测出多个候选区域的情况, 且这些候选区域高度重叠。因此, 在对每个候选区域分类后, 需要从重叠的候选区域中, 选出一个最合适的候选区域确定为最终的交通标志区域, 去除其他的候选区域。
算法2 针对交通标志的NMS算法
Input:已分类的候选区域R, n是R中区域的数量, op是覆盖率阈值。
Output: 交通标志区域 Rpr。
Initialization: keep[1…n]=true, 表示R中的区域是否被保留。
1 begin
2 将R中区域按照区域面积降序排列。
3 将R中区域按照区域分类得分降序排列。
4 for i=1, …, n do
5 for j=i+1, …, n do
6 if overlap(R[i], R[j]) > op
then keep[j]=false;
7 end
8 end
9 Rpr=R[index(keep==true)];
10 end
本文根据每个候选区域的分类得分采用NMS算法确定最终的交通标志区域。即对于每个候选区域, 找出与其重叠且IoU覆盖率大于一定阈值的候选区域, 保留分类得分最高的候选区域, 去除其他候选区域。然而, 当两个候选区域处于包含关系时, 若两者的分类得分相同, 标准的NMS可能会保留被包含的区域, 去除包含的那个区域。但是对于交通标志来说, 经常出现同一个标志内, 有多个图案处于包含关系。限速标志70内部黄色区域外嵌套着红色的区域, 由于黄色区域和红色区域都是连通域, 因此两者覆盖的区域都会被选为交通标志候选区域。显然, 若这两个候选区域分类得分相同, 由于面积较大者(红色区域对应的候选区域)定位更加准确, 此时算法应该保留面积较大的候选区域, 去除面积较小的候选区域(黄色区域对应的候选区域), 然而, 标准的NMS可能会保留面积较小的候选区域, 去除面积较大的候选区域。为了解决该问题, 本文针对交通标志检测改进了NMS算法, 如算法2所示, 在标准的NMS的基础上, 对NMS的输入做了按照候选区域的面积递减排序的预处理。
本文在两个公开的数据集上对本文提出的交通标志检测方法进行了评测:STSD(Sweden traffic sign detection dataset)[21], GTSD(German traffic sign detection dataset)[22]。STSD中交通标志共有20个类别, 有20 000多张图片, 其中20%被人工标注, 共3488个交通标志; GTSD中交通标志共有43个类别, 有600张训练图片, 其中包含846个交通标志, 有300张测试图片, 其中包含了360个交通标志。
对于STSD, 本文按照文献[21]中的评测方法, 只考虑Pedestrian crossing、Designated lane right、No standing or parking、50 kph、Priority road和Give way 这6个类别。对于GTSD, 本文跟其他文献一样, 只评测43个类别所属的三个超类(Superclass), 即Mandatory、Danger和Prohibitory。
2.2.1 实验设计
本小节设计了6种提取交通标志候选区域的方法, 并在公开数据集STSD和GTSD上进行了评估。该实验旨在评估不同颜色空间对交通标志候选区域提取效果的影响, 该实验分别在6种颜色空间的分量形成的灰度图上提取MSER作为交通标志候选区域, 6种颜色空间分别为Ycbcr, RGB, YUV, Lab和HSV(本文选择的颜色空间), 以及文献[1]中提出的Enhanced RGB颜色空间, 该方法在RGB颜色空间中增强了R和B通道, 使得交通标志区域更加显著。
2.2.2 实验结果及分析
表1列出了在Ycbcr、RGB、YUV、Lab各自的三个通道上分别使用MSER提取候选区域、文献[1] 在Enhanced RBG颜色空间中的R、B两个通道上使用MSER提取候选区域和本文中提出的方法(HSV+MSER)的比较, 其中, 算法MSER中的参数Δ 取值为2。本小节实验采用平均召回率(Mean recall, MR)和文献[23]中提出的两个评价指标:MABO(Mean average best overlap)和#win。其中MR和MABO被定义为:
MR=
MABO=
ABOc=
其中, C表示所有交通标志类别, Gc表示第c个类别中所有真实的标注区域,
| 表1 不同候选区域提取方法在STSD、GTSD数据集上的实验结果 Table 1 Experimental results on dataset STSD and GTSD using different methods to extract candidate regions |
从表1中可以看出:
(1)在不同的颜色空间上候选区域提取的效果差距明显。在指标MABO和MR上, 使用Ycbcr颜色空间提取候选区域效果最差, 在最常见的RGB颜色空间上效果也不理想。
(2)在指标MABO和MR上, 使用YUV颜色空间的效果与本文较为接近, 原因是都利用了颜色的色调、饱和度和亮度信息; 在Lab颜色空间上的效果与本文的结果最近, 原因是该颜色空间以数字化方式来描述人的视觉感应, 能够表达的颜色更多, 因此能够更好地区分目标区域和背景。
(3)在公开库STSD上, 在不利用对称信息的情况下, 在指标MABO上, 本文提出的方法比文献[1]高出约0.15, 比其他方法高出0.02~0.19; 在指标MR上, 本文比文献[1]上高出约0.22, 比其他方法高出0.02~0.23。
(4)在公开库GTSD上, 使用文献[1]中的方法提取候选区域具有最高的MR=1, 略高于本文提出的方法, 但是在指标MABO上比本文低; 在Lab颜色空间上的MABO和MR的值仅次于文献[1]和文本提出的方法; 相比较其他颜色空间, 本文在指标MABO上高出0.10~0.12, 在指标MR上高出0.14~0.22。
(5)在指标#win上, 本文提出的方法高于其他方法, 这会导致在候选区域分类过程中在速度上不占优势。
从在两个公开库上的比较可以看出, 使用HSV、Lab颜色空间提取交通标志候选区域具有较好的效果。使用HSV颜色空间平均覆盖率和平均召回率较高, 使用Lab颜色空间由于#win较小, 故检测算法整体速度更快。因此, 从实验对比可知, 色调、对比度和亮度信息是提取交通标志候选区域的重要信息。本文提出的方法正是利用了上述重要信息, 即在HSV颜色空间的三个通道形成的灰度图上使用MSER算法检测标志候选区域, 才能具有较高的平均覆盖率和平均召回率, 即交通标志定位更准和找到的交通标志更多。由在不同的库上实验对比得出, 本文提出的交通标志候选区域的方法效果最好; 然而, 本文提出的方法在每张图片平均候选区域数量上相比较其他方法略高。
2.3.1 实验设计
在STSD数据集上, 本文对比了4种检测算法, 分别为文献[21]提出的使用傅里叶描述子描述交通标志的轮廓并分类的方法、文献[8]提出的方法、本文提出的MH-CAL方法和本文提出的去除属性约束网络的方法MH-CNN。
在GTSD数据集上, 本文对比了6种检测算法, 分别为文献[22]提出的HOG特征结合颜色直方图(Color Histogram)特征描述交通标志候选区域并用SVM对候选区域分类的方法、文献[24]使用ChannelFeature检测子的检测方法、文献[1]、文献[8]提出的方法、本文提出的方法MH-CAL以及本文提出的方法去除属性约束网络的方法MH-CNN。
2.3.2 属性标签设计
本文在充分观察、总结数据集STSD和BTSD中交通标志图案的特点后, 分别为STSD和BTSD设计了属性标签, 表2列出了在STSD数据集上需要评测的6个交通标志类别和背景类别的属性标签和属性向量, 表3列出了在GTSD数据集上需要评测的3个超类和背景类别的属性标签和属性向量。本文从标志整体形状、标志颜色、标志图案内容这三个方面对属性进行了划分, 各类交通标志如果含有某项属性, 则该属性标签值置为1, 否则置为0。由于GTSD数据集上只需评测3个超类, 而不是具体交通标志类别, 因此只需使用形状和颜色这两个方面设计属性标签。最后, 每个交通标志类(或超类)会生成一个唯一的属性向量, 在训练卷积神经网络时, 与类别信息共同作为训练目标。
| 表2 数据集STSD的属性标签和属性向量 Table 2 Attribute labels and attribute vectors for dataset STSD |
| 表3 数据集GTSD的属性标签和属性向量 Table 3 Attribute labels and attribute vectors for dataset GTSD |
2.3.3 训练过程
由于两个公开数据集数据量不足, 因此本文中卷积神经网络的训练采用基于归纳式迁移学习(Inductive transfer learning)的方法。本文使用在数据集ImageNet上训练好的Alex网络模型作为预训练模型(Pre-trained model), 使用交通标志样本对网络进行有监督的微调(Supervised fine-tuning)。在训练时, 特征提取网络和分类网络使用预训练模型中的参数, 属性约束网络中的参数使用随机初始化参数。
由于现有的交通标志数据集训练样本并不充足, 为了获取更多的训练样本, 本文采取以下方法。
首先, 将样本库中的所有图像按顺时针和逆时针方向各旋转5度形成新的训练集; 然后, 在新的训练集上提取交通标志候选区域, 根据经验知识, 交通标志的长宽比不会过大, 因此, 本文只保留长宽比(w/h)满足1/3.5≤ w/h≤ 1.4的候选区域; 最后, 将与真实区域IoU覆盖率大于0.7的候选区域作为交通标志样本, 覆盖率小于0.3的候选区域作为非交通标志样本, 其他的候选区域不作为训练样本。本文使用随机梯度下降法以0.001的学习率(Learning rate)开始训练网络。
在增加交通标志样本的同时, 也增加了大量非交通标志的样本。非交通标志样本和交通标志样本的比例大约为400∶ 1。为了处理数据不均衡的问题, 在训练模型时, 本文采用如下训练方法:首先, 从非交通标志样本中随机挑选4000个样本和所有的交通标志样本作为训练集Strain, 训练模型M; 然后, 用Strain训练好的模型M测试Strain中所有非交通标志样本, 将分错的非交通标志样本随机选取10%加入到Strain中, 重新训练模型M; 以此类推, 重复几次, 直到非交通标志样本的误检率降低到目标值。
2.3.4 实验结果及分析
在STSD数据集上, 本文按照文献[21]中要求, 只考虑20个交通标志类别中的6个类别:Pedestrian crossing、Designated lane right、No standing or parking、50 km/h、Priority road和Give way, 使用准确率(Precision)和召回率(Recall)评价方法。表4是在STSD公开数据集上与文献[8, 21]中的结果的对比, 其中MH-CAL是本文提出的方法, MH-CNN指本文提出的方法去除属性约束网络后的方法。
| 表4 STSD数据集上的实验对比 Table 4 Comparison of experiments on dataset STSD |
(1)在准确率方面, 在每一个类别上, 本文提出的检测方法都优于文献[21]和文献[8]中提出的方法, 尤其是在类别Give way上, 较文献[8]提升了25.92%, 较文献[21]提升了38.16%, 这有赖于卷积神经网络提取的有效特征;
(2)在召回率方面, 对于类别No standing or parking、50 km/h、Priority road、Give way, 本文提出的方法超过了文献[8]4%~34%, 尤其是在50 km· h-1和具有挑战性的Give way这两个类别上有了大幅提升, 说明本文提出的候选区域提取方法能够更好地定位交通标志区域。
(3)在类别Designated lane right上, 本文在召回率上稍落后于文献[8]的方法; 对于类别Pedestrian crossing, 本文的方法在召回率上较低, 原因是其内部图案较为复杂, 当该标志在图片中较小时, 标志表面的连通域不够大, 导致在候选区域提取步骤中无法提取到该区域。如图3所示, 黑方框标出的是本文提出的算法提取出的候选区域, 可以看到, 整个交通标志区域没有被提取出来。
 | 图3 未检测到整个Pedestrian crossing区域Fig.3 Fail to detect the whole area of Pedestrian crossing |
(4)较MH-CNN方法, 在加入属性学习约束后, 准确率和召回率都有所提升, 说明本文提出的属性学习约束方法确实有效。使用卷积神经网络的MH-CNN方法在准确率和召回率上普遍优于使用传统分类器的方法[8, 21], 说明在交通标志分类任务上, 深度学习方法要优于传统学习方法。
(5)整体来看, 在平均准确率和平均召回率上, 较文献[8]分别提高了4.77%和9.88%, 较文献[21]分别提高了7.94%和13.73%。
同时, 本文也在GTSD数据集上用了同样的方法和参数对本文提出的检测方法和其他文献中的方法做了对比, 在该库上, 本文和其他文章一样, 只评测43个类别所属的三个超类:Mandatory、Danger、Prohibitory。在这个公开数据集上训练时, 也是采用归纳式迁移学习的方法, 与STSD不同的是, 在GTSD上用的预训练模型是在STSD数据集上训练好的模型。表5使用了AUC(Area Under PR Curve)评价标准在GTSD上对比了不同的检测方法。从表中可以看出, 本文提出的算法在类别Danger、Prohibitory上优于文献[1]和文献[22]中提出的方法, 与文献[24]和文献[8]中提出的方法持平; 在类别Mandatory上也取得了较高的结果。
| 表5 GTSD数据集上的实验对比 Table 5 Comparison of experiments on dataset GTSD |
从上述两个实验可以看出, 本文提出的交通标志检测方法都取得了较高的召回率, 说明了在HSV颜色空间上提取交通标志候选区域的有效性, 由此可知, 色调、对比度和亮度信息是提取交通标志候选区域的重要信息; 本文提出的方法也取得了较高的准确率, 说明卷积神经网络相比于传统分类器, 泛化能力更强、容量更大; 在加入属性学习约束后, 准确率和召回率都得到了提升, 说明本文提出的属性学习约束学习确实有效。然而, 本文提出的方法有一定的不足, 当交通标志表面图案较为复杂、元素较多时, 如图4所示, 候选区域提取的性能会有一定的损失。
 | 图4 本文提出的交通标志检测方法检测效果示例Fig.4 Samples of the proposed traffic sign detection method |
现有的大部分交通标志检测方法都没有考虑交通标志牌表面的特性和交通标志图案的视觉属性。本文提出了一种基于深度属性学习的交通标志检测方法。该方法首先在HSV颜色空间上使用MSER提取交通标志候选区域; 然后使用加入了属性学习约束的卷积神经网络提取候选区域特征并识别。本文方法不但充分利用了交通标志牌表面不同颜色的共同特性、制作材料的特殊性, 而且将交通标志的形状、颜色、图案内容等一系列视觉属性作为约束条件融入到了分类器中。通过在两个公开数据集上的实验证明, 本方法不但能够在复杂环境下准确定位交通标志区域, 而且能够准确地识别交通标志区域和过滤非交通标志区域。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|