

{kind=link}
{kind=link}
跟踪-学习-检测框架下改进加速梯度的目标跟踪
[杨欣1, 2  , 夏斯军
, 夏斯军1 , 刘冬雪1 , 费树岷3 , 胡银记2 ]
, 夏斯军|
|


作者简介:杨欣(1978-),男,副教授,博士. 研究方向:模式识别,图像处理. E-mail:yangxin@nuaa.edu.cn
单目标持久跟踪的主要难点是由于目标姿态、相似背景及遮挡等因素而导致的漂移问题。基于此提出了一种改进L1APG (L1 tracker using accelerated proximal gradient approach) 的目标-学习-检测(TLD)目标跟踪算法。首先,在L1APG跟踪器中加入遮挡检测判断;其次,将遮挡程度转换为目标模板和背景模板系数的权重;最后,用改进的L1APG跟踪器取代传统TLD框架中的跟踪器,自适应地根据遮挡程度改变模板系数,从而有效地提高了跟踪效果。实验表明:本文算法与传统TLD跟踪框架相比,能更好地处理遮挡和漂移问题,具有较好的稳定性和鲁棒性。
The main challenges in a single target persistent tracking are the factors such as the change of the target pose, similar background and occlusion, which account for the difficulty in solving the drift problem. Based on Tracking-Learning-Detection (TLD), we propose an improved Li Tracker Using Accelerated Proximal Gradient Approach (L1APG) tracking algorithm. First, we add occlusion detection to the L1APG tracker. Then, we transform the occlusion problem into the weight of the target template and the background template coefficients. Finally, the original tracker is replaced by the improved L1APG tracker in the traditional TLD algorithm, the coefficient weights vary adaptively according to the degree of occlusion in real time, which contributes to improving the tracking results effectively. Experiments show that, compared with TLD and L1 tracking algorithms, the proposed algorithm can better deal with the occlusion and drift problems and possesses better stability and robustness.
视频目标跟踪作为计算机视觉研究领域中的一个关键技术, 已广泛应用到国防和民用的各个领域中, 如智能监控、导航制导、医学诊断、人机交互等。同时视频跟踪在实际的应用中面临着多种问题, 比如:跟踪对象的角度、姿态发生改变以及被遮挡等情况, 而长时间目标跟踪更是一个富有挑战性的工作。传统的跟踪方法可分为两类:基于跟踪器的跟踪算法和基于检测器的跟踪算法, 前者主要在于目标特征的选取, 代表性的特征包括目标的质点[1]、目标的轮廓[2, 3, 4]、链式模型[5]和光流[6]。此类方法都是假设目标始终可见, 一旦目标消失就会导致跟踪失败。同样, 检测跟踪方法通常都是基于局部图像特征或者滑动窗口, 对每一帧单独处理检测出目标位置, 此类方法需要离线的学习过程, 并且检测器的性能与学习样本多样性直接相关, 因此基于检测的跟踪算法难以有效地解决过拟合问题。在此背景下, 研究者提出了大量的解决方案, 例如:Mean-shift[7, 8, 9]、粒子滤波[10, 11]、L1跟踪器[12]、视觉显著性特征[13, 14]、实时压缩感知跟踪 (Real-time compressive tracking)[15]。这些算法虽然能较好地实现对无遮挡目标的跟踪, 但无法有效地解决跟踪过程中的遮挡和相似背景及目标姿态变化问题, 或者对全部遮挡效果不理想, 因此无法实现持久的跟踪。多特征融合粒子滤波算法[16, 17]对目标遮挡以及背景混淆等诸多问题具有较高的鲁棒性, 但当视频序列的尺寸较大或者背景较复杂需要数量较多的粒子时, 算法处理的时间较长, 会导致实时性变差。为实现持久的目标跟踪, Kalal等[18]提出了一种新的TLD (Tracking-learning-detection)跟踪算法, 采用跟踪器与检测器并行处理的框架, 并通过学习模块不断更新检测器相应参数值, 最终由整合模块输出跟踪结果。如过跟踪器跟踪失败, 由检测器修正跟踪器的目标模型[19]。该方法能有效地实现对目标的持久跟踪, 并能在一定程度上克服目标姿态变化问题。但当遮挡前景与跟踪目标灰度特征相似时, 会导致跟踪出现偏差, 尤其当相似干扰与跟踪目标交叉运动时, 会出现漂移现象, 无法再次跟踪到初始目标, 导致跟踪失败。
根据上述分析, 本文提出了一种改进的TLD目标跟踪算法, 用改进L1APG(L1 tracker using accelerated proximal gradient approach)[20]跟踪器来取代传统TLD算法中基于光流法的跟踪器, 同时加入遮挡检测判断, 设定遮挡阈值, 并根据遮挡程度实时更新目标模板和背景模板系数权重, 进一步解决遮挡问题, 从而抑制漂移问题。
传统TLD算法中跟踪模块主要是用中值流跟踪算法[18], 中值流跟踪算法就是在光流法的基础上加了个限制, 一个“ 好” 的跟踪应具有正反连续性, 即无论是按照时间上的正序追踪还是反序追踪, 产生的轨迹应该是一样的。根据这个性质规定了任意一个追踪器的FB误差(Forward-backward error):从时间t的初始位置x(t)开始追踪产生时间t+p的位置x(t+p), 再从位置x(t+p)反向追踪产生时间t的预测位置x'(t), 初始位置和预测位置之间的欧氏距离就作为追踪器在t时间的FB误差。选取前、后两帧误差点较小的一半作为追踪点, 以此来估计目标运动位置, 一旦目标消失就会导致跟踪失败。检测器是将方差检测器、集成分类器和最近邻分类器采用级联的方式, 逐次通过每个检测器, 得到最终的目标。根据初始的目标模型, 对每一帧图像进行全面的扫描, 根据每个扫描框与目标的相识度来估计目标可能出现的位置。这种检测方法也会发生错误, 即错误地分类正、负样本。而学习模块中P-N学习主要对这两种错误(错误的正样本和错误的负样本)进行评估, 同时生产新的样本集来更新目标模型, 实现目标的实时更新, 并且对跟踪模块所选取的“ 关键点” (使用的光流法)进行更新, 避免再次出现类似的错误。综合模块主要就是拟合过程:比较跟踪器和检测器的结果, 选择置信度较大者或综合得到目标在下一帧最有可能出现的位置。
传统TLD算法跟踪器的置信度计算依赖于检测器, 因此最终跟踪结果受检测器的影响较大, 并且TLD算法在复杂背景下的跟踪效果较差, 处理遮挡的能力有待提高。
当目标在相对静止的背景中运动时, TLD算法跟踪效果较好。但当背景产生变化时会出现误判, 并且对于相似目标更是无法准确区别。此外, TLD方法对复杂条件下目标的跟踪处理能力不足, 而L1跟踪器由于具有静态原子, 对漂移有一定的抑制能力, 基于此本文对传统TLD进行改进, 采用改进的L1 APG跟踪器模块, 该模块能够快速地求解L1最小问题。并加入遮挡检测, 使其能够有效处理复杂情况, 增加算法的鲁棒性和实时性, 进而能够对目标进行持久跟踪。
候选目标的选择:假设在第t帧时, 目标所在的位置为xt, 对目标的预测的观测结果定义为y1:t-1={y1, y2, …, yt-1}, 可以用下面的两个公式来选取目标在下一帧中的位置:
p(xt|y1:t-1)=∫ p(xt|xt-1)p(xt-1|y1:t-1)dxt-1(1)
p(xt|y1:t)=
对于t帧的最佳目标位置, 近似于后验概率取最大值时:=argmaxxp(x|y1:t)。
目标模型的建立:建立目标模型是为了计算样本在下一时刻所在位置观察可能性p(yt|xt)。Tt=[, , …, ]∈ Rd× n(d≫n)表示t帧的目标模板; Qt={, , …, }表示采样的状态; Mt={, , …, }为目标模板空间相应的候补目标图像块集。可以得到稀疏表达模型:
式中:I为琐碎的模板集(单位矩阵), 表示遮挡和噪声; =[; ]为系数。同时, 对于非负约束有利于提高L1跟踪器的鲁棒性。因此, 对于每个候补的目标块, 其稀疏表达都可以通过求解下式的L1规范最小化得到:
式中:A=[Tt, I, -I]; β 为平衡因子。
通过观察, 可以得:
式中:
由于求解L1计算量比较大, 因此可以先计算出样本观测可能性, 然后根据可能性的大小对样本进行过滤, 舍弃可能性小的样本以此来减少计算量:
p(zt|)=exp{-α
p(zt|)≤ exp{-α
式中:α 为常量, 用来控制高斯核的形状; Γ 为常量; 为式(4)的最小值; zt为对t帧的预估; q(zt|)为样本的观测可能性上限, 并且当q(zt|)<
本文算法将跟踪过程分为如下两种情况:
(1)当没有遮挡时, 目标在下一帧中的状态应主要由目标模板的稀疏线性组合表示, 并且背景模板只占很小的一部分。
(2)当有遮挡时, 根据遮挡的程度增大或减小背景模板所占的比例。能够根据不同的情形来改变=[; ]各自所占的比重。而式(4)显然无法区分这两种情形, 因此将其改进为:
式中:A'=[Tt, I], a=[aT; aI]; ut为用来控制背景模板的权重。
为了更好地处理遮挡情况, 引入遮挡检测判断, 并且根据遮挡程度自适应调节稀疏矩阵系数, 具体如下:设稀疏系数=[; ], 对模板和背景系数分别进行转置可以得到
σ T=
σ I=
式中:m为常数, 表示无遮挡情况下的初始帧数, 通过实验来确定。
最终跟踪目标是由目标模板和背景模板的稀疏表达, 因此, 目标区域中任意像素点的灰度值可由目标模板与背景模板相应点的线性之和来表示, 改变两者系数值与改变其一皆可以达到同等的效果, 即:
式中:、、分别为第i帧图像预测目标、目标模板及背景模板中第p像素点的值(0~255), 对应于单个像素点=1, 并且的范围为(0~255)。改变权重的值, 能使式(12)(13)同时成立。因此, 只需改变背景模板的权重系数, 就能达到预期跟踪效果, 同时大幅度减少计算量, 进而有效提高运行速度。
在后面每一帧都计算相应的参数值, 与σ T、σ I进行比较, 当满足判断遮挡条件时, 更新稀疏表达式的参数所占权重:
(1)当i> m时, 分别计算, 。
(2)当< σ T& > σ I时:
式中:学习率λ 是个固定的参数, 本文算法设定为0.95, 该参数主要更新稀疏表达式中背景模板的比重, 通过线性叠加来更改最终跟踪目标模型, 使其能更好地处理遮挡情况。
本文算法的整体思路为:通过对跟踪器的有效改进, 同时检测器和跟踪器并行处理, 并且学习模块不断更新, 最终结果由综合模块对比输出。具体算法步骤如下:
Step1 设定初始图像中目标所在位置矩阵框参数[x, y, w, h]。
Step2 通过仿射变换, 在目标周围选取正负样本, 以此来初始化检测器相关参数, 并将目标模板保存起来。
Step3 检测是否有遮挡, 若有, 则更新跟踪器的参数ut(根据式(8)), 否则执行下一步。
Step4 用改进的L1APG跟踪器进行跟踪, 并对跟踪结果计算其置信度pt; 同时检测器并行处理, 得到目标在下一帧的位置及其置信度pd。
Step5 当pt> δ 1& pd> δ 2时(δ 1、δ 2分别是跟踪器和检测器设定的阈值, 初始值为0.5), 对比跟踪器和检测器的置信度, 当|pt-pd|> ε (ε 为设置参数, 初始值为0.4)时, 其较大者作为最终的跟踪结果。反之, 对其加权处理, 作为目标位置在下一帧的输出, 并调到步骤Step2。
对于部分遮挡情况, 用FaceOcc1作为测试图像序列, 观察图1(a)的跟踪结果:开始的几十帧图像跟踪效果相当, 但随后L1APG跟踪框发生畸变, 无法准确跟踪到目标。传统TLD在目标静止而遮挡运动时发生偏移现象, 但随后又恢复跟踪。在部分遮挡基础上加入目标姿态变化, 用FaceOcc2作为测试图像序列, L1APG用红色框表示, TLD用黄色框表示, 本文算法用蓝色框表示。从图1(b)中可以得出:L1APG在目标遮挡之后跟踪框发生畸变, 并且无法恢复, 导致跟踪失败。传统TLD算法在目标姿态发生变化及目标和背景较为相似时会导致跟踪失败, 直到目标姿态恢复到初始状态时, 检测器才能重新检测到目标。在目标遮挡及姿态变化的基础上, 加入快速运动这一因素来对比跟踪效果。用Football作为测试图像序列, 从图1(c)中可以得出:当有相似目标出现时, L1APG跟踪算法无法区分目标。传统的TLD算法随着目标与相似背景的交叉运动会发生偏移现象, 导致跟踪失败。而本文的算法在以上3种情况下都具有良好的稳定性和健壮性。
 | 图1 图像序列跟踪结果Fig.1 Image sequences tracking results |
定量分析实验将中心位置误差作为精度标准, 中心误差定义为跟踪目标的中心位置与标准目标位置的中心误差, 采用欧式距离进行比较。从图2的误差结果可以看出, 本文的算法在稳定性和健壮性上都要优于其他两种算法。
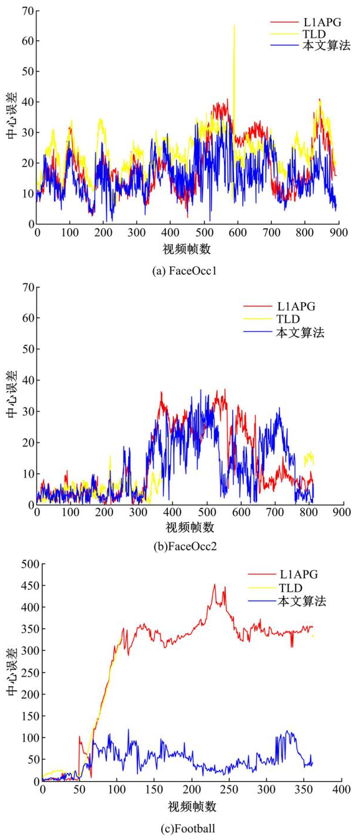 | 图2 误差结果图Fig.2 Error result diagrams |
提出了一种基于TLD框架的跟踪算法, 通过引入改进的L1APG跟踪器来替换传统TLD中的光流跟踪器。由于L1APG跟踪器具有静态模板, 并加入遮挡检测能自适应地更改系数权重, 以此来抑制漂移问题, 从而在目标遮挡、姿态变化以及快速运动的情况下能很好地跟踪目标, 提高了稳定性, 但实时性略低, 以后研究重点将是在保证准确率的基础上, 尽可能地减少粒子数量, 减小计算量, 提高实时性, 能更快速地跟踪目标。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|