
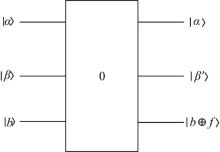
{kind=link}
{kind=link}
量子k-means算法
[刘雪娟 , 袁家斌, 许娟, 段博佳]
, 袁家斌, 许娟, 段博佳]
, 袁家斌, 许娟, 段博佳]
|
|


作者简介:刘雪娟(1980-),女,博士研究生.研究方向:量子计算, 数据挖掘.E-mail:liu_juanjuan80@126.com
为提高经典k-means算法的计算效率,引入量子计算理论得到量子k-means算法。先将聚类数据和 k个聚类中心制备成量子态,并行计算其相似度,接着利用相位估计算法将相似度信息保存到量子比特中,然后利用最小值查找量子算法查找最相似的聚类中心点。对比两种算法的复杂度可知,在一定条件下,相对经典算法而言,量子k-means算法的时间复杂度降低,空间复杂度得到指数级降低。
In this paper a quantum k-means algorithm is proposed by integrating the quantum paradigm to improve the efficiency of traditional k-means algorithm. First, each vector and k cluster centers are prepared to be in quantum superposition, which are then utilized to compute the similarities in parallel. Second, the quantum amplitude estimation algorithm is applied to convert the similarities into quantum bit. Finally, from the quantum bit the most similar center of the vector is obtained using the quantum algorithm for determining the minimum. Theoretical analysis shows that, compared with the traditional quantum algorithm, the time complexity of the quantum k-means algorithm decreases under given condition and the space complexity diminishes exponentially.
近年来, 越多越多的学者将量子计算应用于数据挖掘领域[1]。 Anguita等[2]提出利用Grover量子搜索算法[3]优化支持向量机SVM的训练过程用于解决SVM的训练效率问题。 Rebentrost等[4]提出量子SVM, 利用量子计算解决训练数据的内积计算, 即利用量子计算求解矩阵的偏迹得到训练数据的归一化核矩阵。Lu等[5]提出量子决策树算法, 利用量子态之间的保真度作为训练数据之间相似度的度量, 依此将训练集划分成子类, 并引入量子信息熵作为选择决策节点的依据建立量子决策树。阮越等[6]提出了量子PCA算法并用于人脸识别中, 用量子态表示人脸特征, 将Grover量子搜索算法用于人脸识别的过程达到二次加速的效果。徐永振等[7]提出基于一维三态离散量子游走的聚类算法, 将数据点看作游走粒子, 执行三态量子游走, 根据粒子的测量结果更新数据点的属性值并依此进行聚类。Elhaddad等[8]从并行计算和优化计算两个方面分别分析了量子计算对人工智能和数据挖掘领域所带来的影响。
聚类作为一种无监督的机器学习技术, 其依据给定的相似性度量将数据划分成若干个类, 使得同一类内的数据相似度较高, 而不同类间的数据相似度较低[9]。聚类算法被广泛应用于图像识别、社交网络、商业智能等领域中[10, 11]。k-means是一种经典的聚类算法, 被誉为数据挖掘领域的十大算法之一, 自提出以来就得到了广泛的应用[12, 13, 14]。然而大数据时代, 巨大的数据量为k-means聚类的速度带来了巨大的挑战, 利用基于云计算的大规模集群进行并行聚类成了较为普遍的应对策略; 但是大规模集群所产生的巨大的能量消耗问题又带来新的挑战[15, 16]。而量子计算不但具有超强的并行计算能力, 又因计算的可逆性使其不会面临能量消耗的问题, 故已有学者研究利用量子计算的相关理论对k-means算法进行聚类加速。因量子态之间的信息保真度与传统相似度度量中的余弦相似度相似, Aï meur 等[17]提出利用量子信息保真度代替k-means算法中数据之间的相似度量, 并利用受控交换门Control-Swap计算量子信息保真度, 但k-means算法的其他步骤并没有引入量子计算。随后Aï meur等[18, 19]又提出了利用Grover算法的扩展算法量子最小值查找算法作为一个量子子程序去加速经典k-means算法中的一个步骤, 但算法的计算复杂度并没有降低。k-means算法对初始聚类中心的选择比较敏感, 不同的聚类中心其聚类效果可能不同, 故Lloyd等[20]提出利用量子绝热算法选择合适的初始聚类中心点后, 再利用k-means算法进行聚类, 聚类的计算过程中并未引入量子计算。
综上所述, 有关量子计算与k-means算法相结合的工作中, 大多是利用量子计算对算法中的某一个步骤进行了加速, 但是算法整体的计算复杂度并未降低。本文给出的量子k-means算法将对聚类的主要步骤进行加速, 使算法整体计算复杂度得到降低。
给定数据集X=
(1)随机从数据集X中选取k条记录作为初始聚类中心c。
(2)对每一数据点xi, 计算其到k个聚类中心的相似度。
(3)将数据点xi归于相似度最大的那个聚类中心所属的类。
(4)数据集中的所有数据经过步骤(2)(3)计算后, 根据数据集的类别标号重新计算新的聚类中心。
(5)判断是否达到聚类结束的条件, 若达到, 聚类结束; 否则回到步骤(1)。
k-means算法的主要聚类步骤和计算量集中在第(2)(3)步, 即对每个数据点计算其到k个聚类中心的相似度, 并将其归于相似度最大的聚类中心所属的类别。
量子k-means算法将量子计算的相关理论引入到聚类的主要步骤, 主要分成3个阶段完成该步骤的任务:第一, 先将待聚类的数据点和k个聚类中心点制备成量子态; 第二, 利用受控交换门Control-Swap计算任一数据点xi和k个聚类中心c=
k-means算法中需要计算每一个数据点与k个聚类中心的相似度, 所以需要将其制备成量子态。量子态制备之前先将所有的数据进行归一化处理。假设任一聚类数据点xi用具有d个特征值的向量来表示, 以待聚类的数据点x0为例, 将数据点x0制备成如式(1)所示的量子态:
|x0> =
式中:x0j为第0个数据点的第j个特征值。
将k个聚类中心c=
|c> =
式中:cij表示第i个聚类中心点的第j个特征值。
设2m=k, 2n=d, 量子态|c> 的制备过程如下:
(1)初始输入为|0> m|0> n|1> |0> , 利用H门得到量子态:
(2)将量子黑箱Oracle作用到式(3)上得到:
量子黑箱Oracle定义为:
|i> |j> |1> → |i> |j> |cij>
(3)利用一个绕Y轴旋转的酉操作Ry
|c> =
(4)利用第(2)步的量子黑箱Oracle的逆操作清除式(5)中的|cij> , 得到如式(2)所示的量子态|c> 。
利用同样的方法制备如式(1)所示的量子态|x0> 。 由上述量子态的制备过程可以得到, 制备量子态|c> 需要3次Oracle操作, 制备|x0> 与|c0> 则需要6次Oracle操作。
计算量子态|x0> 与|c> 的相似度, 并利用相位估计算法将相似度存储在量子比特中。对于相似度的计算, 仍然采用文献[17]中的方法:即采用控制交换门Control-Swap计算量子态之间的保真度用于估计相似度。
用于计算量子态|x0> 与|c> 相似度的控制交换门Control-Swap如图1所示, 输入的第1个量子比特位经过一个H门后用作控制位, 当其为1时实现交换操作。计算的过程如下:
(1)|0> |x0> |c> ∥ 初态。
(2)→ (|0> +|1> )|x0> |c> ∥ 应用H门
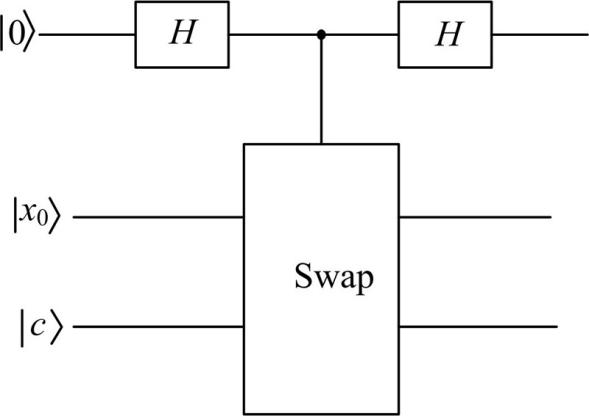 | 图1 控制交换门Fig.1 Control-Swap gate |
到第一寄存器。
(3)→ (|0> |x0> |c> +|1> |c> |x0> )∥执行交换操作。
(4)→ |0> (|x0> |c> +|c> |x0> )+|1> (|c> |x0> -|x0> |c> ) ∥再次应用H门。
由此得到控制交换门的输出结果为:
|ψ > =|0> (|x0> |c> +|c> |x0> )+|1> (|x0> |c> -|c> |x0> ) (6)
设测量算子M1=|1> < 1|, 并且有M1=|1> < 1|, 则:
p=< ψ ||ψ > =< ψ ||ψ > =
由p可以得到第一位量子比特为1的概率为
φ =
接下来将相位估计算法作用在φ 上, 使相似度信息存储在量子比特上[21]。相位估计算法用于求解给定向量的相位, 其实现原理主要是基于量子Fourier变换技术。量子Fourier主要是实现如下形式的变换:
将量子态φ 作为相位估计算法的输入, 可以得到:
α =
由此可将ci与x0之间的相似度存储于量子比特|
量子态α 中保存的k个
利用量子最小值查找算法从量子态α 中查找最小值的步骤如下:首先随机选取一个聚类中心cj作为初始值, 然后重复以下步骤次:
(1)制备初始值cj的量子态为β 。
(2)α 、β 作为输入, b作为控制输入, 利用Grover算法查找到。
(3)若
相应的量子搜索算法模型如图2所示。 此时找到的 cj为与x0最近的聚类中心点, 将x0归于cj所属的类别。
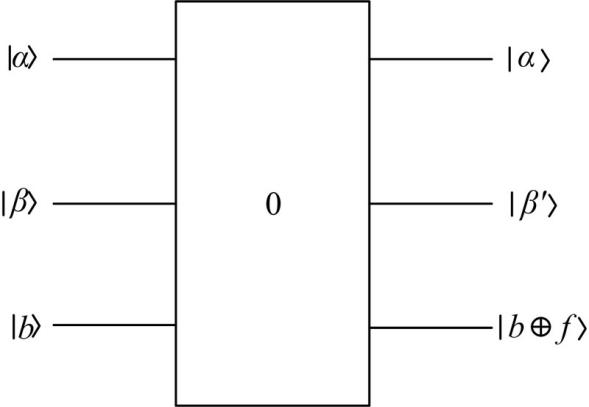 | 图2 查找最相似的聚类中心Fig.2 Find the maximum of similarity to cluster center |
两种算法的时间复杂度和空间复杂度对比结果如表1所示。
| 表1 两种算法的复杂度比较 Table 1 Comparison of complexity of two algorithms |
经典k-means算法中的主要计算步骤为第(2)(3)步。其中第(2)步, 即对于每一个具有d个特征值的数据点xi, 都要计算其与k个聚类中心的相似度, 该步计算的时间复杂度为O。算法第(3)步是从k个相似度中查找最大值, 其时间复杂度为O(k), 文献[23, 24]主要是对该步骤利用量子搜索算法对其加速, 使该步骤的时间复杂度降到O, 但是该步骤的加速并不会使整个算法的时间复杂度提高。对于数据规模为n需要迭代t次的聚类过程, 经典k-means算法的时间复杂度为O(tnkd)。
本文提出的量子k-means算法, 将被聚类的每一个数据点xi与k个聚类中心制备成相应的量子叠加态, 需要的Oracle操作次数为6次。由于量子计算其内生的计算并行性, 则对于每一个数据点xi, 利用控制交换门计算其与k个聚类中心的相似度, 只需要一步计算即可得到。得到的相似度只是作为一个中间值, 并不会对其直接测量, 而是利用相位估计算法将其存储于量子比特中, 该步的结果被直接用于查找与xi相似度最大的聚类中心点。相位估计算法需要的Oracle操作次数为常数R', 查找最相似的聚类中心需要的时间复杂度为O。设6+R'=R, 则量子k-means算法主要步骤的计算复杂度为O, 整个量子k-means算法的时间复杂度为O
在经典k-means算法中, 对于任意数据点xi, 假设一个特征值需要占据一个字节的内存空间, 则xi需要的内存空间为d字节; 由于要计算其与k个聚类中心的距离, 那么其需要的内存应该为(k+1)d字节=8d比特。而对于量子k-means算法, 任一数据点xi的量子态所需要的内存为
本文在k-means算法的主要步骤中引入量子计算相关理论, 得到k-means算法的量子化版本。首先给出了任一聚类数据xi和k个聚类中心的量子态制备过程, 然后给出了xi和这k个聚类中心距离的相似度计算过程, 并利用相位估计算法将相似度转换成量子比特, 最后, 利用最小值查找量子算法查找出最相似的聚类中心点并将其归于所属的类别。 对两种算法的时间复杂度进行理论分析和比较可以得到, 在k和d比较大的情况下, 量子k-means算法相对经典算法的时间复杂度得到降低, 且k和d越大, 这种效果越明显; 而量子k-means的空间复杂度相对经典算法则可以达到指数级降低。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|