

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于最大互信息系数的信息推送模型构建
[谭泗桥1, 2  , 张席
, 张席2, 3 , 李钎2 , 艾陈4 ]
, 张席]
|
|


作者简介:谭泗桥(1974-),男,副教授,博士. 研究方向:模式识别及预测. E-mail:tsq@hunau.edu.cn
针对目标用户近邻集合选择失准的问题,引入可普适性测度非线性关系的关联指标——最大互信息系数(MIC),并以此测度用户间的相似程度。基于某一给定的阈值,为目标用户选择近邻集合,然后以近邻集合作为训练集,构建支持向量机个性化预测模型,对目标用户的感兴趣项目进行打分预测。仿真结果表明,MIC测度较Pearson等测度选择的近邻集合更为准确,并具有对阈值不敏感的优点。
The correlation indicator, Maximum Information Coefficient (MIF), which can pervasively measure the nonlinear relationship, is introduced to solve the problem of inaccurate selection of the near-neighbor set of the target users. The indicator is employed to measure the similarity between users. First, the near-neighbor set target users is selected based on a given threshold. Then, the personalized SVM prediction model is built with the attained near-neighbor set as the training set to carried out scoring prediction for the interesting items of the target users. Simulation results show that the near-neighbor set selected by the MIF Measuring is more accurate than that selected by the Pearson Measuring, and has the merit of insensitive to the threshold.
基于内容的推荐系统与基于协同过滤的推荐系统是信息推送服务的两种主要形式。协同过滤系统推荐过程简单, 可提供个性化搜索服务, 较前者应用更广泛。协同过滤推荐系统一般包括两个主要步骤:①基于用户已评分项目计算用户间的相似性系数, 并以相似性最大原则筛选目标用户的近邻集合(用户偏好相似); ②基于邻居集合的已评分项目为目标用户筛选潜在的推送信息。因此, 对于协同过滤推荐系统, 选择信息完善的近邻集合是保证推荐信息的整体质量的关键点, 若获得的最近邻集合信息不完整, 则后续预测得到的感兴趣信息错误概率会显著增加, 导致信息推荐失败。在传统协同过滤推荐系统中, 与目标用户相似性最高的K个用户可入选近邻集合[1], 但均采用Pearson相关系数、cosine相似性和均方差相似性等线性相似性测度, 存在无法呈现用户间复杂非线性关系的缺陷, 筛选出的近邻集合信息不完整, 导致推荐准确度不高。
本文引入最大互信息系数(MIC)[2]作为用户之间的相似性测度。MIC测度来源于信息论中的互信息测度, MIC经不等间隔寻优以矫正, 具有能普适性检测复杂非线性关系以及等价性的优点。基于MIC测度所选近邻集合具有信息更完整、准确的优点。本文以开源MovieLens评分数据集为仿真数据[3], 以多种相似性测度为参比方法, 结果表明, 基于MIC的非线性方法能有效提高评分预测精度。
关联分析一般指基于某种相关性测度, 评价两个变量间的相似程度, 测度得分值越大, 表示两个变量关联程度越大[4]。
关联测度的优劣可采用普适性[5]和等价性[2]两个指标来度量。普适性表示该测度方法所能检测到的函数关系的类型数量, 检测到的函数关系预测越多, 其普适性越好。如Pearson相关系数仅对线性函数关系敏感, 不能有效捕获非线性函数关系, 普适性较差。公平性表示等噪音的任意函数具有相等的关联测度值。
为解决大数据非线性关联分析, 由Reshef等[2]在2011年提出MIC测度, 其本质上是计算两两变量间的互信息值, 但其在互信息计算过程中采用的是不等间隔寻优法, 并对互信息值进行归一化矫正, 取值范围为[0, 1]。不等间隔寻优使得MIC具有普适性的优点, 归一化矫正使其具有等价性优点。
1.2.1 普适性
普适性是MIC最为重要的优点, 即对任意函数关系, 无论线性、非线性关系, 在无噪音时, 其得分值均最大为1, 面对两个无关系的独立变量, 其得分值为0。表1列出了MIC与几种常用的相关性测度[2], 如Pearson相关系数[6, 7]、Spearman相关系数[8]、基于核密度估计的互信息Mutual Information[2]、CorGC系数[9]等, 对不同函数关系的测度情况。
由表1可知, 以上5种测度均能有效检测出线性函数关系“ Linear” 。Pearson相关系数属于经典的线性相关测度, 仅能较好地检出“ Linear” 线性关系, 对Cubic、Exponential、Parabolic拟线性关系有部分检测能力, 对其他复杂非线性关系基本无法检测。Mutual Information互信息、CorGC测度较Pearson线性关系普适性有提升, 对Parabolic等非线性函数关系有一定的检测能力, 但其普适性均弱于MIC测度。对于表中全部函数关系, MIC得分值均为1, 表明了其优异的普适性特征。
| 表1 不同函数关系下的多种测度值 Table 1 Values of different functions in different measures |
1.2.2 等价性
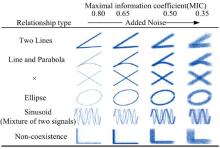
如表1所示, 互信息测度除存在普适性差的缺陷外, 其得分值为[0, +∞ ], 存在不同数据间可比性差的缺点。给定两种函数关系, 若加上等水平的噪音, 其相关系数理应相同, 若某一测度指标计算获得的相关系数差异越小, 表明该测度等价性越高, 反之等价性越差。图1基于6种函数关系示例了MIC的等价性[2]。
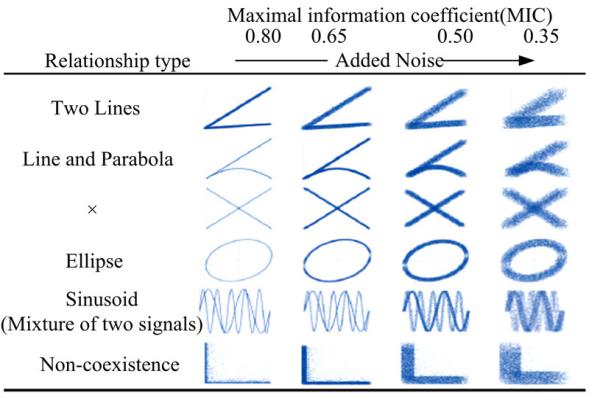 | 图1 不同函数关系不同噪音下的MIC值Fig.1 MIC values of different functions under different noise |
由图1可知, 随着噪音增加, 变量间的相关性降低, MIC值降低, 对相同的噪音水平, 不同函数的MIC值接近, 显然MIC具有较好的等价性。
MIC在本质上是基于互信息的, 但变量的离散化需要进行遍历寻优, 属于计算密集型方法[10]。对大样本数据, 遍历算法并不可行, David等[2]基于动态规划算法给出了快速近似算法。对给定的两个变量x1、x2, 其离散化分段点寻优, 矫正过程如下:
(1)x1 均分。假定x1仅离散化为两段, 首先按升序排列变量x1, 再根据样本数量相等的原则, 按排序均分x1为两段, 该过程即固定x1为两段。
(2)在x1均分两段情况下, 确定变量x2潜在分段点。互信息具有分段数越多得分越高的特点, 为保证MIC得分的准确性, 规定x1变量与x2变量的分段数必须满足限制x× y≤ B(B=n0.6), x表示变量x1的分段数, y表示变量x2的分段数, n表示成对的样本数目。例如, 在x1已均分两段时, 变量x2最多可划分B/2段。一方面为保证x2分段准确性, 另一方面为降低计算复杂度, 采用均分的原则, 可将x2平均分为c× B/2个小簇, c可根据数据样本数自行给定, 如5或15等, 并且在均分x2过程中, 对应x1取值相等的样本应划分在同一个小簇中。这些将x2划分为不同小簇的样本点即为x2的潜在分段点。
(3)基于动态规划的x2变量分段点寻优。遍历上述第(2)步所给定的x2潜在分段点(保持x1均分两段不变), 并计算每种离散情况下的x1与x2的互信息值, 计算公式如下:
I(x1, x2)=H(x1)+H(x2)-H(x1, x2)(1)
定义最大互信息值对应的分段点为x2分两段的最优分段点。在此基础上, 从剩余潜在分段点中确定最优的第3个分段点, 直至第B/2-1个最优分段点, 共划分为B/2段。
(4)x1变量均分多段寻优。当x2仅离散化为两段时, x1最多可被均分B/2段, 依次将变量x1均分为3, 4, …, B/2段, 并重复第(2)(3)步, 获得对应x2变量的最优离散化段数。最终可获得一个不完全的寻优互信息得分矩阵Iij, 矩阵中的每一元素为x1均分为i段、x2离散化j段时x1与x2之间的互信息值。
(5)互信息矫正。上述得到的互信息经最小分段数矫正即可转换为对应的MIC值, 矫正公式为:
MICij=Iij/log2(min([i, j])) (2)
(6)均分方向互换, 将x2均分, 寻优x1变量, 重复第(2)~(5)步, 可获得均分x2方向的MIC得分矩阵。
(7)MIC得分定义为上述两个得分矩阵中最大的得分值。
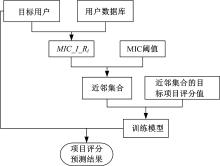
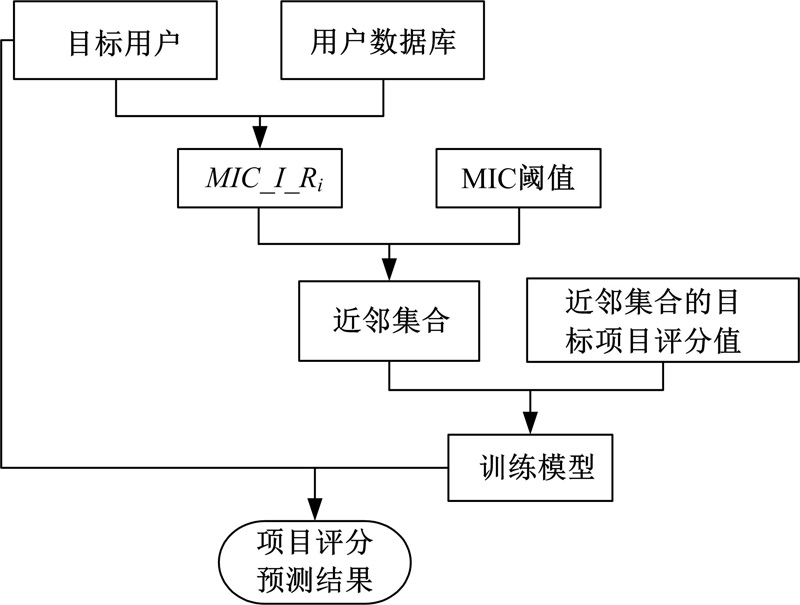
假定n个用户对m个项目评分, 第i 个用户对第j个项目的评价得分为Rij, Rij{i=1, 2, …, n; j=1, 2, …, m}。对目标用户I, 可基于MIC得分表示其与其他用户偏好性的相似程度, 分别记为MIC_I_Ri{i=1, 2, …, n}。
按MIC_I_Ri大小排序, 目标用户I的近邻集合则为与其相似性最高的K个用户, 记为UI_k, 对不同的阈值, 1≤ K≤ n。
对目标用户, 每次基于其所有的近邻集合UI_k作为训练样本, 可对其未评分的项目进行预测评分。本文采用支持向量机(Support vector machine, SVM)作为回归预测模型。
本文所用SVM算法基于采用林志仁教授等[11]开发的LIBSVM平台实现, 该程序包括Svmtrain与Svmpredict两个主程序。前者用于模型训练, 后者用于预测独立测试样本。
以均方误差(Mean square error, MSE)评价预测模型的优劣, 真实值与预测值间差异越小, MSE越小, 即模型预测能力越好, 其计算公式如下:
MSE=
式中:yi为目标用户对第i个项目的真实评分;
本文所用仿真数据为MovieLens网站开源的电影评分数据, 数据集包含了943位用户对1682部电影的100 000条评分记录, 评分值分为5个等级, 用1~5代表, 用户对某部电影越感兴趣, 评分值越大。表2为部分用户对20部电影的评分情况。为降低数据稀疏性, 将1682部电影合并为Action、Children's、Crime、Documentary、Sci-Fi、War等 18种类型。每个类型的评分值为用户对该类型电影评分的平均值。表3为部分合并后的评分矩阵。将全部数据随机分成两部分, 80%用户作为训练集, 20%用户作为测试集。
| 表2 前50个户对前20部电影的评分表 Table 2 Scores of top 50 households on top 20 films |
| 表3 合并后的评分表 Table 3 Combined scores |
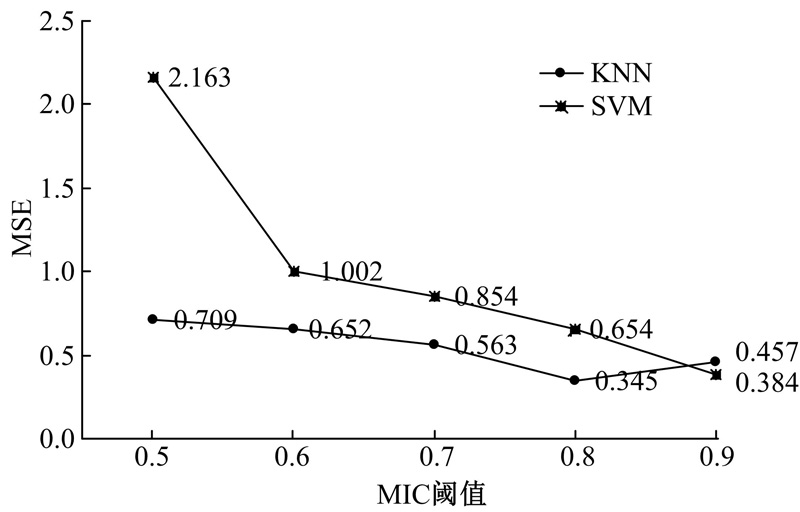
对每个待测样本, 基于给定相似性测度, 从训练集中选择相似性最大的K个样本构建SVM预测模型。本次仿真K取值为60。4种预测模型结果见图3。
 | 图3 不同相似性测度的预测精度Fig.3 Prediction accuracy of different similarity measures |
由图3结果可知, 基于MIC关联测度的模型预测效果最好; CorGC测度能部分检测非线性关联, 其筛选近邻集合的预测精度略低于MIC模型, 但明显优于线性测度Pearson相关系数和MI。
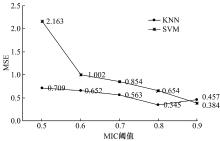
MIC测度所选近邻集合预测精度最高, 因此, 选择该近邻集合作为训练样本, 用于比较不同建模方法预测性能。图4为KNN、ANN、MLR和SVM四种方法的预测效果。
 | 图4 不同建模方法预测精度Fig.4 Prediction accuracy of different modeling methods |
在4种建模方法中, MLR模型预测精度最差, MSE为2.115, 该模型属于典型线性模型, 表明用户评分之间呈现复杂非线性关系, SVM模型属于非线性模型, 其预测精度在参比模型中最优。KNN以近邻集合项目评分均值作为预测样本, 信息完整性不足, 影响预测精度。MIC测度能普适性检测线性、非线性关系, 能筛选信息完整的近邻集合, 所以KNN模型也能获得较优结果。
通过提高待评价项目的评分预测精度, 可以对目标用户对未评分项目的偏好程度做出准确的评估, 确保向用户推送的信息是其真正感兴趣的。因此, 构建准确的项目评分预测模型是协同过滤推荐系统的关键, 训练样本选择(近邻集合筛选)的信息完善程度是构建高精度项目评分模型的基础。基于Pearson相关系数表征用户相似性, 并以此筛选近邻集合是最常用的方法。该方法具有简单、快速的优点, 但具有普适性差的特点, 无法有效地检测用户偏好性的复杂非线性关系。本文引入具有普适性优点的两变量关联测度MIC。仿真结果表明, 相比传统线性关联测度, 基于普适性测度 MIC所选的近邻集合, 项目评分预测模型精度更高, 并具有稳定性好的优点。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|