
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Android恶意软件静态检测模型
[杨宏宇 , 徐晋]
, 徐晋]
, 徐晋]
|
|


作者简介:杨宏宇(1969-),男,教授,博士.研究方向:网络信息安全.E-mail:yhyxlx@hotmail.com
为解决Android恶意应用泛滥的问题,提出一种Android恶意应用静态检测模型。模型选取AndroidManifest.xml文件中3个标签项属性值作为特征属性,采用信息增益(IG)算法对特征属性进行优化选择,根据优化结果生成对应特征向量集合。最后,应用知识分析Waikato环境(WEKA)的4种机器学习分类算法对特征向量集合进行检测和分类。实验结果表明,本文提出的静态检测模型具有较好的检测分类效果。
In order to solve the problem of Android malware spreading, this paper proposes an Android malware static detection model. First, the attribute value of three label items is selected in AndroidManifest.xml file as the feature attribute. Second, the Information Gain algorithm (IG) is used to optimize the feature attribute, then a corresponding feature vector set is generated according to the optimization results. Finally, four kinds of machine learning classification algorithms in Waikato Environment for Knowledge Analysis (WEKA) are used to detect and classify the feature vector set. Experiment results demonstrate that the proposed static detection method has better detection and classification performance.
随着智能手机的不断发展, Android系统逐渐占据了全球手机操作系统大部分的市场份额。然而, Android系统的盛行也使它成为了恶意软件最大的发展平台。360公司发布的《2016年中国手机安全状况报告》[1]显示, 360互联网安全中心2016年全年共截获Android平台新增恶意软件1403.3万个, 平均每天新增恶意软件达3.8万个。Android恶意软件的泛滥给用户带来了众多危害, 使得Android安全成为信息安全研究的热点之一, 所以研究Android恶意软件分类检测方法迫在眉睫。
静态检测是Android恶意软件检测中常用的检测方法。文献[2]提出一种基于权限相关性的Android恶意软件检测方案, 实现了对恶意软件的初步快速检测。文献[3]使用Android权限信息作为特征并进行优化选择, 创建基于改进朴素贝叶斯的恶意应用分类器并取得较好的分类效果。文献[4]提出一种基于支持向量机的Android恶意软件检测方案, 利用危险权限组合和脆弱性API调用作为特征属性并建立分类器, 自动区分恶意软件和良性软件。文献[5]提出一种基于对比权限模式的恶意软件检测方法, 利用关联规则挖掘算法对应用程序进行频繁项集挖掘, 提取出恶意软件与正常软件在权限模式使用上的区别规则, 并在此基础上建立组合分类器用于Android恶意软件检测。其中, 文献[2, 3]只针对Android应用的权限信息进行检测分析, 检测范围不够全面; 文献[4, 5]检测精度都不够高。综上所述, 目前的检测研究成果在检测精度和检测效率方面还存在诸多不足。
本文提出一种Android恶意软件静态检测模型, 对Android应用程序安装包文件进行逆向处理, 提取AndroidManifest.xml文件中的三种标签项的属性值作为特征属性, 采用信息增益算法(Information gain, IG)[6, 7]对特征属性进行优化选择, 建立分类器对Android应用进行检测分类。实验结果表明, 本文方法可有效提高Android恶意软件检测效率。
AndroidManifest.xml文件(以下简称Manifest文件)是每一个Android应用程序中必不可少的组成部分, 必须在该文件中声明应用程序的名称、应用程序运行时所需申请的权限和各类组件的信息等, 上述信息相当于应用程序的配置信息。Manifest文件中有许多标签项, 例如< uses-sdk> 、< permission> 、< application> 等, Manifest文件通过给各标签项添加相应属性值实现对应用程序的配置。表1列出了5组Manifest文件中常用于恶意软件静态检测的标签项。
| 表1 静态检测常用标签项 Table 1 Labels often used in static detection |
表1中, 前3个信息项的标签属性为文本类型, 后两个信息项的属性为数值型。为了便于提取属性值, 本文选取前3个信息项作为属性集合, 即< uses-permission> 、< intent-filter> < action> 和< intent-filter> < category> 。其中, 程序在运行时会使用各种权限, 这些权限需要提前在Manifest文件的< uses-permission> 中进行配置; Intent组件是Android应用间通信的一个关键组件, < intent-filter> 用于描述Intent组件的各种属性, 如动作(action)、类型(category)等, 分别对应于< intent-filter> 标签项中的< action> 和< category> 标签。这两类标签项中配置的属性值显示了应用程序在运行中所申请的权限信息以及与其他应用程序或系统资源间的交互信息。上述3个标签项的属性值能够有效反映出应用程序在运行过程中可能进行的操作, 因此本文选取这3个标签项中的属性值作为特征属性。
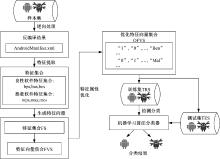
静态检测模型结构如图1所示。该模型主要包括逆向处理、特征提取、生成特征向量、特征属性优化和检测分类等过程。模型处理过程设计如下:
(1)反编译样本集中的Android安装包文件, 生成对应AndroidManifest.xml文件。
(2)分别对AndroidManifest.xml文件中的标签项< uses-permission> 、< intent-filter> < action> 和< intent-filter> < category> 进行属性值提取, 并根据所提取出的属性值统计每个属性值出现的次数并排序, 将使用频率高的属性值组合成为特征集合。
(3)根据特征集合对比与每个Android安装包文件提取出的属性值, 生成相应特征向量集合。
(4)使用属性特征优化算法对特征属性进行优化选择, 对生成的特征向量集合进行特征属性优化排序, 根据排序结果选取更具有代表性的特征属性并生成优化特征向量集合。
(5)将经过优化的特征向量集合分为训练集和测试集, 使用机器学习分类算法对训练集进行训练, 并对测试集进行检测分类。
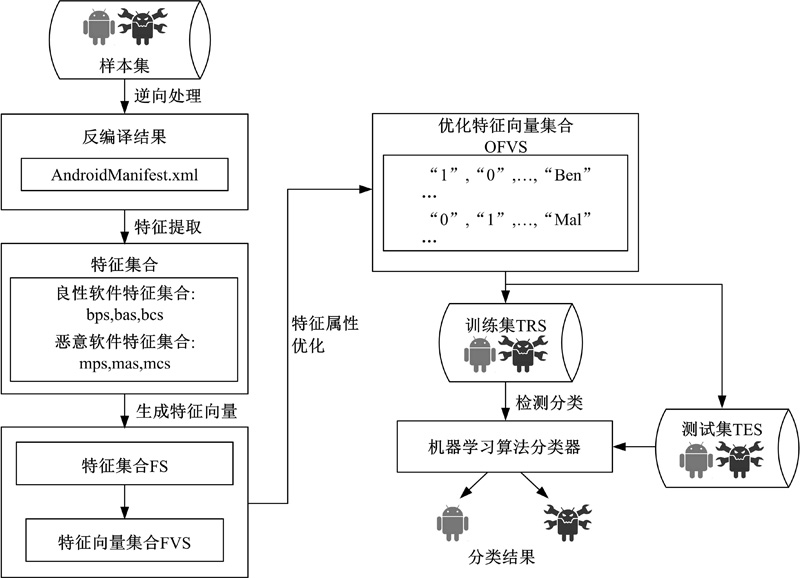 | 图1 静态检测模型Fig.1 Static detection model |
检测模型对恶意软件检测分类过程如下:
(1)使用Apktool[8, 9]对应用安装包样本集进行反编译处理, 生成包含Manifest文件的文件夹。然后使用Python[10]的xml.dom模块和IO模块对Manifest文件进行解析。抽取3个标签项的属性值, 完成样本集中应用安装包文件的特征属性提取。
(2)计算特征属性数量并对其进行排序, 将结果由高到低分别输出。根据排序结果, 分别将Android平台下良性应用和恶意应用中使用频率较高的特征属性组合为3个良性应用属性集合和3个恶意应用属性集合, 然后采用并集运算, 将6个属性集合组合成特征集合FS。
(3)使用匹配算法计算样本集中每个应用的Manifest文件是否含有集合FS中对应的元素, 生成相应特征向量并组合成特征向量集合FVS。采用信息增益算法对FVS的特征属性进行优化排序, 并根据排序结果重新组合形成优化特征向量集合OFVS。
(4)将OFVS划分为训练集TRS和测试集TES。将TRS和TES转换为Waikato知识分析环境(Waikato environment for knowledge analysis, WEKA)的数据输入格式.arff, 使用WEKA集成的机器学习分类算法对TRS进行训练并对TES进行检测分类。
为了验证本文模型的有效性, 对1934个Android应用安装包文件进行检测分类实验。其中, 良性应用安装包来源于谷歌官方应用市场和国内第三方应用市场, 从上述应用市场下载良性应用安装包674个, 共计15.4 GB; 恶意应用安装包文件来源于北卡罗来纳州立大学创建的Android恶意应用基因组项目(Android malware genome project)公布的Android恶意应用样本集合资源[11], 本文从该集合中提取1260个恶意应用安装包, 共计1.53 GB。将上述两类Android应用安装包集合组合成实验样本集合, 共计1934个Android应用安装包文件样本。本实验的软硬件环境配置如表2所示。
| 表2 实验环境配置 Table 2 Experimental environment configuration |
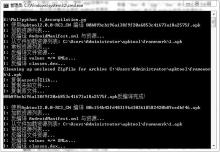
将样本集中的Android应用安装包文件分别放到指定目录下, 按照前文所述模型详细步骤, 首先对Android安装包文件进行批量反编译, 如图2所示。
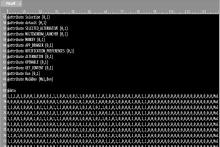
然后, 对反编译得到的Manifest文件进行解析并统计解析结果, 分别得到良性应用和恶意应用的Manifest文件标签项< uses-permission> , < intent-filter> < action> 和< intent-filter> < category> 中使用频率较高的属性值信息, 并对属性值进行排序, 部分标签属性的排序结果如图3所示。
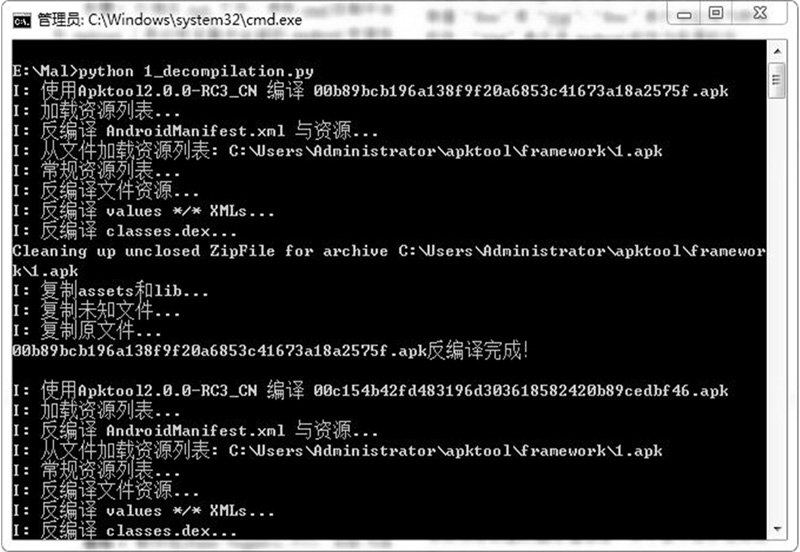 | 图2 批量反编译Fig.2 Batch decompile |
根据上述属性排序结果, 选取使用频率较高的属性, 本文选取了< uses-permission> 标签项中的31个属性值、< intent-filter> < action> 标签项中的16个属性值和< intent-filter> < category> 标签项中的16个属性值, 共计63个属性值作为特征属性。然后根据WEKA的输入数据格式生成对应的特征向量集合FVS.arff, 如图4所示。
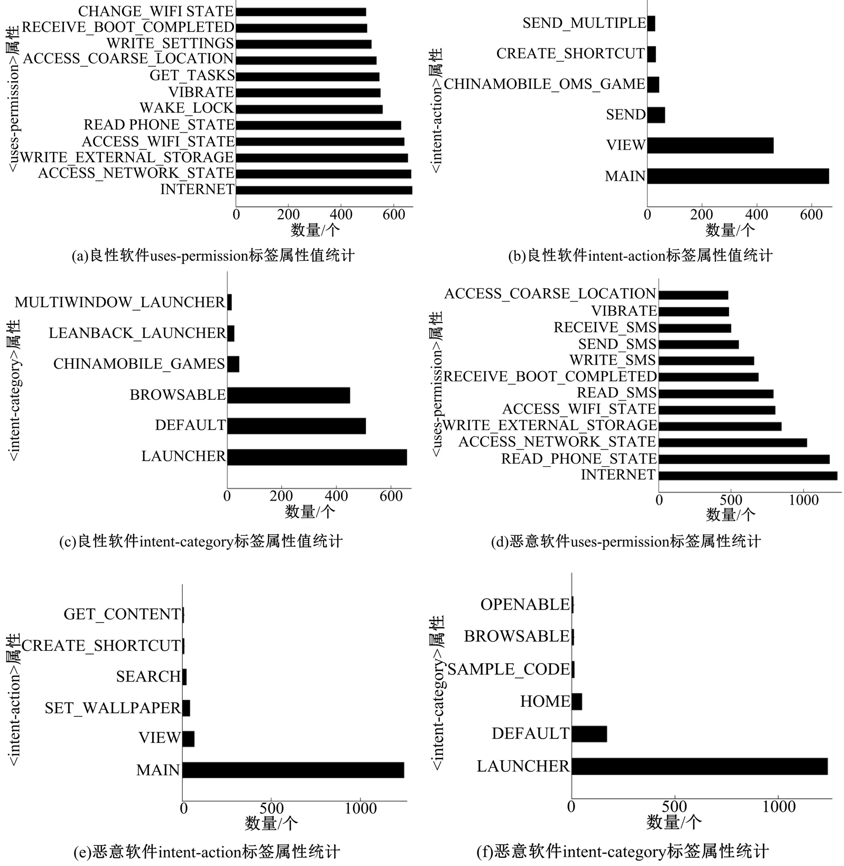 | 图3 Android应用常用属性统计Fig.3 Android application common attributes statistics |
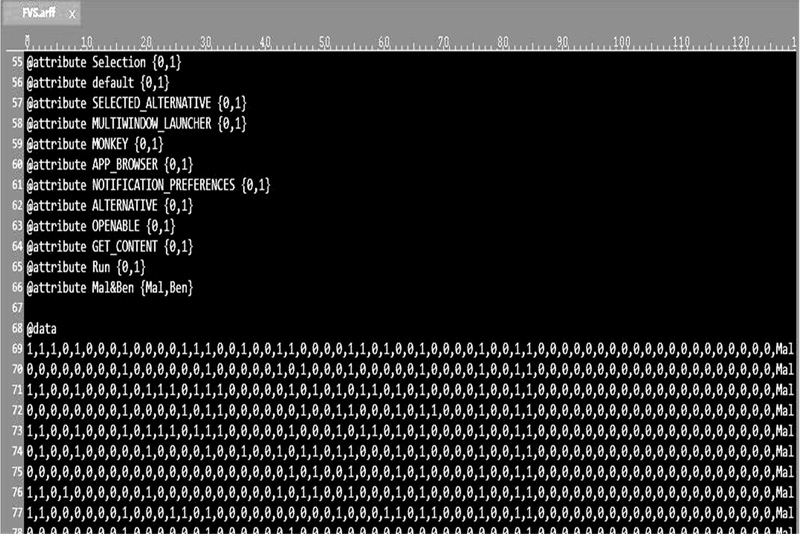 | 图4 特征向量集合FVS.arffFig.4 Feature vector set FVS.arff |
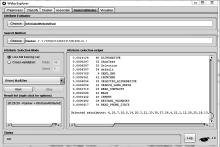
为了选取具有更高区分度并消除尽可能多无关和冗余的特征属性, 作者采用IG算法对特征属性进行优化排序。将FVS.arff输入到WEKA中, 使用IG算法对其中的特征属性进行排序, 排序结果如图5所示, 排序后的部分结果如表3所示。
根据表3的排序结果, 分别生成特征属性数量为10、20和30的优化特征向量集合OFVS_10.arff, OFVS_20.arff和OFVS_30.arff。
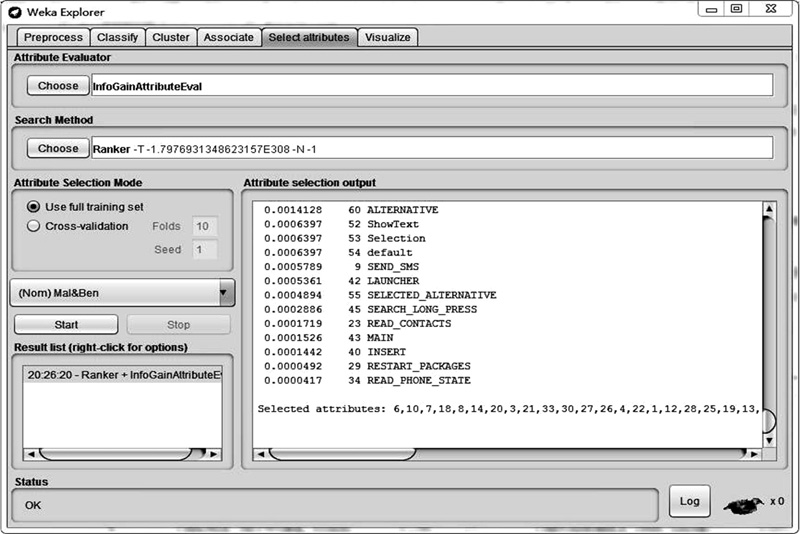 | 图5 WEKA特征优化结果Fig.5 Feature optimization results in WEKA |
| 表3 特征属性排序结果 Table 3 Attributes sorting result |
为有效度量检测分类性能, 定义下列概念:
正确:将恶意应用检测分类为恶意。
误报:将良性应用检测分类为恶意。
识别:将良性应用检测分类为良性。
漏报:将恶意应用检测分类为良性。
正确率:被检测分类出的恶意应用数量与实际恶意应用数量之比, 正确率=正确/(正确+漏报)。
误报率:被检测分类出的恶意应用数量与实际良性应用数量之比, 误报率=误报/(误报+识别)。
检测率:检测分类的准确度, 检测率=(正确+识别)/(正确+识别+误报+漏报)。
将3.2节生成的特征属性长度分别为10、20和30的优化特征向量集合OFVS_10.arff, OFVS_20.arff和OFVS_30.arff输入WEKA, 同时使用WEKA中集成的4种机器学习算法:朴素贝叶斯(Naive Bayes, NB)[12], 序列最小优化(Sequence minimum optimization, SMO)[13], Bagging[14]和随机树(Random tree, RT), 采用10折交叉验证的方法对特征向量集合进行检测分类。
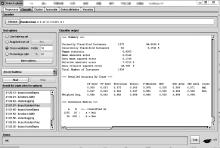
将特征向量集合分成10份, 轮流将其中9份作为训练集, 剩余1份作为测试集, 并对10次实验结果取均值, 实验过程如图6所示。图6中分类输出结果窗口显示的是使用Random Tree算法和特征属性长度为30的特征向量集合的结果, 应用4种算法的检测结果如表4所示。
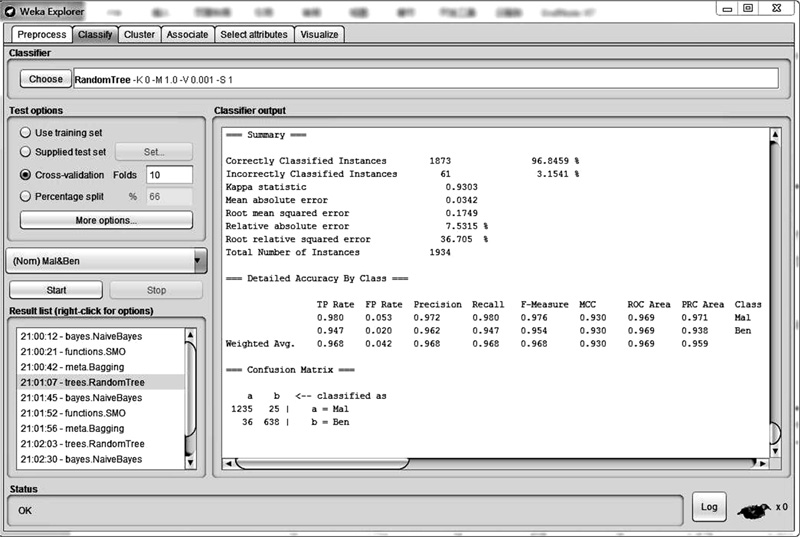 | 图6 WEKA检测分类结果Fig.6 Detection classification results in WEKA |
| 表4 不同分类器的分类效果对比 Table 4 Comparison of classification results of different classifiers |
由表4可见, 本文所提出的静态检测模型分类效果较好, 在4种机器学习算法上都有较好的检测率, 在特征属性数量达到20时有较高的检测率, 在特征属性数量为30时的检测率比20时的检测率普遍提高, 检测率度均大于94%, 高于文献[3]的改进朴素贝叶斯分类器的检测精度92.5%。
针对Android平台恶意软件泛滥以及现有检测算法检测精度还不够高等问题, 提出一种Android恶意软件静态检测模型。模型选取AndroidManifest. xml文件中3个典型标签项中的属性值作为特征属性, 并使用IG算法对特征属性进行优化选择。通过检测实验表明, 该静态检测分类模型拥有较高的检测率。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|