{kind=link}
基于有限序列的压缩新算法
[赵宏伟1, 2, 3  , 刘宇琦
, 刘宇琦1 , 特日根4 , 陈长征2 , 臧雪柏1, 3 ]
, 刘宇琦]
|
|


作者简介:赵宏伟(1962-),男,教授,博士生导师.研究方向:智能信息系统.E-mail:zhaohw@jlu.edu.cn
为了降低排序序列的空间复杂度,提出了CSNB二进制压缩排序数。通过包含有01校验、奇偶校验以及CSNA校验的解压算法,正确地还原出原序列,并对解压算法结果的唯一性进行了理论及实验检验。从实验结果可知,CSNB能够正确描述任意排序序列,且通过CSNB解压算法可以得到唯一解,即可以还原出原序列。通过对CSNB压缩算法的测试,表明CSNB压缩算法对整数型文档具有较高的压缩率。数据压缩不仅可以节省数据的存储空间,而且能够增强其在传输过程中的安全和效率。
CSNB binary compression sort numbers are proposed to reduce the spatial complexity of ordering sequence, and the original sequence is restored correctly by 01 check, parity check and decompression algorithm of CSNA check. The uniqueness of the decompression algorithm result is theoretically and experimentally tested. CSNB can correctly describe any sort sequences through experimental results, and a unique solution can be obtained by CSNB decompression algorithm, which can restore the original sequence. Test results show that CSNB compression algorithm has high compression ratio for documents of integer types. Data compression can not only save data storage space, but also enhance the safety and efficiency in the transmission process.
数据业务和多媒体通信业务等通信量越来越大, 给信息存储特别是网络传输带来前所未有的压力。现有数据压缩算法分为无损压缩和有损压缩。有损压缩通过数据挖掘等手段从数据来源、数据特性出发, 提取关键信息予以保存。语音识别、市场销售数据、气象数据、电信通信数据等均可采用有损压缩方法处理。针对这种数据的有损压缩通常有两类办法[1]:数据汇聚和数据近似。汇聚函数以抛弃数据中的原始结构为代价, 减少数据量, 但这种方法使得一些有用的知识被删除, 其中主要包括COUNT、SUM、AVG等方法; 数据近似[2]可视为基于模型的数据获取, 通过对采集到的感知数据进行分布式建模, 可减少数据传输量、节省网络能量、延长网络生命。有损压缩方法可分为基于概率模型[3]、基于时间序列分析模型[4]、基于数据挖掘模型[5]、基于数据压缩模型[6]4类, 其共性在于压缩率高, 数据还原质量依赖于算法实现的代价。
无损压缩技术[7]在数据压缩过程中不允许损失精度, 可以保真还原。主要用于文本文件、数据库、程序数据和特殊应用场合的图像数据(如指纹图像、医学图像)等压缩。游程长度编码[8]通过去除文本中的冗余字符或字节中的冗余位, 达到减少数据文件所占的存储空间的目的, 其压缩效能取决于整个数据流的重复字符出现次数、平均游程长度以及所采用的编码结构。由于该算法是针对文件的某些特点所设计的, 具有一定的局限性。Gö del[9]提出一种不依赖于数据库的无损压缩方法, 称为哥德尔数方法, 但其使用范围局限于对图灵机程序的压缩, 因此不具有普遍性。
本文提出了CSNB(Compress sequence number-Binary)压缩算法, 通过增加校验位的形式实现压缩。
定义1 对于任意序列, 其对应的最小字长的二进制序列为原序列的CSNB序列。
例:若序列为1, 3, 2, 6, 5, 4, 则CSNB序列为001, 011, 010, 110, 101, 100。
定义2 任意1到n的全排列序列, 通过式(1)计算得到的二进制数为此序列的奇偶校验码CSNBc:
式中:N表示在二进制数N中每位依次求异或所得到的值; CSNBi为CSNB序列中的第i个数。
例:若序列为1, 3, 2, 6, 5, 4, CSNB序列为001, 011, 010, 110, 101, 100, 则奇偶校验码的计算过程为:
CSNBc为100101。
定义3 任意CSNB序列, 通过式(2)计算所得的值为CSNB序列的前序错位求和部分CSNF。
定义4 任意CSNB序列, 通过式(3)计算所得的值为CSNB序列的后序错位求和部分CSNA。
任意长度为n的CSNB序列, 其CSNF和CSNA的长度均为$n+\lfloor log_2 n \rfloor + 1$。
定义5 任意CSNB序列, 通过式(4)计算所得的值为CSNB序列的CSNB。
$CSNB = 10^{\lfloor log_{10} n \rfloor + 10_n + 1} \times CSNF + \\ 10^{n} \times CSNA +CSNB_{c} \quad (4)$
因为CSNB序列为二进制序列, 所以式(4)为二进制计算。
例:CSNB序列为:001, 011, 010, 110, 101, 100
CSNB=$10^{\lfloor log_{10} n \rfloor +10_{n}+1}$× CSNF+
10n× CSNA+CSNBc=101111×
(100× 1+101× 11+1010× 10+
1011× 110+10100× 101+10101× 100)+
10110× (100× 100+101× 101+1010× 110+
1011× 10+10100× 11+10101× 1)+
100101=10000111110000110100101
原序列以十进制的方式记录排序序列。计算机对十进制数常用的编码方式是BCD码, 以16位计算机为例, 在记录十进制数时计算机会为每个十进制数预留16位。而CSNB序列是以二进制的方式记录排序序列, 计算机在记录时不需要编码转换。其对比结果如表1所示。
| 表1 原序列与CSNB序列的比较 Table 1 Comparison of original sequence and sequence CSNB |
原序列、CSNB序列以及CSNB都具有记录序列的功能, 其空间复杂度对比结果如表2所示(计算机为k位)。
| 表2 CSN序列、CSNB序列以及CSNB占用空间对比 Table 2 CSN sequence, CSNB sequence and CSNB space comparison bit |
由表2可知, 当序列长度n≤ 8时, CSNB序列较CSNB有更好的空间利用率, 且CSNB序列并没有进行改装压缩, 所以也不需要繁琐的解压过程, 但当8< n< 2k时, CSNB则需要更少的空间, 且适用范围远比CSNB序列要大。
为尝试所有的排序可能, 需要建立一个具有
定义6 如果一个节点N的奇偶校验码为N1, 其祖先节点要求的奇偶校验码为1, 且N1≠ 1, 则剪枝发生在该节点之上, 此时, 称该剪枝过程为奇剪枝。
定义7 如果一个节点N的奇偶校验码为N1, 其祖先节点要求的奇偶校验码为0, 且N1≠ 0, 则剪枝发生在该节点之上, 此时, 称该剪枝过程为偶剪枝。
定义8 如果一个在第n层(根节点为第0层)的节点N与回溯到根节点中所有遍历到的节点进行式(3)的计算, 得到结果的倒数第n位为C, 其祖先节点要求的01校验码为1, 且C≠ 1, 则剪枝发生在该节点之上, 此时, 称该剪枝过程为1剪枝。
定义9 如果一个在第n层(根节点为第0层)的节点N与回溯到根节点中所有遍历到的节点进行式(3)的计算, 得到结果的倒数第n位为C, 其祖先节点要求的01校验码为0, 且C≠ 0, 则剪枝发生在该节点之上, 此时, 称该剪枝过程为0剪枝。
因为任意CSNB都满足:当i≠ j时, CSNi≠ CSNj且1≤ CSNi≤ n, 所以, 任意一个在第n层的节点向下遍历的所有兄弟节点中, 其奇偶校验值N1为0和1是等可能的, 其通过回溯计算和的倒数第n位为0和1也是等可能的。决策树在没有剪枝时一共有
性质1 由于奇偶剪枝不需要累加运算, 且在选定下一节点时可直接计算, 并且奇偶剪枝针对的是真实的排序值, 所以奇偶剪枝较01剪枝速度更快、效率更高。
虽然通过决策树的剪枝方法能够删掉大多数非解节点, 但剪枝后的决策树仍然可能存在多个所在层为n的叶子节点, 所以还需要通过CSNA对所有可能解进行检验。
例:CSNB序列为:001, 011, 010, 110, 101, 100, CSNB=100001111100101, 其剪枝策略如图1所示, 先进行奇偶校验, 再进行01校验。其中, “ 奇× ” 、“ 偶× ” 、“ 1× ” 和“ 0× ” 分别表示进行奇剪枝、偶剪枝、1剪枝和0剪枝操作。
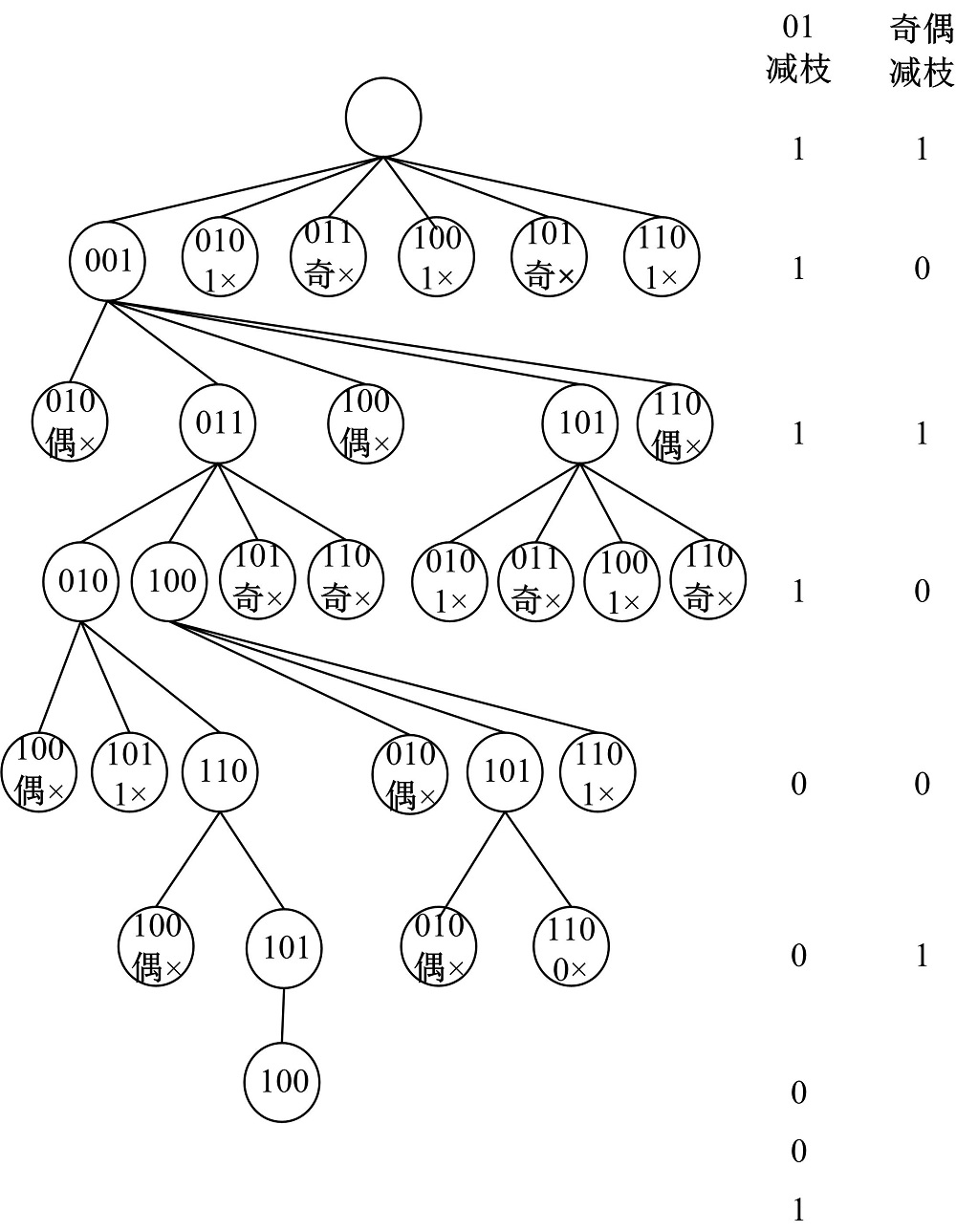 | 图1 剪枝策略示意图Fig.1 Pruning strategy schematic |
创建决策树是从逻辑的角度分析算法的执行过程, 本质上解压算法并不需要构建决策树。决策树在选择节点时, 是通过剪枝策略来判断其选择的节点是否正确, 从逻辑角度来说, 是尝试着确定CSNBi的位置。
根据式(2)求CSNBi, 本质上是在求以CSNB1, CSNB2, …, CSNBn为未知数, 方程CSNF=20× CSNB1+21× CSNB2+…+2n-1× CSNBn(方程为十进制方程)的解, 其中当i≠ j时, CSNi≠ CSNj且1≤ CSNi≤ n。
而决策树是在明确CSNBi值的情况下, 去求其位置, 即为求以x1, x2, …, xn为未知数, 方程CSNF=
根据以上分析, 可制定CSNB解压算法的步骤如下所示。
(1)建立记录所有未知数状态的未知数状态表(State table), 所有未知数的初始状态是Uncertain。若未知数个数为n, 则未知数的其他可能状态数为[1, n]中的整数。
(2)从State table中提取一个未被测试过的且状态为Uncertain的未知数, 并执行第(3)步。如果不存在符合条件的未知数, 则执行第(5)步。
(3)将选定的未知数依次通过奇偶检验和01检验, 如果都通过, 则执行第(4)步; 否则, 将此未知数视为已检测状态, 并执行第(2)步。
(4)将选定的未知数的初始状态更改为未被选定的状态中最小的状态数, 将其他状态为Uncertain的未知数均视为未被测试状态, 执行第(2)步。
(5)若State table中仍存在状态为Uncertain的未知数, 则将状态数最大的未知数以及之后的未知数状态设定为Uncertain, 将之后的未知数视为未检测状态, 并继续执行第(2)步; 否则执行第(6)步。
(6)通过CSNA判断找到的可能解的正确性, 若正确, 算法结束; 否则, 将状态数最大的未知数以及之后的未知数状态设定为Uncertain, 将之后的未知数视为未检测状态, 并执行第(2)步。
所谓正向检验, 就是给定任意排列的CSNB, 由CSNB解其原序列, 若解唯一, 不仅能说明CSNB系统的正确性, 还能检验解压算法的正确性。
任意长度为n的CSNB序列, 其全排列的总数为n!, 当n=9时, 一共有9!=362880种排列情况, 一一测试是不合理的, 所以当1< n< 9时, 对全排列进行测试; 当n≥ 9时, 随机生成1000个排序序列, 并对其进行检验。检验包括没有奇偶校验、没有CSNA校验以及所有校验均存在这3种情况, 01校验本身属于解方程过程, 所以不能没有, 检验结果如表3所示。
| 表3 正向检验解的唯一性 Table 3 Positive test uniqueness of the solution |
由表3可知, CSNA的查错率更高。假设没有奇偶校验和没有CSNA校验的多解率符合某种概率分布, 且是相互独立的, 则当5< n< 9的全校验的多解率应该大于零, 但测试结果显示全校验的多解率为0, 所以可知, 没有奇偶校验与没有CSNA校验的多解率的概率是相关的。
所谓反向检验, 就是给定任意排列的CSNB, 计算是否存在一个不同的CSNB序列的CSNB与其相同, 若存在则解不唯一; 若不存在则解唯一。通过对比正向检验和反向检验的结果可知解压算法的正确性。
任意长度为n的CSNB序列, 其全排列的总数为n!, 通过与其所有不同的CSNB序列作对比, 其比较次数为n!!。当n=9时, 一共有9!!=362880!次比较, 这样测试是不合理的, 所以采用与正向检验相同的方法对其进行反向检验, 即当1< n< 9时, 对全排列进行测试, 当n≥ 9时, 随机生成1000个排序序列, 并对其进行检验。检验结果如表4所示。
| 表4 反向检验解的唯一性 Table 4 Uniqueness of the solution of reverse test |
研究了排序序列的记录及存储方式, 提出了CSNB的存储方式, CSNB中包含有前序错位求和CSNF、后序错位求和CSNA以及奇偶校验码3部分。CSNB通过对排序序列进行压缩, 其空间复杂度为O(log2n+n)。通过解压算法可找到对应的原序列, 实现序列还原。CSNB的压缩不仅可以使其具有更好的空间利用率, 而且能够增加信息传递的可靠性。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|