

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
位图局部敏感哈希的匹配二进制特征搜索算法
[杨东升1  , 张展
, 张展1, 2 , 廉梦佳1, 2 , 王丽娜1, 2 ]
, 张展|
|


作者简介:杨东升(1965-),男,研究员,博士生导师.研究方向:数控技术,机器人视觉.E-mail:dsyang@sict.ac.cn
针对现有匹配二进制特征搜索算法效率低和入围点少的问题,提出了快速计算位图算法和位图局部敏感哈希算法。首先,计算左图提取的二进制特征的位向量;然后,使用快速计算位图算法计算位向量的位图,将位图作为关键字,并与二进制特征的标识作为映射,构建局部敏感哈希表;接着,将哈希表中的关键字存入位集;最后,判断右图提取的二进制特征对应的位图是否存在于哈希表中,优化查询哈希表中的匹配二进制特征,提高匹配二进制特征的搜索效率和质量。实验证明:位图局部敏感哈希算法提高了二进制特征近邻搜索的效率、增加了入围点数。
To solve the issues of low efficiency and less inliers of existing matching binary feature search algorithms, a Fast Calculating Bit Map algorithm (FCBM) and a Bit Map Locality Sensitive Hashing algorithm (BMLSH) are proposed. First, the bit vectors of the binary features extracted from left image is calculated and the FCBM is used to calculate bitmap of each bit vector. Second, the bitmaps of the bit vectors are taken as the key words, and each keyword and its corresponding binary feature identifier are used to construct local sensitive hash table, then the maps are stored in the hash table. Furthermore, the keywords in the hash table are stored in the bit set. Finally, the bit set is used to judge whether the bitmaps of right image binary feature exists or not in the hash table, and the query of matching binary features are optimized to improve the search efficiency and quality. Experiments show that the proposed BMLSH can improve the search efficiency and increase the number of inlier points.
二进制特征是图像特征匹配和识别的先进技术, 相对于SIFT[1, 2]和SURF[3, 4]特征, 其具有有效计算、快速比较和紧密存储的优点。目前, 主要二进制特征的提取算法有BRIEF[5]、ORB[6]、BRISK[7]、FREAK[8]和CBD[9]等。二进制特征即01字符串, 一般使用汉明距离和最近邻比率算法[10](NNDR)判断两个二进制特征是否匹配。
搜索匹配特征向量的算法有多种, 但并不适用于搜索匹配二进制特征, 因此有人提出了适用于搜索匹配二进制特征的哈希技术。例如:Indyk等[11]提出基于哈希表的近似近邻搜索算法— — 局部敏感哈希(LSH)算法, 其只适用于欧氏空间特征向量的搜索。Lv等[12]提出多探头局部敏感哈希(MPLSH), 有效地解决了高维特征的相似度搜索问题, 且可用于匹配二进制特征搜索。Kong等[13]提出将曼哈顿哈希表用于大规模图像检索, 把二进制特征转化为十进制数, 根据曼哈顿距离计算不相似度进行查询。Shrivastave等[14]通过旋转致密化位排列哈希, 实现了高维二进制特征的快速近邻搜索。Lin等[15]提出在高维数据中使用决策树快速监督哈希算法。Liong等[16]提出了基于紧凑二进制代码学习的深度哈希算法。Lin等[17]提出了二进制哈希编码的深度学习算法, 实现了图像的快速检索。Norouzi等[18]在紧凑二进制代码中, 给出最小亏损哈希算法; 之后, 采用多索引实现了在汉明空间的二进制代码子字符串的快速搜索, 使在汉明空间的k近邻(KNN)搜索成为可能[19]。Muja等[20]在使用自动算法配置的快速近邻搜索中, 给出多个随机KD树算法搜索高维匹配特征, 在二进制特征快速匹配算法中提出了多层次聚类树(HCT)算法, 在高维数据可扩展近邻算法[21]中, 对近似最近邻算法做出总结, 并给出相应的近似近邻快速搜索的函数库(FLANN)。文献[22]提出了位图索引的近邻搜索算法, 具有占用空间少和搜索速度快的优点。
本文提出了快速计算位图(FCBM)算法和位图局部敏感哈希(BMLSH)算法, 搜索两个数据集中的匹配二进制特征或相似的二进制代码, 以提高匹配特征搜索效率和增加入围点数。本文实验使用文献[23]给出的图像数据集提取的ORB二进制特征, 使用入围点数、入围率、平均查询时间、平均投影误差和空间复杂度等评价标准, 将本文算法与FLANN函数库中的二进制特征匹配算法(包括LINEAR、MPLSH和HCT等)进行对比。实验结果表明:在相同条件下, 本文算法的消耗时间少、搜索到的入围点数多、匹配入围率与平均投影误差与其他算法接近、消耗的内存空间与多探头局部敏感哈希算法相当。
二进制特征的提取[5, 24, 25]是根据特征点邻域中, 对应的“ 点对” 之间灰度值大小确定特征0、1状态的取值, 如式(1)所示:
式中:
设
二进制特征(如BRIEF、ORB、BRISK和FREAK特征)在存储时, 依次将每8个
最初的局部敏感哈希算法[11], 需要将欧氏空间中的特征向量转换到汉明空间中, 同时确定特征向量在哈希表中的位置, 而二进制特征一般是由BRIEF、ORB等算法直接提取[26, 27]。局部敏感哈希的核心是点积:
$h^{x, b}(\vec{v}) = \lfloor \frac{\vec{x}· \vec{v}+b}{w} \rfloor \quad (3)$
式中: $\lfloor$· $\rfloor$为向下取整函数;
点积的投影使近邻特征映射到哈希表中相同的位置, 需要的条件如下:
(1)在
式中:
(2)在
注意, 由于线性点积, 两特征向量
位图索引
例子中, 有6条点对记录, 所以位向量长度为6, 第1条、第2条和第6条的整型记录为30, 所以整型记录30对应的位向量为110001; 同理, 整型记录40和50对应的位向量分别为001010和000100。例子中, 第1条和第4条的二进制记录为101, 所以二进制记录101对应的位向量为100100; 同理, 二进制记录010和011对应的位向量分别为010010和001001。
二进制特征是高维的位向量, 比如BRIEF、ORB特征是256位, BRISK、FREAK特征为512位。本文以ORB二进制特征为例, 描述本文FCBM算法。ORB特征以无符号字符型(uchar)的形式存储在内存, 所以256位的ORB特征在内存中存储了32个无符号字符型数。FCBM算法的主要目的是让近邻的二进制特征获得相同的或近邻的位图, 并使计算位图的速度更快。
FCBM算法如下:首先从一个无符号字符型数(8 bit)中选取5 bit, 组成一个5 bit的无符号字符类型数
首先, 计算并记录
| 表1 无符号字符型的取位 Table 1 Getting bits of unsigned characters |
由于uchar类型数值的范围为[0, 255], 而uchar类型掩码
| 表2 记录Si和S'i对应的位向量 Table 2 Bit vector of Si and S'i |
最后, 将近邻记录的位向量按位取“ 或” , 其结果作为二进制特征的位图。计算二进制特征时, 位的状态可能跳变, 由0变1或由1变0, 导致近邻记录的位向量是同一位向量或者近邻向量, 如表1近邻记录
将每个二进制特征的位图或其位图的一部分作为关键字, 将关键字与二进制特征的ID作为映射存入每个哈希表相应的桶中。每个哈希表都有一个与关键字长度一致的掩码, 目的是再计算二进制特征的位图时, 避开近邻特征中不一样的位和降维。一般构建多个哈希表, 哈希表中的一个哈希桶对应一个关键字, 一个关键字对应一个或者多个二进制特征ID。因为ORB二进制特征是由256位组成, 即32个uchar类型, 所以ORB二进制特征位图是32维的位向量, 转化成32 bit的无符号整型数, 保存在内存中。
位集(bitset)是快速查询关键字是否存在的一种算法。本文使用位集对匹配二进制特征的查询进行优化, 以快速判断当前查询特征是否存在于哈希表中。初始化位集为0, 首先根据式(6)将哈希表中所有的关键字key存储到位集bitset[]中, 如下所示:
查询时, 根据式(7)判断当前查询关键字是否存在于哈希表中:
若当前计算结果为0, 则关键字不存在; 若计算结果不为0, 说明关键字存在, 则查询与当前哈希表对应的桶。
在位集中, 若当前关键字存在于哈希表中, 则查询关键字对应的哈希桶中所有ID相应的二进制特征, 计算当前关键字相应的二进制特征与ID相应二进制特征的汉明距离, 当遇到与当前查询二进制特征的最近邻特征和次近邻特征时, 保存相应的ID以及最近邻和次近邻距离。设最近邻距离为d1, 次近邻距离为d2, 根据NNDR算法, 判断当前查询特征与ID相应的二进制特征是否匹配, 如式(8)所示:
若满足阈值条件R< 0.6, 则匹配; 否则不匹配。
实验包括5个部分:①计算位图:提取左、右两图像的二进制特征, 使用FCBM算法, 分段依次计算每个二进制特征对应的位图。②构建哈希表:使用左图二进制特征对应位图作为关键字, 将关键字与二进制特征的ID作为映射, 存入每个哈希表里相应的桶中, 一个关键字可以对应多个二进制特征的ID。③位集优化搜索:将哈希表中的关键字存到位集中, 原因是位集可以快速判断当前查询关键字是否存在于当前哈希表中。④保存查询信息:若右图特征对应关键字存在于哈希表中, 则计算左图关键字对应二进制特征与当前右图特征的汉明距离, 保存当前特征的最近邻和次近邻距离以及关键字对应特征的ID。⑤匹配入围点判断:使用NNDR算法, 判断左、右两图二进制特征是否匹配, 根据左、右图像匹配点集合, 计算左图转到右图点的旋转矩阵, 旋转矩阵乘以左图点得到的坐标与对应右图点坐标的距离叫投影误差, 根据投影误差判断当前点是否是入围点, 入围点数除以匹配点数即为匹配入围率。
实验使用Windows7操作系统, OPENCV图像处理函数库; 使用文献[23]给出图像数据集所提取的ORB二进制特征作为算法评价数据集。文献[23]给出的图像数据集中, 每个图库有6幅图像, 且每个图库里的图像都是同一场景在不同情况下拍摄的。实验时使用其中的5个图库, 包括bike、boat、luven、trees和ubc图库, 同一图库将第1幅图像提取的ORB特征作为训练特征, 其他图像提取的ORB特征作为匹配查询二进制特征, 图库中每张图提取的ORB特征数如表3所示。使用搜索算法, 查询左图与右图的匹配二进制特征, 计算两图的匹配点数、入围点数、入围率和平均投影误差等。将本文算法与FLANN函数库中的搜索匹配二进制特征的算法进行对比, 包括LINEAR、MPLSH和HCT算法等。
| 表3 提取不同数据集中各图像的ORB特征个数 Table 3 Number of ORB features for extracting each image in different dataset |
3.2.1 哈希表数目不同
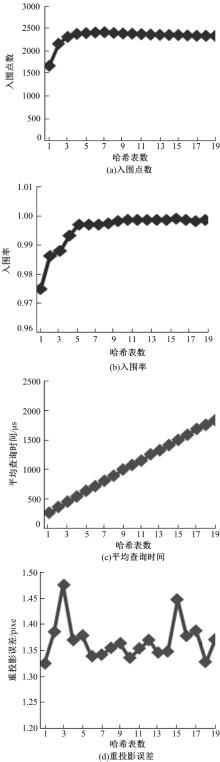
本文BMLSH算法有两个变量, 分别是哈希表数和关键字长度。如图1所示, 本文算法的定量分析图, 设置关键字长度为20, 提取bike图库中bike1图的ORB特征为5972个, bike2图的ORB特征为5067个。由图1(a)可以看出:本文算法搜索到的入围点数在哈希表数不少于3个时, 入围点数大于2300, 并且随着表数的增加, 入围点数先是快速增加随后趋于稳定; 由图1(b)可以看出:本文算法的入围率高, 入围率随着哈希表数的增加先是增加随后趋于稳定; 由图1(c)可以看出:本文算法的平均查询时间随着哈希表数的增加呈线性增长; 由图1(d)可以看出, 本文算法搜索到入围点的平均投影误差小于1.5 pixel。
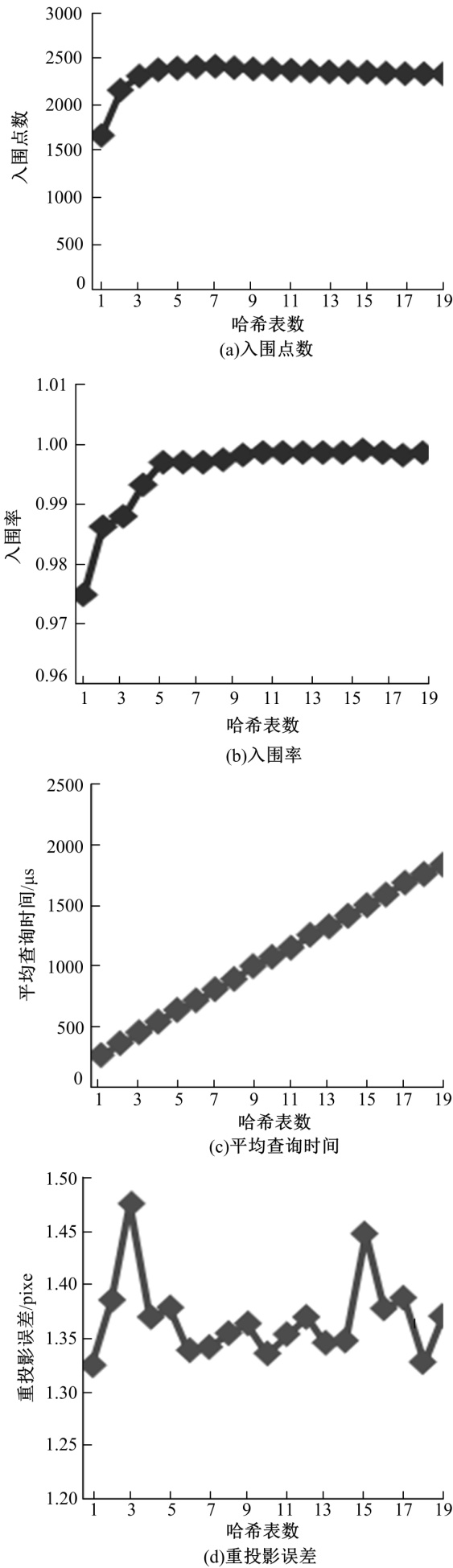 | 图1 不同哈希表数量时本文算法的性能Fig.1 Performance of proposed method under different number of hash tables |
3.2.2 关键字长度不同
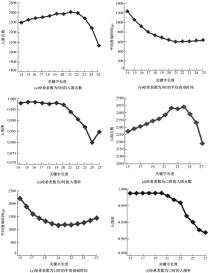
图2为不同关键字长度时本文算法的性能, 定量设置哈希表数为5和12, 提取bike图库中bike1图的ORB特征为5972个, bike2图的ORB特征为5067个。由于3.2.1节入围点数入围率在哈希表数为5时接近最大, 在哈希表数为12时趋于稳定, 所以设置两个定量分析:当哈希表数为5时, 设置关键字长度为14~25; 当哈希表数为12时, 设置关键字长度为15~27。
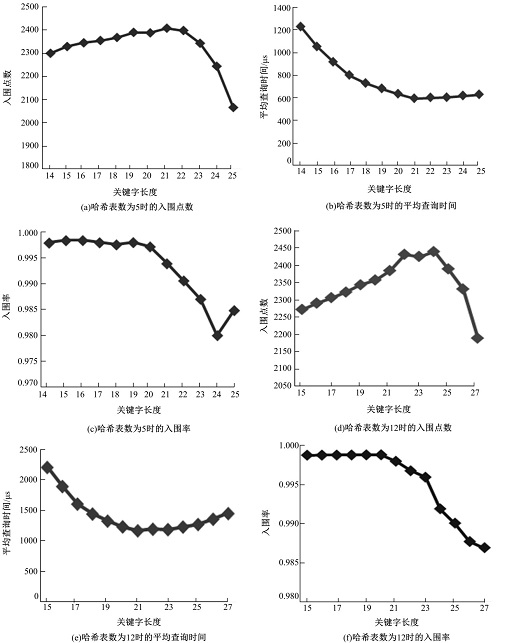 | 图2 不同关键字长度时本文算法的性能Fig.2 Performance of proposed method under different length of key |
由图2(a)(b)(c)可知:随着关键字长度的增加, 入围点数先增加后减小, 入围率逐渐减少, 平均查找时间逐渐减少, 在关键字长度为20左右时, 入围点数最多, 入围率最高, 平均查询时间适中; 由图2(d)(e)(f)可知:随着关键字长度的增加, 入围点数先增加后减小, 入围率逐渐减少, 平均查询时间逐渐减少, 在关键字长度为20左右时, 入围点数最多, 入围率最高, 平均查询时间适中。
3.2.3 不同算法性能的对比
图3为LINEAR、MPLSH和HCT算法, 与本文BMLSH算法的性能对比。其中, 提取bike图库中6张图像的ORB特征数, 如表3所示。本文以bike1作为源图像提取ORB特征作为训练特征, 其他图像(bike2、bike3、bike4、bike5和bike6)提取的ORB特征作为查询特征, bike图库中的图像随着编号的增加其模糊程度也增加。在相同的情况下, 图3(a)表明本文算法的入围点数比其他算法多40个以上; 图3(b)表明, 随着查询特征的增加, 本文算法所需查询时间的增加程度小, 所需的查询时间少; 图3(c)表明本文算法的查询入围率大于95.8%, 与其他算法相当; 图3(d)表明本文算法平均投影误差与其他算法接近。
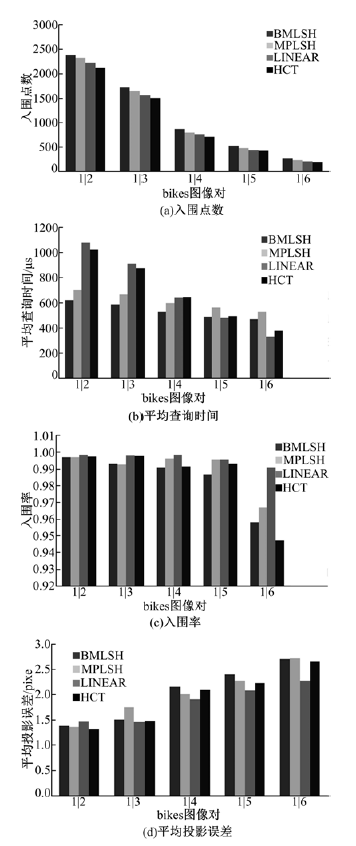 | 图3 使用bike图库时不同算法的性能Fig.3 Performance of different algorithms test bike dataset |
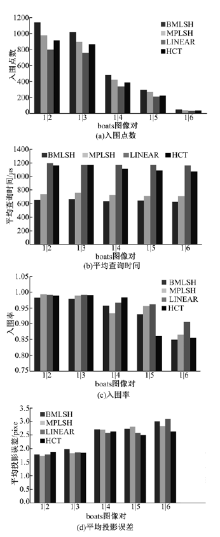
图4为使用boat图库, 不同算法的性能对比。提取boat图库中6张图像的ORB特征数, 如表3所示。boat1~boat6图像是不同视角不同旋转角度下拍摄的图像。在相同的情况下, 图4(a)表明本文算法的入围点数多比其他算法至少多11个; 图4(b)表明, 在查询特征数目一定时, 本文算法所需查询时间少且稳定, 为622.899~664.01 μ s; 图4(c)表明本文算法的查询入围率大于85%, 与其他算法相当; 图4(d)表明本文算法平均投影误差与其他算法接近。
 | 图4 使用boat图库时不同算法的性能Fig.4 Performance of different algorithms test boat dataset |
3.2.4 特征匹配效果对比
图5为本文BMLSH算法与其他算法的入围点连线效果图。实验使用boat图库, 提取boat1和boat2图像的ORB特征分别为1500和1497个。本文BMLSH算法搜索到的入围点数为330个, MPLSH算法搜到295个, LINEAR算法搜到239个, HCT算法搜索到267个。比较入围点连线图5(a)与图5(b)(c)(d)可知, 本文BMLSH算法的入围点连线比较稠密, 匹配入围点数较多。
 | 图5 不同算法的入围点连线图Fig.5 Inliers connection diagram of different algorithms |
表4为不同算法使用luven图库查询匹配特征的入围点数, 1|2是指luven1和luven2组成的图像对。表5为不同算法使用luven图库查询匹配特征的平均查询时间。由表5可知:本文BMLSH算法查询的入围点数多, 比其他算法多9个以上, 平均查询时间短, 在666.046 μ s以下。表6为不同算法使用trees图库查询匹配特征的入围点数。表7是不同算法使用trees图库查询匹配特征的平均查询时间。由表7可知:本文BMLSH算法的查询入围点数多, 平均查询时间最短, 在636.796 μ s以下。
| 表4 luven 图库不同算法的入围点数 Table 4 Number of inliers for different algorithms under luven dataset |
| 表5 luven图库不同算法的平均查询时间 Table 5 Average query time by different algorithms under luven dataset μ s |
| 表6 trees图库不同算法的入围点数 Table 6 Number of inliers for different algorithms under trees dataset |
| 表7 trees图库不同算法的平均查询时间 Table 7 Average query time by different algorithms under trees dataset μ s |
针对线性搜索、层次聚类树等查询匹配二进制特征时, 效率低和入围点数少的问题, 本文提出了快速计算位图(FCBM)算法以及位图局部敏感哈希(BMLSH)算法。本文算法可用于匹配二进制特征的搜索、二进制特征识别、图像定位和拼接等领域。实验证明:在相同条件下, 本文算法的消耗时间少, 搜索到的入围点数多, 入围率和平均重投影误差与其他算法接近, 消耗的内存空间与多探头局部敏感哈希算法相当。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|