




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于空间矢量模型的图像分类方法
[陈绵书 , 苏越, 桑爱军, 李培鹏]
, 苏越, 桑爱军, 李培鹏]
, 苏越, 桑爱军, 李培鹏]
|
|


作者简介:陈绵书(1973-),男,副教授,博士.研究方向:图像处理,人工智能.E-mail:chenms@jlu.edu.cn
针对词袋模型视觉单词没有考虑空间信息的不足,提出了一种基于视觉单词间空间位置信息的空间矢量模型。该模型利用视觉单词的空间位置信息,采用图像空间矢量模型对图像进行表述,从而达到了更好的分类效果。实验在两个标准图像数据集Caltech-101和Caltech-256上进行,分别采用支持向量机(SVM)和K最近邻分类器(KNN)对其进行分类。实验表明,空间矢量模型有效地提高了平均分类正确率(ACA)和平均类别准确率(ACP),具有很好的分类效果。
A space vector model is proposed to overcome the lack of spatial location information in the bag-of-words model. The model turns visual words into vector model using the space location information of visual words to represent image, thereby achieves better classification performance. Experiments are carried out on two standard image datasets Caltech-101 and Caltech-256, respectively, with Support Vector Machine (SVM) and K-Nearest Neighbor (KNN) classifiers. The results show that the space vector model can effectively improve the Average Classification Accuracy (ACA) and Average Category Precision (ACP), and has a good classification effect.
随着互联网中图像数量的急速增长, 如何准确且快速地对图像进行分类显然已经成为了一个热门领域。而源自于文本领域的图像分类模型— 词袋模型(Bag-of-words, BOW)[1]作为一种信息检索算法, 在文本分类领域有着广泛的应用。BOW模型忽略掉一个文档的结构、语法和语序等, 仅仅将其看作是若干个独立单词的集合, 文档中任意位置出现的单词, 均不受该文档的语义影响而单独存在。将这一原理与图像相结合, 认为图像是由一些相互无关联的视觉单词组成。具体的做法为:先提取图像的SIFT[2, 3](Scale-invariant feature transform)特征, 之后把视觉特征转换为一系列的图像视觉单词, 最后, 根据每一个视觉单词在图像中出现的概率来绘制直方图。视觉单词出现的频率越高, 相应的概率值就越大。因此, 词袋模型不仅具有文本匹配高效简洁的特点, 而且原理简单, 易于编程和实际操作。然而, 词袋模型没有考虑到视觉单词之间的空间位置信息。研究表明, 视觉单词间的空间位置信息有助于提高图像的表述能力。Lazebnik等[4]利用金字塔匹配核函数, 提出了SPM模型(Spatial pyramid matching); Wu等[5]提出了视觉语言模型(Visual language model, VLM); Jiang等[6]利用随机划分图像来提高分类性能。然而以上研究均没有考虑到全局信息, 且存在大量冗余的短语信息, 从而严重地影响到计算速率。考虑以上不足, 本文提出了一种基于视觉单词间空间位置信息的空间矢量模型。
在以往的图像分类应用中, BOW模型取得了不错的分类效果。但是在这些应用中, 均是将单词视为独立的存在, 彼此间没有联系且完全独立。可事实上, 通常一幅图像中出现的单词都是有结构联系的, 不可能完全独立, 所以这种单词之间完全独立的假设显然不成立。由此, 这里提出了结合视觉单词空间信息的图像分类方法。实验结果表明, 这种方法能够有效地提高图像分类的平均分类正确率(Average classification accuracy, ACA)和平均类别准确率(Average category precision, ACP)。
对图像进行SIFT特征提取、聚类, 以生成视觉单词。然后利用视觉单词的空间位置信息, 将图像表达为空间位置模型。对于一幅图像来说, 其表示为:
式中:
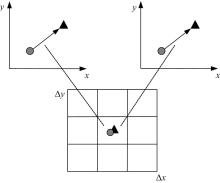
这里需明确两个重要的问题:①视觉单词之间的联系是什么; ②应该怎样准确地表达这种联系。空间位置矩阵最大的问题就是不包含视觉单词之间的空间位置信息。考虑到视觉单词的空间关系, 两两视觉单词能够构成矢量, 形成一对单词对。这样一来图像就能够映射成空间矢量矩阵。如图1所示, 设CUP图像提取出3个视觉单词分别为
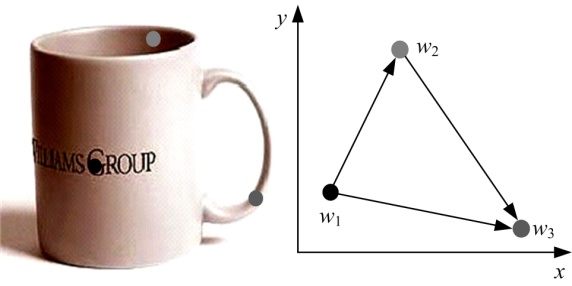 | 图1 空间位置模型与空间矢量模型Fig.1 Spatial position model and space vector model |
同理, 如果一幅图像的视觉单词有
式中:
将图像表示为空间矢量矩阵后, 虽然考虑到了视觉单词之间的联系, 但仍有两个问题有待商榷。
(1)如何构建一个合理的空间矢量模型。对于一幅图像, 可以获得大量空间矢量, 而其中只有非常有限的矢量是有关的。由于需要的视觉单词对是该幅图像与其他图像共同出现的单词对, 所以可以通过对比该幅图像的所有矢量与其他图像矢量的距离来选取有关矢量。若两个矢量间的距离大于某一阈值, 就将该矢量舍弃, 反之, 则保留。不过这种方法显然需要很大的计算量。假设两幅图像分别有
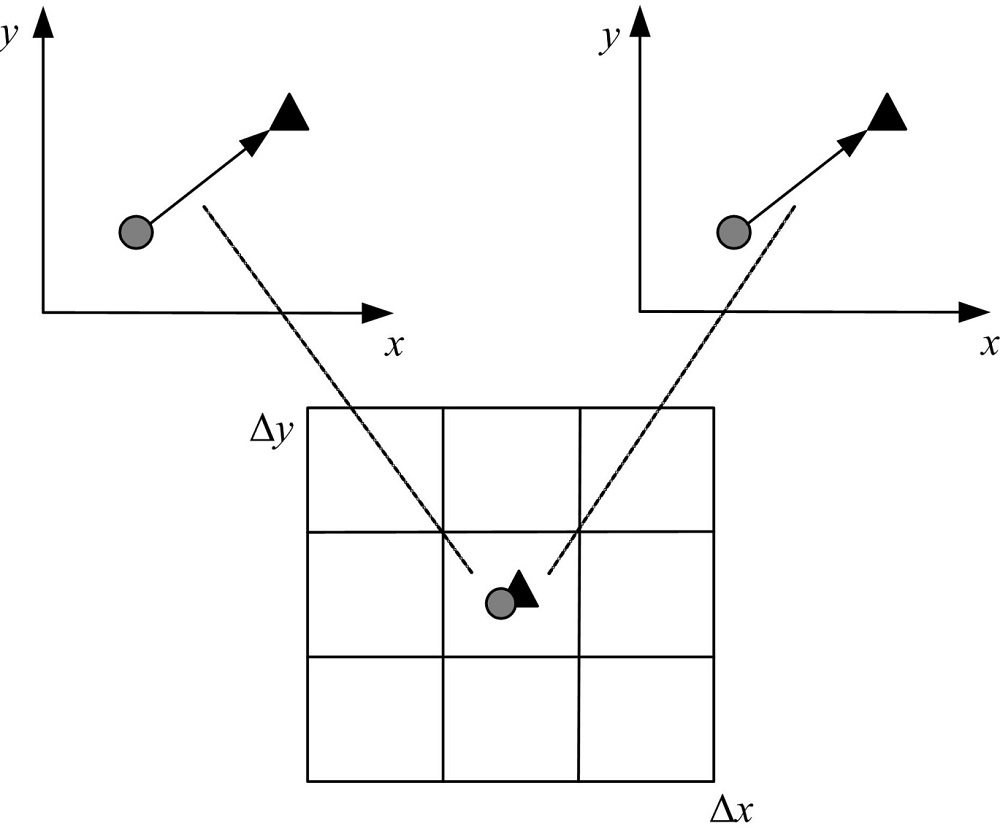 | 图2 矢量位移对比Fig.2 Comparison of vector displacement |
(2)如何利用空间矢量模型进行分类。本文使用支持向量机(Support vector machine, SVM)[7]和K最近邻分类器(K-nearest neighbor, KNN)[8]对图像进行分类, 分别提出两种不同的分类方法。
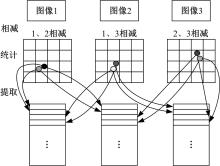
图3为有效空间矢量矩阵的构建过程图, 具体包括以下4个步骤。
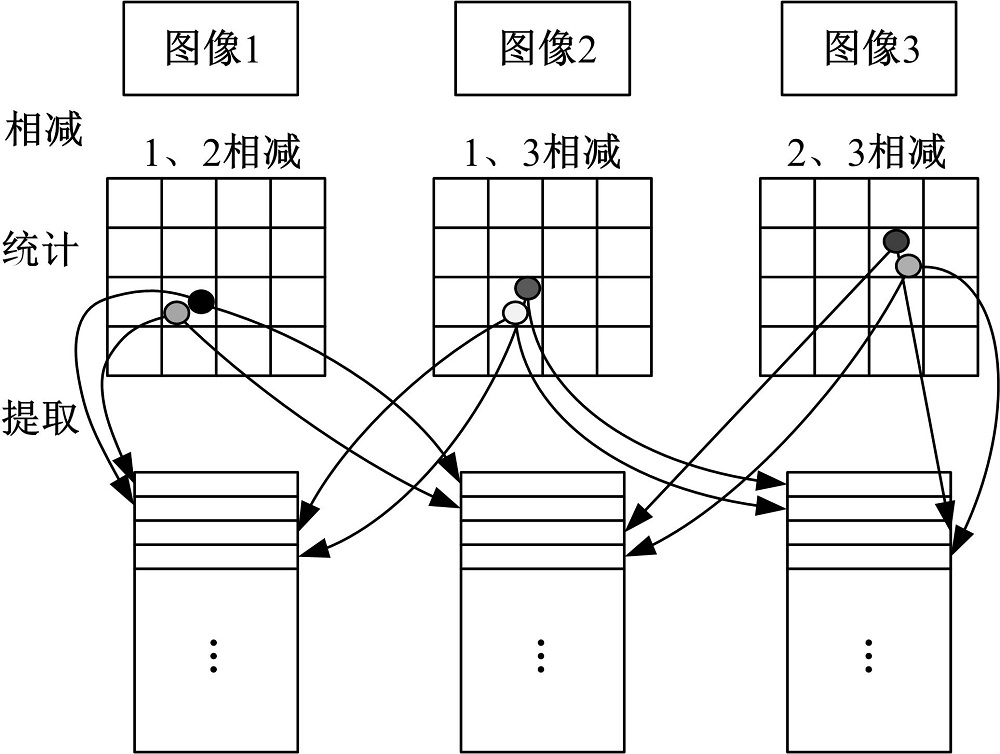 | 图3 有效空间矢量矩阵的构建Fig.3 Structure of valid space vector matrix |
(1)相减
将图像库中不同图像间相同的单词空间位置两两相减。这里假定有分别包含
式中:
假设
(2)统计
假设某网格中有n个点, 若n=2, 那么视觉单词对的个数为1; 若n< 2, 那么视觉单词对的个数为0; 若n> 2, 那么单词对的个数为
(3)提取
提取单词对个数不小于2的点, 并保存到对应的空间矢量矩阵中。假设
同理, 将
以此类推, 依次提取
(4)消除重复
由于总会出现某一图像的矢量与其他图像相同的情况, 所以需要去除
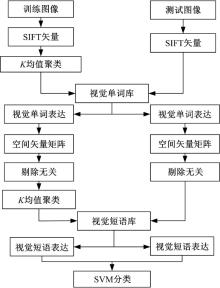
基于SVM分类器的图像分类包括3个步骤:建立视觉短语库、图像表达和分类判决。
2.1.1 建立视觉短语库
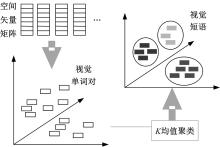
训练集图像的视觉单词经过空间矢量转化后, 每一幅图像都会表示成一个
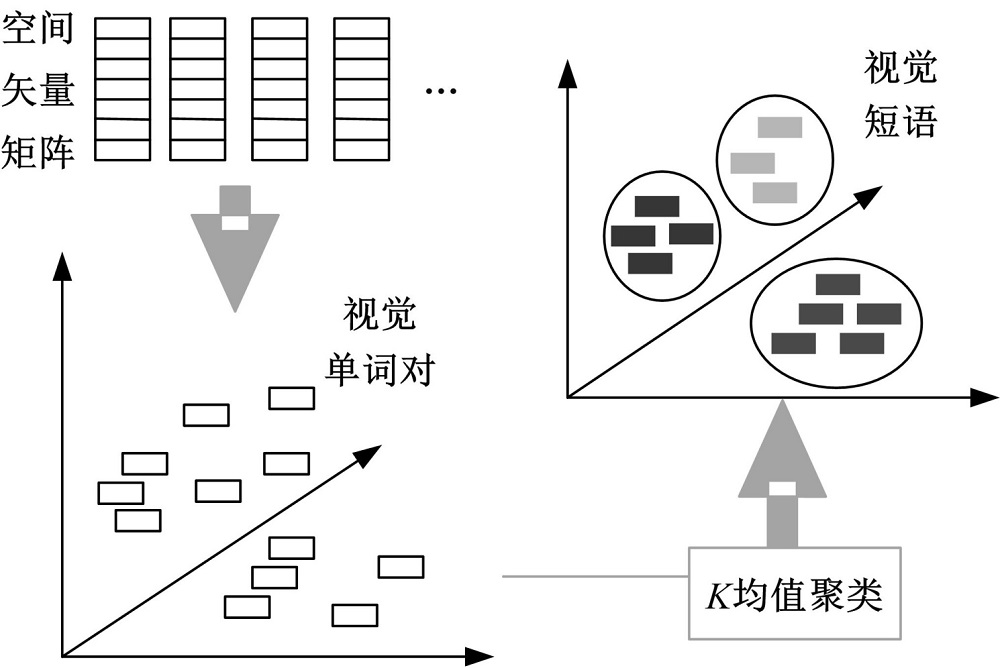 | 图4 视觉短语库构造过程Fig.4 Structure of visual phrase lexicon |
2.1.2 图像表达
假设一个
视觉语言模型的主要原理包括:
(1)对2个特征集
(2)在层
(3)
在后文中, 把
(4)统计每层
(5)两个点集
式中:
视觉语言模型的构建过程主要包括以下两个步骤。
(1)如图5所示, 对图像特征聚类映射后, 提取视觉单词直方图。之后将视觉单词转化为空间矢量矩阵, 提取视觉短语直方图, 如图6所示。
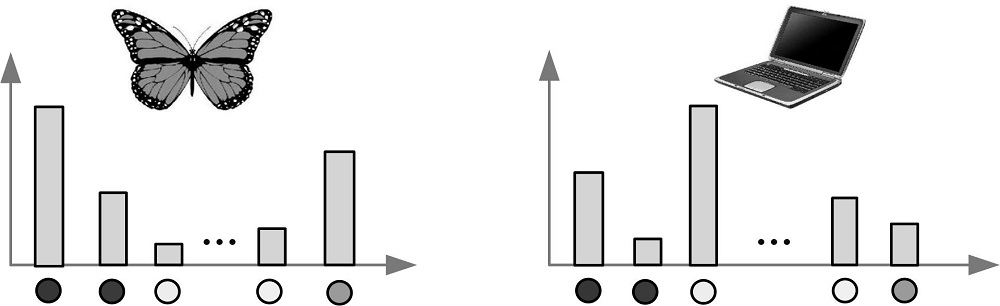 | 图5 视觉单词直方图Fig.5 Histogram of visual words |
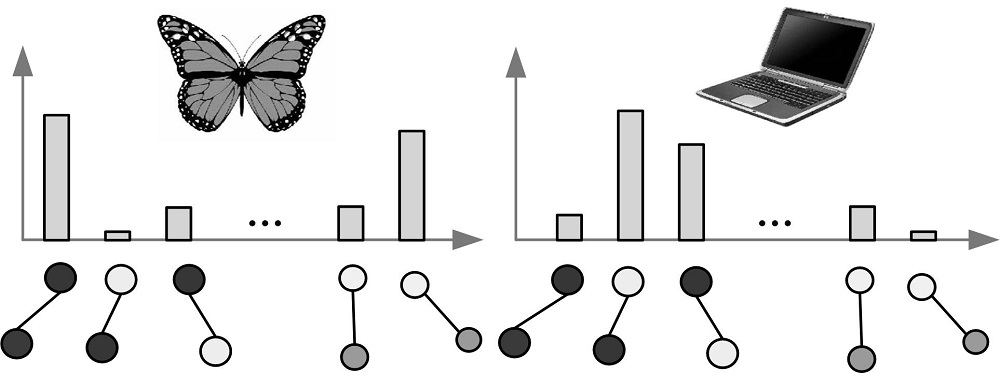 | 图6 视觉短语直方图Fig.6 Histogram of visual phrase |
(2)将两个层的直方图首尾连接, 同时赋予每个层相应的权重, 如图7所示。
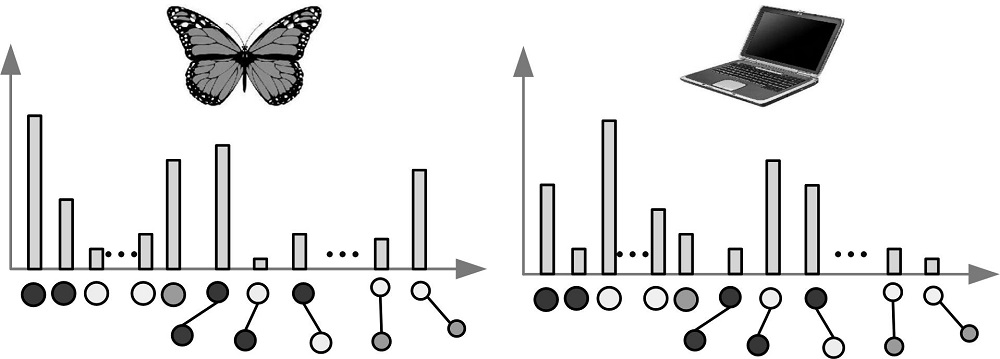 | 图7 视觉语言直方图Fig.7 Histogram of visual language |
2.1.3 分类判决
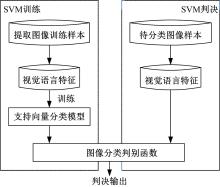
基于SVM分类器的具体训练和判决过程如图8所示。
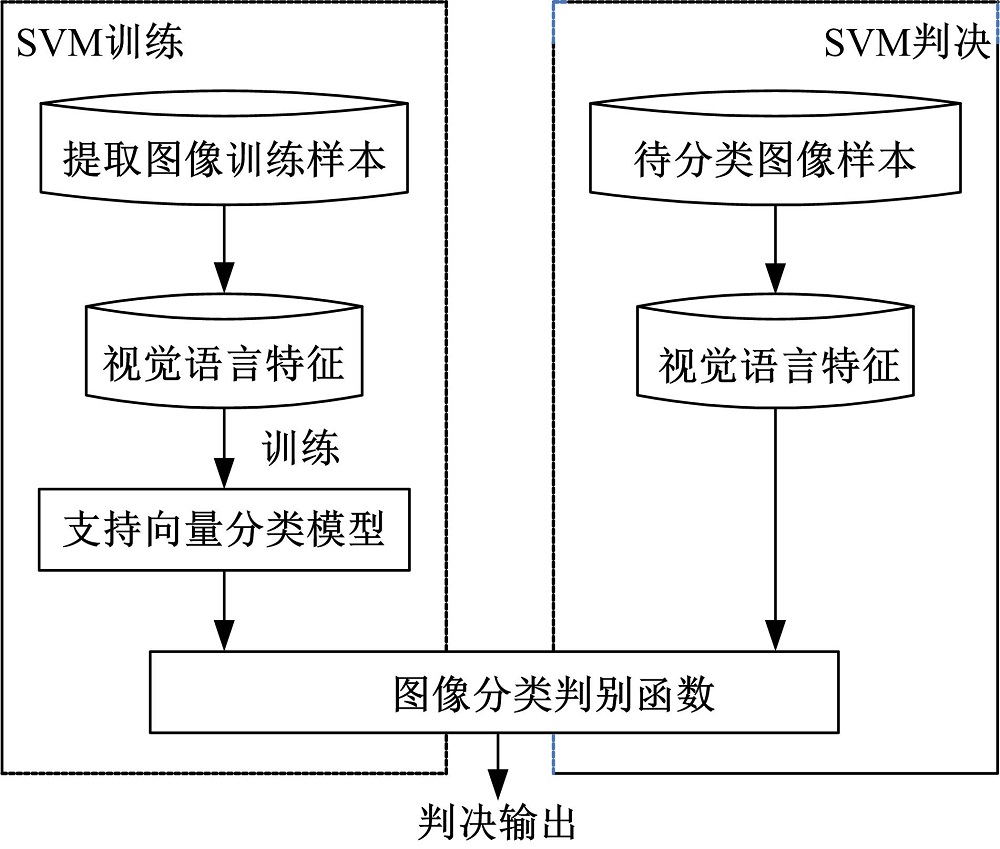 | 图8 SVM分类器过程图Fig.8 Flow diagram of SVM classification |
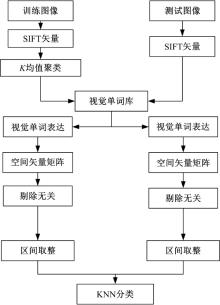
根据KNN分类原理, 利用空间矢量矩阵对图像进行分类:首先, 对所有训练图像的空间矢量矩阵进行量化; 然后, 设
2.2.1 量化统计
首先, 分别对
式中:
2.2.2 参数选取
(1)
本文利用交叉验证法(cross-validate)[9, 10]选取最佳
(2)权重的选取
如果认定各特征的权重都相同, 那么会大大降低图像的分类效果。本文利用与测试图像的空间矢量矩阵相同行的数量来分配权重。然后将权重累加, 选定累加值最高的类别作为样本的类别标签。
将相同行个数的平方值作为权重。设训练数据集包含2个标签,
取权重后的概率为:
判为标签2的概率为:
取权重后的概率为:
式中:
2.2.3 分类判决
通过参数的选取, 确定了基于词袋模型的最佳K值(KB)和基于空间矢量矩阵的最佳K值(KM)。这里假定训练集包括2个标签, 那么对于一幅测试图像, 判为标签1的概率为:
判为标签2的概率为:
比较式(16)和式(17)的大小, 将概率值相对较高的标签作为最终测试图像的分类类别。
在图像分类中, 有些发生旋转的图像会对分类效果造成影响。如图9所示, 为了消除这种影响, 本文提出了矢量模的方法。由于两两单词构成一个矢量, 所以当图像旋转时, 矢量的长度不变。因此对于一个
 | 图9 图像旋转的分析Fig.9 Analysis of image rotation |
在构建有效的空间矢量矩阵后, 分别利用KNN和SVM分类器进行分类。
本次实验在Caltech 101数据集和Caltech 256数据集中[11]分别选取8个类别, 并将数据集分为测试图像和训练图像两部分。从Caltech 101数据集中取8个类别的图像(Faces_easy、向日葵、摩托车、蝴蝶、笔记本电脑、双栀船、盆景、袋鼠)进行分类实验, 实验分为二类类别(Faces_easy、向日葵)、四类类别(Faces_easy、向日葵、摩托车、蝴蝶)、六类类别(Faces_easy、向日葵、摩托车、蝴蝶、笔记本、双栀船)和八类类别(Faces_easy、向日葵、摩托车、蝴蝶、笔记本、双栀船、盆景、袋鼠); 从Caltech 256数据集取8个类别的图像(ak47、双筒望远镜、骆驼、鸭子、烟火、三角钢琴、火星、网球鞋)进行分类实验, 实验分为二类类别(ak47、双筒望远镜)、四类类别(ak47、双筒望远镜、骆驼、鸭子)、六类类别(ak47、双筒望远镜、骆驼、鸭子、烟火、三角钢琴)和八类类别(ak47、双筒望远镜、骆驼、鸭子、烟火、三角钢琴、火星、网球鞋), 所有实验都重复10次取其统计平均, 并对结果进行分析。评价标准采用平均分类正确率(ACA)和平均类别准确率(ACP)。
这里分别基于词袋模型、空间金字塔、空间矢量模型(SpVM)、具有旋转不变性的空间矢量模型(SpVM-ROT)进行实验, 实验过程分别如图10和图11所示。
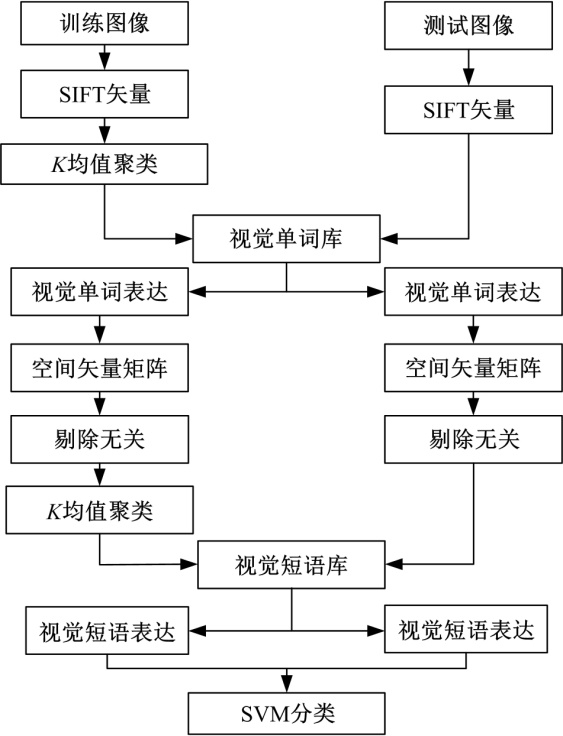 | 图10 基于SVM分类的框架图Fig.10 Frame diagram of classification based on SVM |
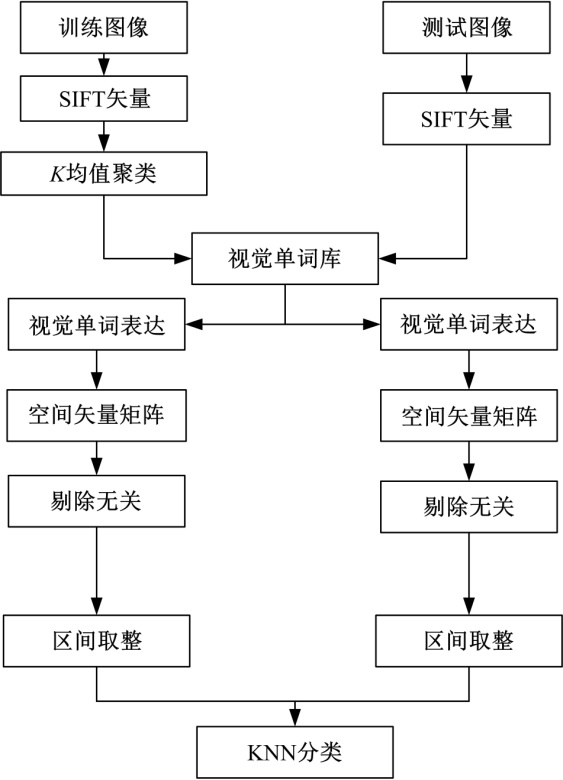 | 图11 基于KNN分类的框架图Fig.11 Frame diagram of classification based on KNN |
4.1.1 参数的选择
(1)网格间距的选择
网格间距的选择对最终的分类结果有很大的影响。若网格间距太小, 那么落入同一网格的单词会很少, 获得的样本太少; 若网格间距太大, 那么落入同一网格的单词会很多, 缺乏了准确性。所以选择一个合适的网格间距尤为重要。这里经验性地选择间距为3。
(2)权重的选择
视觉语言直方图分为两层:1层是视觉单词直方图; 2层是视觉短语直方图。两层的权重分别为
(3)聚类
本文设置不同的
4.1.2 实验结果
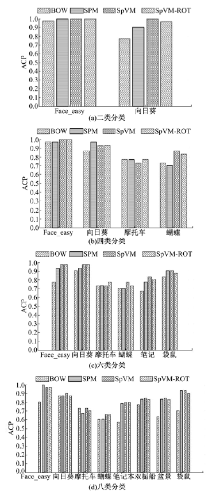
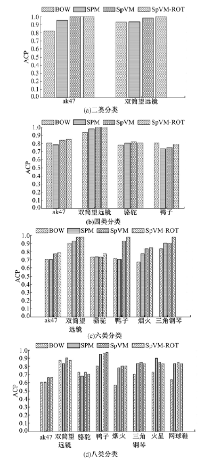
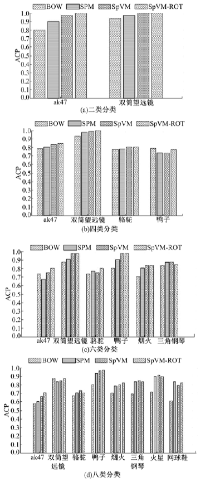
Caltech-101数据集和Caltech-256数据集的ACA和ACP分类结果分别如表1、表2和图12、图13所示。
| 表1 Caltech-101基于SVM的平均分类正确率 Table 1 ACA in Caltech-101 data collection based on SVM % |
| 表2 Caltech-256基于SVM的平均分类正确率 Table 2 ACA in Caltech-256 data collection based on SVM % |
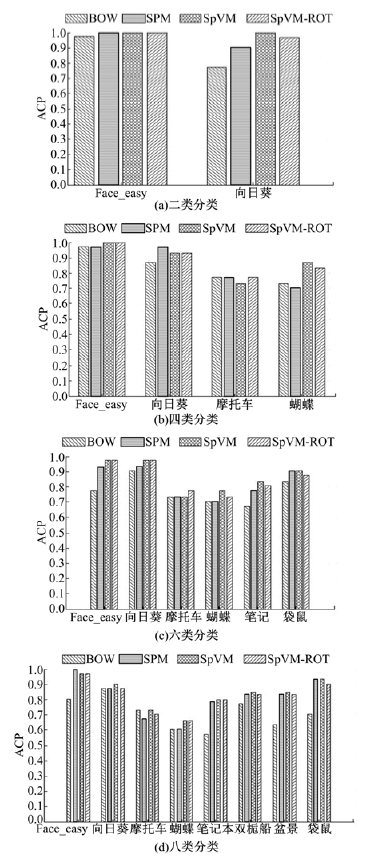 | 图12 Caltech-101基于SVM的平均类别准确率Fig.12 ACP in Caltech-101 data collection based on SVM |
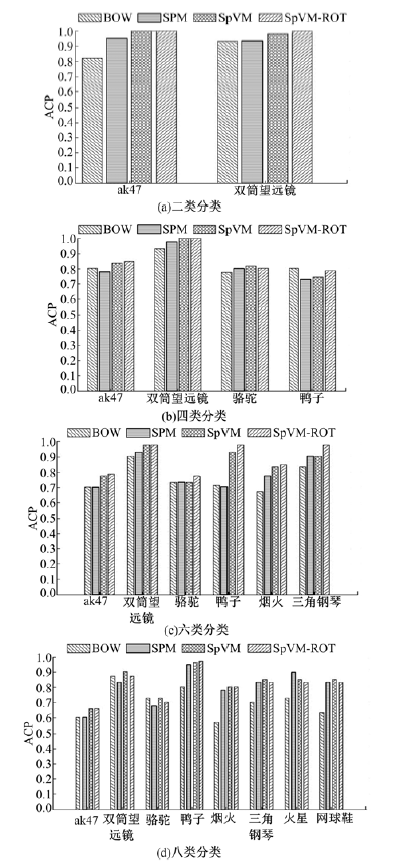 | 图13 Caltech-256基于SVM的平均类别准确率Fig.13 ACP in Caltech-256 data collection based on SVM |
4.2.1 参数的选择
通过交叉验证选择
4.2.2 实验结果
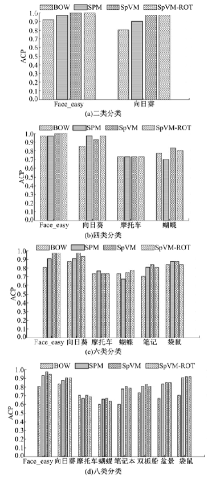
Caltech-101数据集和Caltech-256数据集的ACA和ACP分类结果分别如表3、表4和图14、图15所示。
| 表3 Caltech-101基于KNN的平均分类正确率 Table 3 ACA in Caltech-101 data collection based on KNN % |
| 表4 Caltech-256基于KNN的平均分类正确率 Table 4 ACA in Caltech-256 data collection based on KNN % |
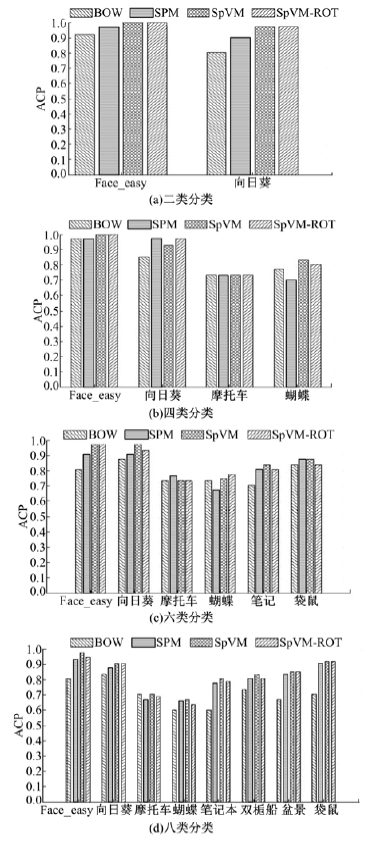 | 图14 Caltech-101基于KNN的平均类别准确率Fig.14 ACP in Caltech-101 data collection based on KNN |
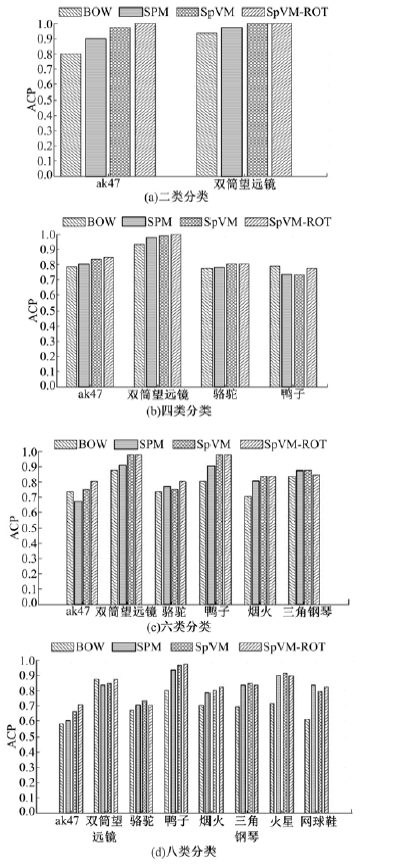 | 图15 Caltech-256基于KNN的平均类别准确率Fig.15 ACP in Caltech-256 data collection based on KNN |
这里对分类错误的图像进行统计和分析。如图16所示, 分类错误的图像主要包括两类:一是受光照影响较大的图像, 可以考虑通过图像滤波或图像增强等对图像进行预处理; 二是背景较为杂乱或者物体本身绘有花纹的图像, 这类影响具有不可避免性, 所以如何避免此类干扰的影响, 从而提高分类效果, 将是下一步研究的重点。另外, 当考虑旋转不变性时, 有些分类准确率会出现不升反降的现象, 这种现象主要发生在Caltech 101数据集上。这是因为Caltech 101数据集中很少有发生旋转的图像, 图像都相对简单, 从而导致聚类后的视觉单词对之间难以分辨; 而在图像数据复杂的Caltech 256数据集上则表现良好。
 | 图16 错误分类图像示例Fig.16 Misclassification image samples |
提出了一种基于视觉单词间空间位置信息的空间矢量模型, 并基于两种分类器提出了不同的分类方法:当使用SVM分类时, 将空间矢量矩阵转化为视觉语言模型, 利用视觉语言直方图特征进行分类; 当使用KNN分类时, 利用空间矢量矩阵具有相同行的个数, 通过选择最佳的
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|