
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于增强核极限学习机的专业选择智能系统
[黄辉1, 2  , 冯西安
, 冯西安1 , 魏燕3 , 许驰3 , 陈慧灵2 ]
, 冯西安, 许驰|
|


作者简介:黄辉(1982-),男, 实验师, 博士研究生.研究方向:图像处理,机器学习.E-mail:huanghui@wzu.edu.cn
基于粒子群优化(PSO)的增强型核极限学习机(KELM)提出了一种有效的预测模型PSO-KELM来辅助第二专业选择。在PSO-KELM 中,PSO策略确定KELM的最佳参数。PSO-KELM与其他两个竞争方法在学生专业选择数据上通过10折交叉验证方案进行比较,这两个方法分别是支持向量机和网格搜索技术优化的KELM。结果表明了本文预测模型在分类精度、受试者工作特征曲线面积(AUC)、灵敏度和特异性方面的优越性。
This paper proposes an effective prediction model for choosing the second major based on the Particle Swarm Optimization (PSO) enhanced Kernel Extreme Learning Machine (KELM), which is called PSO-KELM model. In this model, the PSO strategy is adopted to adaptively determine the optimal parameters in KELM. The PSO-KELM model is compared with other two competitive methods, including Support Vector Machine (SVM) and a KELM is optimized by grid search technique, on a major selection dataset via a 10-fold cross validation scheme. The results clearly confirm the superiority of the proposed PSO-KELM model in classification accuracy, area under the receiver operating characteristic curve (AUC), sensitivity and specificity.
目前, 数据挖掘技术在高等教育教学领域中的应用逐渐受到重视, 在学生选课、成绩预测、职业指导等方面已经有较多的应用。Kardan等[1]探讨了在网络学习背景下通过数据挖掘技术来预测学生课程选择的情况。Guo[2]提出用统计分析和神经网络建立动态模型来分析和预测学生的课程满意度。结果表明, 在预测学生课程满意度时, 多层感知器模型优于线性回归分析。Campagni等[3]提出了一种基于聚类和序列模式的高校毕业生职业生涯分析方法, 有助于研究生职业生涯规划。Huang等[4]分析了统计学、心理学等评价理论, 提出了基于粗糙集的关联规则挖掘算法来进行第二专业选择。仿真结果表明, 他们的方法在软件工程、网络技术、程序设计3个专业的评测上具有较高的精度。
为了提高学生第二专业选择的效率, 本文提出并验证了一种基于粒子群增强的核极限学习机(Particle swarm optimization enhanced kernel extreme learning machine, PSO-KELM)方法。核极限学习机是在极限学习机(Extreme learning machine, ELM)[5, 6]基础上发展而来的, 是一种新的单隐层的前馈神经网络的学习算法。作为ELM的扩展, KELM克服了ELM由于随机权重导致的在不同试验中产生不同性能的缺点, 由于其良好的性能, KELM具有广泛的应用, 包括高光谱遥感影像分类、动作识别、二维轮廓重建、生物引擎性能优化、疾病诊断、故障诊断和破产预测等。目前, KELM尚未被应用于学生第二专业选择。一些研究[7, 8, 9]表明, KELM中的一些参数(如惩罚参数
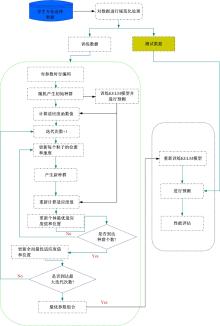
面向第二专业选择系统基于KELM构造, 其中输入数据是由一系列影响专业选择的因子组成, 在输入空间中的数据利用RBF核[13]映射到隐藏层的特征空间; 最优惩罚参数
 | 图1 基于粒子群优化的核极限学习机预测模型Fig.1 KELM prediction model based on PSO |
在PSO-KELM预测模型中, PSO优化KELM参数的步骤如下:
步骤1 初始化如下PSO算法参数:种群规模(pop)、最大迭代次数(maxi)、粒子位置(pos)、粒子速度(vel)和适应度(fit)。
式中:
步骤2 设置维度(
步骤3 将pos和fit赋值给局部最优位置(
步骤4 将最大的
步骤5 将具有
步骤6 更新
步骤7 更新
If
End If;
If
End If;
步骤8 通过比较
步骤9 通过比较最大的
步骤10 判断
步骤11 将
本研究所获得的数据来自温州科技职业学院, 以数字媒体专业三届共402位学生作为研究对象。该专业分为平面设计和影视制作两个专业方向。在第二学期结束后, 195位学生选择了平面设计专业方向, 207位学生选择了影视制作专业方向。本研究通过对学生性别、高考生类别、区域生源、文理科情况、志愿情况、基础课成绩、第三课堂参加情况、自考学习情况、专业方向关联基础课成绩等11个特征属性进行挖掘分析, 了解各属性的重要性及属性之间潜在的内在联系, 为实验准备必要的数据。表1为11个特征属性的具体描述。
| 表1 特征属性描述 Table 1 Description of data set |
为了验证本文PSO-KELM算法, 将该算法与其他两种高效的机器学习算法Grid-KELM和SVM进行对比。对于SVM, 利用文献[14]中实现的算法LIBSVM。数据在分类之前, 被缩放到[-1, 1]内, 实验环境基于AMD Athlon 64 X2双核处理器(2.6 GHz)和4 GB内存, 运行在Windows 7操作系统上。
k折交叉验证(CV)用于验证分类的性能来保证结果的无偏差, PSO-KELM的参数设置如下:迭代次数和粒度分别设置成100和25; 参数搜索范围:
为了评价面向第二专业选择的PSO-KELM算法, 本文主要考查4个指标:分类准确率(ACC)、ROC曲线下面积(AUC)、灵敏度(Sensitivity)和特异性(Specificity)。性能指标计算公式如下:
式中:
ROC曲线是一种图像化显示方法, 用于衡量Logistic模型的预测精度, 曲线显示模型的真阳性和假阳性率; AUC是ROC曲线下的面积, 是用来比较分类器在二分类问题上性能的最佳方法之一。
在该实验中, 本文评估了PSO-KELM模型在原始特征空间的有效性, PSO-KELM取得了平均81.25%的分类正确率, 80.38%的ROC曲线下面积, 82.85%的灵敏性和81.58%的特异性。此外, 观察到算法在每次交叉验证中可以自适应指定参数
为了分析PSO-KELM算法的收敛性, 本文记录了每一次迭代过程中, 分别在最佳适应度、局部最佳适应度和平均适应度下的分类准确率。图2分别显示了在10折交叉验证中, 第1、3、5、7折交叉验证下PSO-KELM算法的学习曲线。可以看出, 图2(d)中的Best fitness曲线在小于30次迭代后始终收敛到全局最优, 在第1~30次迭代过程中, 它们逐步提高, 在小于30次的某一次迭代后, 不再有显著的提高, 最终在第100次迭代, 即粒子达到停止标准(最大迭代次数)时终止。在演化初始阶段, 分类正确率适应度增长迅速; 在经过一定数量的迭代后缓慢增长; 在演化的后期, 适应度趋于稳定, 直到停止标准满足。这种现象表明, PSO-KELM算法能快速、有效地得到全局最优解。
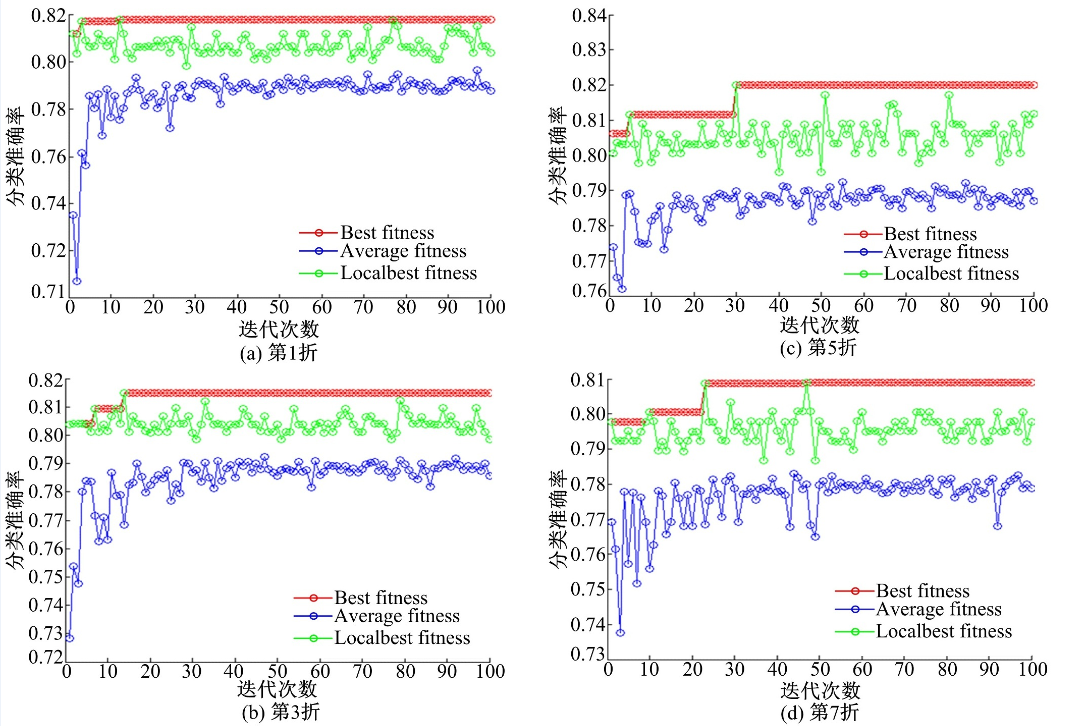 | 图2 在训练阶段第1、3、5、7折交叉验证的学习曲线Fig.2 Learning curves during training stage for folds 1, 3, 5 and 7 in 10-fold CV |
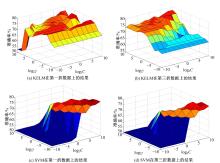
为了验证本文方法的有效性, 将其与两种高效的机器学习算法Grid-KELM和SVM进行比较。一种网格搜索技术用于获取Grid-KELM和SVM中RBF核函数的最优参数值, RBF核函数中的相关参数C和
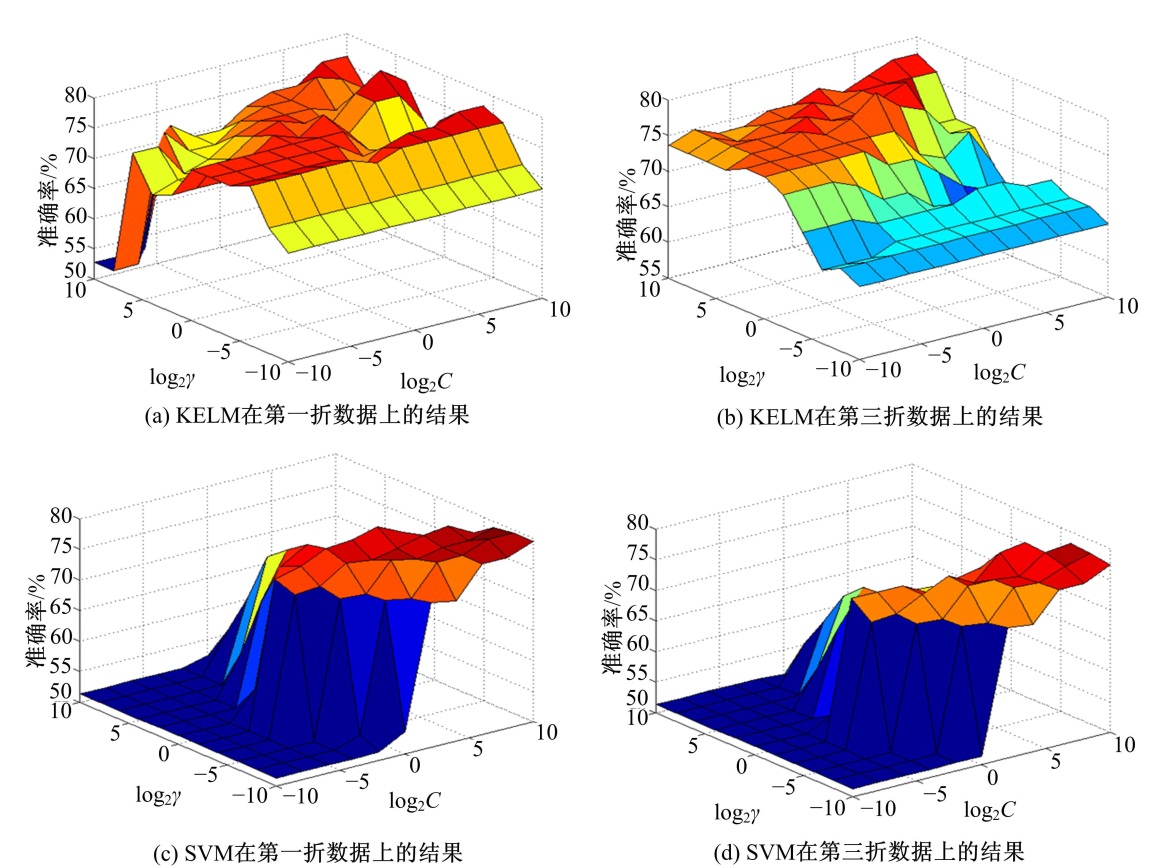 | 图3 通过网格搜索获得参数的KELM和SVM训练准确率曲面图Fig.3 Training accuracy surfaces of Grid-KELM and SVM with parameters obtained by grid search for several folds |
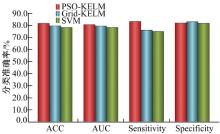
Grid-KELM模型获得的平均分类准确率、ROC曲线下面积、灵敏度和特异性分别为79.56%、79.49%、76.02%和82.96%; SVM模型获得的平均分类准确率、ROC曲线下面积、灵敏度和特异性分别为78.36%、78.31%、74.89%和81.71%。如图4所示, 可以看到, PSO-KELM模型在分类准确率、ROC曲线下面积和灵敏度上超过SVM和Grid-KELM, PSO-KELM的特异性也与其他两种方法相近, 该方法的优异性能可能是由于PSO辅助KELM分类器自动检测最优参数对从而达到最高分类性能。
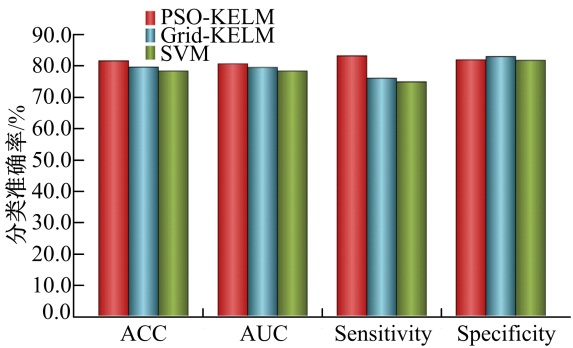 | 图4 不同方法在ACC, AUC, sensitivity和specificity方面的分类性能比较Fig.4 Classification performance obtained by different algorithms in terms of ACC, AUC, sensitivity, and specificity |
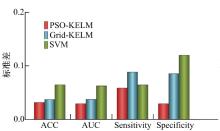
3种方法的标准差如图5所示, 从图5可以看出:在4个评价指标上PSO-KELM的标准差比其他两种方法小得多; PSO-KELM在分类准确率、ROC曲线下面积和特异性方面胜过SVM, 并在灵敏度上比SVM获得略高的标准差值。比较结果显示:PSO-KELM在第二专业选择方面是最稳定和鲁棒的方法, Grid-KELM和SVM方法次之。
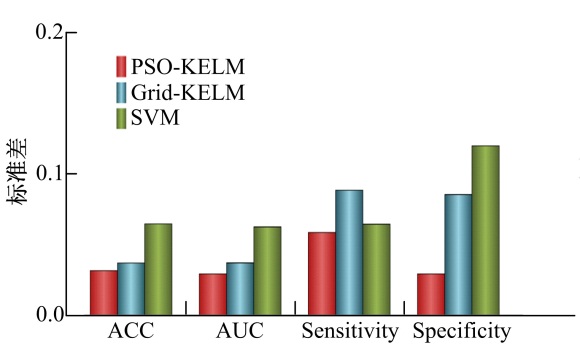 | 图5 不同方法在ACC, AUC, sensitivity和specificity方面的标准差比较Fig.5 Standard deviation obtained by different methods in terms of AGG, AUC, Sensitivity, and specificity |
探讨了应用KELM分类器辅助学生进行专业选择的可行性, 利用粒子群算法来搜索最优参数, 达到KELM模型的最高性能。实验结果表明, 在真实的数据集上, 开发的模型与其他两种先进的机器学习模型相比, 在分类准确率、ROC曲线下面积、灵敏度和特异性方面具有更好的性能。这表明本文开发的智能系统为学生第二专业选择提供了一种有前景的决策支持系统。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|