

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Corr-LDA模型的图像标注方法
[曹洁1  , 苏哲
, 苏哲1 , 李晓旭1, 2 ]
, 苏哲|
|


作者简介:曹洁(1966-),女,教授,博士生导师.研究方向:智能信息处理,信息融合.E-mail:caoj@lut.cn
针对现有图像标注方法大多将不同类别的图像置于同一主题空间下进行标注的不足,提出了一种新的图像标注方法,该方法以Corr-LDA模型为基础,将各类图像置于不同主题空间下,并为每个类别学习出适合该类的图像标注模型。在Labelme及UIUC-Sport数据集上的实验结果表明,本文方法的标注性能要优于其他方法。
Most of existing image annotation methods are based on the same topic space. In fact, categories are important information to determine the image annotation words, different classifications of images present different objects. In this paper, a new image annotation method based on Corr-LDA model is proposed. In this method all sorts of images are placed in different topic spaces, and the image annotation model suitable to each category is learned. Experiment results on Labelme and UIUC-Sport datasets show that the proposed method has better performance than other methods.
随着网络图像数量的飞速增长, 如何对海量图像数据进行高效的检索和管理, 成为当下亟需解决的问题。图像标注[1, 2]试图在底层特征与高层语义之间建立映射, 并利用二者的关联关系来确定待标注图像的语义概念, 它可以将图像检索转换为成熟的文本检索, 从而帮助用户准确地检索到所需图像信息。目前, 图像标注问题已成为计算机视觉领域中的一个研究热点。
作为解决图像标注问题的主流方法之一, 基于概率主题模型[3, 4, 5]的图像标注算法, 近年来受到研究人员和学者的广泛关注, 其图像标注工作可大致分为两类:①将标注放在比图像高一层次的水平上。例如:2010年, Putthividhya等[6]在sLDA模型和Corr-LDA[7]模型的基础上提出了sLDA-bin[8]模型, 该模型结合了sLDA模型和Corr-LDA模型的特点, 其中, sLDA为监督模型, 可用作标签变量的预测分析, Corr-LDA是图像标注的经典模型, 它的标注词从图像主题的子集产生, 以此来实现文本与图像的一致。2011年, 李志欣等[9]提出采用自适应不对称学习来融合图像及文本模态主题的图像标注方法; 2013年, Nguyen等[10]在会议上提出了基于多示例、多标签、多模态的标注方法, 该方法利用多模态信息来促进标注。②将图像和标注文本放置在同一水平上来学习图像和文本模态之间的关联。例如, 2003年, Blei等[7]在LDA模型的基础上提出了Mm-LDA模型, Mm-LDA模型的文本模态与图像模态的主题条件独立; 2005年, Li等[11]在LDA模型基础上, 利用已知类别信息进行模型训练, 并将各语义设置在同一主题空间中; 后来, 又提出了可同时分类、标注的概率生成模型[12]; 2009年, Wang等[13]提出了同时做图像分类和标注的Mca-sLDA模型; 2010年, Putthividhya等[8]提出了Tr-mmLDA模型, 该模型通过回归公式, 得到文本和图像主题的关联度; 2013年, Xu等[14]在ICME2013会议上提出了引入主题相关性的Corr-CTM图像标注模型。近年来, 基于神经网络的神经主题模型研究也相继展开。2012年, Larochelle和Lauly[15]共同提出DocNADE模型, 该模型是无监督神经网络主题模型, 用于文档的检索及分类任务; 2014年, Zheng等[16]在CVPR会议上, 提出了DocNADE的扩展模型SupDocNADE, 该模型可以对视觉单词、标注词及类别标签进行共同学习。
以上图像标注方法将不同类别的图像置于同一主题空间下进行标注。事实上, 类别和图像呈现的事物有着密切的联系:类别不同, 图像呈现的事物也不同。以“ 海岸” 类及“ 城市” 类图像为例:“ 海岸” 类图像主要呈现船、大海、沙滩等事物; “ 城市” 类图像则主要呈现道路、高楼、门、路标等事物。可见, 类别是确定图像标注文本的重要信息。因此, 本文提出了一种新的图像标注方法, 该方法以Corr-LDA模型为基础, 将各类图像置于不同主题空间下, 并为每个类别学习出适合该类的图像标注模型。在Labelme及UIUC-Sport数据集上的实验结果表明, 本文方法的标注性能要优于其他对比模型。
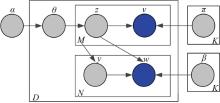
Corr-LDA是图像标注工作的经典模型, 其将LDA扩展成多模态模型, 灵活地把图像与其对应的文本联系起来。该模型不仅考虑了图像与其对应文本的条件关系, 也关注了它们之间的联合作用。Corr-LDA概率图模型如图1所示。
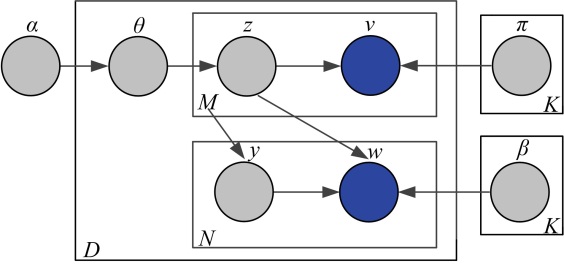 | 图1 Corr-LDA概率图模型Fig.1 Probabilistic graphical model of Corr-LDA |
Corr-LDA模型各参数意义:
具体生成过程如下:
(1)抽取一个主题比例
(2)对于每一个图像词
(a)抽取主题分配
(b)抽取图像单词
(3)对于每一个文本词wn, n∈ {1, 2, …, N}:
(a)抽取索引变量yn~Unif(1, 2, …, M);
(b)抽取文本单词
模型的联合概率分布如式(1)所示:
式中:
该模型生成过程分为两个阶段:抽取图像词汇阶段及抽取文本词汇阶段。
图像词汇抽取:模型以参数为
文本词汇抽取:按照上一阶段生成图像的主题比例, 选择一个主题生成标注词, 重复
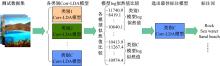
本文提出一种新的图像标注方法(Corr-LDA-C方法)。该方法依据类别信息, 将各类别图像置于不同的主题空间下, 具体方法为:
(1)模型训练过程:①依据类别信息, 将各类别图像输入到Corr-LDA模型中; ②确定最佳主题参数:各类别标注模型的最佳主题数通过其对应的
 | 图2 模型训练过程Fig.2 Model training process |
(2)类别模型确定及标注词预测过程:首先, 将测试数据集分别对已构建的各类别模型进行测试。然后, 采用log似然值比较方法(log似然值计算方法如式(4)所示)选出log似然值最大的标注模型来对测试图像进行标注词预测。最后, 确定出各图像语义标注词。具体如图3所示。
式中:
 | 图3 类别模型确定及标注词预测过程Fig.3 Class model determination and annotation words prediction process |
对于上述方法中的Corr-LDA模型, 本文采用变分EM算法求解其参数。模型训练测试过程及变分EM算法如下所示, 表中各参数意义与第一节(Corr-LDA概率主题模型)相同。
Model training test process
Train
input train dataset (1~C)
for scene = 1 to C do
invoke Variational EM
for topic k = 1 to 100 do
comparing F-measure value
end for
end for
output category models(1~C)
Test
input test dataset
for category model = 1 to C do
comparing likelihood value
end for
using model to predict words
output text annotation words
Variational EM
repeat
/* * * * E-Step* * * * /
for d = 1 to D do
initialize
repeat
update
until convergence
end for
/* * * * M-Step* * * * /
update
until convergence
为评价标注性能, 本文采用信息检索领域中的
式中:
为评估本文方法, 选择Labelme及UIUC-Sport作为实验数据集。
Labelme数据集包括 “ coast” 、“ forest” 、“ highway” 、“ insidecity” 、“ tallbuliding” 、“ street” 、“ mountain” 、“ opencountry” 8类自然场景图像, 每类场景包含200幅图像, 每幅图像大小为256× 256像素, 共有1600幅图像。UIUC-Sport数据集共有1792幅图像, 包括8类复杂事件类图像:255幅“ Rowing” 类、183幅“ Polo” 类, 190幅“ Snow Boarding” 类、190幅“ Sailing” 类、313幅“ Badminton” 类、137幅“ Bocce” 类、330幅“ Croquet” 类、194幅“ Rock Climbing” 类。每幅图像大小为400× 400像素。
对Labelme及UIUC-Sport数据集提取128维的SIFT特征。经过K-means聚类后, 得到长度为240的图像码书。对于文本词, 除去数据集中少于3 次的标注词, 构成长度为294的文本码书。最后, 对于Labelme数据集, 从每个类别中抽取100幅图像, 构成训练集对模型进行训练, 剩余图像数据用于测试; UIUC-Sport数据集分别从每个类别(每个类别图像数目从137到330不等)图像中随机抽取一半图像作为训练集, 剩余图像作为测试集。
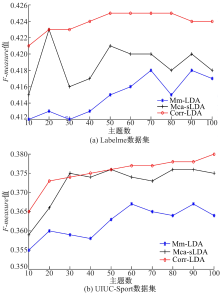
在Labelme及UIUC-Sport数据集上, 选取3组图像数据, 均匀地从10到100中选择10组主题, 分别计算Mm-LDA模型、Mca-sLDA模型及Corr-LDA模型的
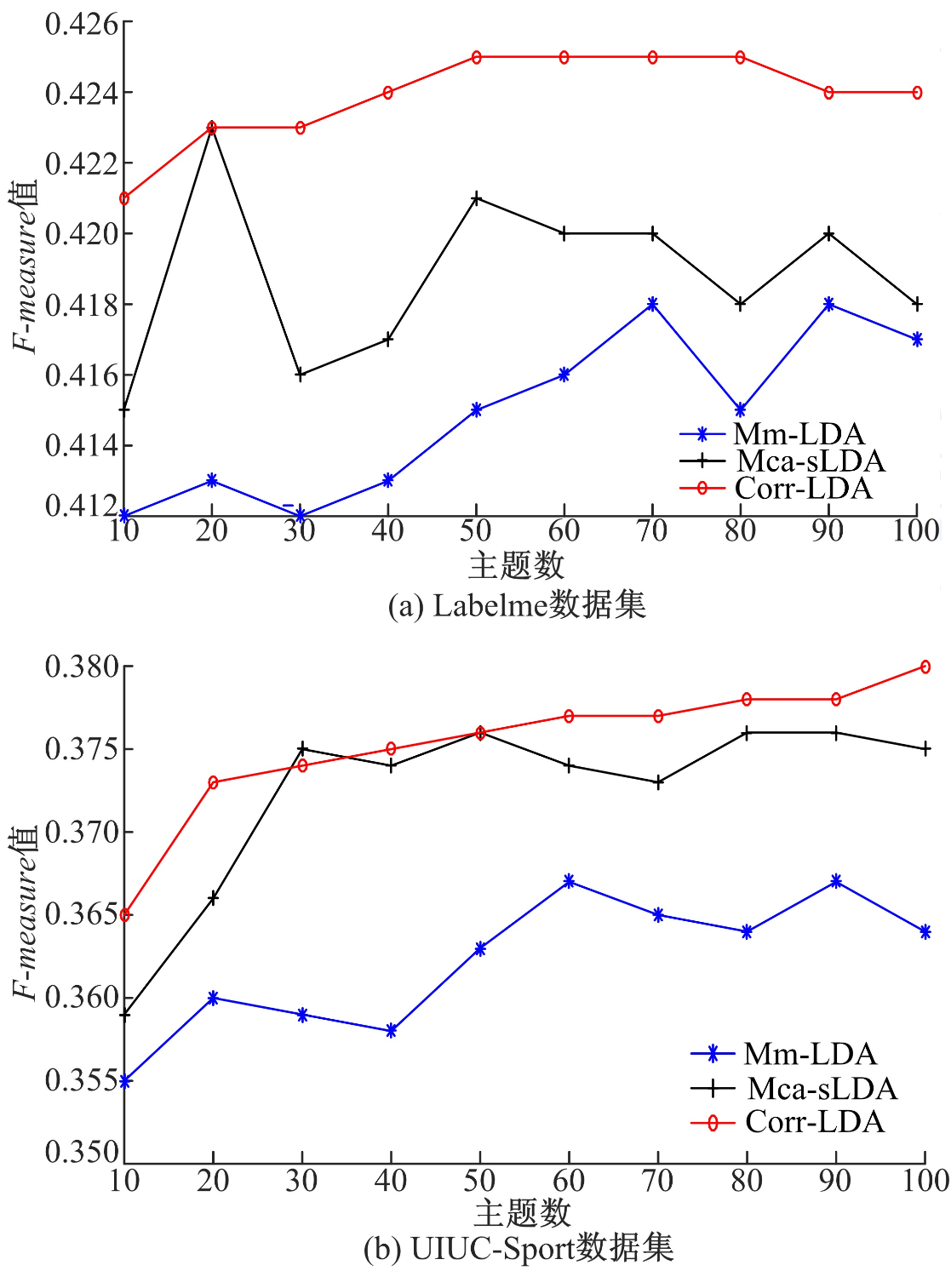 | 图4 各模型最佳F-measure值比较。Fig.4 Comparison of the best F-measure values of each model |
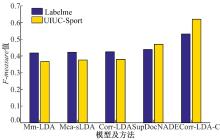
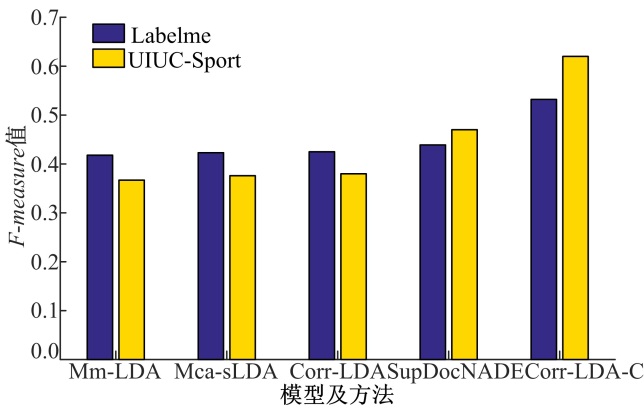 | 图5 Corr-LDA-C方法与各模型的最佳F-measure值比较Fig.5 Comparison of Corr-LDA-C method and the best F-measure value of each model |
图4(a)与图4(b)分别为Mm-LDA模型、Mca-sLDA模型和Corr-LDA模型在Labelme及UIUC-Sport数据集上的实验结果。由图4(a)可知, Mm-LDA模型、Mca-sLDA模型和Corr-LDA模型的最佳主题数分别为70、20、50, 其对应的
图5为Corr-LDA-C方法与各模型在Labelme及UIUC-Sport数据集上的最佳
在CVPR2014会议上, Zheng等[16]提出了SupDocNADE模型, 本文直接引用该工作的实验结果(在Labelme和UIUC-Sport数据集上, SupDocNADE模型
上述实验结果表明, 本文方法的
鉴于类别信息会影响图像的标注性能, 本节选取了UIUC-Sport数据集中的一组图像数据来举例说明, 如表1所示。
| 表1 各类别不同主题参数F-measure值比较 Table 1 Comparison of F-measure values of different themes in different scenarios |
表1为UIUC-Sport数据集中各类别在不同主题数下的
本文采用Matlab R2014a及Python2.7.10软件, 在索尼VAIO(Intel(R) Core(TM) i5-4200U CPU @1.60 GHz, RAM 4GB)64位Windows7旗舰版操作系统上实现。
Labelme及UIUC-Sport数据集构成图像码书及文本码书的长度分别为240及294。
Labelme数据集分别从8个类别(每个类别200幅图像)图像中随机抽取100张图像作为训练集, 剩余图像作为测试集; UIUC-Sport数据集分别从8个类别(每个类别图像数目从137~330不等)图像中随机抽取一半图像作为训练集, 剩余图像作为测试集。
Labelme数据集:
(1)Corr-LDA模型的训练及预测标注词共用时约为6.25 h(训练图像数据:800幅图像; 测试图像数据:800幅图像)。
(2)Corr-LDA-C方法训练各类别最佳主题参数标注模型及标注词预测共用时约为6.08 h(训练图像数据:每个类别100幅图像, 共800幅图像; 测试图像数据:800幅图像)。
UIUC-Sport数据集:
(1)Corr-LDA模型的训练及预测标注词共用时约为10.08 h(训练图像数据:894幅图像; 测试图像数据:898幅图像)。
(2)Corr-LDA-C方法训练各类别最佳主题参数标注模型及标注词预测共用时约为5.67 h(训练图像数据:每个类别输入68~156幅图像不等; 测试图像数据:898幅图像)。
在Labelme及UIUC-Sport数据集上, Corr-LDA-C方法比训练Corr-LDA模型及预测标注词的总体用时要分别短约0.17 h及4.41 h。其主要原因是:Corr-LDA-C方法依据类别信息, 将所有类别图像分类并置于不同主题空间下, 各类别模型训练的迭代次数相对较少, 模型参数收敛较快。因此, 本文Corr-LDA-C方法的总体用时较短。
图6为Corr-LDA模型及Corr-LDA-C方法在Labelme数据集的标注结果图。以第一行、第二幅 “ Tallbuilding” 类图像为例, 该图像的真实文本标注词(Ground truth)分别为:“ building” 、“ building crop” 、“ building occluded” 、“ sky” 、“ skyscraper occluded” 。其中, Corr-LDA模型标注正确的只有“ sky” 和“ building” 这两个标注词。与之相比较, Corr-LDA-C方法标注正确的文本词个数却达到4个, 分别为:“ sky” 、“ building occluded” 、“ skyscraper occluded” 、“ building” 。同样的, Corr-LDA-C方法在其他类别中也有较好的标注效果。可见, Corr-LDA-C方法的标注性能更佳。
 | 图6 Corr-LDA和Corr-LDA-C的标注结果比较Fig.6 Comparison of annotation results between Corr-LDA and Corr-LDA-C |
本文以Corr-LDA模型为基础, 提出一种新的图像标注方法。该方法将各类图像置于不同主题空间下, 并为每个类别学习出适合该类的图像标注模型。在Labelme及UIUC-Sport数据集上的实验结果表明:与Mm-LDA、Mca-sLDA、Corr-LDA模型及SupDocNADE模型相比, Corr-LDA-C方法具有更好的图像标注性能。此外, Corr-LDA-C方法中的Corr-LDA模型也可替换为其他概率主题模型来进行图像标注。因而, 该方法可看作为基于概率主题模型的图像标注框架。本文工作没有考虑码书尺寸对图像标注性能的影响。码书尺寸较大时, 可获得较强的辨别能力, 但会包含一定的冗余信息; 码书尺寸较小时, 可消除冗余、减少计算量, 但信息量却不够丰富。因此, 构建尺寸合适的码书会有效地提高图像的标注性能。本文下一步工作将致力于该问题的研究来进一步改善图像的标注性能。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|