
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于马尔科夫链的长春市乘用车行驶工况构建
[曹骞 , 李君, 刘宇, 曲大为]
, 李君, 刘宇, 曲大为]
, 李君, 刘宇, 曲大为]
|
|


作者简介:曹骞(1986-),男,博士研究生.研究方向:行驶工况构建算法开发.E-mail:docfile1@126.com
针对乘用车现阶段油耗国标测试结果与实际道路行驶相差较大的问题,研究了长春市乘用车代表性行驶工况。针对长春市乘用车采集一年行驶数据,获得有效数据3 538 335条,应用聚类和马尔科夫链方法构建代表工况,并与上海工况及NEDC工况进行对比分析。结果表明:构建工况与数据库总体的平均偏差为4.03%,远低于10%的偏差要求,能够准确反映长春市乘用车的行驶特征;长春工况与上海工况及NEDC工况相比差异较大,特征值平均偏差分别为22.7%和21.1%,中国城市行驶工况存在明显差异,现行NEDC工况难以准确描述中国乘用车行驶特征,构建符合国情的行驶工况十分必要。本文结果为提升长春市乘用车测试和评价结果准确性提供了有益参考。
With regard to the big gap between fuel consumption measurement and actual driving performance of passenger car, the typical driving cycle of passenger car in Changchun city was researched. One year's driving data were collected in Changchun city, from which 3 538 335 valid data were acquired for the research. Cluster method and Markov chain principle were applied to construct the typical driving cycle, and Changchun cycle was compared with Shanghai cycle and NEDC cycle. The results show that the average absolute deviation of the characteristic parameters between the constructed cycle and sample database population is 4.03%, which is obviously lower than the 10% deviation requirement and indicates that the constructed cycle could accurately reflect the driving characteristics in Changchun city. The driving characteristics of Changchun cycle differ widely from that of Shanghai cycle and NEDC cycle. The average absolute deviation of the characteristic parameters between Changchun cycle and the other two cycles is 22.7% and 21.1% respectively. The driving characteristics of NEDC cycle can not accurately describe the driving characteristics of passenger car in China. Therefore, it is necessary to construct driving cycle that conforms with the situations of China. The results of this research may provide references for promoting the accuracy of measurement and assessment on passenger car in Changchun city.
代表性行驶工况是反映某一地域车辆行驶特征的一组速度-时间序列, 它可以用于估测车辆的实际排放和能耗水平, 为车辆新技术的开发提供数据支持。由于中国乘用车保有量巨大且地域广阔, 导致各地的道路水平、行车习惯等不尽相同。单一的行驶工况往往与当地的实际行驶特征存在较大差异, 使测试结果与实际工况存在较大偏差。因此, 有必要探究地域的行驶特征, 为构建准确的代表行驶工况提供合理的依据。
目前, 国内外均有关于构建代表性行驶工况的研究成果。国外方面, Lin等[1]采集了加州3个地区的行驶数据, 通过研究发现地域变化会使行驶工况的加速、减速、匀速和怠速状态出现明显差异, 从而证实行驶工况具有鲜明的地域特征, 不同地域的测试结果也会出现波动。Andre等[2]分别采用通用行驶工况和有针对性开发的行驶工况测试了30辆乘用车的排放水平, 通过对比发现采用单一行驶工况难以覆盖所有的车型, 这会导致测试结果与实际工况不符, 因此有针对性地开发行驶工况对于保证测试结果的准确性是很重要的。Seers等[3]根据行驶条件和车辆类型开发了针对性的行驶工况, 并与FTP-75工况进行了对比, 发现后者测得的油耗和排放结果比前者明显偏低。可见, 根据当地实际情况构建代表工况, 能够保证测试结果与实际工况吻合, 不过行驶工况的构建方法也会对测试结果有影响[4]。国外也有不少城市独立开发了代表性行驶工况, Ho等[5]开发了新加坡城市工况, Fotouhi等[6]开发了德黑兰城市工况, 对比结果表明, 这些代表性城市工况均与传统工况存在明显偏差, 独立的城市工况更能反映实际行驶特征, 准确度更高。
在国内, 刘希玲等[7]对5个典型城市的行驶工况进行了考察, 通过分析指出采用单一工况明显偏离当地实际的行驶特征, 指出建立我国城市道路行驶工况是十分必要的。对此, 中国也已经有多个城市, 如上海、合肥等, 建立了符合当地实际特征的行驶工况。通过比较研究, 指出构建有针对性的独立行驶工况具有可行性和现实意义[8, 9]。
构建行驶工况的常用方法有聚类分析[10, 11]以及基于马尔科夫链的随机过程[12, 13]等。其中, 前者需要对样本进行分类, 然后筛选出每一类的最优样本并组合, 最终得到完整的代表性工况。不过该方法只能从实测数据中提取短行程, 需要对样本进行取舍以满足时长、比例等要求, 有时会导致构建工况的特征值与实际工况出现较大偏差。后者是根据样本空间的统计结果建立基于车速的状态转移矩阵, 据此随机生成代表性工况, 获得的时间精度和准确度均较高。
长春市在国内属于中等城市, 位于高寒地带, 其经济发展水平及道路设施与其他主要城市相比存在明显地域差异。为验证长春市乘用车道路行驶特征的独立性, 本文将构建的长春市乘用车代表性行驶工况与上海工况和NEDC工况进行对比分析, 发现长春市的行驶特征与两者均存在显著差异, 证实行驶特征地域差异是存在的, 因此有必要构建符合地域特点的行驶工况。该研究所用方法可为行驶工况构建提供有益参考, 相关分析结果对制定车辆评测标准具有指导意义。
行驶数据采集方式有追踪车法[14]、自主驾驶法等。追踪车法是对正在行驶的机动车进行追踪并同步采集行驶数据, 不过这种方式容易受到周围交通环境的影响, 且随意性较大, 容易导致数据采集不充分。因此本文采取自主驾驶方法收集道路行驶数据, 也就是不具体规定行驶方案, 让驾驶员按自身需求自主安排行驶路线, 这样做能够最大限度地覆盖行驶道路范围和行驶时段, 使样本数据能够充分反映本地区的行驶特征。
为消除驾驶习惯对行驶数据统计的影响, 本文选取了5种车型, 每一车型选取2辆车共10辆乘用车, 动力类型均为汽油机, 选用车型的基本参数如表1所示。
| 表1 测试车型参数 Table 1 Type and parameters of vehicles for test |
本文利用车载数据采集终端采集行驶数据, 终端内置GPS定位、无线传输及内部存储器等模块。该终端会将读取的试验车辆实时行驶数据连同GPS坐标信息等自动保存在内部存储器中, 同时通过无线网络发送至管理平台数据库用以后续的数据调取和分析。为实现大样本数据特点, 本文连续采集行驶数据12个月, 采集频率为1 Hz, 获取有效试验数据总共3 538 335条, 本文将据此分析长春市乘用车道路行驶特征并构建典型行驶工况。
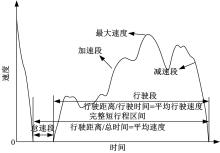
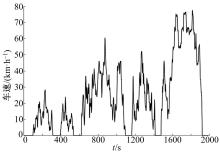
一个完整的短行程如图1所示, 它是从一个怠速起始点开始到下一个怠速起始点为止的行驶片段, 主要包括加速、减速、匀速和怠速4个行驶特征, 本文对这4个行驶特征的定义为:
 | 图1 短行程结构Fig.1 Structure of a micro-trip |
(1)加速段:加速度大于等于0.15 m/s2并且车速不为0的不间断行驶状态。
(2)减速段:加速度小于等于-0.15 m/s2并且车速不为0的不间断行驶状态。
(3)匀速段:加速度绝对值小于0.15 m/s2且车速不为0的不间断行驶状态。
(4)怠速段:加速度和车速为0且发动机持续运转的行驶状态。
按照上述原则分割数据点, 提取出有效样本短行程总数为24 104个, 本文将据此建立短行程样本数据库。
为了描述短行程样本, 本文选取了18个特征参数, 其含义及符号如表2所示。
| 表2 短行程的特征参数 Table 2 Characteristic parameters of micro-trips |
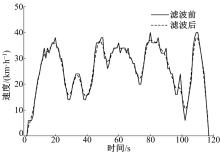
受采集设备灵敏度的影响, 原始速度-时间曲线往往存在噪声干扰, 如果不对其进行降噪处理, 会导致计算结果出现较大误差。为此, 本文采用Epanechnikov核密度函数[15], 对提取到的有效短行程进行滤波。
核函数滤波的基本原理就是将当前时刻的某一邻域作为计算区域, 在邻域内的其他数据点被赋予不同的加权系数, 通过加权求和最终得到当前时刻的估计值。核函数用于计算加权系数, 它的形式为:
式中:
定义邻域
则当前时刻
式中:
当前时刻
式中:dt表示相邻两个数据点的时间间隔。
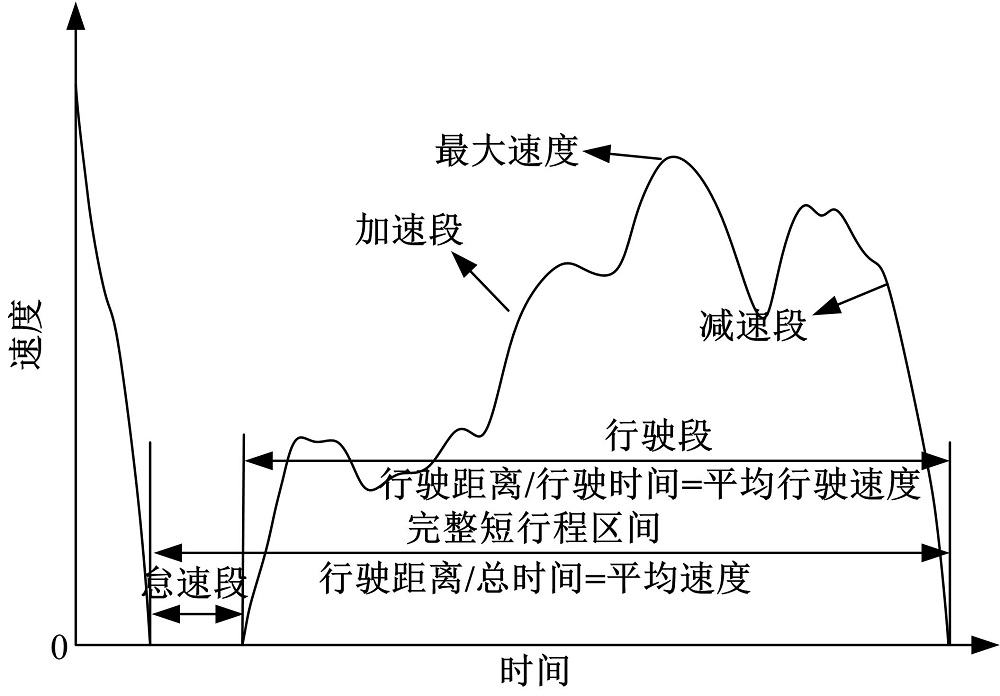
图2是对某一短行程滤波处理前后的速度-时间曲线对比, 从图中可以看到, 滤波处理后的曲线与原始曲线的走势是吻合的, 同时曲线更加平顺, 基本去掉了“ 尖峰” 的干扰, 实现了降噪的目的, 保证了后续分析工作的可靠性和准确性。
 | 图2 滤波前后对比Fig.2 Comparison of before and after filtering |
对滤波后的短行程样本用表2中指定的特征参数进行统计, 最终建立短行程样本数据库, 即样本空间, 如表3所示。
| 表3 短行程样本数据库 Table 3 Sample database of micro-trip |
由于描述短行程的特征参数较多, 其中一些参数可能存在线性相关, 为简化运算, 采用主成分分析对特征参数做降维处理, 将短行程样本空间转换为主成分得分矩阵, 作为聚类分析的依据。
由于特征参数的单位和幅值存在差异, 为了统一特征参数在样本空间中的变化尺度, 首先对特征参数按式(6)进行标准化处理。
式中:
标准化处理之后利用MATLAB软件进行主成分分析, 得到18个主成分变量。表4为按降序排列的主成分方差及其贡献率。从表中可以看到, 从第6个主成分变量开始, 方差值小于1, 前6个主成分变量的累加贡献率达到了83.8%, 说明这6个变量能够反映样本空间的大部分变化, 因此选取前6个主成分变量组成主成分得分矩阵, 如表5所示, 表中P1~P6表示主成分变量。
| 表4 主成分显著性评估 Table 4 Significance assessment of principle components |
| 表5 主成分得分矩阵 Table 5 Score matrix of principle components |
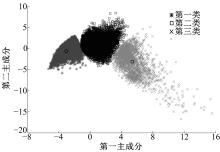
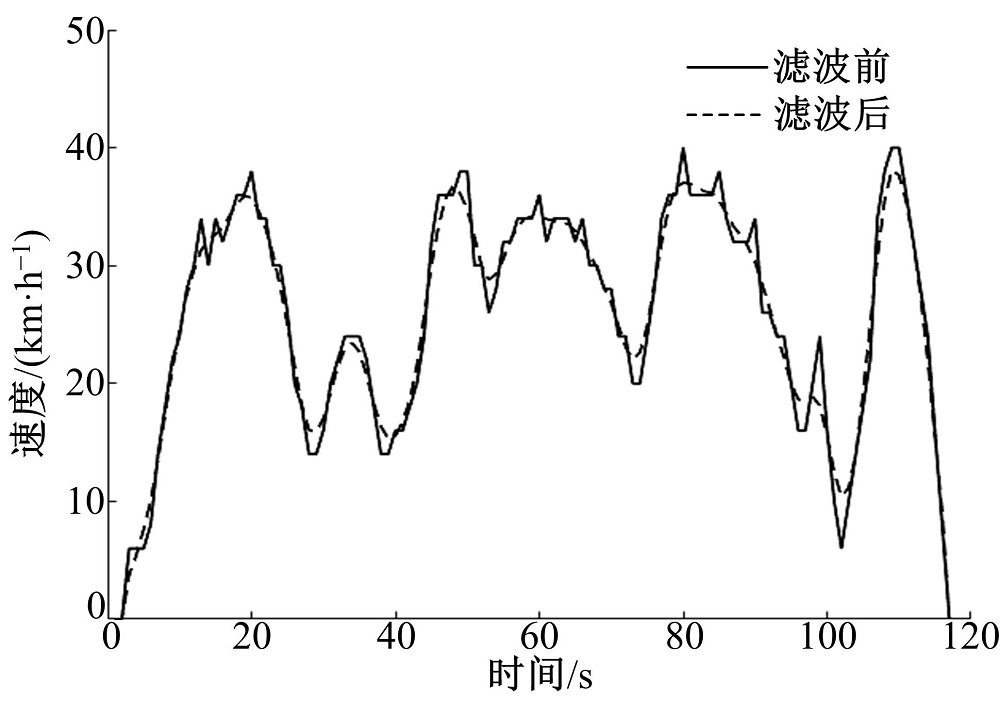
再次利用MATLAB软件, 采用K均值聚类算法, 对表5的主成分得分矩阵进行聚类分析, 最终将短行程样本划分为3类。为了直观考察分类效果, 绘制了前两个主成分的样本散点分布图。如图3所示, 各类的中心点用圆圈标出。从图中可以看到, 相邻两个类之间的界限较为清晰, 其中前两类的样本点较为集中, 第3类样本点的区间跨度较大且较为分散。特别是在第一主成分坐标方向上, 各类中心点的间隔较大; 而在第二主成分坐标方向上间隔略小。总体来看, 各类的散点形态能够得到很好的区分, 分类结果较为理想, 本文将据此对各类统计特征并进行分析。
 | 图3 聚类分析结果Fig.3 Result of clustering analysis |
表6为各类特征值的统计结果, 其中, Ps是样本数占比, Ts是以秒计的短行程平均时长。从表6中可以看到, 类1和类2的样本数占比分别为42.1%和49.1%, 两者数值较为接近并且比例之和超过90%, 这说明类1和类2是主要行驶事件; 而类3的样本数占比仅为8.8%, 是次要行驶事件。类1的平均行驶速度、最高车速和平均样本时长是三类中最低的, 而怠速比例是最高的, 这说明行车通过性较差, 因此可以认为该类代表市区拥堵工况。类2的平均行驶速度、最高车速和平均时长均比类1明显提高, 怠速比例显著下降,
| 表6 各类特征值对比 Table 6 Comparison of characteristic value in 3 classes |
说明行车通过性改善, 可以认为该类反映的是市区畅通行驶工况。类3的短行程平均时长远高于前两类, 并且平均车速和最高车速是3个类中最高的, 同时怠速比例却最低, 说明该类的行驶流畅性较好, 并且能够保证长时间的行驶状态, 因此可以认为其反映的是郊区行驶工况。
本文采用基于马尔科夫链随机过程的方法构建代表性行驶工况。该方法的基本原理就是将短行程的车速-时间序列看成一个完整的随机过程, 先分割速度区间, 每个速度区间代表不同的速度状态, 将车速转换为速度状态, 这样车速-时间序列就变为状态-时间序列。由于下一状态只与当前状态有关, 因此只要确定了相邻两个状态之间的转移概率, 建立如式(7)所示的状态转移概率矩阵, 就可以利用程序随机生成一组随机状态序列, 再将状态序列转换为速度序列, 最后就得到一组符合样本空间特征的行驶工况。
式中:
图4为根据极大似然法求得的关于类2的状态转移概率矩阵, 其他类的情况与此类似。从图中可以发现, 概率值主要集中在对角线上, 这符合车辆的行驶规律, 因为一般来说车速的变化是一个渐变的过程。
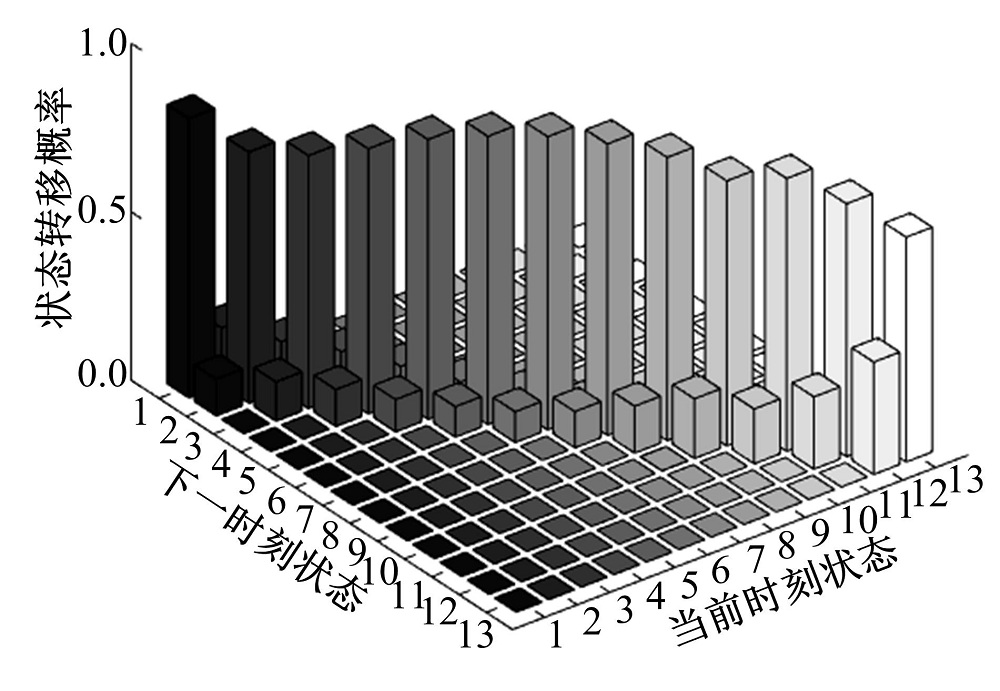 | 图4 速度状态转移概率矩阵直方图Fig.4 Histogram of speed state transfer probability matrix |
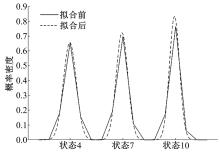
将图4所示的状态转移概率矩阵投影到下一时刻状态, 就得到了当前时刻状态的概率分布。图5实线所示为类2在当前状态4、7和10的概率分布, 可以发现三者的概率值普遍呈现中间高、两边低的正态分布特点, 这与文献[16]的发现一致, 其他两类的状态概率分布与此类似。因此, 可以通过正态拟合, 修正状态转移概率矩阵中各元素的值。图5中虚线所示为经过正态拟合之后得到的概率密度分布, 可以看到拟合结果改善了平顺性, 同时接近原状态概率分布。
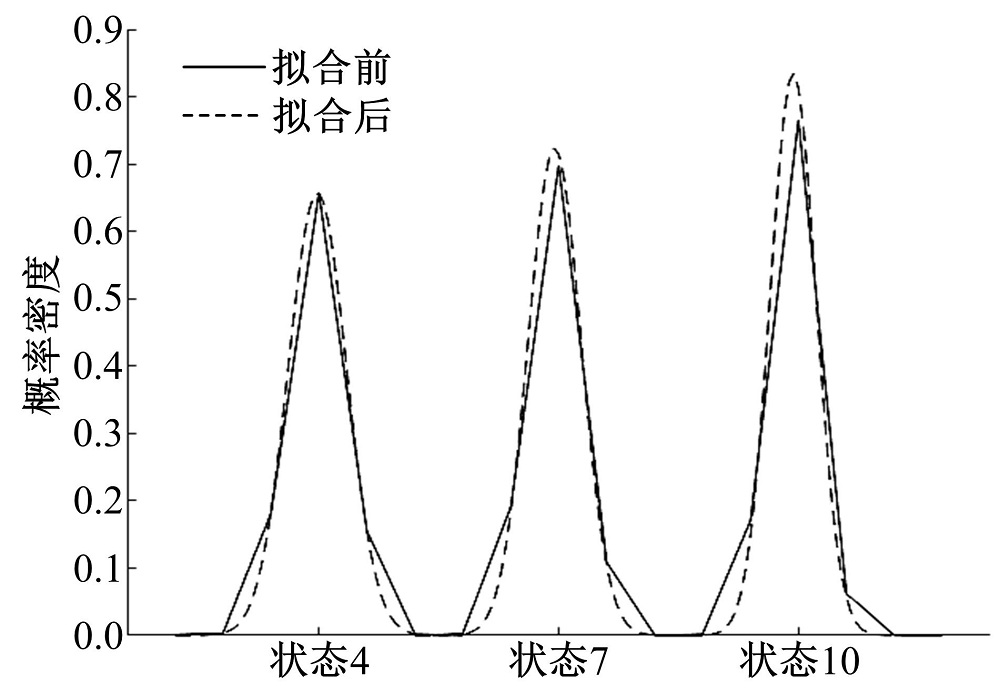 | 图5 速度状态概率分布特征Fig.5 Feature of speed state frequency distribution |
本文将类1、类2和类3的状态数分别设定为15、13和13, 得到各类的状态转移概率矩阵之后, 利用MATLAB软件编程并运行, 先为每一类生成代表性工况, 然后组合成总时长为2000 s左右的代表性工况, 各类代表性工况的时长由各类相对于数据库总体的时间占比确定。构建类代表性工况的具体的方法如下:
(1)从状态1开始并视为当前状态, 利用状态转移概率矩阵确定下一状态值, 以此类推, 直到生成的状态序列满足指定时长并再次返回状态1。
(2)将得到的状态序列转换为速度序列, 转换公式如下:
式中:
(3)得到的速度序列就是候选工况, 计算其特征参数值, 并将结果与类统计结果进行比较, 如果平均绝对值偏差值在10%以内, 则视之为合格的代表性工况, 退出迭代, 否则返回步骤(1)重新开始迭代计算。本文选定的特征参数为行驶段平均速度、行驶段速度标准差、行驶段加速度标准差、加速段平均加速度、减速段平均减速度、行驶段加速比例、行驶段减速比例和行驶段匀速比例共8个, 平均绝对值偏差的计算公式如下:
式中:
将得到的类代表工况按类1、类2和类3的顺序进行组合, 最终得到如图6所示的代表性工况, 工况总时长为1984 s, 平均速度为23 km/h, 行驶里程为12.7 km。
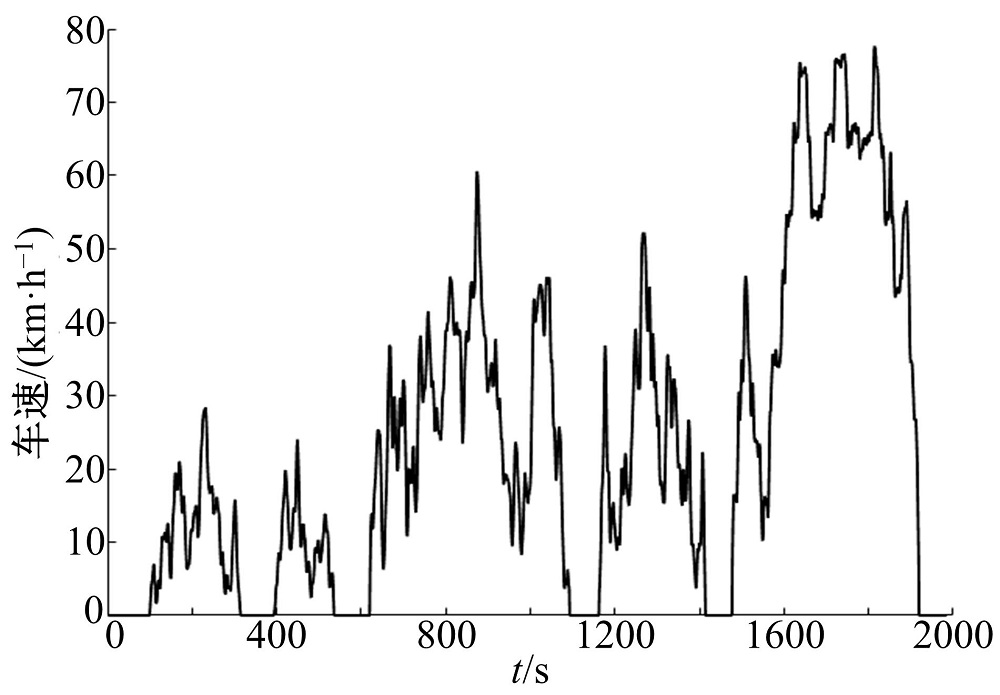 | 图6 构建的代表性工况Fig.6 Constructed typical driving cycle |
为验证构建工况与数据库总体的特征是否吻合, 本文将两者的特征参数统计结果进行对比, 结果如表7所示。经过计算, 两者的平均绝对偏差为4.03%, 远低于程序中10%的偏差要求, 并且各参数值偏差都在10%以内, 偏差量较小且较为稳定。由此可见, 构建工况能够准确反映总体特征, 可以作为代表工况用于后续分析。
| 表7 构建工况与样本总体对比 Table 7 Comparison of constructed cycle and sample population |
为考察长春市工况的独特性, 并考虑到上海与长春在城市规模、发展水平和地域特征的差异明显, 将长春市代表工况与独立开发的上海工况[8]和NEDC工况的特征值进行比较, 结果如表8所示。
| 表8 代表性行驶工况对比 Table 8 Comparison of three typical driving cycles |
从表8中可以发现, 长春市工况的速度比例呈均匀分布特征, 并且平均车速在3个工况中处于居中位置, 而与其他两个工况的加减速度特征差异较小。其中, 长春工况与上海市工况的平均偏差为22.7%, 差异较大的是匀速比例、怠速比例和全局平均车速, 两者的偏差分别为56.7%、60.7%和29.7%。由此可见, 长春市车辆的行驶速度较高, 与上海市区相比能够保证长时间的稳定行驶。长春工况与NEDC工况的平均偏差为21.1%, 差异较大的是匀速比例、减速比例、全局平均速度和平均行驶速度, 偏差值分别达到27.7%、29.5%、45.9%和46.4%。长春工况与NEDC工况的怠速比例接近, 但匀速比例和平均速度低于后者, 可见NEDC工况的行驶通畅性更好。由此可见, 长春工况与NEDC工况和上海工况都存在显著差异, NEDC工况难以准确反映长春市乘用车实际行驶特征。因此为保证测试结果的准确性, 有必要考虑地域差异的影响, 构建符合中国城市车辆行驶特征的代表工况。
(1)建立了长春市乘用车行驶样本数据库, 基于聚类和马尔科夫相结合的方法构建行驶工况, 构建工况时长为1984 s, 平均速度达到23 km/h, 行驶里程为12.7 km, 与数据库总体的平均特征偏差为4.03%, 所有参数的偏差均低于10%, 能够准确反映实际行驶特征, 可以作为长春市乘用车的代表工况。
(2)长春市工况的速度比例呈均匀分布, 平均车速介于上海工况和NEDC工况之间, 平均加、减速度与两个工况的值较为接近。长春工况与上海工况和NEDC工况均存在显著差异, 平均偏差分别达到22.7%和21.1%。NEDC工况难以准确描述中国车辆行驶特征, 中国城市间行驶特征存在地域差异。本文得到的工况可以为中国新工况构建及标准测试的地域加权提供数据依据。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|