

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
子句级别语境感知的开放信息抽取方法
[欧阳丹彤1, 2  , 范琪
, 范琪1, 2 ]
, 范琪|
|


作者简介:欧阳丹彤(1968-),女,教授,博士生导师.研究方向:基于模型诊断、语义网.E-mail:ouyd@jlu.edu.cn
针对开放信息抽取文本中与事实相关的语境信息,本文首先从原有语境标识中提取特征进行训练分类,扩展了可识别的语境标识;其次,利用文本中依存关系,自顶向下逐层将识别出的语境信息与被限定子句构造成层次结构图,并最终根据层次图为被限定子句中抽取出的关系元组自底向上地分配对应语境域,从而一方面避免了语境信息被错误的抽取为关系元组,另一方面在保证关系元组正确的基础上,正确地将语境域分配给被限定的关系元组。实验结果验证了子句级别语境感知的抽取方法ClauseContextIE,在随机数据与含语境信息的文本中,实现了较高的召回率和精确度。
In order to address the issue that sentences may contain context-information with reference to the facts, this paper presents a Clause-Level Context-aware Open Information Extraction approach (ClauseContextIE). ClauseContextIE extends the scale of context-information that can be identified, and takes advantage of the dependency-parsing to extract the context-information and general clauses in a top-down way, so that it can construct a graph that expresses the hierarchical structure. Finally, ClauseContextIE assigns the corresponding context-information to each tuple extracted from general clauses in a bottom-up approach. ClauseContextIE avoids extracting context-information as a relation tuple, and assigns context-information to correct relation tuples accurately. Experiments were conducted to compare ClauseContextIE with ReVerb, OLLIE and ClausIE on three datasets, ReVerb dataset, Wiki dataset and NYT dataset. Experimental results show that ClauseContextIE achieves significantly higher accuracy and recall than the other extractors.
开放信息抽取[1]是指在无预先指定关系的前提下, 从海量多样化的文本中大规模自动化的抽取出结构化信息的一种自然语言处理任务。近年来, 开放信息抽取在知识图谱构建和自动问答系统等领域, 发挥了举足轻重的作用。2007年, Banko等[1]最早提出的TEXTRUNNER 是第一个真正意义上的开放信息抽取方法, 随后Wu等[2]提出了WOE方法, 这两种方法采用启发式或远监督方法标记语句, 利用CRF等模型学习抽取器抽取论元和关系。Fader等[3]提出了ReVerb方法, 对抽取的关系进行语法约束和词汇约束, 避免了无逻辑的关系和信息不完整的关系的抽取。随后一些方法被提出, OLLIE[4]增加了对以名词或形容词为中心的关系进行抽取; KrakeN[5]可以抽取任意类型的
在开放信息抽取处理的语句中, 经常存在与事实相关的信息, 来表达事实成立的条件或者主观信念的来源, 称之为语境。现有开放信息抽取的抽取方法在抽取关系元组时并不考虑语境信息, 不能抽取到语句中的事实信息, 并且不可避免地将一部分语境信息错误地抽取为关系元组的一部分。在语境抽取方面, 仅有OLLIE方法在抽取关系元组后为关系元组添加语境信息, 但由错误的模板会抽取到错误的关系元组, 即使加上语境信息, 也会生成错误的事实信息。
针对上述目前开放信息抽取语境信息处理方法面临的问题, 受基于子句的ClausIE[6]方法启发, 本文提出了子句级别语境感知的开放信息抽取方法ClauseContextIE。该方法首先利用OLLIE识别的语境信息训练模板, 以抽取更多的语境, 并且在从子句中抽取关系元组前抽取语境信息, 同时考虑语句中的层次结构将语境信息分配深入到子句级别, 有效地解决了上述两个问题。实验结果表明, 本文方法ClauseContextIE在随机数据集上, 抽取结果总体优于相对于目前最具竞争力的ReVerb、OLLIE以及ClausIE方法, 并且对于含有语境信息的语句, 抽取结果明显优于OLLIE方法。
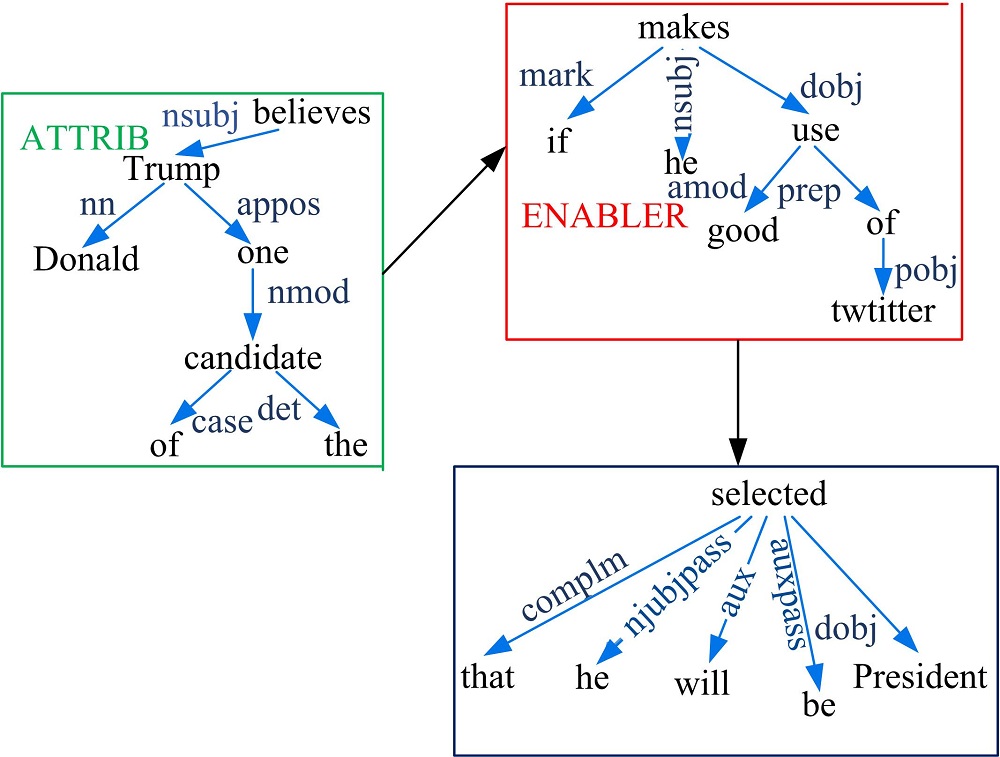
句子结构在开放信息抽取方法中具有非常重要的作用, 而依存解析通过分析语言单位内成分之间的依存关系可以揭示句法结构。使用非词汇化Stanford依存解析[13]工具, 分析句子S:“ Donald Trump, one of the candidates, believes that if he makes good use of twitter, he will be selected President.” , 可以得到如图1所示的句子结构。
 | 图1 句子S的依存解析结构Fig.1 Dependency parsing structure of sentence S |
子句是句子中表达合理语义信息的片段, 根据子句组成成分的不同, 文献[14]给出了子句的类型。ClausIE[6]方法参考子句类型, 利用语句的依存路径采用以下规则抽取子句:① 首先为每个与主语相关的依存(如nsubj)构造子句; ②若依存中出现关系从句(rcmod), rcmod的支配方作为该子句的主语; ③若出现同位语(appos)或所有格(pos), 则增加一个“ is” 或“ has” 作为子句的关系动词; ④若出现分词形式(partmod), 则在分词前增加一个系动词与分词一起构成关系成分; ⑤最终, 根据依存路径生成每个成分的完整表达。
通过ClausIE可以从语句S得到如下子句:C1(S:“ Donald Trump” , V:“ believes” , C:“ that if he makes good use of twitter he will be selected President” ), C2(S:“ Donald Trump” , V: “ is” , C:“ one of the candidates” ), C3 (S:“ he” , V:“ makes” , O:“ good use of twitter” ), C4 (S:“ he” , V:“ will be selected” , O:“ President” , A?: if he makes good use of twitter)。
从图1的依存解析结构可以看出, 子句具有不同的层次并且子句间存在一定的依赖关系。ClausIE方法考虑句子的结构, 能够从复杂的句子中识别出多个子句, 并进一步生成多个关系元组。
语境信息一般分为两种:条件语境和归因语境。OLLIE[4]方法采用线索词和依存边信息识别两种语境。条件语境的线索词为:after, although, because, before, but, however, if等14个。归因语境的线索词则来自VerbNet[15]中的communication和cognition两个单词列表。对于包含条件语境信息线索词的语句, 该方法会进一步检查依存边。条件语境通常包含一个advcl依存边, 支配方为被修饰子句中的核心词, 依存方指向修饰子句中的核心词。而含有归因语境信息的语句的依存解析, 通常包含一个ccomp依存边, 支配方为语句中归因主体的核心词, 依存方为被归因的内容的核心词。上述方法为语境识别提供了非常简单的两种模板, 可以从语句S中识别出条件语境(“ if he makes good use of twitter” )和归因语境(“ Donald Trump, one of the candidates, believes” )。
实际上, 含有语境信息的语句并不仅限于以上线索词与依存形式。本文以上述线索词为样本进行训练、分类, 得到模板, 从而识别更多语境。语境中常含有事实信息, OLLIE并不能对其进行抽取, 本文的方法将增加对这部分事实信息的抽取。
对于描述事实的语句, ClausIE方法能够取得很高的召回数和精确度。然而, 对于包含语境信息的复杂语句, ClausIE方法从子句中抽取出的元组所包含的信息往往是缺少语境信息或者过于复杂的。而OLLIE方法同样会把语境信息抽取为关系元组, 并且抽取的正确关系元组的数量并不理想。本文利用分类器扩展了语境的识别模板, 提出首先抽取语境信息, 然后在句子的非语境部分抽取子句, 并构造语境与子句间层次结构图将抽取出的语境分配到不同子句, 最终实现子句级别语境感知的ClauseContextIE方法。
在开放信息抽取中, 利用Bootstrapping过程生成模板受到广泛关注。OLLIE[4]方法和ZORE[9]方法以ReVerb的抽取模板为基础, 成功训练并识别出更多形式的模板。OLLIE方法也因此获得了以名词或形容词为中心的关系进行抽取的模板。
为获取更好的识别语境信息, 本文使用Bootstrapping过程分别为条件语境和归因语境生成模板。首先, 利用线索词和对应依存边, 获取部分语句, 人工标注语句中语境信息的标识词以及局部依存解析结构信息, 将依存结构和标识词的词向量作为特征, 分别为条件语境与归因语境训练SVM模型。然后, 利用分类器识别语句, 并从依存结构和语句中根据标识词与模板相似提取出包含标识词和局部依存结构的新模板。最后, 为保证模板的可靠性, 只筛选少量局部依存结构简单, 标识词与局部依存结构重复次数高的模板, 并经过人工验证。
SVM分类器的特征主要包括两类:①词向量方面, 本文使用文献[16]中训练好的词向量glove.42B.300d, 为简化训练, 采用备选标识词与已有标识词的词向量余弦相似度(前5个最大的相似度)代替300维的向量特征。另外, 最大相似度大于阈值参数的单词才被选为备选标识词。②局部依存结构方面, 本文使用标识词在依存解析中存在的一阶和二阶依存边, 分别构成两个向量(向量的每一维取值为1或0, 分别表示该类型的依存边是否与标识词相连或二阶相连), 一阶依存边为ccomp、mark等, 二阶依存边为advcl、nsubj等, 这两个向量组成了该模型的局部依存结构特征。
利用该方法, 能够发现更多模板。例如, 该方法发现了类似语句“ Students cannot copy, cannot dress up in teacher's mind.” 具有归因信息, 并识别出包含“ in sb's mind” 的局部依存结构和标识词“ mind” 的模板。人工筛选模板不仅能够确保准确的发现语境, 并且能够准确的划定语境的范围, 为高质量的语境抽取提供保障。
识别语句中存在的语境后, 将对语境及子句进行抽取, 并将语境分配给语句中相应的子句。为避免语境信息被错误地抽取为关系元组的一部分, 本文将语境信息和一般子句加以区别。
为了精确地进行语境的分配给一般子句, 将构造语句的层次图, 其中构建的层次关系可以存在于语境间、一般子句间或者语境和子句间。本文将层次分为并列关系和父子关系两种。若语境与子句为并列关系, 那么说明这个子句不再在该语境的作用范围, 与该语境无关; 若为父子关系, 即语境的层次位于子句上方, 那么这个子句就在该语境的作用范围内, 与该语境相关。在本文的方法中将根据一个句子的依存解析为句中的语境和一般子句构造一个层次图, 语境和子句用结点表示, 父子关系由一个有向边表示, 由表示高层次的父节点指向低层次的子节点。
在构造语境信息与一般子句间的层次图时, 首先在语句的依存解析上自顶向下的抽取语境信息并识别一般子句:若遇到语境的标记, 则抽取句中的语境信息, 并将语境信息加入层次图的结点集合, 对于其中的每两个语境, 若在依存解析中存在一条路径将它们连接, 那么在层次图中为它们之间增加一条同向的边; 同时为依存中除语境外的主语依存构造一般子句, 并将一般子句作为层次图的结点加入到集合中, 若子句与一个语境有直接依存关系, 那么这个子句与该语境有父子关系, 将为两者间增加一个从语境指向子句的边, 否则为并列关系, 在边集中增加一条由语境的父结点指向该子句的边。
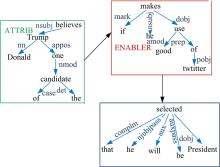
例如语句S, 在图1中, “ Donald Trump, one of the candidates, believes” 和“ if he makes good use of twitter” 首先分别被标记为ATTRIB和ENABLER; 然后自顶向下识别出这两个语境和子句(S:“ he” , V:“ will be selected” , O: “ President” ), 并构造层次图, 如图2所示。
 | 图2 句子S的层次图Fig.2 Hierarchical graph of sentence S |
当语境信息的依存路径中存在同位语(appos)、关系从句(rcmod)和分词修饰符(partmod)依存边时, 该语境中通常存在一个事实信息, 能够使这个事实信息不受任何语境的约束, 所以在ClauseContextIE中将从语境中抽取该子句, 并作为一个独立的结点加入到层次图中。如语句S中的语境“ Donald Trump , one of the candidates, believes” 中包含一个独立子句(S:“ Donald Trump” , V:“ is” , C:“ one of the candidates” ), 更新后得到的层次图如图3所示。
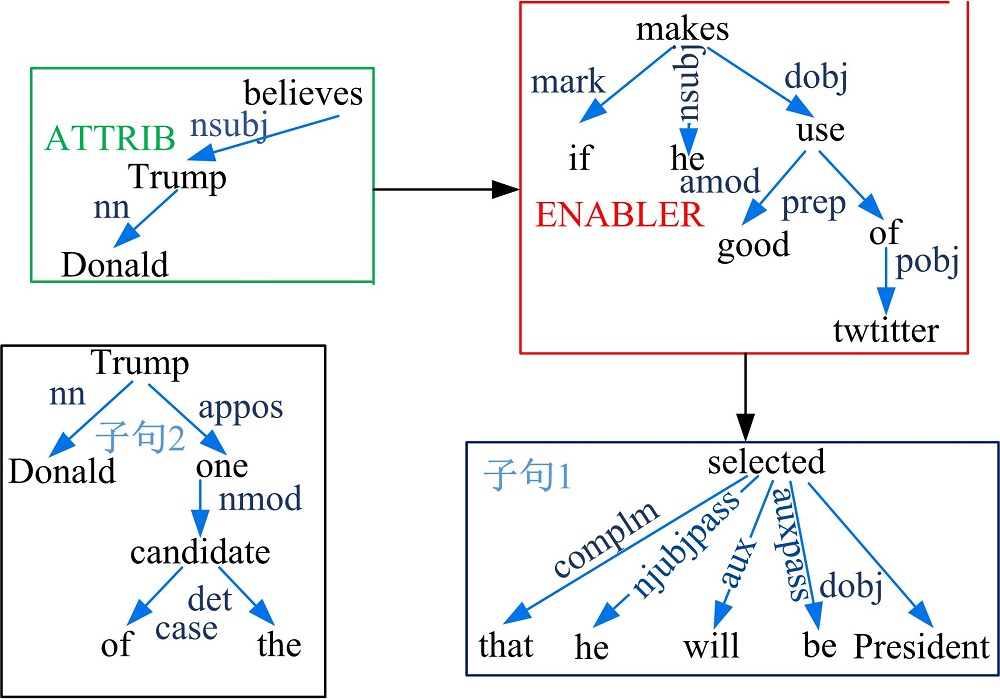 | 图3 句子S处理同位语后的层次图Fig.3 Hierarchical graph of sentence S after processing appos |
得到完整的层次图后, 从一般子句中抽取到关系元组R1(“ Donald Trump” , “ is” , “ one of the candidates” )和R2(“ he” , “ will be selected” , “ President” ), 最终根据层次图对R1 和R2分配语境, 得到T1(“ Donald Trump” , “ is” , “ one of the candidates” ), T2(“ he” , “ will be selected” , “ President” , “ ENABLER: if he makes good use of twitter” , “ ATTRIB: Donald Trump believes” )。
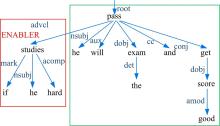
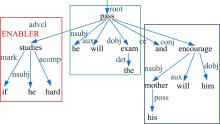
特别地, 对于并列连接词连接子句的情况, 除依赖解析结构外, 本文还进一步考虑句子中的时态、标点以及主语约束范围等来识别语境信息与子句的约束关系。例如, 语句S1:“ If he studies hard, he will pass the exam and get a good score. ” 和语句S2:“ He will pass the exam if he study hard, and his mother will encourage him.” 具有类似的依存解析结构, 如图4和图5所示。
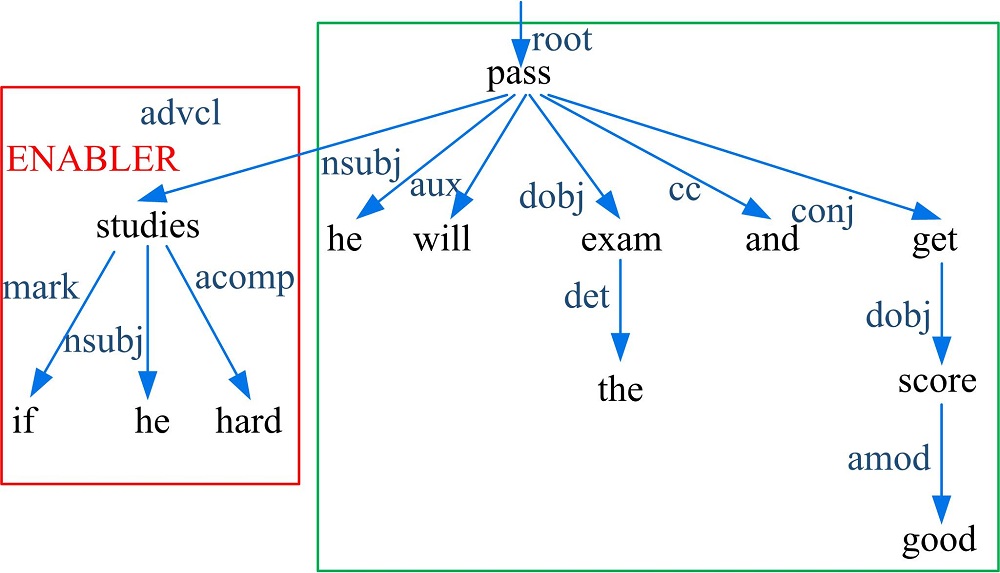 | 图4 句子S1的依存解析结构Fig.4 Dependency parsing structure of sentence S1 |
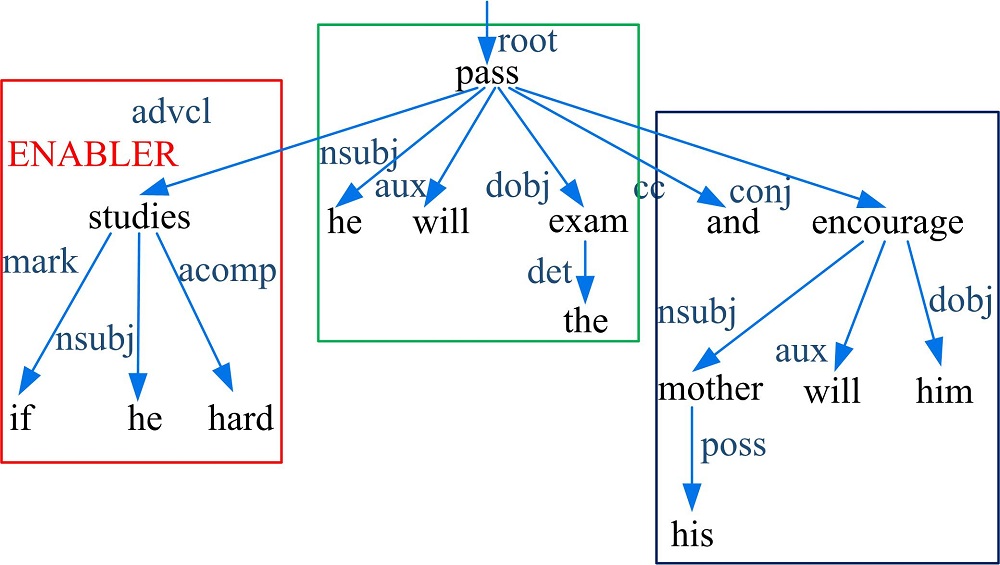 | 图5 句子S2的依存解析结构Fig.5 Dependency parsing structure of sentence S2 |
考虑主语约束范围, 可以识别出“ if he studies hard” 在S1中同时约束子句(S:“ he” , V:“ will pass” , O:“ the exam” )和 (S:“ he” , V:“ will get” , O:“ a good score” ), 而在S2中则仅约束子句(S:“ he” , V:“ will pass” , O:“ the exam” )并不约束 (S:“ his mother” , V:“ will encourage” , O:“ him” )。于是, ClauseContextIE将根据不同的主语约束范围来构造语境和一般子句的层次关系。
算法1 ClauseContextIE
Input: sentence
Output: facts
1.facts = { }
2.dp ← get the dependency parsing of sentence
3.match contexts with patterns
4.label the head of each contexts in dp
5.extract general clauses in dp
6.graph = construct ( dp, contexts, clauses)
7.reltriples ← extract relations in clauses
8.for each reltriple in reltriples do
9. fact← assign reltriple with contexts
10. facts.add(fact)
11.end for
12.return facts
算法1为ClauseContextIE的基本框架。本文首先使用2.1中训练得到的模板对语句中的语境信息进行识别并标记为条件语境(ENABLER)或归因语境(ATTRIB)(第3行和第4行), 同时抽取句子中存在的除语境信息外的一般子句(第5行), 其次以图的形式为语句中语境信息和一般子句构建层次关系(第6行), 然后从一般子句中抽取关系元组(第7行), 最终, 根据所构建的图, 自底向上地为关系元组分配相应的语境信息(第8行到第11行)。
相对于OLLIE方法, ClauseContextIE方法不仅能够正确地识别出更多包含语境的语句, 有效地处理复合语境, 而且能够更好地对语境信息进行分配。为验证ClauseContextIE方法对语境处理的优越性, 实验部分将会对一般情况和包含语境的情况分别进行对比和分析。
为了保证实验的公平性, 本文选用开放信息抽取中广泛使用的3个数据集:
(1)ReVerb dataset[3], 该数据集为ReVerb实验中使用的数据, 包含了使用雅虎随机连接服务得到的500个语句, 这些语句大部分包含噪音。
(2)Wiki dataset[6], 由从维基百科随机抽取的200个语句构成, 相对于ReVerb中的语句, 维基百科中的语句通常简短并且不包含噪音, 然而由于一些维基百科的撰写者不是以英语为母语, 语句中可能包含错误的语法结构。
(3)NYT dataset[6], 是从New York Times文库[17]中随机抽取的200个语句, 这些语句通常很干净, 不包含噪音或语法结构, 但是相对其他数据集中的语句结构更加复杂。
实验选用ReVerb[3]、OLLIE[4]和ClausIE[6]三种方法与本文提出的基于子句的语境感知信息抽取ClauseContextIE进行对比, 可以从文献[6]中获取上述3种已有方法的源代码和抽取结果。
每种方法将分别对3个数据集进行抽取, 然后人工标记从所有方法中得到的抽取元组。为了保证标记的一致性, 将ReVerb、OLLIE和ClausIE三种方法对每个数据集的抽取结果进行再次标记, 由于原标记没有考虑语境, 所以新标记后得到的精确度将低于原标记的结果。此外, 在标记时, 若元组中存在指代或屈折变化, 如(“ he” , “ has” , “ office” ), 则将元组标记为正确的抽取(T)。对于含有(“ has reported 1993 events in Moscow in” )这种冗长关系的元组, 则将元组标记为错误的抽取(F), 然后根据标记的结果得到抽取的精确度和召回率。然而, 由于开放信息抽取不限定关系类型, 无法准确统计数据集中所包含的所有正确事实关系的数量, 在实验中将用所有抽取到的正确元组数量代替召回率。
对抽取的结果进行统计可以得知, 在3个数据集所有语句中, ClauseContextIE可以从中抽取到条件语境的语句占总数的7%, 可以抽取到归因语境的语句占总数的13%, 基本抽取到了所有包含语境的语句。对条件语境的处理纠正了ClausIE中与之相关的41%的错误, 并且没有引入新的错误, 而归因语境的处理使得ClausIE中68%与归因情况有关的错误变作正确的, 并且只引入少量错误。
表1~表3分别为各种方法对ReVerb dataset、Wiki dataset和NYT dataset三个数据集抽取的具体结果。
| 表1 对ReVerb dataset抽取的结果 Table 1 Extraction results of ReVerb dataset |
| 表2 对Wiki dataset抽取的结果 Table 2 Extraction results of Wiki dataset |
| 表3 对NYT dataset抽取的结果 Table 3 Extraction results of NYT dataset |
(1) ClauseContextIE抽取到的正确事实可以达到ReVerb的3倍和OLLIE的2倍, 这是由于ClauseContextIE将语句划分到子句级别, 可以从一个语句中获取多个子句, 并且从每个子句中可以抽取到多个元组。因为含有语境处理方法的ClauseContextIE删除了ClausIE抽取结果中不包含语境的不正确的抽取, 所以抽取的元组的数量略低于单纯的基于子句的信息抽取ClausIE, 但是ClauseContextIE抽取的事实元组中包含了元组所处的语境, 将在ClausIE中得到的不正确的元组修改成包含语境的正确的元组, 使其抽取的正确元组的数量反而增加了。由于实验采用所有抽取到的正确元组数量代替召回率, 所以可以认为ClauseContextIE的召回率最好。
(2)如表2所示, 在Wiki dataset中, 没有采用依存解析的ReVerb的精确度高于使用了依存解析的其他3种方法, 由于有部分语句不符合语法结构, 在表1和表3中, 即在含有噪音的ReVerb dataset和语句复杂的NYT dataset上, ClauseContextIE抽取精确度都要高于其余抽取方法, 原因有以下3点:①相对于ReVerb和ClausIE来说, ClauseContextIE增加了语境的处理。②相对于OLLIE在抽取关系元组前处理语境信息, 避免了将语境信息抽取为关系元组, 并且增加了语境模板以及OLLIE不能处理的并列连接词的语境分配和对语境信息中存在事实的分析抽取。③ClauseContextIE优先处理语境信息并将语句划分为多个子句再进行抽取, 还达到了将语句简单化的效果, 减少了元组抽取的难度。综合比较, 在4种方法中ClauseContextIE的精确度最高。
为更进一步说明本文方法在语境处理上的优势, 表4列出了OLLIE和ClauseContextIE仅对含有语境的语句的抽取结果。从表4可以看出, 对含有语境信息的语句的抽取, ClauseContextIE的正确抽取数量要远大于OLLIE的正确抽取数量, 这是因为:①本文对语句中语境的存在进行详细的分析, 语境的分配更加合理。②关系元组的抽取采用基于子句的方法, 于是生成了大量正确的关系元组。正确的语境信息, 加上正确的关系元组, 构成了大量的正确的事实元组。
| 表4 对含语境信息语句抽取的结果 Table 4 Extraction results of sentences contains context information |
对ClauseContextIE不正确的抽取结果进行分析, 得到如下结论:①近70%的错误源于不正确的依存解析, 这可能源于输入的语句含有噪音或错误的语法。②有19%的错误发生在判定子句类型时, 将SVOA类型误判为SVO类型, 导致元组中缺少了必需成分。③余下的错误是由于忽略了一些其他形式的语境, 文中对语境的分析虽然可以涵盖大部分情况, 仍有特殊的语境可能出现在语句中。其中, ClauseContextIE方法面临的问题①和②与ClausIE方法相同。因此, 子句识别方面仍需进一步改进。
在基于子句的信息抽取方法上, 结合深入的语境分析, 提出一种子句级别语境感知的开放信息抽取方法, 该方法根据输入语句的依存解析路径, 先识别并标记语句中语境信息, 再从外层到内层将语句划分为多个语境部分和子句, 抽取每个子句中的关系元组后, 再利用语境和子句间的层次结构为关系元组分配相应的语境, 得到最终的事实元组。与ClausIE不同, ClauseContextIE方法避免了将语境信息错误的抽取为关系元组的一部分, 并且保留了其基于子句方法中高召回率的优势。同时, ClauseContextIE不仅可以抽取OLLIE可以抽取简单的语境, 还可以处理复杂的复合语境并且抽取语境中存在的事实信息。实验中将该方法与其他3种主流方法在3个不同的数据集上进行了比较, 结果验证了该方法不仅提高了抽取的召回率, 还提高了抽取的精确度。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|