
{kind=link}
{kind=link}
基于改进的标签传播算法的网络聚类方法
[桂春1  , 黄旺星
, 黄旺星2 ]
, 黄旺星|
|


作者简介:桂春(1981-) 女,副教授,博士研究生.研究方向:复杂网络,数据挖掘.E-mail:guichun2103@163.com
采用传统标签传播算法实现网络聚类时,由于标签初始分配过程随机、节点选择过程随机、且标签更新顺序随机的原因,影响聚类结果。为此,提出一种新的基于改进标签传播算法的网络聚类方法,即用图对网络进行描述,并为网络聚类提供基础。改进标签传播算法过程如下:求出网络中任意两节点拥有最大公共邻居的平均阶数,把相似性最高的节点和邻居节点看作初始核心社团,为其分配初始标签;引入基于随机游走的相似度矩阵,令节点选择和自身相似度最高的节点拥有的标签;通过H指数对标签算法更新顺序进行改进;依据改进后结果,按照标签传播算法网络聚类过程实现聚类。实验结果表明,本文所提的网络聚类方法具有更高的准确性和稳定性。
Using traditional label propagation algorithm in network clustering, the initial allocation of taps, the node selection and updating order of the labels are all random processes, which affect the clustering results. To overcome this problem, a new method of network clustering based on improved label propagation algorithm is proposed, in which the graph is used to describe the network and provide the basis for the network clustering. The process of the improved label propagation algorithm includes the following steps. First, the average malpractice in the network order of any two nodes with the largest common neighbor number is obtained. Second, the most similar node and neighbor node are taken as the initial core community and its initial label is assigned. Third, the random walk similarity matrix is introduced based on the node selection and the label of the node with the highest similarity. Fourth, by using the H index on the label algorithm, the update order is improved. Finally, according to the improved result, the clustering process is realized according to the clustering process of the label propagation algorithm network. Experimental results show that the proposed network clustering method has higher accuracy and stability.
当前很多系统都以网络的形式存在, 而且复杂程度高[1]。网络簇结构为网络最关键的拓扑结构属性, 为了描述网络中真实的簇结构, 需研究一种有效的网络聚类方法, 为研究网络拓扑结构、理解网络功能、发现网络中的规律及预测网络行为提供重要应用价值。有效的网络聚类方法在其他应用性网络中也有很高的应用前景, 不但是计算机领域亟需研究的重点课题, 也吸引了其他学科的众多研究者[2]。
有关网络聚类的研究近年来有很大的进展, 当前网络聚类方法主要包括图分割法、W-H法、层次聚类法和标签传播算法[3]。图分割法被广泛应用于计算机领域, 依据迭代对分原理, 把网络划分成两个最佳子图, 再不断对子图进行分割, 直到子图个数满足既定条件[4]。图分割法的弊端为每次仅可把网络划分成两部分, 为了得到有效聚类结果需不停迭代, 实现过程复杂。W-H法任意选择两个不同社区节点, 将其设置成电压是1的初始点与电压是0的结束点, 剩余节点将获取各自电压值, 把电压值基本相同的节点分配至相同社区, 从而实现网络聚类[5]。该方法的弊端是在分配前需掌握网络结构的先验信息。层次聚类法通过节点间的相似关系对网络进行聚类, 然而层次聚类法通常会忽略大量相似度很低的点, 导致聚类结果准确性较低[6]。标签传播算法和以上几种方法相比, 无需掌握网络结构或先验知识, 根据网络传播特征即可实现网络聚类, 所以效率很高。但标签传播算法在传播时, 由于标签初始分配过程随机, 当相邻节点标签出现相同高频率时, 会随机选择一个标签, 且标签更新顺序随机, 影响聚类结果。为此, 本文提出了一种新的基于改进标签传播算法的网络聚类方法。
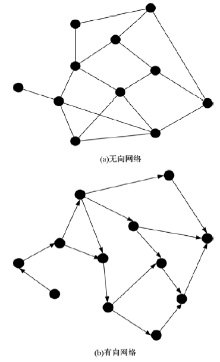
本文采用图方式对网络进行描述, 用图对网络进行描述有很高的应用价值, 不但能够描述网络, 而且是网络聚类的基础。将网络记作
 | 图1 网络描述Fig.1 Network description |
采用标签传播算法对网络进行聚类处理的基本思想为:依据网络的传播特征完成对网络节点标签信息的传播, 以获取潜在网络结构, 将结构相似的网络划分至一类。首先为所有节点赋予初始标签, 然后在标签的传播过程中对节点标签进行更新, 认为标签一致的节点属于相同网络[7]。标签传播算法易于实现, 复杂度低, 被广泛应用。
采用标签传播算法实现网络聚类详细过程如下:
(1)为网络中所有节点赋予唯一初始标签, 对其所处网络进行标记, 通常将数字或字母看作标签。
(2)完全标签信息的传播与更新处理。在进行迭代时, 全部被更新的节点标签均被其相邻节点出现次数最多的标签替代, 也就是所有节点均需与其大部分相邻节点标签保持一致。若某节点相邻节点中存在若干标签出现次数相同且达到最大的情况, 则随机选择一个标签作为该节点标签。不断迭代更新, 直到所有节点标签均保持不变, 则停止迭代。
(3)全部标签相同的节点属于相同网络。
图2描述的是标签传播过程图。
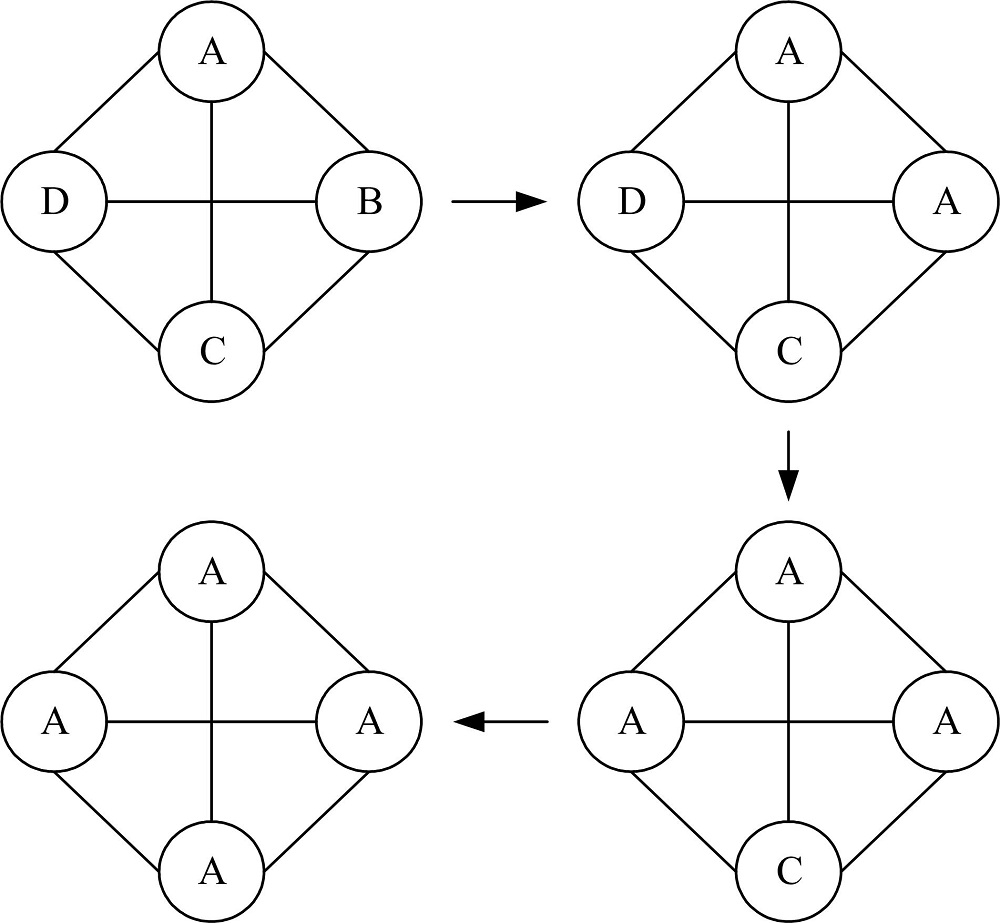 | 图2 标签传播过程图Fig.2 Label propagation process diagram |
标签的更新主要包括两种类型, 分别是同步更新和异步更新[8]。其中, 同步更新可采用下式描述:
式中:
同步更新存在一定的弊端, 在二分图内容易导致震荡现象发生[9]。为了确保更新具有较好的收敛性, 一般选用异步更新策略。异步更新的数学表达式为:
标签传播算法时间效率高, 初始化时为全部节点分配标签的时间复杂度为
分析标签传播算法可知, 标签传播算法能够解决传统算法在处理大规模网络时的时间复杂度问题, 无需预先掌握先验知识, 且不需要设计目标函数, 依据网络传播特征充分满足网络特点。然而, 在标签传播算法中, 网络中所有节点在初始时均会被赋予唯一标签, 传播时完成动态标签更新, 将会造成很多零散的、孤立的小社区出现, 导致真正网络无法聚类。因为所有节点仅有一个标签, 部分影响力较小的节点在传播时会受影响力较大的节点的影响, 导致标签传播过程出现消耗资源的逆流现象。不仅如此, 在某节点相邻节点有很多符合条件的候选标签时, 将随机选择标签, 导致网络聚类稳定性降低, 大量随机性叠加将使若干次实验结果有很大的不同。除此之外, 标签传播算法最大的弊端是节点更新顺序也完全随机。下面针对上述弊端, 采用改进的标签传播算法实现网络聚类。
1.3.1 初始化过程改进
本节主要针对标签传播算法的初始化过程进行改进, 求出网络中任意两节点拥有最大公共邻居的平均阶数, 把相似性最高的节点和K阶邻居K节点看作初始核心社团, 为其分配初始标签。
网络中K值的确定通常取决于网络自身的特性, 公式描述如下:
式中:
详细改进过程为:
(1)对全部点对的K阶公共邻居集进行运算。
(2)挑出存在最大公共K阶邻居的点对。当求取相似度时, 把存在最大相似度的点对以及它的K阶公共邻居当成首个初始核心社团, 同时对标签赋值。
(3)为网络中的每一个节点都分配一个标签, 作为社区的标识, 表示所处社区, 按照标签的顺序对网络中的节点进行排序, 按照排序结果组建集合
(4)针对集合
(5)重复此过程, 直至集合
(6)将网络
通过上述过程获取部分局部核心子结构, 将其看作初始核心社团, 同时将其看作初始标签, 也是标签传播的初始点。
1.3.2 节点标签选择
为了控制节点标签选择方向, 本文引入基于随机游走的相似度矩阵, 节点更新标签时会选择和自身相似度最高的节点拥有的标签。
初始时把随机游走的步行者置于图中任意节点, 令其依据马尔科夫性质随机选择下一位置[10]。用
式中:
对节点
式中:
假设
针对某固定网络, 其总边数
以
1.3.3 更新顺序改进
标签传播算法中节点更新顺序是随机的, 若依据设定顺序进行更新, 则将大大提高网络聚类稳定性。H指数为信息计量学中体现学者贡献的指标[11], 可有效衡量节点重要性, 所以本节通过H指数对标签算法更新顺序进行改进。节点H指数可描述为:
式中:
对节点的局部影响力进行分析, 这里将采用归一化的度值作为节点
式中:
节点
节点
式中:
实验部分对本文所提的基于改进标签传播算法的网络聚类方法进行验证, 实验结果取100次运行均值。
实验数据集选择LFR基准网络数据集和真实网络数据集, LFR网络为典型的人工形成测试数据集, 将节点数量设置为800, 平均节点度设置为30, 网络混合系数依次取0.4、0.5、0.6和0.7。真实网络数据集随机选择4个典型网络:Karate、Dolphin、Jazz和Email。
实验选用NMI、模块度两个指标对网络聚类结果进行衡量[12, 13, 14]。模块度为网络结构和与其有相同期望度序列的随机网络间的差异, 模块度越高, 聚类结果越准确, 计算公式如下:
式中:
NMI可通过下式求出:
式中:
在LFR基准网络中, 混合系数越低, 网络结构越简单。混合系数为0.4和0.5时, 网络结构较为明显, 混合系数为0.6和0.7时, 网络结构较为复杂。将克隆方法和人工免疫方法作为对比, 比较3种方法对LFR基准网络数据集的NMI指标和模块化指标, 如表1和表2所示。
| 表1 三种方法针对LFR基准网络的NMI比较结果 Table 1 NMI comparison results of three methods for LFR reference network |
| 表2 三种方法针对LFR基准网络的模块度比较结果 Table 2 Modularity comparison of three methods for LFR baseline network |
分析表1和表2可知, 在网络结构较为简单的情况下, 3种方法网络聚类NMI与模块度指标相差不大。但是, 随着混合系数的逐渐增加, 网络结构越来越复杂, 与克隆方法、人工免疫方法相比, 本文方法在NMI和模块度上均有很大的提高, 在混合系数达到0.7的情况下, 克隆方法、人工免疫方法NMI和模块度均低于0.1, 已经失去了网络聚类的意义, 然而本文方法仍可有效聚类, 说明本文方法聚类效果佳。
真实数据集网络结构较为复杂, 针对Karate、Dolphin网络进行了NMI与模块度的比较, Jazz和Email因为无已知网络结构, 仅进行模块度的比较。3种方法比较结果分别用表3和表4进行描述。
| 表3 三种方法针对真实网络的NMI比较结果 Table 3 Comparison results of three methods for real network NMI |
| 表4 三种方法针对真实网络的模块度比较结果 Table 4 Comparison results of three methods for real network module degree |
分析表3与表4可知, 在真实数据集的4个网络中, 本文方法在模块度上明显高于人工免疫方法和克隆方法, 在Karate、Dolphin网络中, 本文方法NMI比人工免疫方法和克隆方法也明显更高, 说明本文方法网络聚类结果比其他两种方法更加稳定和准确。
提出了一种新的基于改进标签传播算法的网络聚类方法。用图对网络进行描述, 给出了采用标签传播算法实现网络聚类详细过程。针对标签传播算法的弊端进行了改进, 依据改进后结果, 按照标签传播算法网络聚类过程实现聚类。实验结果表明, 本文提出的网络聚类方法的准确性和稳定性更高。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|