

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多尺度特征融合的边界检测算法
[车翔玖1  , 王利
, 王利2 , 郭晓新1 ]
, 王利|
|


作者简介:车翔玖(1969-),男,教授,博士生导师.研究方向:计算机图形学,大数据可视化.E-mail:chexj@jlu.edu.cn
针对以往边界检测算法提取的噪声边界过多,导致最终检测的效果提高不多的问题,本文提出了一种基于多尺度特征融合的边界检测算法。在单一图像尺度下,该算法利用图像抠图领域的Trimap和抠图算法生成图像中物体层次特征,并结合提取多尺度的像素层次特征得到边界信息。为了进一步减少过多的噪声边界,该算法提取多尺度图像下的边界信息,并通过融合这些边界信息来过滤噪声边界。在美国加州伯克利大学的BSDS500数据集上进行实验,实验结果表明该算法比单一图像尺度下的边界检测算法具有更高的准确率。
Prior contour detectors based on single scale input images usually extract multi-scale low-level cues to increase the detection accuracy, however, this kind of methods do not improve accuracy much due to the extracted noisy boundaries. The reason behind this is the lack of object-level features. To address this problem, this paper proposes a boundary fusion method which is capable of combining low-level and object-level cues on multiple scales. For a single scale image, at the beginning, we use Trimaps and an image matting method to generate object-level features, then we combine the object-level features with extracted low-level cues. For multi-scale images, we fuse the boundary maps extracted from each single scale image to reduce noisy boundaries. Experiments show that our method outperforms the single-scale boundary detector on the BSDS500 dataset.
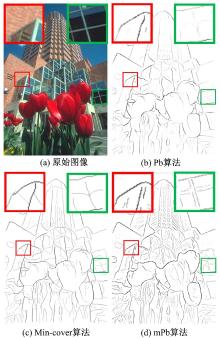
在计算机视觉领域, 物体的边界或轮廓信息对于物体的检测、分类和识别起到重要作用[1, 2, 3]。精准的边界信息可以有效的提取移动目标结构以及追踪目标[4, 5, 6]。目前, 从给定图像中准确检测和提取与背景相近的弱边缘仍然是一项挑战。在早期提出的边界检测算法中, 诸如Roberts[7]、Sobel[8]、Prewitt[9]、Canny[10], 主要在单一图像尺度上通过亮度梯度信息来检测边界。Pb(Probability of boundary)算法[11]在亮度梯度基础上提出引入颜色和纹理特征, 一定程度上提高了检测精度。这类基于像素层次检测的方法正被具有物体层次特征的算法改进, 例如CRF算法[12]和Min-cover算法[13]。基于物体层次的边界检测算法提出将图像中物体层次特征和像素层次特征结合能够得到更好的检测效果。至此, 边界检测算法可以分为两类:基于像素层次特征的边界检测算法(以下简称单层次算法)以及结合像素层次特征和物体层次特征的边界检测算法(以下简称双层次算法)。
因为单层次算法输出的边界线通常存在断裂或不连续的问题, 为了得到更加连续的边界线, 双层次检测算法通常将像素层次算法的输出做为它们的输入。例如, Pb [11]算法得到的边界图被作为CRF(conditional random fields) 算法的输入。然后CRF会进一步处理得到更加平滑以及连续的边界图。另外, Min-cover算法利用解决数学中最小覆盖问题的方法去连接Pb算法得到的不连续边界线。单层次算法mPb[14]引入多尺度的亮度, 颜色和纹理特征的提取思想, 但由于该算法敏感于图像中细小特征变化, 导致提取出过多的噪声边界。
受到CRF和Min-cover算法提出的物体层次特征启发, 本文尝试将其与mPb算法得到的像素层次特征融合, 以减少噪声边界。但与前面提到的CRF和Min-cover算法不同, 本文提出利用图像抠图(Image matting)领域里的Trimap和抠图算法来提供图像中物体层次的特征[19]。假设图像中前景物体为目标物体, 那么目标物体与背景之间的边界即为物体层次的边界。对于单一尺度的图像, 本文利用Trimap和抠图算法来生成物体层次特征的边界图, 并将它与像素层次的特征结合得到单一图像尺度下的边界图。然后本文融合多种图像尺度下得到的边界图, 最终得到融合的边界图。在美国加州伯克利大学的BSDS500[14]测试集上的实验表明, 本文提出的融合算法具有比mPb算法更好地检测精度。
无论是CRF还是Min-cover算法都是试图从单层次算法输出的断裂的边界线中寻找可能的物体层次边界并连接断线。因此, Min-cover算法检测的边界比Pb算法更连续。Arbelaez等人[14--18] 从单层次算法入手, 提出将多尺度的亮度, 颜色和纹理特征加入到检测算法里, 并提出多尺度特征的像素层次检测算法mPb。该算法通过加入多个像素级特征, 有效的连接了Pb算法的断裂边界线, 得到比Min-cover算法更好的检测结果(见图1)。
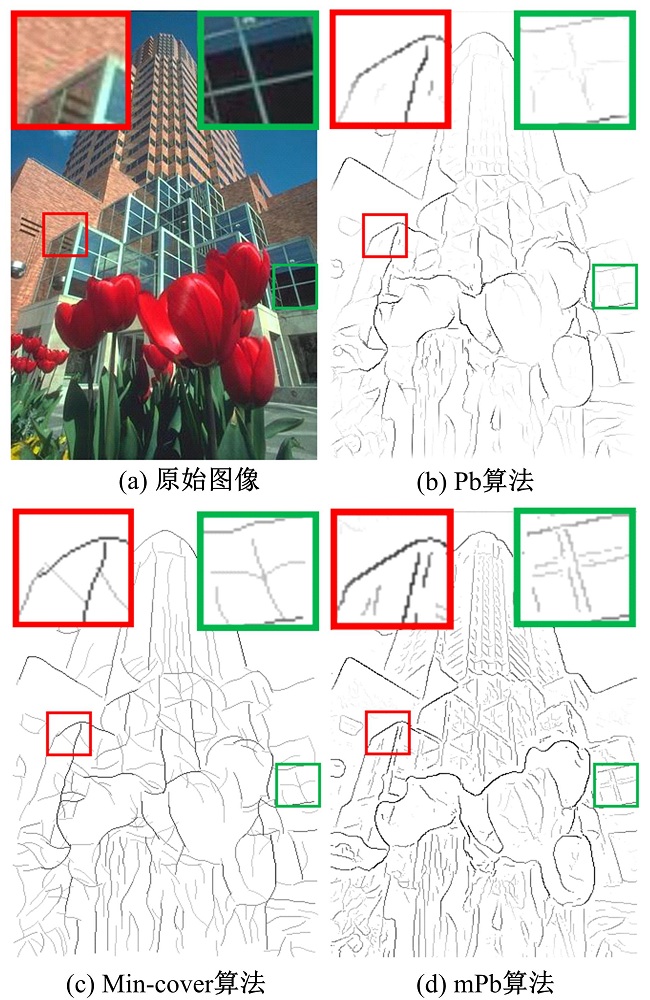 | 图1 不同算法检测结果Fig.1 Detection results of different methods |
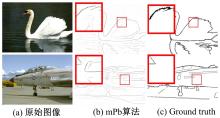
但mPb算法过于敏感于图像中细小的亮度, 颜色和纹理的变化, 导致过多的提取出噪声边界。如图2, 因为缺少物体层次信息约束, mPb算法提取出天鹅和飞机身上细小的边界线, 而这些边界线在ground truth中并不出现。因此, mPb算法边界检测的准确性有待提高。
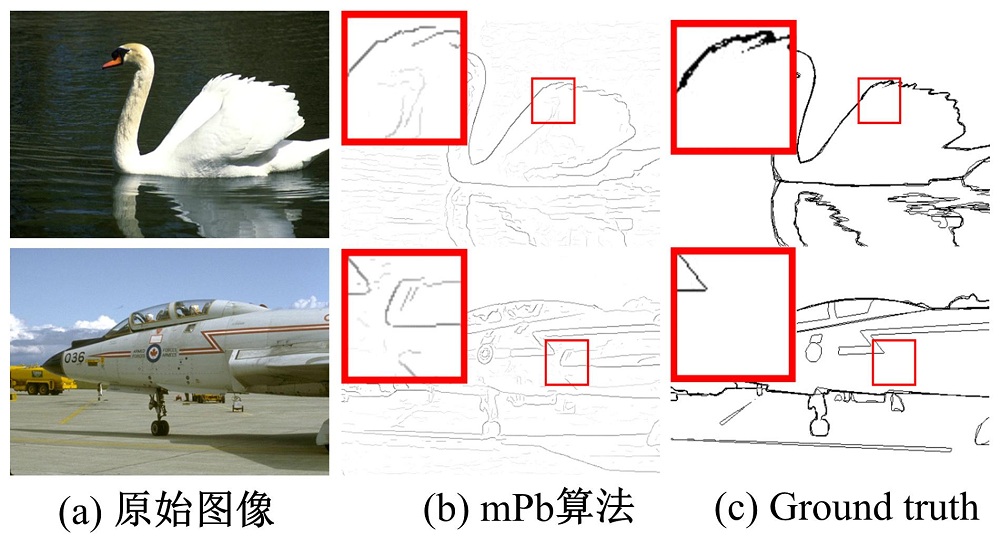 | 图2 mPb算法检测结果Fig.2 Detection result of mPb method |
为了解决mPb算法提取过多噪声边界的问题, 本文受图像抠图领域前景与背景存在语义上边界的启发, 提出由Trimap和抠图算法生成的抠图图像(alpha matte estimation)来提供图像中物体层次边界, 并提出多尺度图像像素层次特征和物体层次特征相融合的边界检测算法。该算法可以在保留物体层次边界的基础上, 减少过多的噪声边界。
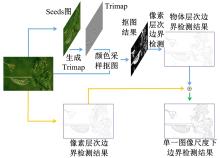
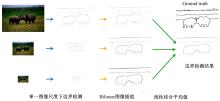
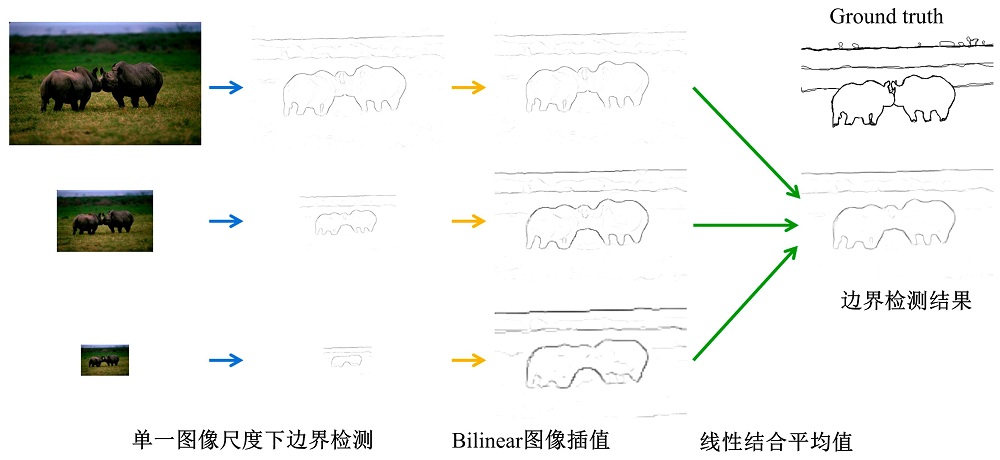
本文单一图像尺度下边界检测整体算法框架见图3。从原始图像开始, 分为上下两个平行阶段。在上阶段(蓝色), 原始图像中物体首先被少量人工标注形成Seeds图, 其次生成Trimap图, 然后原始图像和Trimap图会被输入到抠图算法(如颜色采样抠图算法[20])进行抠图处理, 最后通过像素层次边界检测算法提取出物体层次边界图。在下阶段(橙色), 原始图像会直接被像素层次算法提取出像素层次边界图。最终, 像素层次边界图和物体层次边界图进行线性组合输出最终单一图像尺度下的边界检测结果。
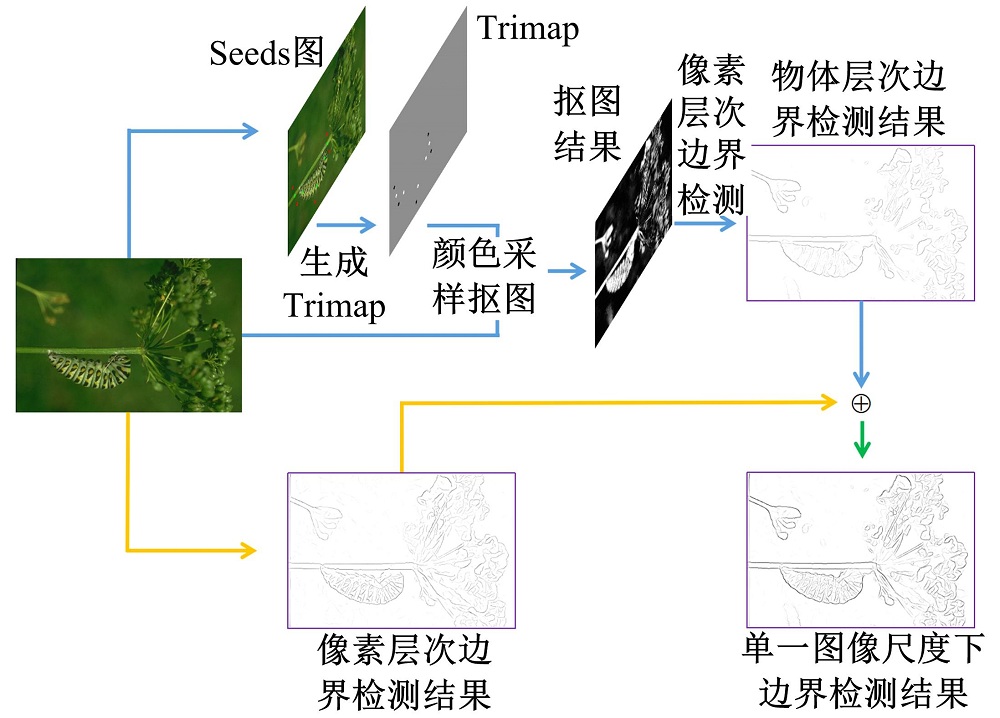 | 图3 本文单一图像尺度下边界检测算法框架图Fig.3 System pipeline for proposed single-scale boundary detector |
在早期的边界检测算法中, 图像的亮度梯度是作为计算像素层次边界的主要特征。例如, Rorberts[7], Sobel[8]和 Prewitt[9]通过计算图像中像素点的一阶导数来得到图像数据中亮度的梯度。Canny[10]通过计算亮度通道上像素值的不连续来确定提取的边界, 并通过非极大值抑制技术来有效的去除被错误检测的边界点。蚁群算法ACO(Ant colony optimization) [20] 通过将亮度作为启发信息素来模拟自然界中蚂蚁寻找食物的过程。在此过程中, 蚂蚁智能体释放信息素在走过的路径上, 最终形成边界。
在亮度梯度的基础上, 一些边界检测算法将图像中的颜色和纹理也作为计算边界的特征。例如, Pb算法构建一个线性回归分类器, 将图像的亮度梯度, 颜色和纹理输入到这个分类器中来预测边界图。Pb算法的基础理论是计算方向梯度信号
其中, 假设两个半圆含有相同的
Arbelaez等[14] 将不同尺度的直方图中四个梯度作为输入, 提出多种尺度像素层次特征multiscalePb(x, y, θ ):
式中:
最后, 取像素点
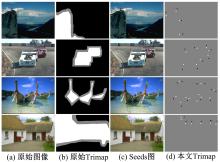
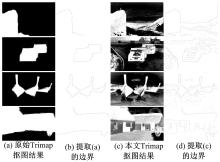
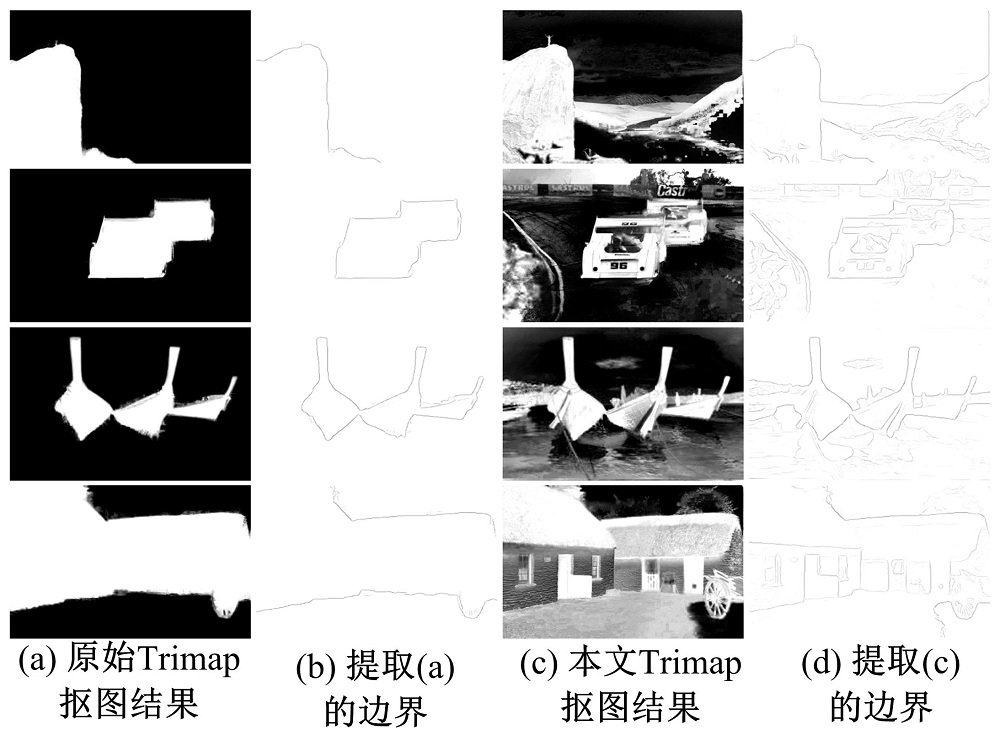
在引言中, 本文假设图像中前景物体和背景之间的边界是物体层次的轮廓边界。在图像抠图领域, 图像中前景物体和背景在Trimap图中由白色和黑色区域来标注, 剩下的灰色区域是需要精准确定的前景和背景的边界, 也是图像抠图算法需要计算的部分。如图4(b)所示, 白色和黑色区域需要被人为标注。传统的Trimap图需要大量的人为标注信息。如果本文想利用Trimap来提取物体层次边界, 应该尽可能少地利用人为标注信息, 否则大量的标注信息将使得检测边界变得无意义。因此, 本文提出了一种仅需要非常少的标注点的Trimap生成方法。
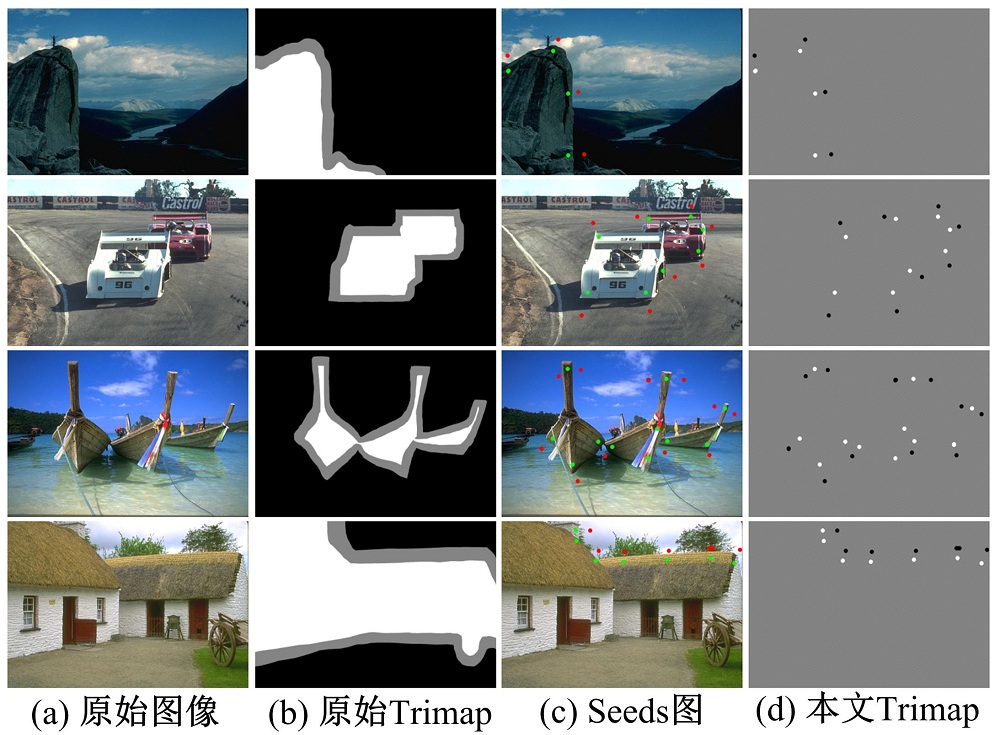 | 图4 原始Trimap和本文Trimap检测结果Fig.4 Detection resuits by traditional Trimaps and our proposed Trimaps |
对于图像抠图算法来说, 由Trimap提供大量的前景区域、背景区域以及不确定区域是抠图算法的重要前提。因为抠图算法需要能够达到提取图像中头发丝(如果有头发部分的话)的精确程度。相比于抠图算法, 边界检测对Trimap要求是不需要如此精确, 事实上, 大量的区域标注对于自然图像来说, 也是不现实的。因为一张自然图像可能包含诸多的物体实例, 比如图4(a)栏的第二张赛车图像中包含两辆赛车, 旁边的草丛, 后面的广告牌以及人和树木等物体。如果图像中每一个物体都需要人为标注, 这显然也是不现实的, 而且从图4(b)也能看出, 从原始Trimap抠图得到的结果也只会是赛车与背景的边界, 那么广告牌和天空的边界, 树木与天空的边界就都会丢失。本文深入到图像抠图算法(如颜色采样抠图[20]), 发现抠图算法中具有像素值从前景区域(即数值1)到背景区域(即数值0)扩散的过程, 那么利用此扩散过程有可能将未被标注的物体(原背景区域)变换成前景区域。基于这个想法, 本文提出一种Seeds图像(见图4(c)), 即在原始图像上加入少量前景和背景的标注点, 先生成对应Trimap图像(见图4(d)), 在利用抠图算法[20]将图像中未标注物体生成为前景区域(见图5(d))。
 | 图5 原始Trimap的抠图结果与本文Trimap的抠图结果Fig.5 Alpha matte estimation results generated by traditional Trimaps and our proposed Trimaps |
在图4(c)中, Seeds图中的绿点和红点分别表示前景和背景。在图4(d)中, 白色、黑色和灰色分别表示前景区域、背景区域以及不确定区域。在本文的所有实验中, 图像中一个物体最多只标注4对前景和背景点。
本文采用颜色采样抠图[19](Color sampling matting)算法计算抠图结果(Alpha matte estimation)。生成后的Trimap以及原始图像将作为颜色采样抠图算法的输入, 最终生成抠图结果(见图5(d))。如图5(d)所示, 相比于原始Trimap仅生成标注物体与背景的边界, 抠图算法将本文Trimap图中少量的前景区域(原白色点)扩展至全图的白色区域, 使得本文Trimap图中未被标注的物体被自动标注成前景区域, 并在前景物体与背景之间形成具有亮度梯度变化巨大的边界。因为本文仅专注于边界检测, 因此上述抠图算法不做进一步详细介绍, 详见参考文献[19]。
在图5(d)中, 可以看到原始图像中的前景物体都被自动标注出来, 接下来将抠图结果利用前面提到的mPb算法提取边界, 得到的结果如图6(d)所示。
 | 图6 物体层次边界图Fig.6 Boundary maps on object-level |
相比于原始mPb算法提取的边界图, 物体层次边界有效过滤掉了一些噪声边界。但由于边界图缺少有效的细节边界, 导致检测结果不比mPb算法好。基于此, 本文提出通过加权组合像素层次边界和物体层次边界来过滤噪声边界并保留有效边界。
在单一尺度图像下, 利用第1单元的边界检测算法mPb(x, y)去检测由颜色采样抠图算法计算的抠图结果, 得到物体层次的边界图
式中:
在多尺度图像下, 通过如下公式得到最终边界图:
式中:
结合以上信息, 本文提出的多尺度特征融合的边界检测算法框架见图7。可以看到, 小尺度图像检测的边界图具有明显的物体层次特征却缺少像素层次特征。大尺度图像的边界图提取出非常丰富的像素层次特征。那么多尺度边界图结合将在保留物体层次特征的同时过滤掉过多的噪声边界。所以, 多尺度特征融合的边界图将得到更好的检测结果。
 | 图7 本文多尺度特征融合边界检测算法框架图Fig.7 Ppipeline of our proposed multi-scale boundary detection algorithm |
为了表明本文提出的多尺度特征融合
给定一张边界图, F-measure被用来表示该边界图在数据集尺度上的最佳评估值(Optimal dataset scale, ODS)和图像尺度上的最佳评估值(Optimal image scale, OIS)。
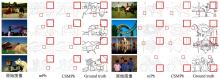
图8和图9, 给出部分BSDS500测试集的对比实验结果。可以很明显的看到本文提出的CSMPb算法减少了mPb算法提取的噪声边界(如图8中第二排对比), 并且填补mPb得到边界图中的断点(如图8中第三排右侧对比和图9中第一排左侧对比)。在图8第二排右侧对比中, 可以看到mPb算法提取出了树梢间细小的间隙边界, 而Ground truth中将树梢和树干等更倾向于看作一个具有整体语义结构的物体。本文提出的CSMPb算法通过结合多尺度的物体层次边界和像素层次边界, 有效的减少了树梢间隙等细小的噪声边界并保留整体语义结构的边界, 因而得到更好的检测效果。
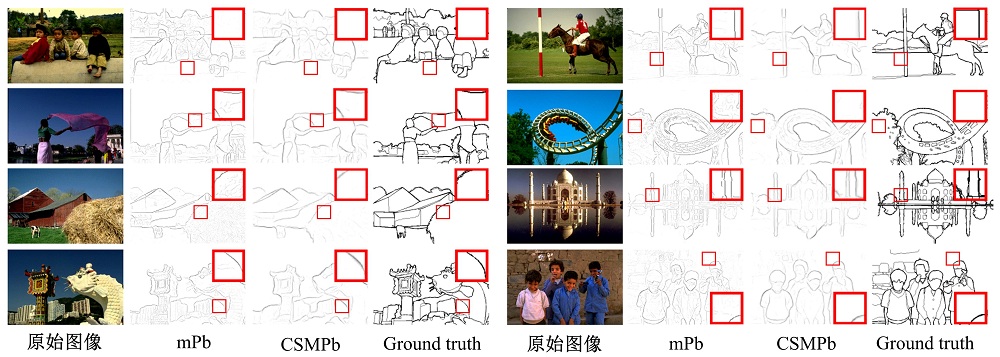 | 图8 部分BSDS500测试集结果对比Fig.8 Selected comparisons between mPb and CSMPb on BSDS500 test images |
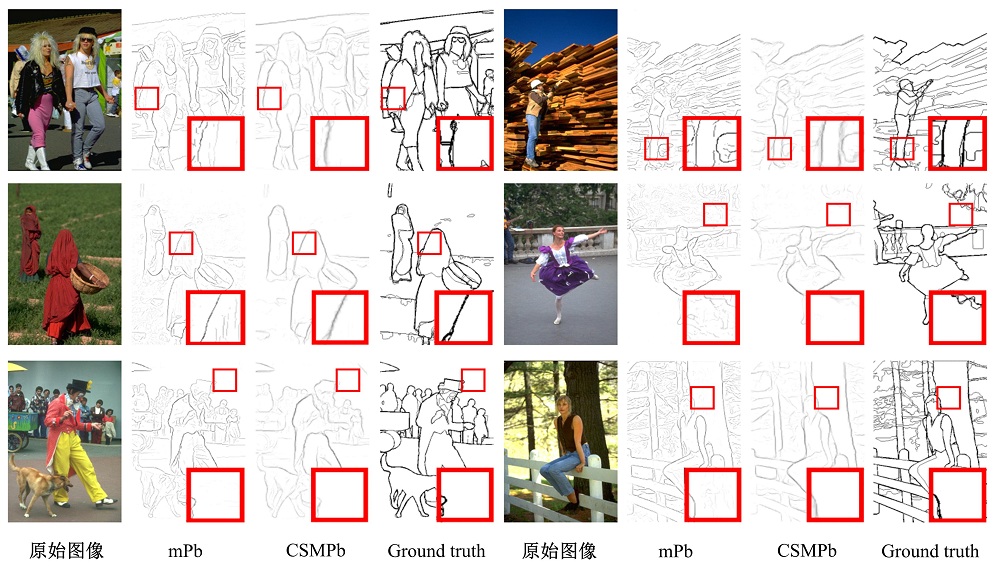 | 图9 部分BSDS500测试集结果对比Fig.9 Selected comparisons between mPb and CSMPb on BSDS500 test images |
在图8第三排右侧对比中, 可以看到mPb算法提取出了断断续续的柱子外层轮廓边界, 而CSMPb算法则提取出完整并连续的外层边界。因而, CSMPb算法在有效减少噪声边界的同时, 还能提取出完整并连续的物体轮廓边界。
在图9中, 可以看到在原始图像具有丰富的细节边界的情况下, CSMPb算法在保持物体层次边界不变的同时有效的去除了mPb算法提取的噪声边界。如图9第一排左侧和第二排右侧对比中, CSMPb算法有效的去除掉mPb算法分别在袖口处和背景处的噪声边界, 得到更加接近于ground truth的实验结果。
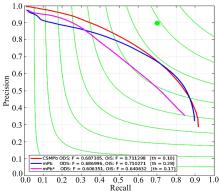
图10给出CSMPb算法, mPb算法和mPb* 物体层次边界在BSDS500测试集上的评估对比。可以看到, 无论是在数据集尺度(ODS)还是图像尺度(OIS)上, 本文提出的CSMPb算法都获得比mPb算法和mPb* 更高的F值, 并且在数据集上表现的方差值(th)更小。这说明CSMPb算法通过减少mPb算法提取的噪声边界, 提高边界的检测精度, 也验证了本文提出多尺度特征融合方法的有效性。mPb* 物体层次边界获得比mPb算法更低的F值, 这是因为mPb* 虽然具有更高的物体层次边界, 但由于缺乏大量自然图像中具有的细节边界, 再加上抠图算法在扩展前景区域时存在误差, 导致检测效果不好。 但通过将mPb* 提供的物体层次边界结合mPb算法的像素层次边界, 本文提出的CSMPb算法最终还是获得更好的边界检测结果。
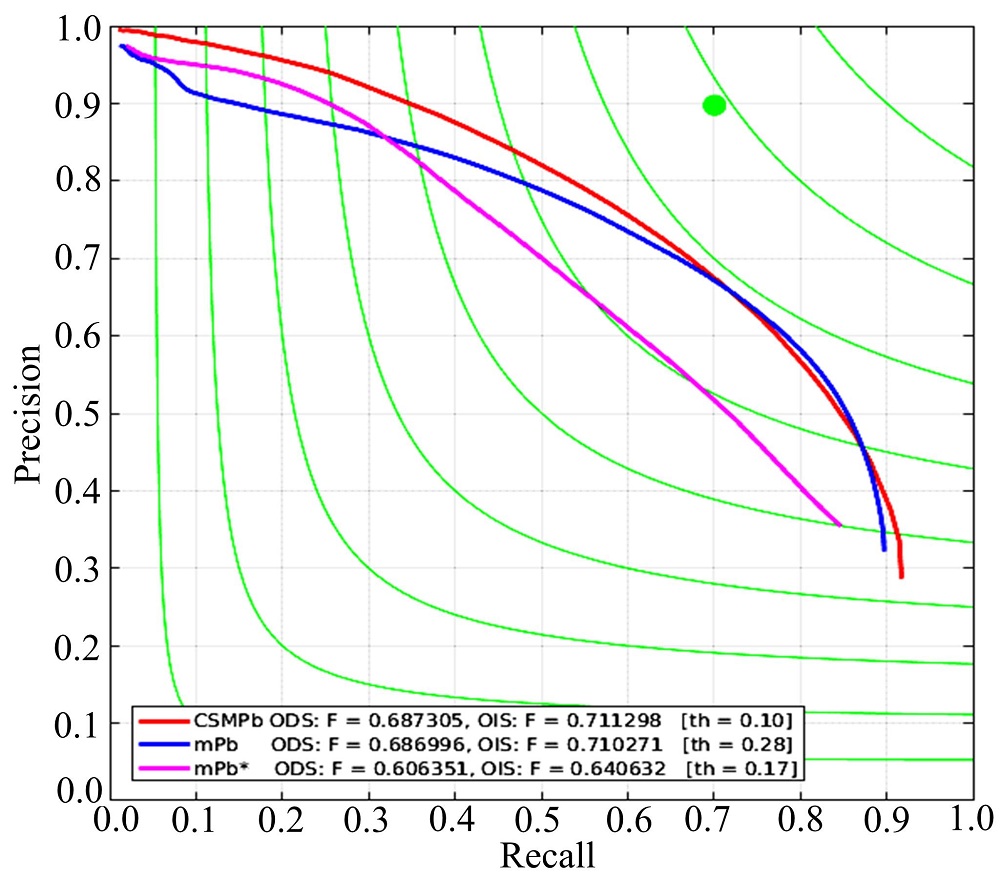 | 图10 BSDS500数据集评估结果Fig.10 Evaluation results on BSDS500 dataset |
给出CSMPb算法和mPb算法在图8示例图上的F-measure值对比。可以看到, CSMPb算法得到比mPb算法更高的F-measure值, 同时也验证主观对比的结果。
| 表1 图像尺度上F-measure值的对比(与图8中位置对应) Table 1 F-measure comparison on OIS (in that order of Fig.8) |
像素层次边界检测在引入多尺度亮度, 颜色和纹理特征后, 存在对图像细小边界过于敏感的问题, 导致提取过多的噪声边界。本文针对这一问题, 结合物体和像素双层次特征, 并以多尺度特征融合方式, 提高了边界检测的准确度。在美国加州伯克利BSDS500标准数据集上的实验结果表明, 本文提出的算法在主观对比和定量分析上降低噪声边界的有效性。本文提出的边界检测算法虽然在静止的自然图像上得到了一些提高, 但它仍然是半自动的检测算法, 这约束了其未来可能在视频中的应用。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|