
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
动态约束下可重构模块机器人分散强化学习最优控制
[董博1  , 刘克平
, 刘克平2 , 李元春2 ]
, 刘克平]
|
|


作者简介:董博(1986-),男,博士研究生.研究方向:智能机械与机器人控制.E-mail:bodong09@mails.jlu.edu.cn
基于ction-critic-identifier(ACI)与RBF神经网络,提出了一种外界动态约束下的可重构模块机器人分散强化学习最优控制方法,解决了存在强耦合不确定性的模块机器人系统的连续时间非线性最优控制问题。文中将机器人动力学模型描述为一个交联子系统的集合,基于连续时间MDPs性能指标,结合ACI与RBF神经网络,对子系统最优值函数,最优控制策略及总体不确定项进行辨识,使系统满足HJB方程下的最优条件,从而使可重构模块机器人子系统渐进跟踪期望轨迹,跟踪误差收敛且有界。采用Lyapunov理论对系统稳定性进行证明,数值仿真验证了所提出的分散控制策略的有效性。
Based on Action-Critic-Identifier (ACI) and Radial Basis Function (RBF) neural network, a novel decentralized reinforcement learning optimal control method for time varying constrained reconfigurable modular robot is presented. The continuous time nonlinear optimal control problem of strongly coupled uncertainty robotic system is solved. The dynamics of the robot is described as a synthesis of interconnected subsystems. As a precondition to the continuous-time MDPs performance indicators, the optimal value function, optimal control policy and global uncertainty of the subsystems are estimated combing with ACI and RBF network. The optimal conditions of HJB equation with regard to the subsystem are satisfied, so that the reconfigurable modular robot system can track the desired trajectory in a short time and the estimation error can converge to zero in finite time. The stability of the system is confirmed by Lyapunov theory. Simulations are performed to illustrate the effectiveness of the proposed decentralized control scheme.
可重构模块机器人是一类具有标准接口与模块可以根据不同的任务需求对自身构形进行重新组合与配置的机器人。根据模块设计的概念及子系统分散控制理论,可重构模块机器人可以在不同的外界环境与约束下根据不同的任务需要来改变自身构形,且不需要重新设计控制器。此外,可重构模块机器人的模块关节还包括了通讯、驱动、控制、传动等单元,使重构后的机器人对新的工作环境具有更好的适应性。
许多学者对可重构模块机器人的动力学与控制方法进行了研究。文献[1]提出了一种基于VGSTA-ESO的可重构模块机器人分散自抗扰控制方法,文中设计了一种高精度VGSTA-ESO,用来对子系统模型非线性项与子系统交联项进行辨识,从而实现关节轨迹跟踪控制。基于计算力矩法,文献[2]提出了一种基于速度观测模型的可重构机械臂模糊RBF神经网络补偿控制方法,通过Lyapunov函数对神经网络权值、隶属度函数中心与宽度进行更新,并证明补偿控制算法一致有界。文献[3]提出了一种可重构模块机器人分散自适应模糊滑模控制方法,采用模糊逻辑系统估计子系统未知动力学模型,并通过带有自适应结构的滑模控制器补偿交联项及模糊估计误差。文献[4]提出了一种基于观测器的可重构模块机器人自适应模糊控制器,采用自适应模糊系统对子系统未知动力学模型进行辨识,并通过状态估计的方式来重构子系统交联项。
近年来,可重构模块机器人系统的最优控制问题成为机器人控制领域研究的热点与难点之一,而强化学习算法自诞生之日起就被认为是解决此类问题最有效的方法。强化学习是一种从环境到行为映射的学习方法,其目的是将环境中的报酬与评价信号最大化。与监督学习相比,强化学习不需要预知各种状态下的导师信号,而是在与环境的交互过程中学习,由于其具有在非线性模型不确定性条件下的自适应优化能力,因而在解决复杂模型的优化策略与最优控制等问题方面有着独特的优势[ 5, 6, 7, 8]。
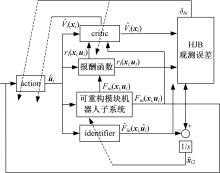
本文基于马尔可夫决策过程(Markov decision processes,MDPs)连续时间性能指标,将ACI与RBF神经网络相结合,在外界动态约束下提出一种可重构模块机器人分散强化学习最优控制策略,解决了存在强耦合不确定性的模块机器人的连续时间非线性最优控制问题。采用ACI对系统Hamilton jacobi bellman(HJB)方程进行辨识,其中critic网络可以辨识系统最优值函数,action网络用来辨识系统最优控制策略,最后通过identifier网络对系统模型非线性项与子系统交联项进行辨识,并利用RBF神经网络对ACI网络权值进行更新,使系统满足HJB方程下的最优条件,以此来满足机器人子系统对期望轨迹的跟踪要求。
可重构模块机器人末端所受外部动态约束为:
式中:
在动态约束下,
式中:
在对自由空间运行的模块机器人引入
定义关节变量表示形式如下:
将式(3)代入式(1)可得:
其中,
对式(4)求导可得:
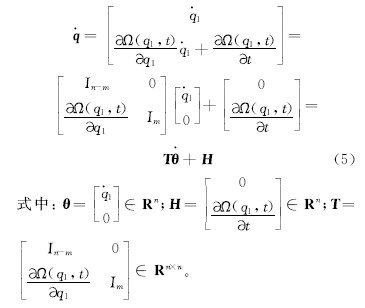
对
将式(5)(6)代入式(2)可得:
定义
式中:
子系统动力学模型可以改写为:
令
式中:
本文基于MDPs连续时间性能指标,针对外界动态约束下的可重构模块机器人子系统动力学方程建立HJB方程,结合ACI与RBF神经网络分别对HJB方程中的最优值函数、最优控制策略及子系统非线性项进行辨识,并设计权值更新率对网络权值进行更新,从而得出满足HJB方程的相应最优解,以此来满足动态约束下可重构模块机器人子系统关节轨迹跟踪要求。
假设1 期望轨迹
式中:
假设2 子系统交联项
式中:
定义一类马尔可夫决策过程为一个五元组:
式中:
式中:
若采用式(15)中的最优值函数

引理1[ 10] 对于给定式(13)的可重构模块机器人子系统,若要保证式(17)中的HJB方程的极值相对于
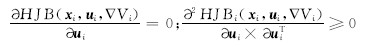
若上述条件满足,则可以得出下列结论:
(1)采用有界控制策略
(2)系统Hessian矩阵正定,所采用的控制策略
(3)如果最优控制策略存在,那么它是唯一的。
若报酬函数光滑,且采用最优控制策略
其中,最优控制策略可以表示为:

由式(18)(19)可知,若最优值函数
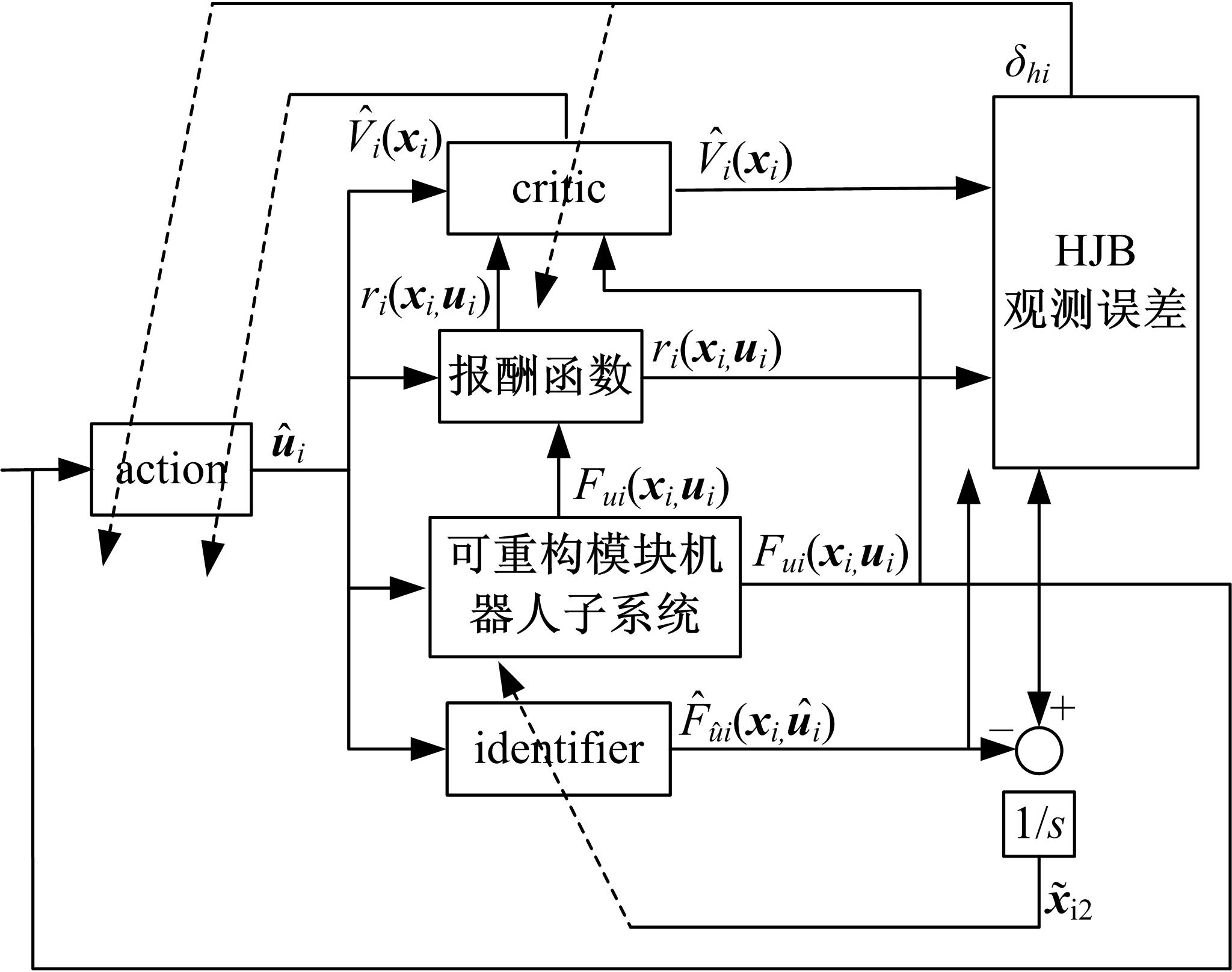 | 图1 action-critic-identifier结构框图Fig.1 Architecture of action-critic-identifier |
采用鲁棒神经网络identifier辨识系统不确定部分
HJB方程的辨识误差为:
对于一类经典RBF神经网络[ 11]可以表示为:
式中:
最优值函数与最优控制策略可以分别表示为:
式中:
采用critic网络和action网络分别对
式中:
critic网络权值可按如下LS更新率进行更新:
式中:
action网络的权值可采用如下的梯度更新率进行更新[ 8]:

式中:proj(·)为投影算子;
在对
式中:
为了解决非线性项对子系统的影响,设计一类鲁棒神经网络identifier对
式中:
式中:
identifier网络的状态估计误差为:
式中:
定义滤波辨识误差:
对式(38)求导可得:
对式(39)中的
由此,式(39)可以化简为:
其中,
由假设1及式(36)(37)(38)可知,
由式(42)(43)(44)可知:
定理 对于外界动态约束下的可重构模块机器人子系统动力学模型(9)及状态方程(13),若采用式(25)(26)(32)所示的critic网络、action网络及identifier网络分别对子系统的最优值函数
证明 定义Lyapunov函数:

对式(46)求导:
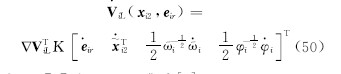
式中:
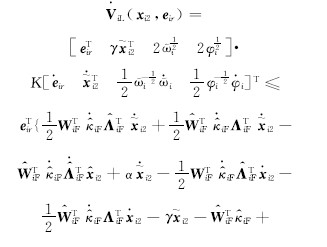
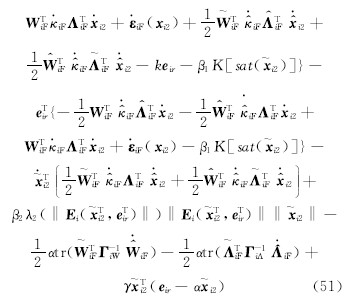
将式(42)(43)(44)代入(51),可得:
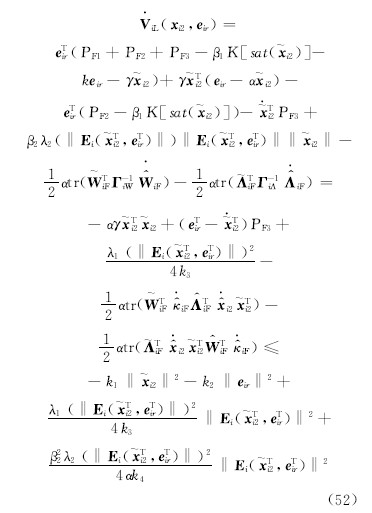

由此可知,对任意正常数c,则 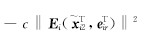
因此,根据Lyapunov稳定性理论可知,系统是稳定的。
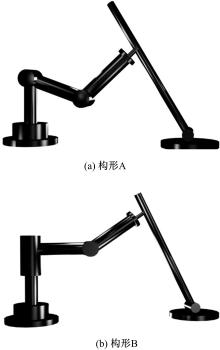
为了验证所提出的基于ACI的分散强化学习最优控制方法的有效性并考查误差的收敛情况,本文采用两组不同的二自由度受外界动态约束的可重构模块机器人构形来进行仿真。其中,构形实例如图2所示。
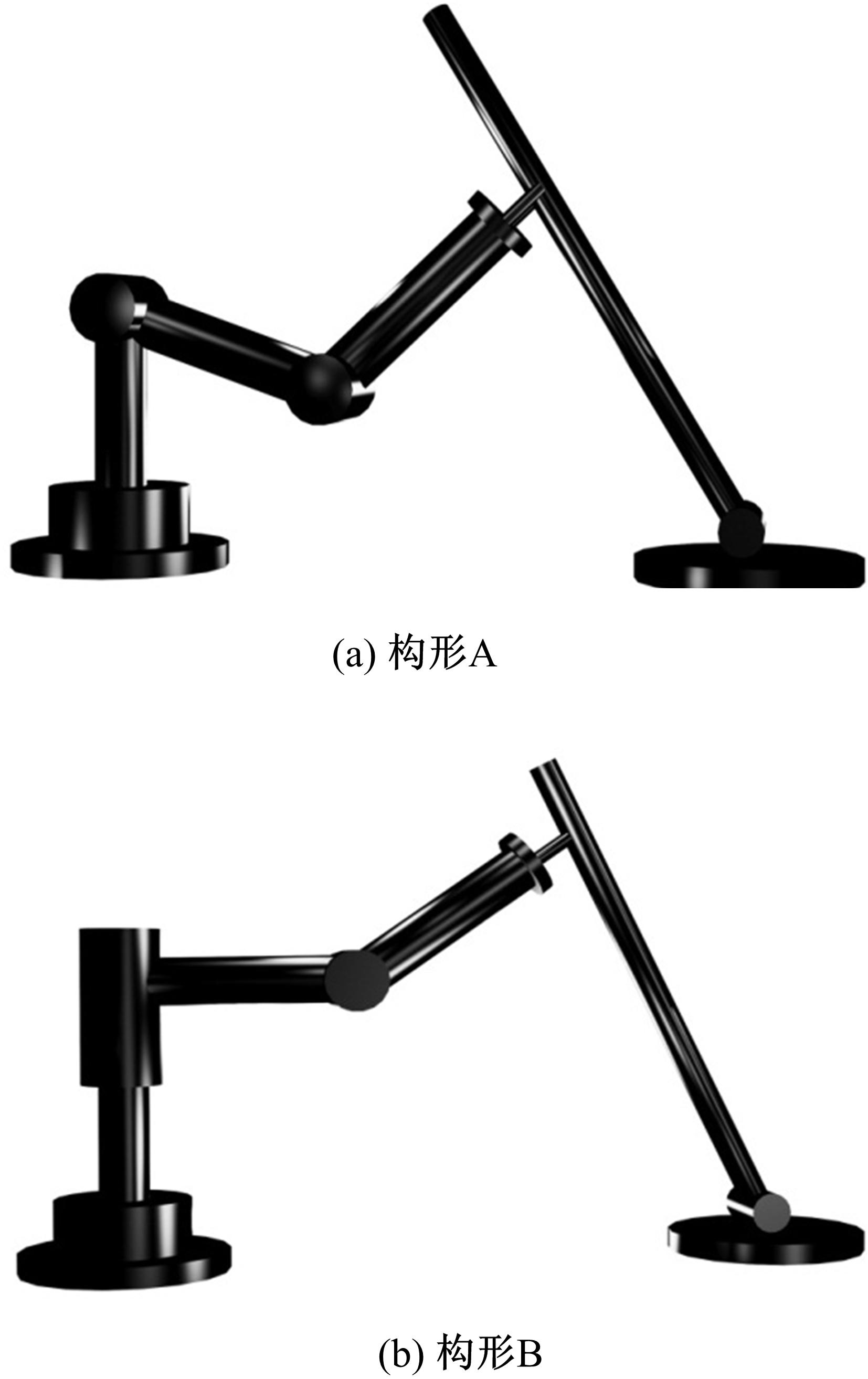 | 图2 动态约束下可重构模块机器人仿真图Fig.2 Configuration A and B for varying constrained robot |
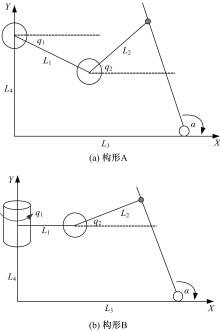
为了便于对上述构形实例进行分析,将上述构形转化为如图3所示的解析图。其中,外界动态约束可以定义为一类绕确定自由度旋转的长柱,构形A与构形B的约束方程如下:
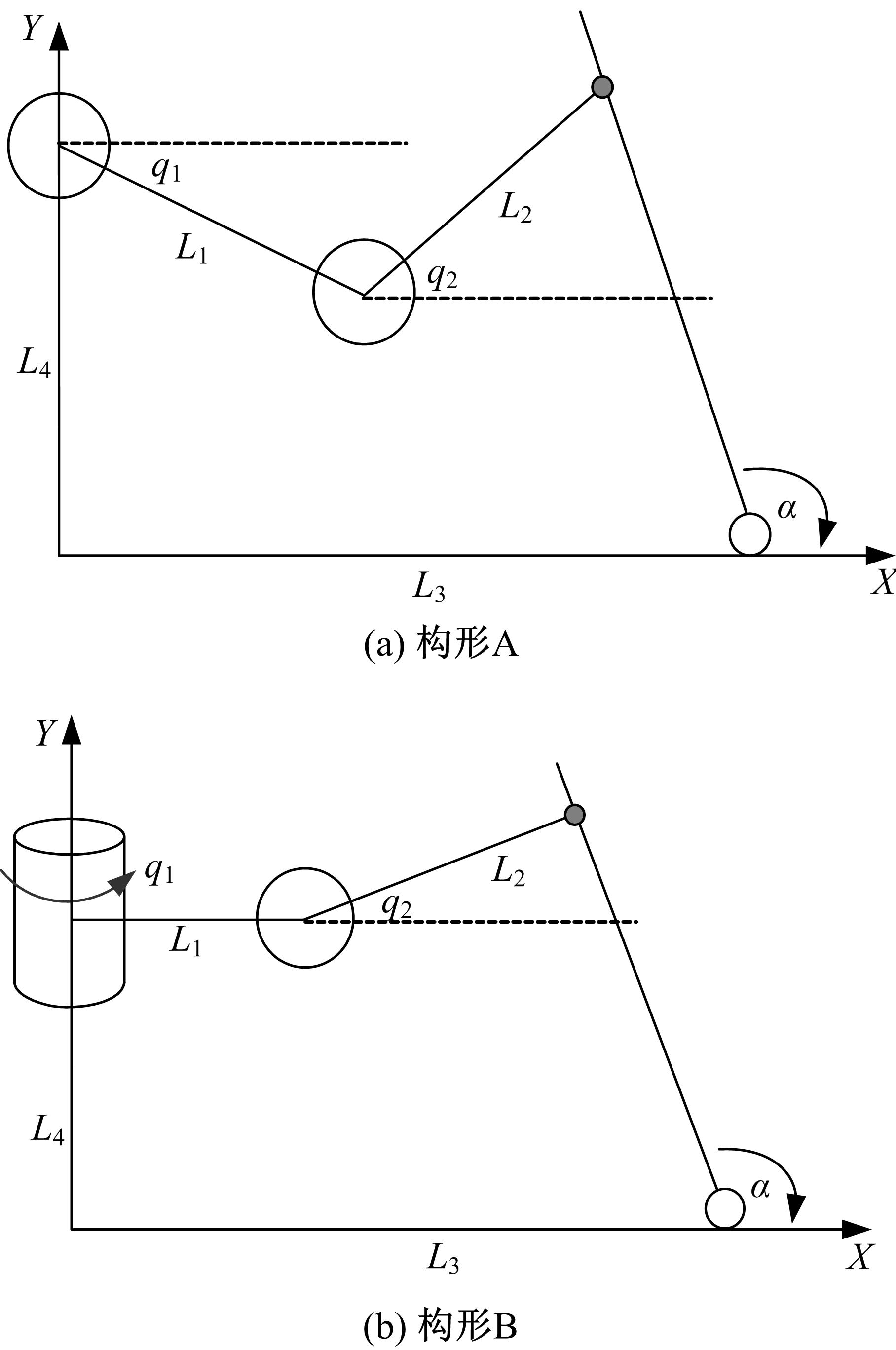 | 图3 解析图Fig.3 The analytic chart |
式中:
构形A与构形B的关节角初值定义为
构形A的期望轨迹如下:
构形B的期望轨迹如下:
其中,构形B由于外界动态约束的限制,关节1变量为零。ACI中所定义的参数如下:
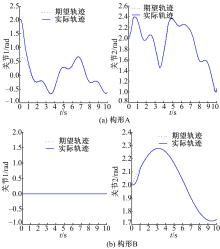
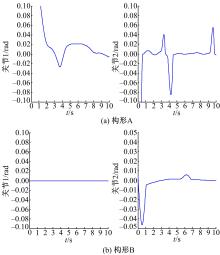
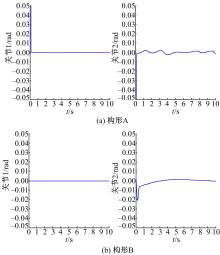
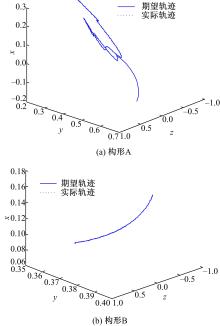
为了证实所采用的方法可以应用在不同的构形当中,并验证基于ACI的分散强化学习最优控制方法对子系统期望轨迹的跟踪性能,文中分别采用标准RBF神经网络控制方法与基于ACI的分散强化学习最优控制方法进行对比仿真。图4、图5为采用RBF神经网络补偿系统模型非线性项与子系统交联时的关节跟踪曲线及误差曲线。图6、图7为采用ACI对系统HJB方程中最优值函数、最优控制策略及模型非线性项进行辨识时关节的跟踪曲线及误差曲线。图8为采用ACI的末端轨迹跟踪曲线。通过仿真图可以看出:采用标准RBF神经网络对期望轨迹进行跟踪时,关节子系统跟踪速度较慢,且跟踪误差较大;而采用基于ACI与强化学习的分散最优控制策略后,关节子系统可以在0.2 s内跟踪期望轨迹,且跟踪误差小于±0.05。由此可知,基于ACI与强化学习的分散最优控制策略可以应用于不同构形的受外界动态约束的可重构模块机器人,且在不同构形中均可使子系统关节变量在极短的时间内跟踪期望轨迹,误差收敛且波动范围极小。
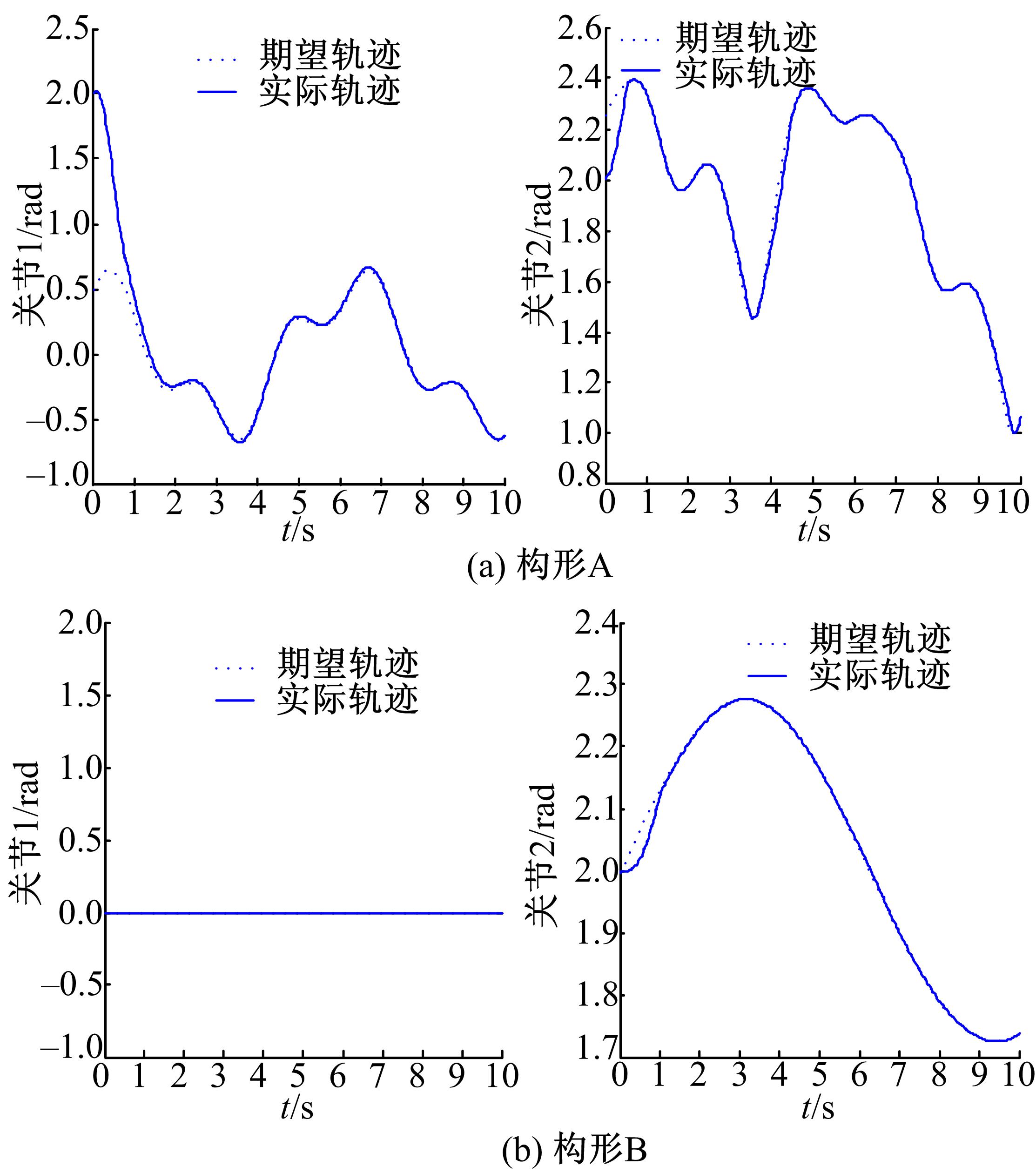 | 图4 采用RBF神经网络的轨迹跟踪曲线Fig.4 Trajectory tracking curve with RBF |
 | 图5 采用RBF神经网络的跟踪误差曲线Fig.5 Tracking error curve with RBF |
 | 图6 采用ACI强化学习的轨迹跟踪曲线Fig.6 Trajectory tracking curve with ACI |
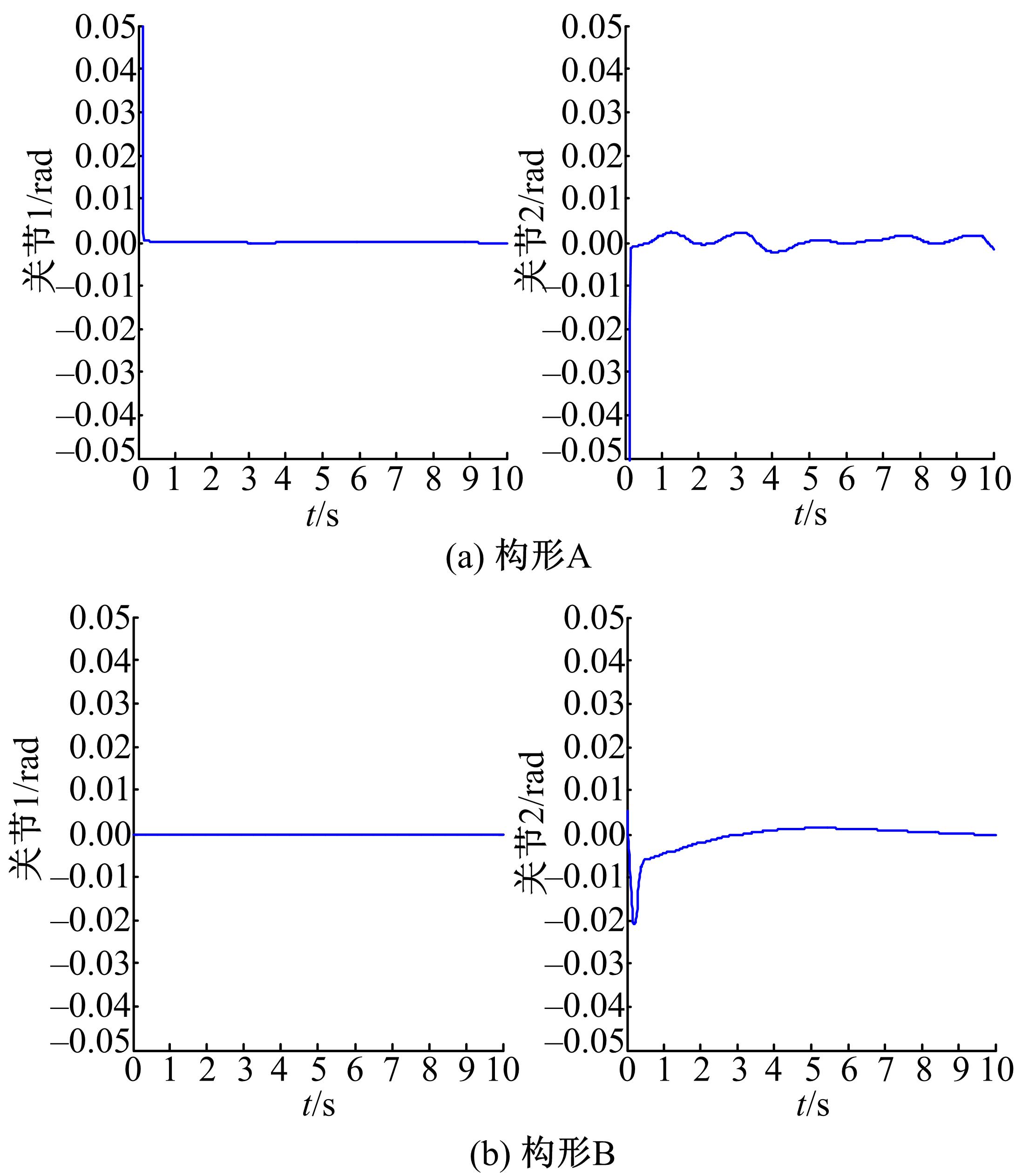 | 图7 采用ACI强化学习的跟踪误差曲线Fig.7 Tracking error curve with ACI |
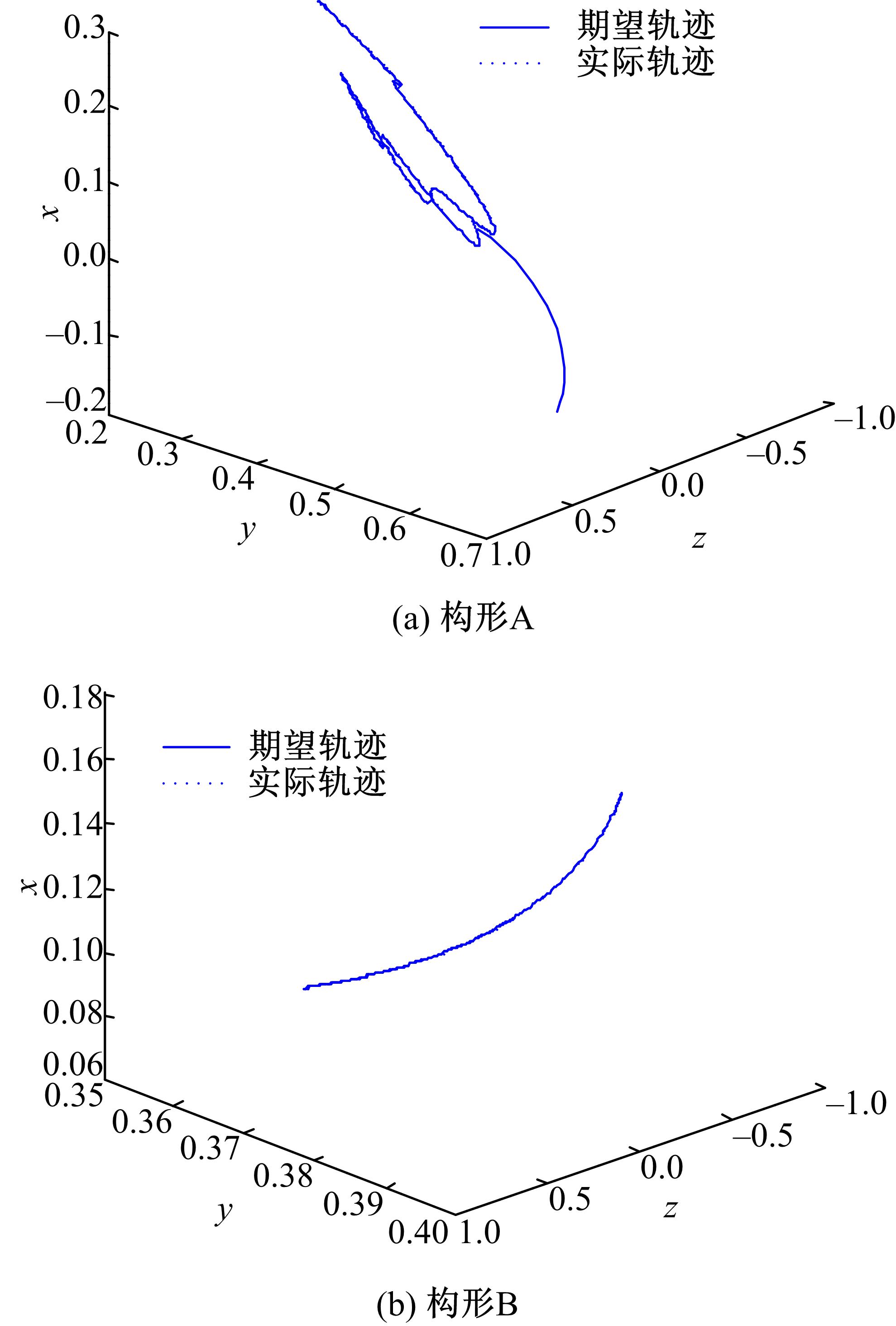 | 图8 采用ACI强化学习的末端轨迹Fig.8 Tip trajectory curve with ACI |
结合ACI和RBF神经网络,提出了一种外界动态约束下的可重构模块机器人分散强化学习最优控制方法,解决了存在强耦合不确定性的可重构模块机器人系统的连续时间非线性最优控制问题。首先,建立了存在外界动态约束下的可重构模块机器人动力学模型,并将其划分为交联子系统的集合。其次,以马尔可夫决策过程性能指标为基础,针对子系统状态方程定义最优值函数与最优控制策略的观念表达式,将模型非线性项与子系统交联项划分为一类总体不确定项,并设计子系统HJB方程。之后,采用ACI对HJB方程中相应的最优函数进行辨识,其中action网络用来辨识子系统最优控制策略,critic网络对子系统最优值函数进行辨识,再通过identifier网络对子系统总体非线性不确定项进行估计,从而使子系统满足HJB方程下的最优化条件,使可重构模块机器人子系统渐进跟踪期望轨迹,且跟踪误差有界收敛。通过Lyapunov理论,对所提出的分散强化学习最优控制策略进行稳定性证明。最后,通过对两组不同构形的可重构模块机器人进行数值仿真,进一步验证了所提出的分散控制策略的有效性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|