
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
片上网络的访存延迟均衡性
[李洋1, 2  , 陈小文
, 陈小文3 , 赵晓晖1 , 杨勇2 ]
, 陈小文, 杨勇|
|


作者简介:李洋(1978-),女,博士研究生.研究方向:无线网络通信理论和技术.E-mail:lyang@cust.edu.cn
对片上网络访存延迟均衡性展开了研究,提出基于总延迟预测的访存报文仲裁技术。首先,依据访存报文后续路径的拥塞信息预测访存报文未来等待延迟,并计算出总延迟。其次,基于预测的总延迟对竞争同一链路的访存报文进行仲裁。在Mesh片上网络路由器中,对该技术进行了设计和实现。实验结果表明:在不同的网络规模和报文注入率下,与经典Round-Robin仲裁机制相比,本文技术能够极大减少片上访存的最大延迟和延迟标准差,减少平均延迟,证明能够获得更佳的访存延迟均衡性。
A novel arbitration technique for memory access packets is proposed, which is based on the round-trip latency prediction. First, the congestion information in the subsequent path of memory access packets is used to predict the waiting latencies of the memory access packets in the future, and then the round-trip latencies are calculated. Second, the predicted round-trip latencies are used to decide the arbitration for the memory access packets contending for the same link. The proposed technique is designed and implemented in the routers of mesh-based NoCs. Experimental results show that, under different network sizes and packet injection rates, compared with the classic Round-Robin arbitration mechanism, the proposed technique can greatly reduce the maximum latency, the average latency and the latency standard deviation of on-chip memory accesses, and it is proved to achieve better latency equalization of memory access.
高性能片上系统(System-on-chips, SoCs)逐渐由单核系统发展到多核甚至众核系统[1, 2]。在众核系统中, 片上网络(Network-on-chips, NoCs)[3]由于具有良好的可扩展性被用于连接众多处理器核和存储资源, 片上存储资源已由十年前占芯片面积的20%上升到如今占芯片面积的85%[4]。在以片上网络为互连架构的众核系统中, 大量存储资源通常分散在各个节点, 构成分布式共享片上存储系统, 能够避免集中式存储带来热点区域和大的竞争延迟。处理器核和存储资源分散在不同节点, 这些节点可能是中心节点、边节点和角节点, 构成NUMA(Non uniform memory access)[5, 6]结构。由于通信距离的不同, 片上访存的行为也不同。随着网络规模的增加, 片上访存通信距离差异变大, 并且大量片上访存加剧网络竞争和拥塞, 导致不同访存之间的延迟差距变大, 易引起片上网络访存“ 木桶效应” 。本文旨在研究片上网络访存延迟均衡性, 缩短不同访存之间的延迟差异, 避免过大延迟访存的出现。对于访存延迟均衡问题, 之前的研究工作主要集中在对片外SDRAM的访存延迟均衡性研究, 文献[7]面向多处理器芯片(CMP), 提出一种SDRAM公平访存调度机制, 均衡访问共享数据和访问私有数据的延迟。文献[8-9]提出依据拥塞信息在SDRAM存储控制器中调度到达SDRAM的访存请求, 来自拥塞程度低的区域的访存请求优先被响应。文献[10]提出依据服务曲线理论(Service curve theory)来避免在SDRAM附近产生严重的拥塞, 从而保证延迟均衡。文献[11]提出一种访存敏感的片上网络路由器, 根据SDRAM访存延迟来进行网络开关仲裁。如今部分研究工作开始关注片上访存延迟均衡性, 文献[12]研究的是片上访存延迟和片外访存延迟之间的均衡性问题, 提出一种智能调度片上访存和片外访存的方法。文献[13]研究了片上网络延时差异对片外SDRAM访问公平性影响, 在存储控制器中对访存请求的调度加入了片上网络延时差异的因素。文献[14]研究了片上访存内部之间的延迟均衡性, 将一次完整的访存分成读写请求报文和读写响应报文, 并只针对读写响应报文进行调度。本文以一次完整访存的总延迟作为仲裁调度的基础来实现片上访存延迟均衡性研究。本文的一个重要工作就是依据访存报文后续路径的拥塞信息预测未来等待延迟, 从而估算出总延迟。
为了支持片上网络访存延迟均衡, 本文提出基于总延迟预测的访存报文仲裁技术, 包括总延迟预测方法和具有延迟均衡的路由器设计。
一次完整的片上访存包括去程部分的读写请求和回程部分的读写响应。随着网络规模的扩大和通信距离的增大, 本文认为, 为了使片上访存延迟更加均衡, 当多个访存报文竞争同一链路而需仲裁时, 最好以一次完整片上访存的总延迟为依据, 因为这样可以综合考虑当前片上访存报文的历史延迟和未来可能延迟来均衡各访存报文之间的延迟差异。
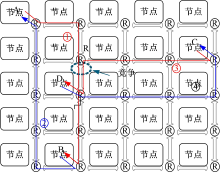
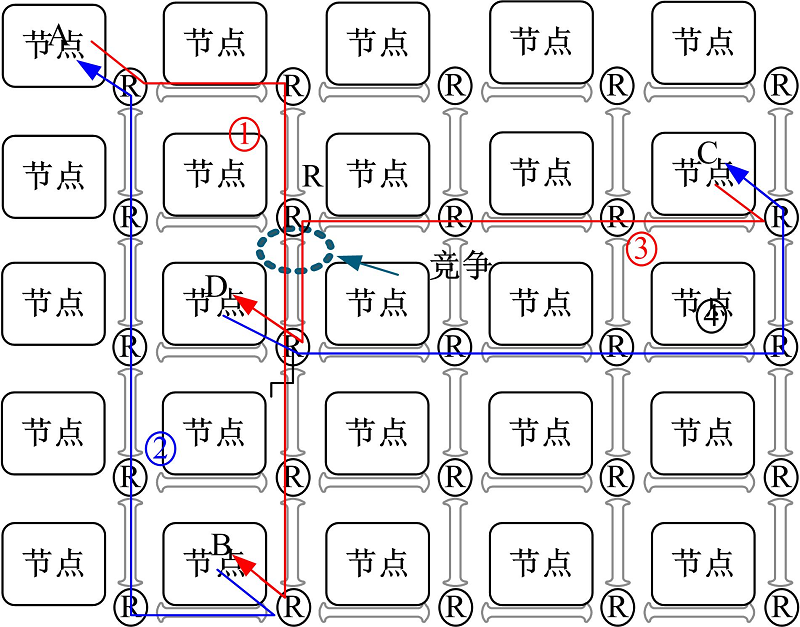 | 图1 本文方法基本思想示例Fig.1 Example of explaining the basic idea of our proposal |
以图1为例对本文方法的基本思想进行说明。图中显示了一个5× 5Mesh片上网络, 该片上网络采用报文切换, 支持确定性XY维序路由(X方向优先), 并且一个跳步延迟为1个时钟周期。假定节点A发起一次片上访存, 去访问节点B的本地存储器。该次片上访存包括两部分:从节点A到节点B的访存请求(如图1中实线①)和从节点B到节点A的访存响应(如图1中实线②)。与此同时, 节点C发起一次访问节点D本地存储器的片上访存, 同样包括两部分:从节点C到节点D的访存请求(如图1中实线③)和从节点D到节点C的访存响应(如图1中实线④)。访存请求①和访存请求③由于都要使用路由器R的南端下行链路而在路由器R中产生竞争。假定依据报文的历史延迟为依据进行仲裁, 由于到达路由器R时, 访存请求③的已有延迟为3拍, 大于访存请求①的2拍延迟, 因而访存请求③竞争成功而获得链路, 而访存请求①不得不在路由器R的缓冲中等待一拍。最终结果是:片上访存(A-B)在去程上花费6拍延迟, 在回程上花费5拍延迟, 共计11拍; 片上访存(C-D)则花费8拍延迟。两次片上访存的平均延迟为9.5拍, 两次片上访存的各自延迟都偏离平均延迟1.5拍。虽然在到达路由器R时访存请求③的已有延迟(3拍)大于访存请求①的延迟(2拍), 但是片上访存(A-B)的总延迟大于片上访存(C-D)的总延迟。如果以总延迟为仲裁依据, 则当访存请求①和访存请求③在路由器R中竞争南端下行链路时, 访存请求①竞争成功, 那么最终结果是:片上访存(A-B)花费10拍, 片上访存(C-D)由于在路由器R中等待一拍而共计花费9拍延迟。虽然两次片上访存的平均延迟仍为9.5拍, 但是两次片上访存的各自延迟仅都偏离平均延迟0.5拍。这样, 两次片上访存的延迟差异缩小, 延迟更加均衡。
如果以片上访存的总延迟为仲裁依据, 就需要对总延迟进行计算。总延迟包括历史延迟和未来延迟两部分。在片上网络中多个报文存在竞争, 未来延迟是不确定的, 但可以估算。
用L表示一次片上访存的总延迟, 计算式为:
式中:第一个括号中的部分表示片上访存在已传输过程中的延迟, 包括路径延迟(DLp)和等待延迟(WLp)。路径延迟是指无竞争情况下报文的传输延迟, 等于跳步数与一次跳步延迟的乘积, 等待延迟是报文由于链路竞争失败在路由器中的等待时间。第二个括号中的部分表示片上访存在未来传输过程中的延迟, 同样包括路径延迟(DLf)和等待延迟(WLf)。
本文采用二维Mesh确定性维序路由(X方向优先)片上网络, 因此DLf的大小是确定的, 式(1)可以改写为:
式中:DLt=DLp+DLf。
1.2.1 计算DLt
由于片上网络采用确定性路由, 因此DLt由源节点和目的节点的坐标可计算得出:
式中:Xsrc和Ysrc分别为源节点的X坐标和Y坐标; Xdst和Ydst分别为目的节点的X坐标和Y坐标, 从报文头中可以获得(如图2所示)。
1.2.2 计算WLp
在报文中新增加一域“ WT(等待延迟)” (如图2所示), 用于保存报文在网络中已传输过程中的等待时间。一次片上访存由去程读写请求报文和回程读写响应报文组成。当读写请求报文刚进入片上网络时, “ WT” 域初始化为0。当读写响应报文进入片上网络时, “ WT” 域初值等于与之关联的读写请求报文到达存储器时的“ WT” 值。读写请求报文和读写响应报文在片上网络中传输时, 如果由于竞争失败, 则每在路由器缓冲中多等一拍, “ WT” 值加一。
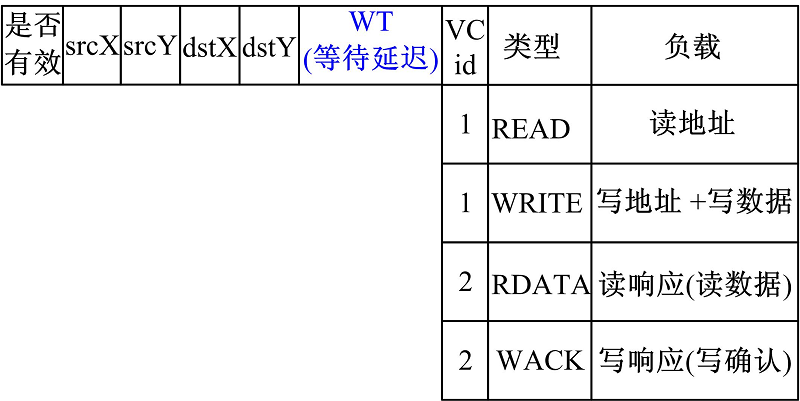 | 图2 报文格式Fig.2 Packet format |
1.2.3 估算WLf
WLf表示片上访存在未来传输过程中的等待延迟。由于在片上网络中多个报文存在竞争, WLf是不确定的, 本文提出依据访存报文后续路径的拥塞信息来估算WLf。后续路径的拥塞信息由后续路径上相关路由器缓存已占用深度来表示。例如, 当一个报文A准备进入后续路径上第一个路由器R的输入缓冲时, 该输入缓冲中已有两个报文(记为B1和B2), 那么当报文A离开路由器R时, 它需要在路由器R中被阻塞等待1拍。因为当报文A进入路由器R输入缓冲时, 虽然与此同时报文B1离开路由器R, 但是报文B2仍在路由器R的输入缓冲中, 所以报文A需要等待报文B2离开路由器R的输入缓冲, 从而被阻塞等待1拍。因此, 报文A在后续路径上第一个路由器R中的等待延迟为1拍, WLf可以由后续路径上所有相关路由器缓冲的已占用深度来估算得出。具体估算过程如下:①由于片上网络采用确定性路由策略, 根据报文的源节点坐标和目的节点坐标即可得到后续路径上所有路由器的集合R, ②WLf由下式计算:
式中:FWL(R)为计算报文在后续路径上路由器R中的可能等待延迟, 具体为:
式中:δ R为报文所在的当前路由器到后续路径中路由器R的跳步数; φ R为路由器R中与报文相关的输入缓冲的已占用深度。
上述两步估算的是在后续路径上由于相关路由器输入缓冲中已有报文造成头阻塞(Head-of-line, HoL)导致的可能等待延迟, 头阻塞的出现是因为历史上多个报文同时竞争下游链路, 使得竞争失败的报文不得不等待在路由器缓冲中。这两步估算讨论了历史报文竞争导致的等待延迟, 未讨论当下多个报文同时竞争下游链路导致的等待延迟。因而, 上述两步估算得到的WLf比实际的要偏小。随着报文注入率的增加, 出现多个报文同时竞争链路的概率加大。因此, 引入一个因子ε , 用于修正上述两步估算的WL'f, 修正公式如下:
式中:ε 与报文注入率ρ 有关, 随着ρ 的增大而呈非线性增大。在网络未达到饱和前, ε 随着ρ 的增大而缓慢增大; 在网络达到饱和后, ε 随着ρ 的增大而急剧增大。随着网络规模的扩大, 网络达到饱和点时ρ 变小。
前面描述的是计算总延迟的一般性方法。在实际设计中, WLf和WL'f的估算可以简化和便于实现, 具体为:
(1)由式(5)可知, 如果在后续路径路由器R的相关输入缓冲中的报文个数小于或等于报文所在当前路由器与后续路径路由器R之间的跳步数, 则报文不会在后续路径路由器R中等待。因此, 由于实际设计中缓冲的深度有限(假设深度γ ), FWL(R)的计算可以简化为只需计算后续路径上最近γ -1个路由器的相关输入缓冲已占用深度之和。在第2节中, 输入缓冲深度为4, 那么只需要统计后续路径上最近3个路由器的相关输入缓冲已占用深度信息。在图3所示的路由器中, 与当前路由器距离小于3的路由器的φ R值合在一起作为“ 预测因子” 输入传递给当前路由器, 当前路由器的φ R值作为“ 预测因子” 输出传递给与之距离小于3的路由器。
(2)在计算WL'f时, 需要知道ε 因子。首先, 在传统采用Round-Robin仲裁的片上网络进行实验, 统计报文注入率ρ 变化时出现多个报文同时竞争链路的次数为m。ε 随ρ 的变化趋势与m随ρ 的变化趋势一致。根据m值的分布, 结合实际网络设计, 估算一组ε 值, 与m值的分布一致。
本文采用的是二维Mesh确定性维序路由片上网络, 报文首先向X方向传输, 再向Y方向传输, 避免转向环的出现, 从而防止死锁。在路由器中实现对总延迟的计算, 并基于总延迟对竞争报文进行仲裁。
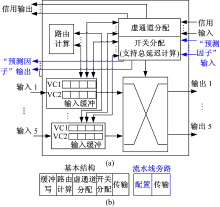
图3(a)显示了具有延迟均衡的路由器的结构。
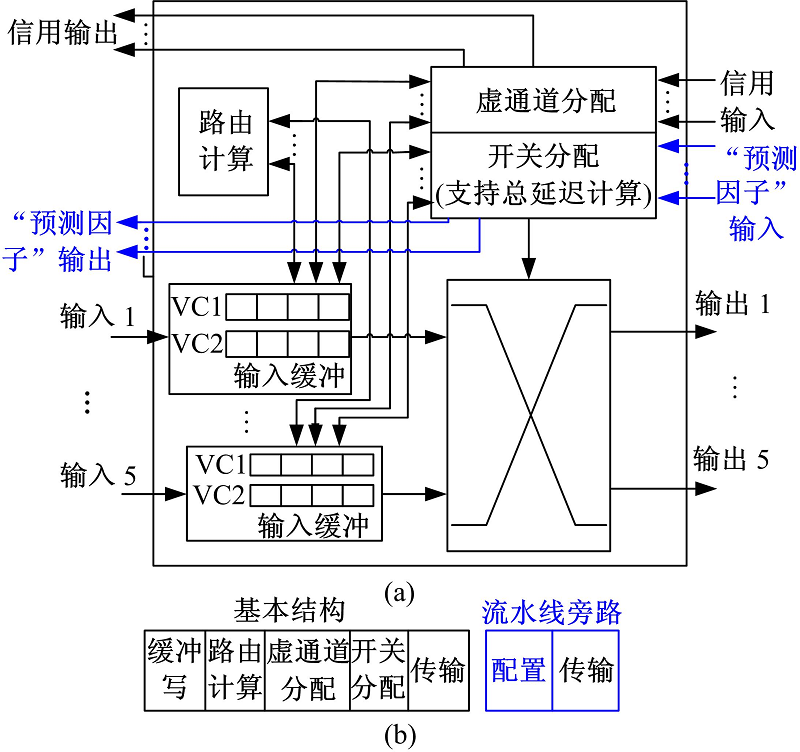 | 图3 具有访存延迟均衡的路由器结构Fig.3 Router structure supporting memory access equalization |
该路由器采用广泛使用的基于报文切换和信用的虚通道[15]路由器结构。在路由器的开关分配模块中实现访存总延迟的计算。使用两个虚通道, 一个虚通道用于缓存访存去程阶段的读写请求报文, 一个虚通道用于缓存回程阶段的读写响应报文, 从而防止读写请求报文与读写响应报文之间相关性造成的死锁。路由器采用标准5级逻辑流水结构[16], 如图3(b)所示。当报文到达路由器的输入端口时, 首先在“ 缓冲写” 站写入到对应的虚通道缓冲中。在下一站“ 路由计算” 中, 路由计算逻辑计算报文的输出端口。然后, 在“ 虚通道分配” 站中, 根据上一站计算出的报文输出端口, 相关报文竞争获取虚通道。如果报文成功获得虚通道, 则报文进而在“ 开关分配” 站中竞争到输出端口的开关链路。如果报文成功获得到输出端口的开关链路, 在“ 传输” 站中, 报文从虚通道缓冲中读出, 并经由开关网络传输给下一级路由器。在具体实现中, 为了加速报文的传输, 采用“ 流水线旁路” 机制。“ 缓冲写” 、“ 路由计算” 、“ 虚通道分配” 和“ 开关分配” 四站合成一个“ 配置” 站。这样, 在片上网络中, 一个跳步仅需要一拍。
如图3(a)所示, 在开关分配模块中实现总延迟的计算, 并根据总延迟对竞争同一个输出端口开关链路的报文进行仲裁。路由器的“ 预测因子” 输入为来自与之距离小于3的邻近路由器的φ R值, 路由器的“ 预测因子” 输出为当前路由器的φ R值, 并传递给与当前路由器距离小于3的邻近路由器。“ 预测因子” 输入用于按照第1.2节总延迟的计算方法来计算总延迟。进行报文仲裁时, 总延迟大的报文优先获得开关链路。如果多个竞争报文的总延迟相同, 则采用Round-Robin方式。
本文采用C++语言实现一个时钟精确的同构众核模拟器, 采用2D Mesh片上网络作为互连, 每个节点含有一个处理器核和本地存储器。该模拟器对处理器核、本地存储器、网络接口、路由器进行了建模实现。
采用均匀合成流量模式对第1节提出的基于总延迟预测的访存报文仲裁技术进行性能评估。均匀合成流量模式是最常用的流量模式, 在该模式下, 每个处理器核按照相同的概率随机向位于其他节点的存储器发出多次片上访存。在实验中, 模拟器运行分为预测、测量和排空三个阶段。首先, 在预测阶段, 模拟器开始运行时, 每个处理器核随机产生10 000次访存, 向片上网络注入10 000个读写请求报文, 使片上网络逐步进入稳定状态。在预测阶段, 访存延迟不会被统计用于性能分析。其次, 模拟器进入测量阶段, 每个处理器核继续随机产生10 000次访存, 该阶段产生的访存的延迟被测量, 并用于性能分析。最后, 模拟器进入排空阶段, 每个处理器核继续随机产生访存, 直到在测量阶段产生的访存的延迟都被统计到。一次访存的延迟是指处理核发出该次访存的读写请求报文的时间与接收到该次访存的读写响应报文的时间之差。通过变化网络规模和报文注入率, 进行多次实验。在实验中, 选择经典Round-Robin仲裁机制作为对比对象。对实验数据进行了整理, 统计了最大延迟(ML)、平均延迟(AL)和延迟标准差(LSD), 用于评估本文技术性能。延迟标准差是衡量各个访存报文之间延迟均衡性的重要指标, 反映各访存延迟偏离平均延迟的程度。ML、AL和LSD的定义如下:
式中:N为测量阶段发出的访存的次数; Li为访存i的总延迟。
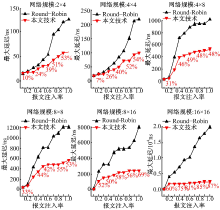
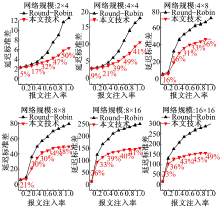
图4、图5和图6分别显示了在不同网络规模和报文注入率下的最大延迟、平均延迟和延迟标准差。为了更直观地表示本文技术与Round-Robin技术相比的优势, 图中给出了两者对比的延迟减小百分比。由图可知:
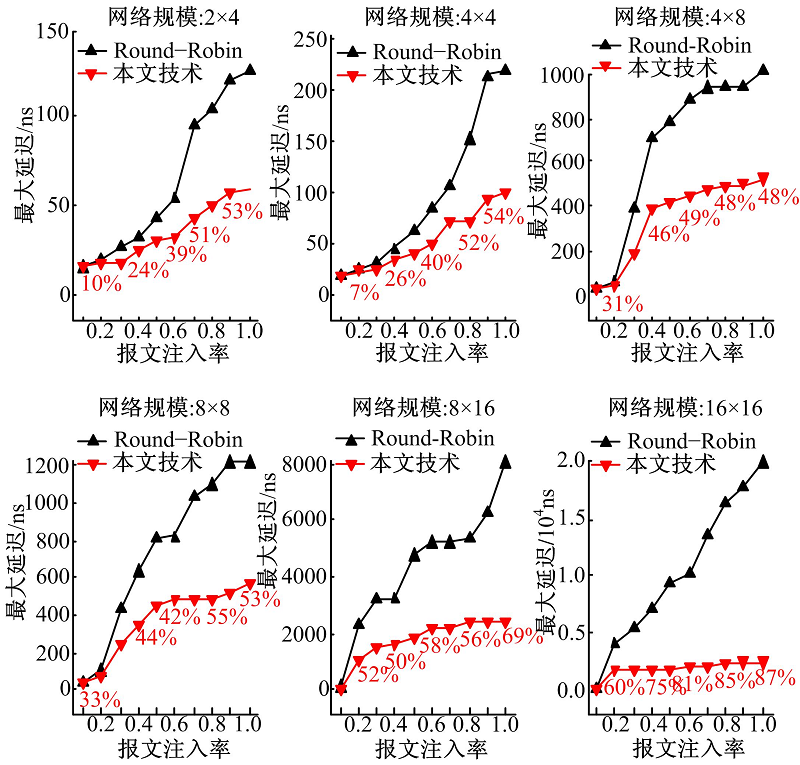 | 图4 本文技术与Round-Robin仲裁机制的最大延迟比较Fig.4 Comparison of maximum latencies between our approach and Round-Robin arbitration mechanism |
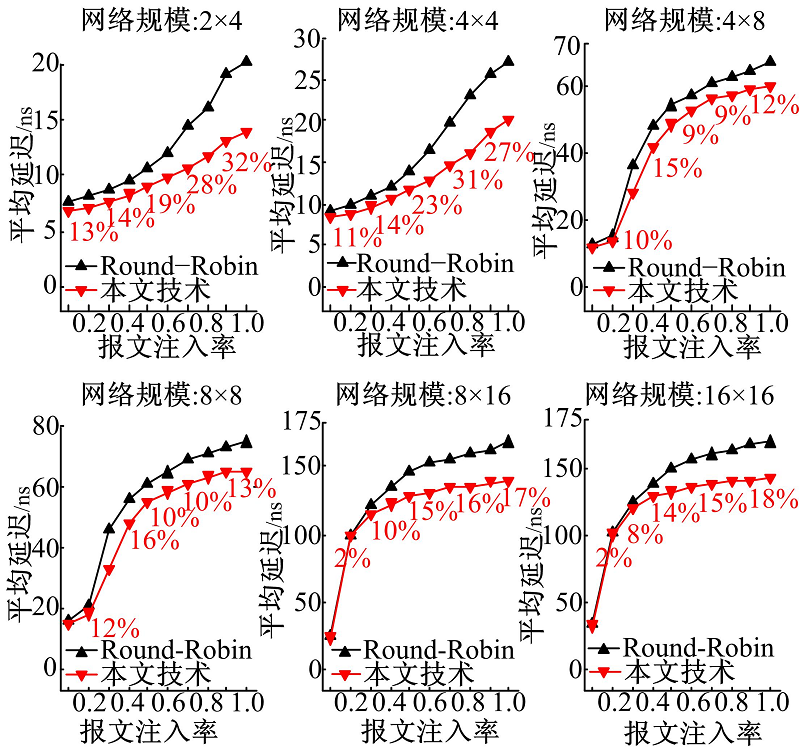 | 图5 本文技术与Round-Robin仲裁机制的平均延迟比较Fig.5 Comparison of average latencies between our approach and Round-Robin arbitration mechanism |
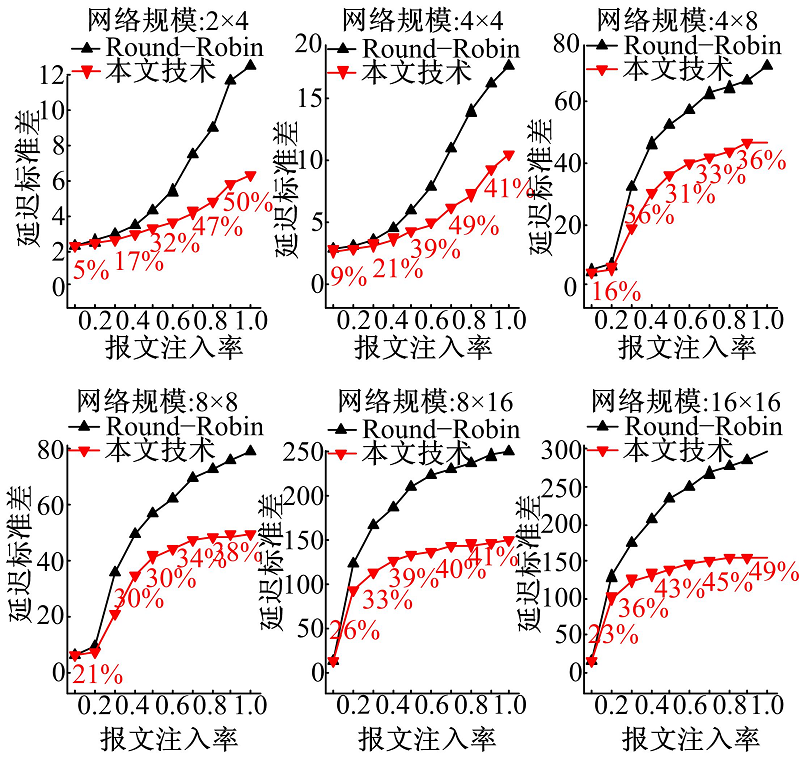 | 图6 本文技术与Round-Robin仲裁机制的延迟标准差比较Fig.6 Comparison of latency standard deviation between our approach and Round-Robin arbitration echanism |
(1)与经典Round-Robin仲裁机制相比, 本文技术具有较低的最大延迟、平均延迟和延迟标准差, 使得片上访存延迟更加均衡。
(2)随着网络规模的扩大和报文注入率的增加, 与经典Round-Robin仲裁机制相比, 采用本文技术得到的最大延迟、平均延迟和延迟标准差的减少比例更大。这是因为在大规模网络中和大量报文注入情况下, 经典Round-Robin仲裁机制使得片上访存之间的延迟差异加大, 而本文技术能够优化延迟差异。例如, 在网络规模为16× 16和报文注入率为1.0时, 与经典Round-Robin仲裁机制相比, 本文技术使得最大延迟、平均延迟和延迟标准差分别减少了87%, 18%和49%。
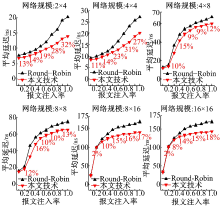
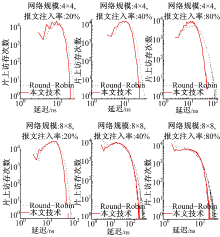
图7为片上访存分布图, 它表示通过统计具有不同总延迟的访存的次数。由图可知:
(1)与经典Round-Robin仲裁机制相比, 本文技术减轻了访存延迟的散布, 使得片上访存延迟更加均衡。
(2)减少了延迟大的访存数量, 减轻了大延迟报文对系统整体性能的制约。
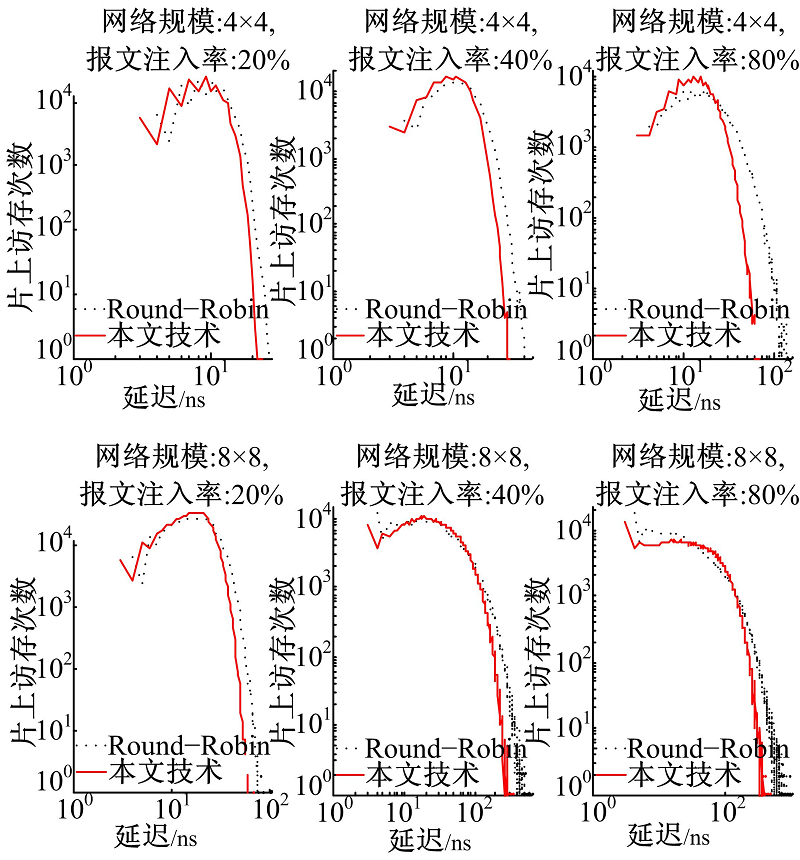 | 图7 本文技术与Round-Robin仲裁机制的访存分布比较Fig.7 Comparison of on-chip memory access dispersion between our approach and Round-Robin arbitration mechanism |
提出了基于总延迟预测的访存报文仲裁技术。依据访存报文后续路径的拥塞信息预测访存报文未来等待延迟, 结合历史等待延迟和总距离延迟计算出总延迟; 然后基于估算的总延迟, 对竞争同一链路的访存报文进行仲裁; 最后设计了具有访存延迟均衡的路由器。实验结果表明, 在不同的网络规模和报文注入率下, 与传统Round-Robin仲裁机制相比, 本文技术能够极大减少最大延迟和延迟标准差, 减少平均延迟, 获得更佳的访存均衡性。在未来工作中, 将对其他规则或非规则拓扑结构的片上网络展开访存延迟均衡性研究。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|