{kind=link}
{kind=link}
改进的粒子滤波重采样算法
[李娟1  , 刘晓龙
, 刘晓龙1 , 卢长刚2 , 左英泽1 ]
, 刘晓龙|
|


作者简介:李娟(1970-),女,副教授,博士.研究方向:信号与信息处理.E-mail:ljuan@jlu.edu.cn
针对粒子滤波算法粒子退化的问题,提出了分类重采样(CR)算法。根据重采样时筛选出粒子数目的多少采用不同类型的复制方案,并在有效粒子减少的情况下,及时补充新粒子。仿真结果表明:当选取的粒子数目较少或者仿真周期较长时,该算法相比较多项式重采样(MR)算法和系统重采样(SR)算法具有较小的均方根误差,且多次仿真得到的均方根误差(RMSE)的方差也相对较小,说明该算法在鲁棒性、持久性和稳定性方面有所改善。
To solve the problem of particles degeneracy in the particle filter algorithms, a Classified Resampling (CR) algorithm is proposed. This algorithm adopts different duplication schemes according to the quantity of selected particles; furthermore, it replenishes new particles in the case that the number of effective particles is reduced. Simulation results demonstrate that, with smaller number of particles or longer simulation period, the proposed algorithm has minor Root Mean Square Error (RMSE) compared with Multinomial Resampling (MR) and Systematic Resampling (SR), and with multiple simulations the variance of RMSE is smaller, which indicates that the robustness, durability and stability of the proposed algorithm are improved.
粒子滤波(Particle filter, PF)是一种基于Monte Carlo仿真的递推贝叶斯估计方法, 它是在序贯重要性采样(SIS)的基础上, 再进行重采样的一个递推过程。粒子滤波可以有效地处理非线性、非高斯噪声环境下的状态估计问题, 被广泛用于在目标跟踪[1]、导航定位[2]等领域。
自从1993年Gordon等[3]提出重采样算法以来, 出现了很多重采样算法, 比较经典的有多项式重采样(Multinomial resampling, MR)[3], 系统重采样(Systematic resampling, SR)[4]和残差重采样(Residual resampling, RR)[5]。以上算法在一定程度上解决了样本退化的问题, 但随着时间的延长, 大权值粒子多次被复制, 粒子集的多样性丧失。为此, Li和Sattar等提出Deterministic Resampling算法[6], 通过划分网格并逐步裂变的方法保持了粒子的多样性, 但由于计算量过大不适宜做实时处理。此外, 结合最新观测值的辅助粒子滤波算法[7]增加了一步重采样过程, 因此更接近真实状态值, 但当过程噪声较大时, 滤波性能急剧下降。基于观测似然重要性采样粒子滤波[8]直接根据观测似然函数进行采样, 保证大多数粒子点都分布在高观测似然区域, 提高了粒子的利用效率, 但只适合于观测精度高的场合。
本文提出了一种改进的重采样算法— — 分类重采样(Classified resampling, CR), 该算法使大权值粒子全部保留, 小权值粒子被舍弃, 在按权值由大到小的顺序依次进行相应次数复制的过程中, 根据筛选出粒子个数的不同采用不同的复制方案。若采样粒子的权重分布极其恶劣时, 及时补充新粒子, 保持了粒子的多样性。
粒子滤波是通过寻找一组在状态空间中传递的随机样本对概率密度函数p(xt|y1:t)进行近似, 并以样本均值代替积分运算, 从而获得状态最小方差的估计过程。随着粒子数的增加, 粒子的概率密度函数逐渐逼近状态的概率密度函数, 即达到了最优贝叶斯估计的效果[9]。
假设动态系统的目标状态转移方程和目标观测方程分别为:
式中:nt-1和vt分别为过程噪声和观测噪声; xt为目标状态值, 具有马尔可夫特性; yt为目标观测值, 各时刻的值具有独立性。
由式(1)(2)可以看出, 系统模型没有对系统作线性和非线性以及对噪声作高斯或非高斯的假设, 因此适用于非线性非高斯状态下的跟踪滤波。
传统的粒子滤波方法[4]就是用前一时刻状态值xt-1和现在的观测值yt来递推估计现在的状态值xt。其算法步骤如下所示:
(1)初始化:由先验概率密度p(x0)随机抽取N个粒子
(2)重要性采样:将p(xt
(3)重采样:通过对比阈值Nth和有效粒子数Neff=1
(4)状态输出:根据Monte Carlo思想, 通过对采样粒子进行加权来近似表示当前状态值。若无重采样:
(5)令t=t+1, 返回到步骤(2), 进行下一时刻的状态估计, 直到滤波结束。
粒子退化现象是SIS的主要缺点, 具体表现为经过若干次迭代后, 重要性权值的方差会随着时间递增, 即最后只有少数粒子具有很大的权值, 而其余粒子的权值几乎可以忽略不计, 从而使得粒子集不能有效地表达状态的后验概率密度分布[10]。为了防止这一现象, 本文提出的分类重采样方案通过直接方式对粒子进行筛选, 保留大权值粒子, 去除小权值粒子, 然后按权值大小顺序对大权值粒子进行复制, 使粒子总数恢复原有总数。这样直接改善了粒子退化的现象, 使得新产生的粒子集能更有效地表达状态的后验概率密度分布。下面将本文在粒子筛选和复制时采用的方案做出详细说明。
(1)粒子的筛选方案
首先选取区间0~1/N中的内的任一随机数u, 然后将此时刻每个粒子的权重
means=sum/C
粒子滤波重采样算法的原则就是剔除小权值粒子、复制大权值粒子, 本文直接将粒子的权重与一个小于1/N的数字相比较, 保大舍小。筛选的标准选定为0~1/N中的一个随机数, 1/N是所有粒子权重的平均值, 也就是说舍去的粒子的权重全部小于粒子权重的平均值。
(2)粒子的复制方案
为了恢复粒子总数为N, 必须对筛选出的粒子进行复制。复制过程是从权值大的粒子开始直至粒子总数达到N为止。选取一个粒子数目的门限值Np, 每个粒子复制的个数要根据筛选出的粒子数C与门限值Np的比较结果选取不同复制方案:①当筛选出的粒子数大于或等于门限值, 即C≥ Np时, 每个粒子复制的次数为小于或等于
根据粒子权重越大, 复制次数越多的原则, 将复制次数选择为一个接近
(3)新粒子产生方案
若采样粒子的权重分布极其恶劣, 即权重方差过大时, 容易出现将C个粒子复制相应次数后, 粒子总数仍不足N的情况。为了增加粒子的多样性, 而不是将原有大权值粒子多次复制, 采用了产生新粒子的方案。将大权值的粒子
产生新粒子时, 要给原有粒子加上一个噪声级别的随机数, 这个随机数也可以称之为扰动。本文根据状态噪声的统计特性来确定扰动的数值范围。由于状态噪声的分布是确定的, 因而噪声的数字特征可以根据具体分布得出。当状态噪声的均值为E(nt)方差为D(nt)时, 扰动的取值为:
-E(nt)+
式中:X为-1到1之间任一随机数。
以状态噪声nt-1~N(0, 1)为例, 扰动即为-1到1之间任一随机数。根据概率分布原理:
此时扰动的取值范围占状态噪声分布的68.26%, 数值取得过大, 所占噪声分布比例大, 但造成扰动也较大, 综合衡量扰动大小和所占噪声分布比例的扰动取值与状态噪声比例较为合理。
新粒子只有在粒子集的权重方差较大的时候才需要产生, 新粒子一方面保持了与原状态值的近似, 另一方面又不同于原本己多次复制的大权值粒子, 达到了粒子集的优化。这只是在粒子的权重分布极其恶劣的条件下采取的一种补救方法。通过新粒子的产生增加了粒子的多样性, 防止了粒子的枯竭。
(1)粒子筛选;
(2)计算筛选出粒子的个数、权重和、均值;
(3)粒子的复制, 采用分类复制方案, 必要时产生新粒子;
(4)均分权重, 将所有粒子的权值重置为1/N。改进算法伪代码如表1所示。
| 表1 分类重采样算法的伪代码 Table 1 Pseudo-code of CR algorithm |
将本文提出的分类重采样算法与多项式重采样算法和系统重采样算法进行分析和比较, 通过在相同条件下对3种算法的仿真, 得出各算法的优劣性。
仿真采用了一种广泛使用的非线性系统模型。状态方程为:
观测方程为:
仿真参数设置:状态初始条件为x0~N(0, 5); 状态噪声nt-1~N(0, 1); 观测噪声vt~N(0, 1); 门限值Np=2N/3。为了观测不同粒子数目和不同仿真周期情况下各算法的性能, 仿真采用的粒子数N分别为10、20、50; 仿真周期T分别为100、1000、10000。
(1)均方根误差(RMSE)为:
式中:xt为状态真实值;
(2)RMSE的均值和方差
进行M次蒙特卡罗仿真后, RMSE的均值为:
RMSE的方差为:
为了更清晰地对比这3种重采样算法, 本文进行了3次实验。在3次实验中, 采用不同粒子数的目的是评价算法的鲁棒性, 采用不同仿真周期的目的是评价算法的持久性, 计算RMSE的方差是为了评价算法的稳定性。
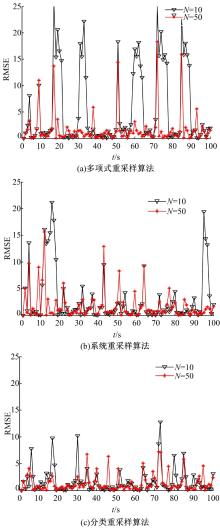
实验1 当T=100时, 选取粒子数目不同的情况下, 各种重采样算法均方根误差的对比结果如图1所示。
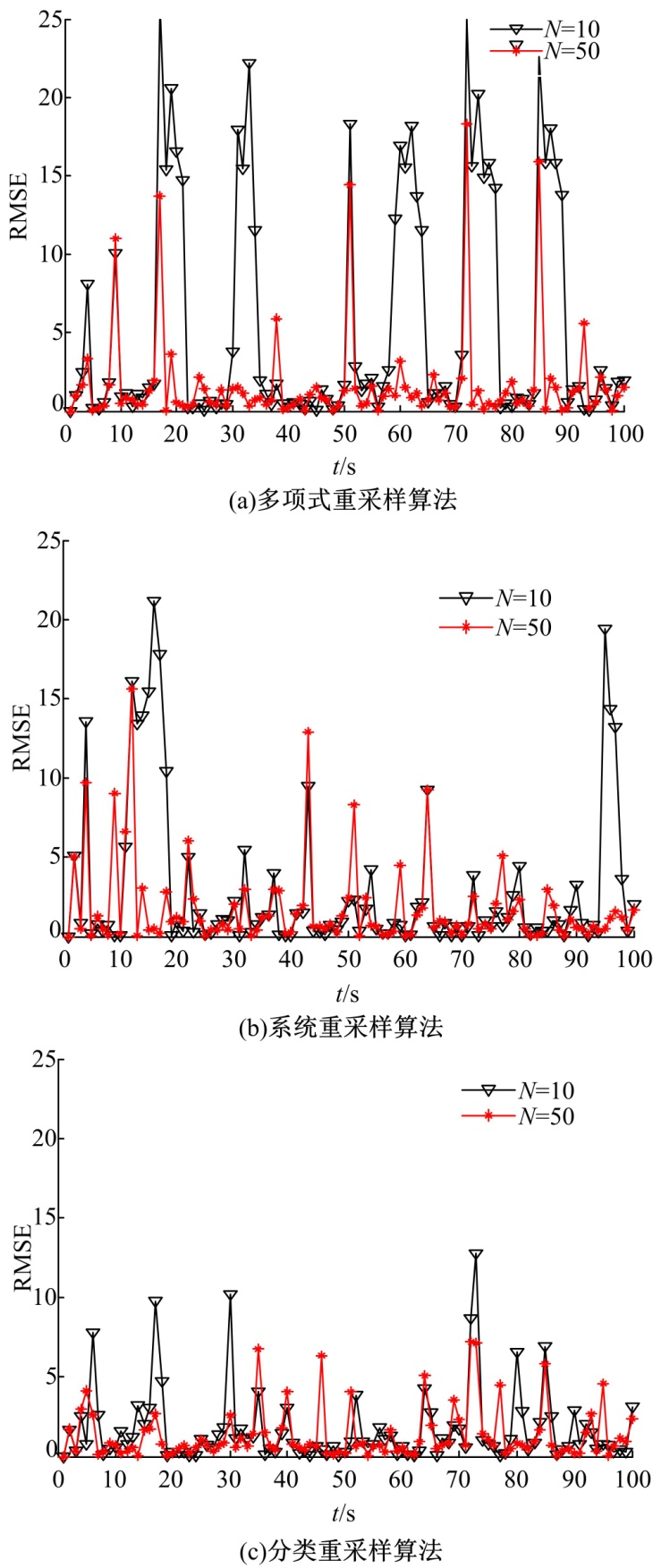 | 图1 三种重采样算法取不同粒子数时的RMSEFig.1 RMSE of three resampling algorithms with different particle numbers |
增加粒子数可以减小结果的RMSE, 但计算量却随之成级数增加。因此当系统计算条件有限时, 就需要在较少的粒子数目下, 保持算法的准确性。从图1(a)可看出, MR算法在粒子数为10和50时, RMSE相差很大。这说明该算法对粒子数的多少很敏感, 在粒子数较少的情况下, 算法的估计精度和稳定性都会急剧下降; 从图1(b)可看出, SR算法在粒子数较少时, RMSE较大, 虽然没有MR算法的那么突出, 但反应出的估计效果并不理想。从图1(c)可看出, CR算法在粒子数不同时, RMSE均较小, 尤其在粒子数少时, 比前两种算法具有较高的估计精度, 证明了该算法有较好的鲁棒性。
实验2 进行100次仿真后, 在不同粒子数和不同仿真周期的情况下各种算法性能对比, 结果如表2和表3所示。
| 表2 N=10时不同仿真周期情况下3种算法的 |
| 表3 N=20时不同仿真周期情况下3种算法的 |
由表2和表3可以明显看出, 在T=100时, 3种重采样算法的
从表4中可以明显地看出, 随着重采样粒子数的增多, 3种算法RMSE的方差都明显减小。其中分类重采样的方差在不同粒子数情况下都是最小的, 尤其是粒子数越少时, 分类重采样的优势越大。由图1也可以验证该结论。这说明该方法具有稳定的估计性能。
| 表4 T=1000时3种算法在不同粒子数的σ 2 Table 4 σ 2 of three algorithms with different particle numbers when T=1000 |
实验3 各种算法估计效果仿真。
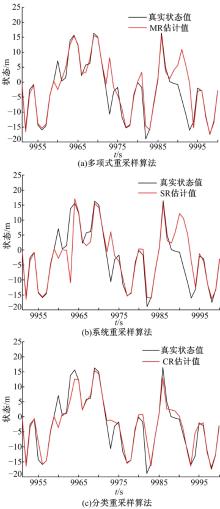
图2(a)(b)(c)分别是3种重采样算法在N=20; T=10000时, 对前述非线性系统模型跟踪的结果。为了清晰起见, 图中只展示了后50个时间点。从图中可以看出, CR算法比另两种算法更接近真实值。
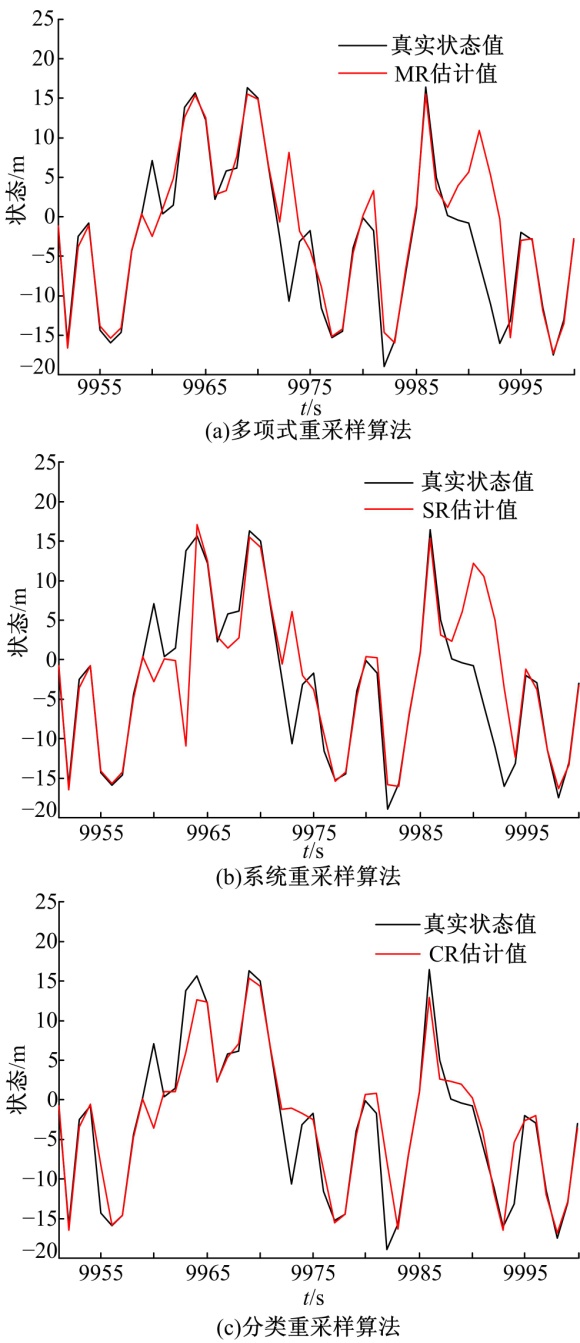 | 图2 基于三种重采样算法的估计结果Fig.2 Estimation result with three resampling algorhtms |
SIS算法会出现退化现象, 而重采样算法虽然可以解决退化现象, 但又带来了样本枯竭的问题, 一个好的重采样算法应该在减少小权值粒子数目和保持粒子多样性之间进行合理权衡。本文提出的CR算法, 根据筛选出的粒子的多少采用不同复制方案, 必要时通过扰动产生新的粒子。算法原理简单, 易于实现, 在解决粒子退化的同时, 预防了粒子的枯竭。仿真结果显示:RMSE在粒子数目较少时较之MR和SR算法有明显优势, 此外RMSE随着仿真周期的延长变化不明显。在N=10, T=10000时,
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|