



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于三维激光雷达和深度图像的自动驾驶汽车障碍物检测方法
[王新竹1  , 李骏
, 李骏1, 2 , 李红建2 , 尚秉旭2 ]
, 李骏, 李红建|
|


作者简介:王新竹(1985-),男,博士研究生.研究方向:自动驾驶技术.E-mail:xzwang12@mails.jlu.edu.cn
介绍了一种基于三维激光雷达和深度图像的障碍物检测方法.首先,根据Velodyne HDL-32E激光雷达自身工作特性,将点云数据以矩阵方式表达,并表示为深度图像;然后,根据点云中各点的距离信息在深度图像横向上进行聚类;最后,在纵向上建立线性模型,对聚类点进行分类,划分出地面点集和障碍物点集.仿真实验结果表明:本方法能够抑制障碍物遮挡造成的误判,并能够很好地适应地形变化.
An obstacle detection method based on 3D laser scanner and range image is proposed for intelligent vehicle. First, the range image of one scan is established based on the Welodyne HDL-32E laser scanner data. Then, according to the range image analysis, the point cloud in one row of the image is classified into several groups. Finally, the point clouds in different groups are detected by a linear model in column. Simulation reveals that using the proposed method, the rate of false detection caused by the obstacle lock is reduced, and this method well adapts to the terrain change.
环境感知的主要任务是对车辆行驶中的障碍物进行提取, 并分辨出可通行区域, 从而为路径规划提供可靠依据.根据应用传感器的不同, 环境感知方法可归纳为:基于毫米波雷达的方法[1], 基于立体视觉的方法[2, 3, 4, 5], 基于激光雷达的方法[6, 7, 8, 9, 10, 11]和基于多传感器信息融合的方法[12, 13, 14, 15, 16]等.基于毫米波雷达的方法通常受到传感器自身特性的影响, 比如较大的光斑以及有限的距离分辨率.基于立体视觉的环境感知方法通常应用多目摄像头重建三维场景, 该方法很难准确获悉目标的精确位置, 对目标形状和大小的计算方法通常较为复杂, 限制了环境感知的实时性, 而且摄像头受光线等环境因素影响较为明显, 在阴天和夜晚等情况下效果将大打折扣.基于多传感器融合的环境感知方案能够提供更加丰富的环境信息, 但同时也带来了信息的冗余, 提高了计算的复杂度.此外, 由于传感器之间应用固定的校准参数, 校准参数时常会受到环境的影响(如道路的颠簸等), 一旦引入噪声, 会在一定程度上影响环境感知的准确性.为了保障环境感知的准确性, 在数据处理中不得不花费更多的计算来判定当前状态下哪个传感器获取的信息更为准确, 而这无疑将引入更繁重的计算[17].
自美国DARPA无人车挑战赛以来, 基于激光雷达的环境感知技术得到了国外学者的关注, 如Google无人车, 卡内基梅隆大学的Boss无人车[18]和斯坦福大学的Junior无人车[19]等.国内也举办了多届"中国智能车未来挑战赛", 激光雷达在众多参赛队伍车辆中同样扮演着重要的角色.通常应用的激光雷达分为三维激光雷达和二维激光雷达.三维激光雷达较二维激光雷达进一步提供了高度信息, 令障碍物的检测更为简便可靠.因此诸多研究机构在自动驾驶汽车的研究中均采用三维激光雷达, 如Velodyne HDL-64E激光雷达和Velodyne HDL-32E激光雷达等.本研究中采用Velodyne HDL-32E激光雷达, 其相对Velodyne HDL-64E雷达具有更小的体积.
Moosmann等[10]提出了基于快速网格化的障碍物检测方法.该方法首先寻找点云中每点的4个近邻点, 从而分析点与点, 点与面以及面与面的关系, 应用区域增长法来分割点云, 从而获取环境信息.该方法巧妙地应用了激光雷达的工作方法来进行快速网格化, 然而该网格化方法往往很难准确地估计各点所在平面的法向量信息, 并对噪音干扰较为敏感.Douillard[9]等提出了基于高斯过程的样本增量一致性算法, 并用该方法进行障碍物检测, 方法首先选定一些路地点, 建立道路模型, 然后根据当前道路模型判定其后若干点是否属于道路点, 如果属于道路点, 则加入样本, 然后重新建立道路模型.该方法能够对非道路点(离群点)进行过滤, 但是要求初始的样本点为道路点, 否则将无法建立正确的初始预测模型, 一旦初始道路点选择错误或失败将造成模型建立失败, 这将直接影响到环境感知的准确性.Himmelsbach等[6]提出了应用线性模型来描述道路的变化, 该方法较为快捷, 但该方法最初是用于机器人室内道路检测中, 因此对于道路多变的室外区域, 该方法很难跟随路面的变化.Douillard和Himmelsbach都应用了极坐标栅格, 然后沿栅格纵向应用算法进行建模计算, 然而却忽略了横向上的相关性.此外, 固定的栅格有时很难适应复杂的道路环境, 在遮挡情况下很难用当前模型判别当前点的类别.
本文提出了一种基于深度图像的障碍物检测方法, 该方法结合了三维激光雷达的工作特性.首先在深度图像对应矩阵的横向上进行聚类分析; 然后根据聚类结果自适应地划分横向跨度; 最后选择特征点, 并在纵向上建立线性模型进行分类.本方法的特点在于:① 以图像的角度来对点云进行分析; ② 不同于以往的栅格方法, 本文提出的方法在横向跨度选择上具有自适应性, 以减少计算复杂度; ③ 在极少计算复杂度的前提下, 本方法对全部的采样点进行了应用, 最大程度地应用点云信息.
图1所示为Velodyne HDL-32E激光雷达, 其使用32个固定式激光发射器来测量周围的环境, 每个都固定到一个特定的垂直角度, 每间隔时间Δ t, 32组激光发射器发射一次, 雷达通过高速旋转扫描来检测周边环境信息, 激光雷达每扫描过360° , 称为一帧.对于时刻t的输入数据为一系列三维点, 根据激光发射器垂直角度由小到大将时刻t获得的32个点编号为1~32.因此, 对于t时刻第n点pn, t, 定义其4个相邻点为pn+1, t, pn, t-1, pn, i+1, pn-1, t .若根据这一原则, 将一帧点云映射到一幅图像中, 并以水平深度作为其像素, 则可获得一幅深度图像, 如图2所示.
 | 图1 Velodyne HDL-32E激光雷达Fig.1 Velodyne HDL-32E laser scaner |
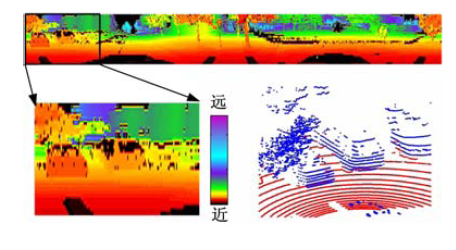 | 图2 将三维点云转换为深度图像Fig.2 3D point cloud is illustrated by a range image |
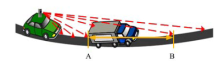
Douillard和Himmelsbach提出的方法中只考虑了在纵向建模, 而当如图3所示存在障碍物遮挡的情况下, 由于地面点A与估测点B间隔较大, 很难对点B进行正确判定.假设能够判定点B的一个邻近点属于地面点, 而B又与该相邻点属于同一类别, 那么将依此判定点B也属于地面点, 反之亦然.因此, 本文首先考虑对每环点云(即深度图像横向上)进行聚类分析.由于Velodyne HDL-32E激光雷达具有较高的旋转速度, 所以每环点云具有很高的密度, 利用这一特点, 首先在深度图像横向上进行聚类分析, 然后根据聚类结果自适应地选择跨度, 这样不仅能够减少运算量, 而且能够在一定程度上解决由于障碍物遮挡造成的建模不准等问题.
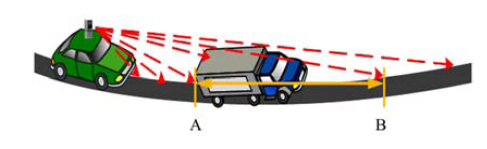 | 图3 激光扫描受到障碍物遮挡Fig.3 Lasers are blocked by an obstacle |
假设
式中:Δ ω 为激光雷达旋转的平均角速度; Dn, t为水平半径长度.
根据每环相邻点之间的距离进行聚类.当相邻两点之间的距离
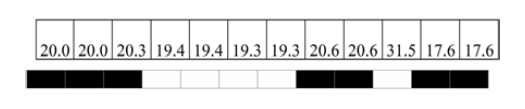 | 图4 聚类方法示意图Fig.4 Illustration of point clouds classification |
应用递推的方式在深度图像上逐行对障碍物点和道路点进行检测.对一行中的一簇点云, 首先从该簇点中选择若干特征点, 然后以特征点的均值来代表整簇点云, 最后在纵向上建立2D模型, 以此对该点进行判定, 如果均值点属于道路点, 那么整簇点归类为道路点, 反之归类为障碍物点.
假设已推算出了1到m-1行的道路点
For w=m-1:-1:1
Rw=[]; Lw=[]; Rcommon=[l:l+s-1]
For v=l:l+s-1
If
Rw=[Rw, v]
End
Rcommon=Rw∩ Rcommon
If Rcommon is not empty
Lw=[Lw, w]
end
end
end
Pmean=MeanRow(G(Rcommon, Lw))
Pmol=Pinitial∪ Pmean
其中, Rcommon记录候选特征点所属的列,
实验数据采集于中国第一汽车集团公司技术中心研发的搭载了Velodyne HDL-32E激光雷达的挚途自动驾驶汽车, 如图5所示.Velodyne HDL-32E激光雷达有32个激光器, 纵向视野40° , 质量小于2 kg, 32个激光器组可以实现+10° 到-30° 角度调节, 可提供极好的垂直视野, 水平视野可达360° .HDL-32E每秒可输出700 000像素, 测量范围可达70 m, 一般精度可达± 2 cm.实验中激光雷达的实际旋转速度选定为15 Hz.
 | 图5 挚途自动驾驶汽车Fig.5 Zhi Tu autonomous vehicle |
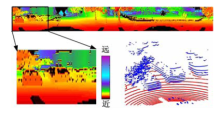
本文应用了Matlab对算法进行了仿真, 并应用实验采集数据进行了验证.这里给出了与文献[6]和文献[9]的对比实验.由图6(a)可见, 圈出的区域应为地面区域, 但是文献[9]的方法却误识别为障碍物.其主要原因在于车辆行驶中容易引入噪音.当应用文献[9]的方法时, 如果初始点受到噪音干扰, 则不能很好地建立地面模型, 从而出现误判.由图6(b)可见, 按照本文提出的方法, 首先在横向上进行了聚类分析, 从而将受到噪音干扰点单独作为一类分离出来, 这样在判定时将不再对其他点的判定造成干扰.由图6(c)(d)可见, 当存在障碍物遮挡时, 会形成一个盲区, 对其后的障碍物或道路判定造成影响.本文提出的方法由于对横向上点与点的关系进行了分析和聚类, 从而在一定程度上避免了盲区影响.
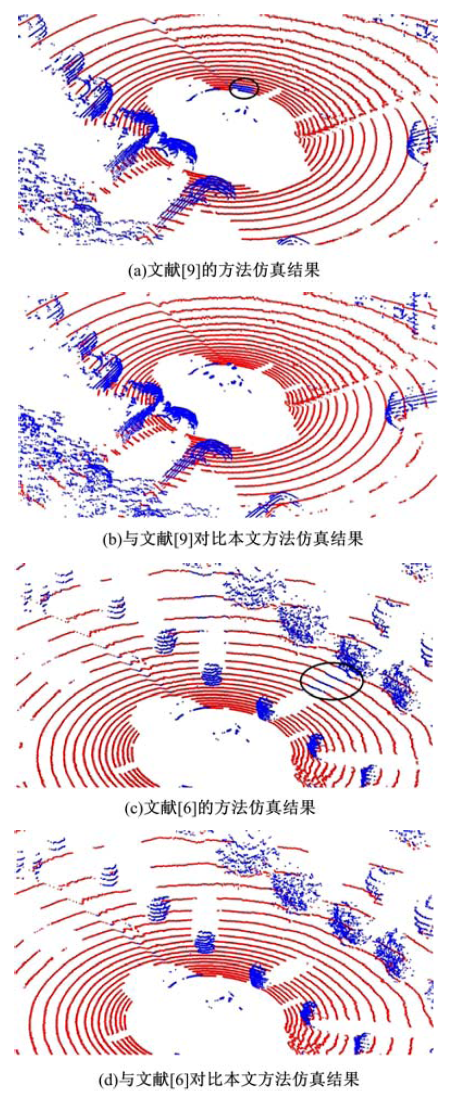 | 图6 对比实验Fig.6 Experiment of comparison |
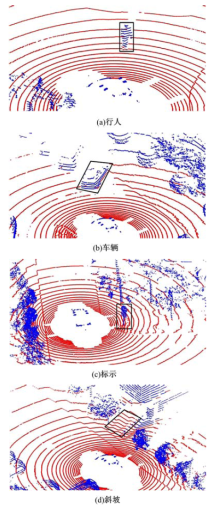
图7为部分仿真结果, 可以看到本方法能够很好地在复杂环境下对车辆, 行人, 标示, 树木等障碍物进行检测, 并对斜坡区域有着很好的辨识度, 不会将其误识别为障碍物区域.
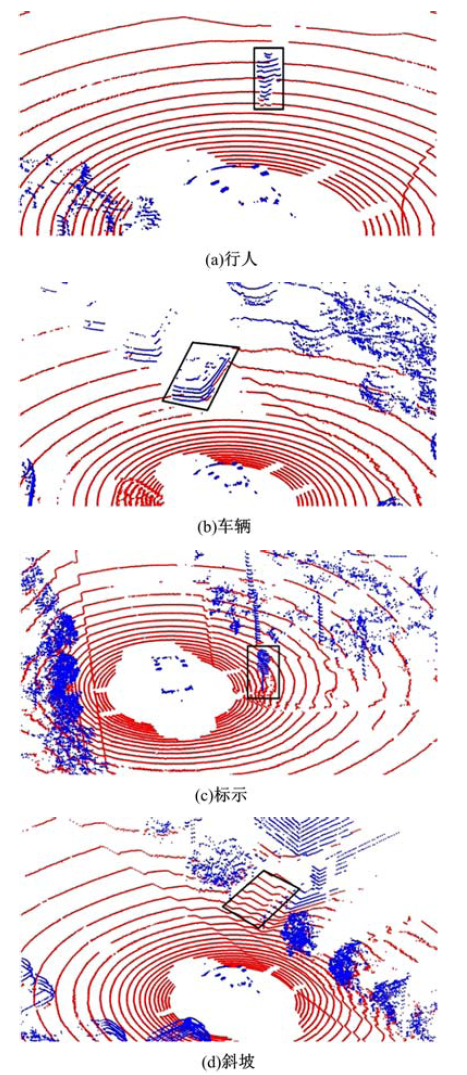 | 图7 仿真结果Fig.7 Simulation experiment results |
介绍了一种基于Velodyne HDL-32E激光雷达的智能车障碍物检测方法.该方法不同于以往的基于栅格的障碍物检测方法.首先, 基于Velodyne激光雷达工作原理建立深度图像; 然后基于深度图像信息在图像矩阵每行上进行聚类分析, 以自适应的方式划分宽度; 最后应用线性模型对深度图像进行逐行检测以划分出障碍物.本方法的优势在于:① 结合了激光雷达工作特点, 以简便的算法应用了全部的点云信息; ② 综合考量了点云深度图像横向和纵向上的相关信息, 并自适应的划分网格跨度, 减小了运算复杂度; ③ 能够较好地解决由于障碍物遮挡造成的盲区影响; ④ 能够很好地区分障碍物区域和斜坡, 避免斜坡区域的误报.
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|