{kind=link}
{kind=link}
{kind=link}
基于优化算子的快速碰撞检测算法
[曲慧雁1, 2  , 赵伟
, 赵伟3, 4 , 秦爱红5 ]
, 赵伟, 秦爱红|
|


作者简介:曲慧雁(1980-),女,副教授,博士.研究方向:虚拟现实,图形图像处理.E-mail:quhuiyan68@163.com
针对复杂人机交互实时性的要求,提出了一种基于优化算子的SIMD并行碰撞检测算法。引入了优化算子,将搜索空间限定在非均匀的局部极小区域,减少了蚁群的搜索时间。在多蚁群求解过程中,将子任务使用负载均衡策略分配到多核处理器的各个处理核心上并行执行,实验结果表明:与经典的I-COLLIDE、MPI及Pipelining等算法相比,本文提出的算法较好地解决了人机交互中的碰撞检测问题。
To meet the real-time requirement in complex human-computer interaction, a Single Instruction, Multiple Data (SIMD) parallel collision detection algorithm based on optimization operator is proposed. By introduction of optimization operator, the search space is confined in a non-uniform local minimum area, reducing the colony search time. In the process of solving the multiple ant colony, the load balancing strategy is used to assign the sub-tasks to each processing core on multi-core processors for parallel execution. Results show that, compared with the classic I-COLLIDE, MPI and Pipelining algorithms, the proposed algorithm has better performance in solving the human-computer interaction in collision detection.
碰撞检测是计算机图形学、增强现实、人机交互等领域研究的热点问题。近几年大规模复杂场景的实时仿真受到了很多学者的关注, 尤其是云计算与大数据技术的出现, 给实时场景的仿真提出了更高的要求, 这也给研究者带来了前所未有的机遇和挑战。由于虚拟环境几何复杂性的增加, 使得碰撞检测的计算复杂性大大提高, 复杂场景的交互消耗了大量的计算机资源, 因此快速的碰撞检测问题成为了虚拟环境中的一个瓶颈[1]。如何设计出满足实时性、精确性要求的高效碰撞检测算法, 成为当前亟待解决的问题。
碰撞检测算法大致可以分为两大类:一类是基于物理空间的碰撞检测算法, 另一类是基于图像空间的碰撞检测算法。基于物理空间的碰撞检测算法, 如空间分解法和层次包围盒法。空间分解法中比较典型的有k-d树、八叉树、BSP树、空间网格等。层次包围盒法比较典型的有:沿坐标轴的包围盒(Axis-aligned bounding boxes, AABB), 包围球(Sphere)、沿任意方向包围盒[2](Oriented bounding box, OBB)和固定方向包围盒[3](Fixs directions hulls, FDH)及k-DOP包围盒。基于图像空间的碰撞检测算法, 如将图形处理单元GPU相关技术应用到碰撞检测中可以提高了碰撞检测的效率[4, 5]。这类算法主要是把复杂计算量分配给GPU减少CPU的计算负荷, 提高了碰撞检测的效率。
针对复杂虚拟空间碰撞检测实时性、精确性的要求, 本文提出了一种基于优化算子的SIMD的并行碰撞检测算法。首先引入了优化算子的概念, 采用优化算子对迭代几乎停滞的最劣子群重新初始化, 使其重新开始新的迭代搜索。将复杂虚拟空间的物体划分为若干子群, 将子群使用负载均衡技术执行SIMD并行模型。对比实验结果表明:与经典的I-COLLIDE、MPI及Pipelining等算法相比, 该算法在效率、精确性方面具有较明显优势, 可以满足人机交互中的碰撞检测实时性和精确性的要求。
定义1 设三维几何空间为R, 用三维几何坐标系统FW表示。在FW中用FA表示模型A所占的集合, 则FA是FW的子集。T={T1, T2, T3, …, Tn}为时间集, Ti表示时间集上的任意时刻, FW随着T变化的四维空间坐标系统CW, 模型A沿着一定轨迹运动够成CW的子集表示为CA。碰撞检测就判断空间坐标系统CW的子集CA是否为空集, 即
碰撞检测过程就是判断空间任何两个几何体之间是否存在相交的过程, 而空间几何体的划分多以三角形为主, 因此相交检测的过程就是三角形与三角形求交的过程。文献[6]提出了矢量判别法和标量判别法两种判别三角形相交的算法, 并通过实验证明了矢量判别法比标量判别法速度快7%, 本文以此算法设计了基本碰撞检测算法, 并采用k-Dop包围盒及并行化的SIMD-Dop的方法实现三角形的求交过程。
在碰撞检测中最常用的技术就是包围盒相交检测技术。目前常用的包围盒技术有包围球、AABB、OBB、k-DOP等, 每一种包围盒都有其各自的优缺点和适用范围。k-DOP即为离散有向多面体(Discrete oriented polyhedron, k-DOP)。
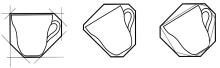
由于k-DOP的平面方向是固定的, 包围盒逼近效果比较好, 几何体重叠相交测试速度快, 所以本文选择k-DOP为碰撞检测层次中的包围体, 随着k的增大, k-DOP与物体的凸包越来越相似, 测试表明, 选k=18时具有最好的效率。如图1所示, 是一个茶杯的8-DOP示例。
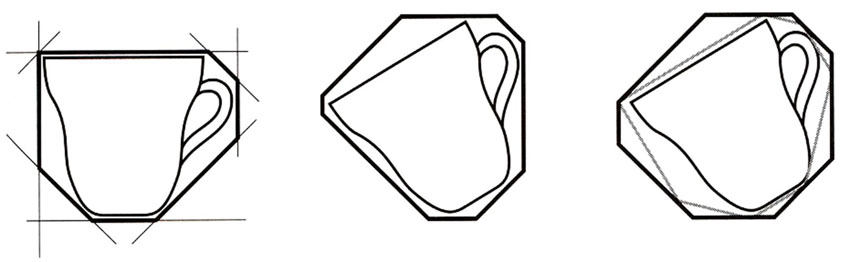 | 图1 一个茶杯的二维8-DOPFig.1 Two-dimensional 8-DOP of a cup |
k-DOP其实是介于AABB和凸包之间的包围盒, 其突出特点是只要合理地选取平行平面对的个数和方向, 就可以在碰撞检测的简单性和包裹物体的紧密性之间灵活取舍, 即紧密性要优于AABB, 而相交测试的复杂度要小于OBB。由于k-DOP包围盒间相交测试的速度是所有包围盒类型中最快的相交测试, 所以本文采用的检测包围盒选择了k-DOP包围盒。鉴于此, 本文提出了一种新的构建k-DOP平衡包围盒树的方法。具体构建方法如下:
(1)任取空间解集M={M1, M2, …, Mn}的任意两个物体Mi∈ M, Mj∈ M, 分别以Mi, Mj为根节点构建其整体k-DOP包围盒树, Mi, Mj包含组成物体所有多边形。
(2)采用文献[7]分裂平面的方法划分Mi, Mj的左右子树。
(3)使用最长轴方法确定分裂轴、分裂点, 然后确定根节点Mi, Mj中所有几何元素的中心点在分裂轴上的投影。
(4)找出最大点和最小点, 并以这两个点为中心点, 将距离投影点分为两组。若有点距两中心点等距, 则将其归入含投影点少的一组。
(5)递归执行上述过程, 直到满足线性判别函数P(x)=* Mj的递归终止条件。其中Mi=(Mi1, Mi2, …, Min), Mj=(Mj1, Mj2, …, Mjn)。Mj1, Mj2, …, Mjn为递归终止条件, 可以是包围盒树高度, 叶子节点中所含基本几何元素的最多数等, Mi1, Mi2, …, Min分别为Mj1, Mj2, …, Mjn对应的加权值。
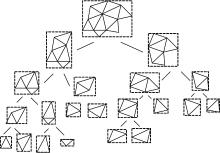
设Mi∈ M, Mj∈ M是空间解集M={M1, M2, …, Mn}的任意两个元素, 不妨设Mi, Mj是构建包围盒树的两个根节点, 按照1.3节k-DOP平衡包围盒树构造方法构造两颗平衡包围盒树。则以Mi, Mj为根节点的平衡包围盒树包含组成物体所有多边形。其划分过程如图2所示。
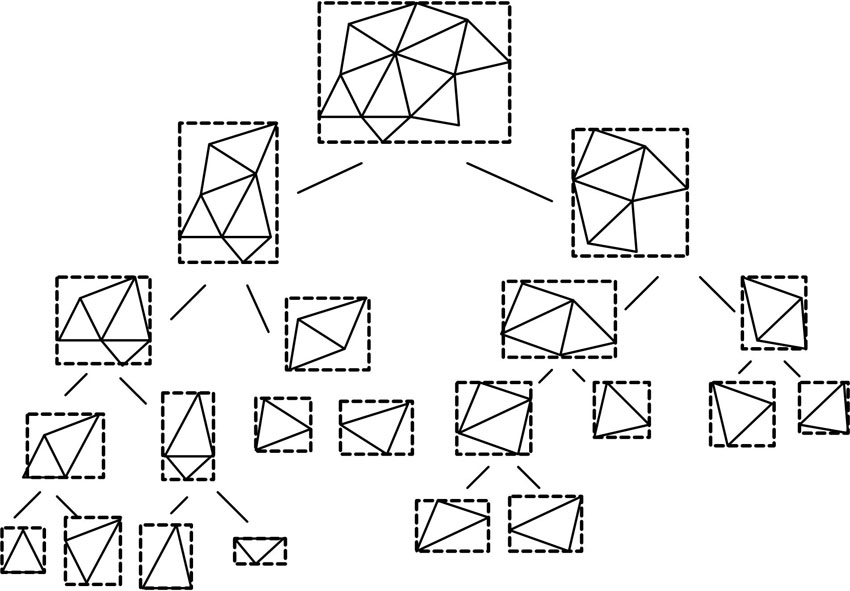 | 图2 划分为几何体的平衡包围盒树Fig.2 Divided into geometry balance bounding box tree |
定理1 任取空间解集 M={M1, M2, …, Mn}的任意两个物体Mi∈ M, Mj∈ M, δ =D(Mi, Mj)为两个物体间距δ ≥ 0, 若两物体之间存在一特征点Mi, j(Mi, Mj), 满足D(Mi, Mj)≤ δ , 当δ =
证明:假设Mi, Mj不相交, 则一定存在一个特征点
所以在随机碰撞检测中, 若判断两个物体是否相交, 就是要判断两个物体之间是否存在一特征点Mi, j(Mi, Mj), 满足D(Mi, Mj)≤ δ 。若存在这样的特征点, 则两物体发生碰撞。Mi, Mj是两物体物体的基本几何元素包围盒特征, 它们在物体空间具有坐标属性(x, y, z), D为距离函数, δ 为距离阈值, 为了能找到满足条件的特征对集合, 本文把问题转化为一个由两模型特征对序号构成的离散二维空间中的优化问题, 并将优化算子引入蚁群优化算法求解, 从而返回模型间的碰撞点。搜索空间M是由两模型特征对任意组合形成的二维离散空间, 并且M的大小为Mi× Mj。构建的搜索空间是一个多峰值的动态空间, 这是因为在物体空间中, 发生碰撞的两个物体可能产生多个碰撞点, 把它描述在搜索空间中即是存在多个极值, 另外在搜索空间中最优解位置变化也会引起搜索空间动态变化。
对于中小规模的应用问题, 蚁群算法可以在允许的时间范围内获得满意的解。对于大规模或超大规模多变量的求解问题, 简单的串行蚁群算法由于可能会出现早熟现象, 从而影响求解过程[8]。近年来出现了一些并行蚁群算法或将串行算法并行化[9], 其目的不只是为了缩短算法的执行时间, 更多的是为了维持群体多样性的能力, 避免算法出现早熟。
为了避免蚁群陷入局部最优解, 本文提出了优化算子的概念。
优化算子:首先将该子种群τ 0和τ max初始化为τ 0=τ max=1/
其中:
Δ =
Sk表示选出的第k个解的路径长度, rk为[0, 1]之间均匀分布的随机数, ck为Δ 的权重值, 由于rk的期望均值为1/2, 所以
对于子种群参数α 、β 和ρ 采用算术交叉方式完成初始化如下:
其中, rk和ck为初始化信息素时保留值。而α k、β k和ρ k则为选出的第k个解所使用的运行参数。
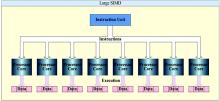
SIMD是在单一控制部件下的多个处理单元构成的阵列, 所以有时也称为阵列处理机。SIMD技术主要用于大量高速向量或矩阵运算的场合。SIMD重复设置多个同样的处理单元(Processing element, PE), 按照一定的方式相互连接, 在统一的控制器控制下, 各自对分配来的数据并行地完成同一条指令所规定的操作。可以提高数据同时运算的效率, 这个特点使SIMD技术特别适合计算密集型的应用, 如三维游戏动画、实时仿真等。如图3所示。
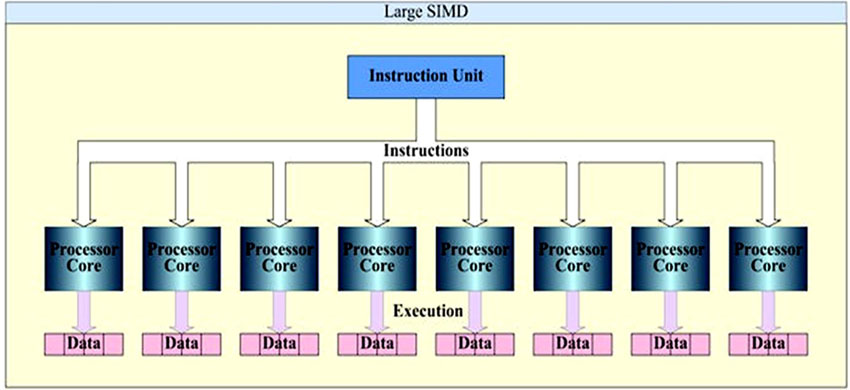 | 图3 SIMD并行处理机模型Fig.3 SIMD parallel processor model |
(1)基于SIMD指令的k-DOP优化
k-DOP是由多组平行面定义的3D空间封闭区域。每组中的两个平行平面限定了物体在平面法向方向上的延伸范围。k-DOP提供了相对AABB更加紧凑的包围盒并且与OBB相比进行构造和整理的代价较小[10]。
通过使用SIMD浮点向量保持所有数据, 我们可以使用SIMD指令对SIMD-DOP重建、整理、重叠测试进行加速, 在k-DOP包围盒树的重建、遍历、相交测试时都可以将SIMD并行指令应用在执行过程, 加速数据处理速度。
(2)基于优化算子的SIMD并行算法
两个碰撞的模型是两个特征集合, 在解空间里就是两个模型的坐标点, 判断两物体是否发生碰撞就是判断两个物体间是否有一特征对间的距离是否达到碰撞的条件。如果将每个特征集合做成一个蚁群, 就可以应用蚁群算法, 在蚁群算法中应用SIMD并行技术。
对于多种群的蚁群算法, 本文提出了一种新的可以避免过早局部收敛的算法, 使用了优化算子。算法开始执行时, 多种群蚁群都处于初始化状态, 在SIMD下并行执行, 如果某个子群陷入局部最优解, 利用信息素优化算子, 重新初始化这个子种群, 同时给出了该算法的SIMD并行实现过程。把这一算法应用到碰撞检测上, 采用了文献[10]的基于前线分解的方法。采用多进程、多线程的并行方式, 对碰撞检测任务进行细粒度分解, 对每个子任务使用负载均衡策略分配到多核处理器的各个处理核心上并行执行。
基于优化算子的并行算法具体实现过程:
Optimization Operator Collision Detection(Mi, Mj)
(1)输入空间解集 M={M1, M2, …, Mn}, 其中
M为蚁群, ∀ Mi∈ M为子群。
(2)输出∀ Mi∈ M, ∀ Mj∈ M, Mi
Mi
(3)初始化M及∀ Mi∈ M子群; 置任意两子群Mi, Mj的检测标志Mif=0, Mjf=0。
构造预检测的层次包围盒BVH:
前线节点集FV={fv1, fv2, …, fvn}
初始化堆栈LIVESMi=∅,
LIVESMj=∅;
初始化碰撞检测标志Collision
flag=FALSE。
(4)如果蚁群M=∅, 表示所有子群都检测完成, 则算法结束, 转到(7); 否则在M中删除Mif=1; Mjf=1的子群; 采用SIMD并行指令并行执行∀ Mi∈ M, ∀ Mj∈ M且Mif=0, Mjf=0任意两子群Mi, Mj的相交检测。
(5)采用SIMD并行多进程、多线程技术更新FV={fv1, fv2, …, fvn}; 更新检测模型的顶点坐标; 更新层次包围盒BVH。
(6)判断是否存在最优解Mi
将检测到碰撞的两个子群压入堆栈, Push Mi, Mj to LIVESMi, LIVESMj。
利用优化算子重新初始化子群Mi, Mj, 使Mif=1, Mjf=1。转到(4)。
(7)输出所有Mi
如果(LIVESMi≠ ∅, LIVESMj≠ ∅)
Pop LIVESMi, LIVESMj。
算法结束。
本文算法已经在一台HP-Z820图形工作站(2颗E5-2643V2, 六核, 3.5 GHz/32GB/2x1TB /K4000)2颗六核心CPU, E5-2643V2, 25MB三级缓存, 3 GB独立显示卡上实现。以Microsoft Visual Studio 2005, VC++为开发工具。实验环境设定了一个复杂的动态场景, 分别选取32个和1500个物体做仿真运动, 基本几何元素数(三角面片数)多于300个和90 000个。为了说明算法的性能, 我们做了如下两个实验:
实验一:时间效率分析
我们把本文提出的优化算子的并行碰撞检测算法(Optimization operator collision detection algorithm, OOCDA)与基本的三角形求交算法(Base collision detection algorithm, BCDA)、经典的I-COLLIDE算法、包围球算法SPHERE、串行算法(Serial collision detection algorithm, SCDA)做了时间复杂性、帧频及运行2000步的时间测试, 实验结果如表1所示。
通过时间复杂性对比分析可知, OOCDA算法与其他4种算法相比, 算法的时间复杂性是O(nlogn), 比BCDA好一些, 与I-COLLIDE、SPHERE、SCDA相同; 在帧频刷新上, 采用OOCDA算法, 帧频刷新可达到15.57 帧/ms, 是其它算法帧频刷新的2.3~5.7倍, 运行2000步所用的时间仅为其它经典算法的1/50~1/1.9, 算法效率有较大提高, 在检测同一场景物体的碰撞检测上用时也有所减少。
实验二:OOCDA与经典串并行算法的比较
对比实验将本文提出的OOCDA算法与经典的串行SCDA算法及另外两种并行算法MPI及Pipelining从时间效率和资源消耗两个方面进行了比较。实验结果如表2所示。其中MPI为采用文献[5]中MPI的并行碰撞检测算法; Pipelining为采用文献[6]中流水线和分治技术的并行碰撞检测算法。
| 表1 算法效率分析 Table 1 Analysis on algorithm time efficiency |
| 表2 OOCDA与串行算法SCDA及并行算法MPI、Pipelining的比较 Table 2 Comparison of OOCDA with serial algorithm SCDA and parallel algorithm MPI, Pipelining |
从对比数据可以看出, 本文提出的OOCDA碰撞检测算法的时间效率高于并行MPI算法, 与Pipelining并行算法几乎相同。这是因为MPI并行工作时采用多进程, 把要进行碰撞检测的物体划分为多任务, 然后分配给多处理机, 由多进程完成碰撞检测的计算任务, 除了计算需要时间外, 进程间还需要通讯, 需要花费额外的通讯时间。而Pipelining并行算法不仅在单进程中采用了多线程, 同时整个任务还采用了多进程, 因此它的效率高于MPI的并行算法, 由于本文提出的优化算子的并行碰撞检测算法也采用了多进程与多线程, 因此OOCDA算法与Pipelining算法用时几乎相近, 略高于Pipelining的主要原因是, 算法中采用了优化算子避免了蚁群算法陷入局部最优解, 优化了模型, 因此减少了算法执行时间。但Pipelining算法的主要缺点是:Pipelining的任务进程数p对算法性能有很大影响, 在实际求解时, 很难找到较合适的最佳p值, 因此算法稳定性较低。从资源消耗方面来说, 本文提出的OOCDA算法效率明显比串行SCDA效率高, 比采用多进程的并行算法MPI要节省内存空间。同时OOCDA具有可移植性强, 实现简单, 可扩展性好, 灵活支持多线程等优点。对于网络大数据间信息通讯极为方便, 同时在海量数据存取上也有优势。
本文提出了一种基于优化算子的并行碰撞检测算法OOCDA。引入了优化算子, 将搜索空间限定在非均匀的局部极小区域, 减少了蚁群的搜索时间。在多蚁群求解过程中, 采用并行任务的细粒度分解, 将子任务使用负载均衡策略分配到多核处理器的各个处理核心上并行执行。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|