







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于车载的运动行人区域估计方法
[李志慧1  , 胡永利
, 胡永利1 , 赵永华2 , 马佳磊1 , 李海涛1 , 钟涛1 , 杨少辉3 ]
, 胡永利, 马佳磊|
|


作者简介:李志慧(1977-),男,副教授,博士.研究方向:交通视频检测与处理.E-mail:lizhih@jlu.edu.cn
针对传统行人检测系统采用全局模板搜索匹配识别易造成大量的盲目空间搜索,降低了行人检测的实时性,且难于直接服务于车载环境下的无人驾驶、行人安全保障技术等应用的问题,基于运动行人与车载移动背景的运动差异性,提出了基于光流聚类的行人区域快速估计方法。该方法首先利用局部与全局光流相结合的计算方法,获取图像光流场;根据移动背景与前景的运动差异,建立了光流聚类算法和背景估计方法,获取剔除背景的可能前景光流图。然后利用图分割算法,实现光流矢量图分割,获取运动物体候选区域。最后根据人体形态特性,判别运动物体候选区域是否为行人有效区域,从而实现行人区域估计。基于JLU-PDS和Daimler国际行人共享测试库进行试验,结果表明本文算法具有较好的检测效果,能够极大地降低行人识别的空间搜索范围,为车载主动行人保障技术、无人驾驶、智能车辆等研究和应用提供了技术支持。
Traditional pedestrian detection system uses global template for search and recognition, resulting in large useless search and reducing the realtime pedestrian detection performance. In addition, it is difficult to apply to unmanned vehicle and pedestrian safety technology in the traffic environment. Based on the difference of motion between pedestrian and vehicle moving background, a fat pedestrian area estimation method is proposed using optical flow clustering. This method uses the combination of local and global optical flow to obtain the optical flow field. According to the difference between background and foreground, the optical flow clustering algorithm and background estimation method are established. Then, the image segmentation algorithm is used to realize the segmentation of optical flow vector. Finally, according to the characteristics of the human body, we can judge whether the candidate region of the moving object is an effective area for pedestrians and realize the pedestrian area estimation. Experiments are carried out based on JLU-PDS and Daimler international pedestrian sharing test library, and experimental environments include the crowed, shelter, streets, fields and other auxiliary working conditions. Results show that the algorithm has good detection effect and greatly reduces the sear space of pedestrian recognition. In addition, it provides technical support and basis for research and application of vehicle active pedestrian protection technology and unmanned intelligent vehicles.
车载行人检测技术利用车辆前方的摄像机等设备检测、定位以及识别行人, 为无人驾驶、自动辅助驾驶等技术提供了智能决策支持, 从而提高行车安全、减少人车碰撞事故。目前, 常用的检查算法有:Haar小波行人检测法[1]、人体形态检测法[2, 3, 4, 5, 6]、HOG+SVM行人检测法[7, 8, 9]等, 这些算法均采用滑动窗口的行人模板匹配方法来识别行人, 但由于模板匹配的全局多尺度窗口搜索策略, 造成行人检测时大量的盲目搜索, 降低了行人检测的实时性。
通过检测行人感兴趣区域(Regions of interest, ROI)可以获得可能存在行人的区域, 减少滑动窗口盲目搜索的时间, 提高行人检测的实时性。目前行人ROI检测方法可分为两类:①特征估计法, 该方法通过图像纹理、颜色、亮度等特征, 估算行人形态、概率密度分布等, 从而获取行人ROI。如:Itti等[10]利用生物激励注意特性, 判断显著性区域, 获取行人ROI; Gualdi等[11]采用蒙特卡洛和高斯核函数密度估计行人ROI; Kamijo等[12]利用时空马尔科夫随机场模型估计行人ROI。该类方法虽然能够获取行人ROI, 但模型较复杂, 增加了行人检测算法的运行时间。②运动检测法, 该方法利用光流计算和运动分割方法, 获取行人区域。如:Zhang等[4]和Elzein等[13]利用光流计算获取场景的光流场, 利用图分割获取行人ROI, 该方法从运动分割的角度为行人ROI估计提供了新的视觉, 但未考虑运动场景与行人的运动差异性, 仍无法降低光流场分割计算的复杂度。
为了快速定位运动行人ROI, 减少行人检测滑动窗口的搜索时间, 本文根据车载运动场景与行人的运动差异性, 提出了一种基于光流聚类的行人ROI快速估计方法。该方法首先计算车载视频图像的光流场, 通过光流场聚类和运动场景的背景光流估计, 剔除背景光流。然后, 利用图分割获取可能的行人前景区域, 根据人体形态特征, 去除非行人区域, 获取行人ROI, 减少了行人识别盲目搜索的时间。最后, 基于自有车载试验平台JLU-PDS进行试验测试, 并与德国奔驰Daimler行人检测基本数据集的测试结果进行对比, 结果表明了本文方法的有效性。
运动行人具有运动突然和随意性强的特点, 往往致使驾驶员难以发现而酿成无法挽回的悲剧。从而, 运动行人ROI快速估计对车载行人预警等智能车辆技术显得尤为重要。为快速估计行人ROI, 本文制定了图1所示的技术框架。该技术框架包括图像获取、光流估计、光流聚类、运动场景背景估计、光流分割、区域判别和感兴趣区域获取等部分。
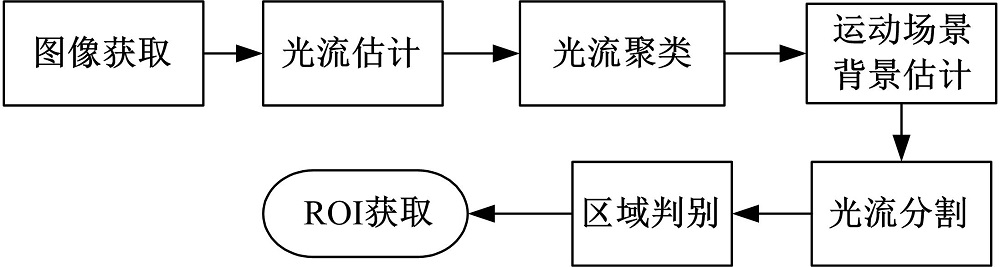 | 图1 基于光流聚类的运动行人ROI估计方法框架Fig.1 ROI estimation method of moving pedestrian based on optical flow clustering |
图像获取利用装载在车辆前方的摄像机获取车辆前方道路信息; 光流估计利用光流计算获取图像的光流场; 光流聚类通过统计每个像素点的光流场强度和运动方向, 获取其运动场直方图, 该处理过程实现了不用运动属性的物体归类; 运动场景背景估计根据车载运动场景具有基本相同的运动属性, 且这些运动属性明显不同于行人的运动属性以及场景背景区域明显大于行人图像区域等特点, 获取直方图的极大值点和分割边界, 实现运动场景背景估计; 光流分割利用去除背景光流的光流场图像和图分割算法, 获取不同的分割区域; 区域判断根据人体形态特征, 剔除非行人区域, 获取行人ROI。
光流场表征为图像二维平面内物体表面的运动矢量场, 是3D空间物体表面在图像的运动投影, 其广泛应用于物体运动检测。经过多年的发展, 在估计精度和速度方面取得重要进展, 并行环境下运算速度可达到45帧/s[14], 其中基于梯度的光流估计方法应用尤为广泛。基于梯度的光流估计方法是在假设光强亮度恒定和物体微小运动的基础上来估计光流矢量场。
令
忽略高阶项
令
其行列式形式为:
图像光流计算矩阵表示为:
为了计算式(5), Lucas和Kanade[15]假定局部邻域为常数, 采用局部光流计算方法, 利用最小二乘法计算矩阵方程求解图像光流场; Horn和Schunck[16]采用全局光流计算方法, 利用松弛迭代法求解全局能量最小, 计算全局光流场。局部光流法对噪声具有较好的鲁棒性, 但计算结果为稀疏光流场; 全局光流法具有较好的图像结构边缘探测精度, 可获取稠密光流, 但抗干扰性较差。为满足行人运动区域估计效率和精度的要求以及降低外界干扰的影响, 本文采用文献[10]中局部与全局相结合的光流求解方法, 该方法利用共轭梯度法快速求解光流矩阵。图2给出连续两帧的光流的孟塞尔颜色可视化系统效果图, 其中矢量角度大小表示色相和色度, 矢量模表示明度。
 | 图2 车载视频连续帧光流效果图Fig.2 Optical flow rendering of vehicle video continuous frame |
图像光流场反映了物体表面在图像平面的运动投影, 因此具有相同运动属性的物体将具有近似相同的光流场。车载相机的移动致使交通场景背景具有近似相同的运动场, 从而交通场景图像的背景每个像素点具有近似相同的光流矢量, 即背景的光流场具有近似相同的幅值和方向。移动个体作为不同于背景的运动, 具有不同于背景的光流场。因此, 根据运动差异性, 可实现对图像光流场聚类前景与背景的分离。
令
为快速获取图像背景光流分量, 分别统计图像光流场每个像素点的幅值
 | 图3 车载视频连续帧及光流图Fig.3 Adjacent frames and optical flow chart |
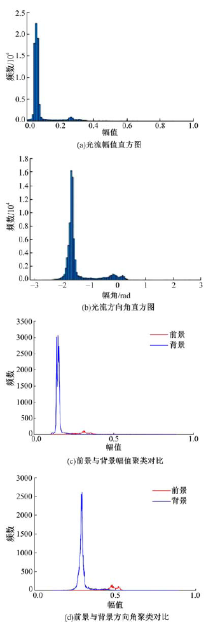
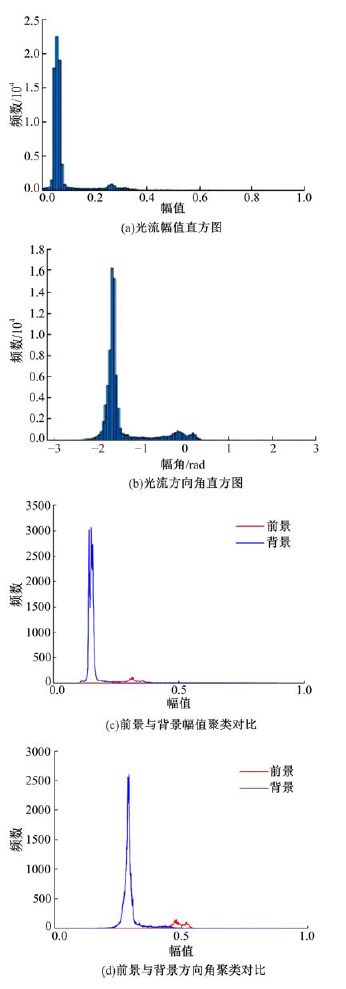 | 图4 光流幅值和方向角直方图以及聚类对比图Fig.4 Amplitude and angle histogram of optical flow, contrast amplitude and angle graph of foreground and background |
由图4可以看出, 背景和前景的光流直方图统计分布为近似高斯分布, 因此图像光流直方图可视为背景、前景、光流场估计误差以及过程噪声等构成的混合高斯分布。
假设图像光流场直方图为
式中:
由于车载视频场景中运行物体和行人个数的不确定性, 图像光流场直方图的混合高斯分布难以确定高斯的个数, 从而通常的期望最大化(Expectation-maximization, EM)算法和K-means等聚类算法难以确定背景的高斯分布。
通常车载视频场景中图像的背景占图像的绝大部分区域, 即图像光流聚类直方图的极大值点对应图像背景区域。因此, 分别统计幅值和方向角直方图的极大值
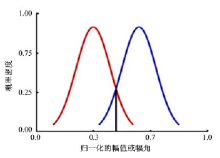
由图5可以看出:两高斯分布的最小误分类阈值
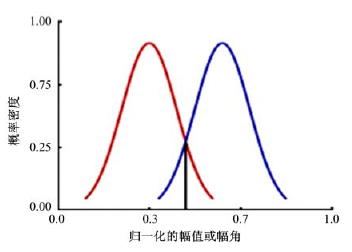 | 图5 双高斯间的最小误分类分割阈值Fig.5 Threshold of minimum misclassification between double Gauss |
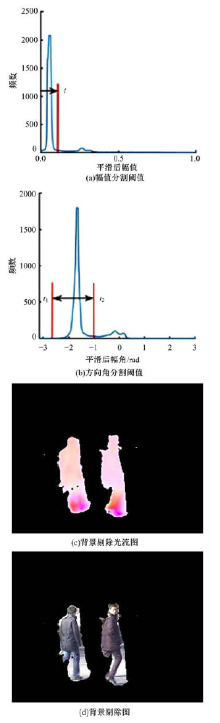
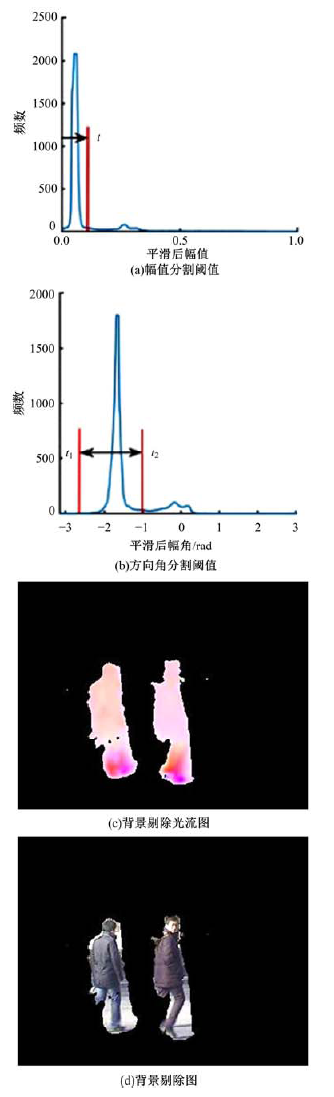 | 图6 图3(a)和(b)相邻帧阈值分割后的效果图Fig.6 Rendering of adjacent frame threshold segmentation of figure 3(a) and 3(b) |
式中:
为了满足背景估计的自适应性要求, 需自适应确定背景光流幅值与方向角的分类阈值, 即自适应确定阈值
为了降低噪声等对直方图造成的干扰, 本文利用平滑窗口函数
由于
通常不同运动物体具有不同的运动属性, 同一运动物体同一时刻具有基本相同的运动属性。对图像光流图而言, 同一物体光流场具有均一性, 不同物体具有不同的光流场。因此, 对图像光流场进行光流分割可实现前景物体的分割。为了有效获取前景物体, 本文对背景剔除后的光流图采用基于图论[17]的分割算法。
式中:
根据图
式中:
根据上述准则进行光流图分割, 得到如图7所示的分割效果图。其中, 图7(a)中蓝色点表示前景光流矢量; 图7(b)中不同区域颜色不同标识。
 | 图7 图分割效果图Fig.7 Rendering of segmentation |
通过图像的前景光流分割获取前景运动物体的有效区域, 但由于前景有效分割区域除了包括行人外, 还可能包含运动车辆、部分背景等, 需进一步剔除非行人区域。由于行人人体形态结构异于其他物体形态的天然特性, 本文利用人体形态的相关指标特征进行判断, 剔除部分非行人区域。
本文选取人体高度与宽度比
式中:
图8为运动区域判别效果, 可见, 区域将面积较大和较小的区域剔除。
 | 图8 运动区域提取示意图Fig.8 Schematic diagram of motion region extraction |
分别利用本课题组研发的JLU-PDS车载试验平台(见图9)以及国际Daimler[4]车载行人测试视频集对本文算法进行测试。
 | 图9 JLU-PDS车载试验平台Fig.9 JLU-PDS vehicle test platforme |
JLU-PDS试验环境选取吉林大学校园内车辆运行环境, 实车测试时长为2 h, 其部分测试结果如图10所示。Daimler测试视频集为野外和城市道路上的视频集, 其部分测试结果如图11所示。
 | 图10 JLU PDS实际场景测试效果图Fig.10 Test results of the JLU PDS actual scene |
 | 图11 Daimler数据库试验效果图Fig.11 Experiment results of Daimler database |
由图10和11可以看出, 本文算法能够较好地满足行人被部分遮挡、野外、街道、人群等复杂环境下的应用, 实现不同尺度下行人ROI区域估计, 同时能够保证行人ROI区域的检测精度, 表明了本文算法具有较好的环境应用性和较好的性能。本文算法对光流分割前进行了预处理, 极大地降低了行人检测的搜索空间, 为车载环境下的行人识别提供了快速、准确的行人区域估计方法。
根据运动行人与车载移动背景的运动差异性, 通过光流聚类获取了不同物体的运动表达, 建立了基于光流聚类的行人ROI估计方法。通过JLU-PDS和Daimler国际行人共享测试库对本文方法进行实际场景测试, 结果表明, 本文方法极大地降低行人识别的空间搜索范围, 克服了传统行人检测的盲目搜索的问题, 能够实现行人的快速检测。该方法可为车载主动行人保障技术、无人驾驶、智能车辆等研究和应用提供技术支持。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|