





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
全局相机姿态优化下的快速表面重建
[林金花1  , 王延杰
, 王延杰2 , 王璐1 , 姚禹3 ]
, 王延杰|
|


作者简介:林金花(1980-),女,讲师,博士.研究方向:数字图像处理、目标识别与跟踪.E-mail:ljh3832@163.com
针对传统三维重建算法存在的漂移问题,提出了一种端到端的在线大规模三维场景重建算法。首先,使用一种在线估计策略来鲁棒地确定相机的旋转姿态,同时构建层次优化框架用于融合深度数据的输入。然后,依据相机的全局估计姿态对每一帧的信息进行优化,解除了算法对目标跟踪时间的限制,完成了对帧间关系对象的实时跟踪。试验结果表明:本文算法的平均重建时间为399 ms,平均估计迭代最低点(ICP)次数为20,完成每帧变换的时间为100 ms;系统对大规模场景的重建具有鲁棒性,且实时性较好,是一种具有对应关系稀疏特性、结构信息稠密特性和相机光照一致特性的实时三维重建算法。
An end-to-end online large-scale 3D scene reconstruction method is proposed. This method uses robustness to estimate the rotation attitude of the camera and constructs a hierarchical optimization framework for the fusion of depth data input. Then, the information of each frame is optimized according to the global pose of the camera, and the algorithm limits the target tracking time and completes real-time tracking of the frame. Experimental results show that the average time to reconstruct the algorithm reaches 399 ms and the average number of estimated Iterative Closest Point (ICP) times is 20, which needs 100 ms to complete each frame transformation. The system is robust to the reconstruction of large-scale scenes and has better real-time performance. This method is a real-time three-dimensional reconstruction system with corresponding sparseness, dense structure information and camera illustration uniformity.
近年来, 获取二维图像并重建三维场景技术的应用范围不断扩大, 主要包括机器视觉系统、三维制造行业以及图像增强等方面。作为用户或机器人需要实时扫描整个房间或多个空间, 将累积的3D模型瞬间、连续地融合到目标应用中; 机器人导航需要将物理世界映射到虚拟世界, 在扫描期间提供即时的信息反馈。这些需求使得研究人员开始对大规模场景的实时重建展开研究。
在过去的几十年, 研究人员对三维重建方法展开了大量的研究。三维重建方法使用多传感器获取底层数据信息, 包括使用点数据信息融合的表示方式[1, 2, 3, 4]、2.5维度的RGB-D数据表示[5, 6]、基于高度信息融合的数据表示[7]以及应用广泛的三维体素融合方法[8, 9]。基于隐式截断距离场(Truncated signed distance felds, TSDF)的三维重建算法是一种鲁棒性强的三维体素融合方法[10], 该方法使用连续函数编码几何表面信息, 对噪声具有抗干扰特性, 且不再受表面拓扑结构的制约。
体素融合算法需要表面几何均匀分布, 不具有普遍适用性, 为了改善这个问题, 科研工作者提出了各种改进算法来实现空间体素融合[11, 12], 使用截断式带符号距离函数表示空间几何结构表面信息是一种普遍适用的表示形式。该算法虽然支持大规模场景的体素融合过程, 然而姿态漂移问题仍然存在, 导致重建后的三维场景失真现象严重。
使用深度图接收的三维重建算法一般要求是非在线算法, Zhou等[13]给出的使用全局相机位置优化的三维重建算法, 通常需要花费1 h以上的时间完成重建。同步定位映射(Simultaneous localization and mapping, SLAM)算法的关键在于准确估计相机位置, 研究者给出了具有在线重建特性的单向深度重建算法, 主要包含具有稀疏特性的重建算法、具有半稠密特性的重建算法以及直接三维重建算法[14, 15]。以上各种算法使用单目深度传感器获取目标场景的姿态图并完成场景的捆绑调整过程, 实现了误差最小化, 然而无法构建精度高的三维表面。
单项体素重建融合算法实现了SLAM算法的稀疏绑定过程, 完成了稠密三维体素的融合过程, 三维重建结果较好, 然而对于大规模的场景重建效果一般。SLAM算法重建一般使用帧到帧的融合算法实现相机位置估计, 同时使用离线算法调整相机位置, 引起重建速率大幅度下降。Newcombe等[16]给出了从图像帧到三维表面的实时检测架构, 实现了从稀疏到稠密的密集三维场景重建, 无需调整重建模型, 然而该算法不适应于大规模场景的三维重建。
迭代最近点(Iterative closest point, ICP)相机位置估计方法使用最近点距离函数预测对象目标位置, 然而重建精度受到影响。研究者使用深度图和整体相机位置估计方法来提高重建算法的精度[17], 包括采用优化目标姿态、检测对象的闭环、绑定位置优化以及基于坐标点与二维图像的重新定位策略来优化目标跟踪过程。这些方法可以实现对三维目标场景的实时重建, 然而优化过程通常需要较长时间, 且闭环策略需要相对繁杂的定位轨迹, 因此对相机运动轨迹是有制约的; 另外, 根据在体素融合前的跟踪信息生成相机运动轨迹, 相对制约了三维场景的优化精度。
针对上述问题, 本文给出了一种CPU端到GPU端的在线体积重建算法, 其关键思想是基于一种相机姿态的鲁棒估计策略, 全局优化每一帧的相机运动轨迹, 同时将深度数据信息融合到一个具有层次架构的整体优化框架中。算法对每个深度帧进行整体到局部的对应关联, 对闭环包的处理主要使用隐含方法进行, 解决了复杂的闭环检测过程。当系统发生检测失败现象时, 跟踪被终止时, 可以从另外一个视角重新启用跟踪, 因此重建鲁棒性较好。
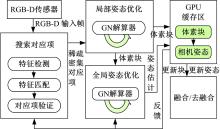
本文使用一种全局相机姿态优化策略, 实现对每一帧图像信息的实时位置优化, 根据优化后的相机姿态来更新下一帧信息, 算法兼容摄像机运动轨迹的多角度变化, 快速定位目标位置且快速重新访问目标区域, 可有效处理遮挡问题, 完成帧间数据的在线跟踪定位, 为大规模场景的在线重建提供了理论基础, 系统重建流程如图1所示。
 | 图1 系统重建流程框图Fig.1 Block diagram of reconstruction system |
(1)根据RGB-D传感器取得深度数据信息, 同时基于稀疏对应关系组合得到整体到局部的对应关系, 接着使用最优密集光照和拓扑对应关系来优化对应关系, 得到尺度不变特征变换(Scale invariant feature transform, SIFT), 查询全部帧间信息对应的SIFT值, 同时使用滤波器过滤异常信息。
(2)在相机全局运动轨迹对准过程中, 使用帧间层次优化策略对全局相机姿态进行优化处理。在第1层优化过程中, 由
(3)根据全局相机姿态优化下的三维场景帧对下一帧信息进行更新, 实现深度数据帧的快速融合, 同时用基于反向融合策略得到帧信息代替在过去相机姿态下获取的深度帧信息, 同时更新当前帧信息。重复此步骤直到重建精度达到阈值要求, 该策略保证了算法对大规模场景的重建精度。
使用全局相机姿态对准策略的实时三维重建的核心是鲁棒性强的整体分层姿态优化过程。输入数据是由深度传感器获取的深度流:
式中:
本文基于目标特征匹配和相应的滤波策略来检测帧间的稀疏对应关系组合。准确的对应关系组合对应精准的全局优化过程至关重要, 下面将主要阐明对应关系的检测滤波过程。
对于每个新获取的帧数据, 计算SIFT特征值, 同时将该帧信息对应到全部先前帧处。SIFT用于说明深度信息的检测结果变化情况, 例如缩放, 平移, 旋转等步骤。然后对帧间数据进行滤波操作, 生成对应关系组合, 该组合用于全局相机姿态优化过程, 该过程如图2所示。该步骤主要在GPU上完成, 减少了数据备份视觉, 降低了中央处理器开销。本文计算SIFT信息描述符的速率大概是4~5 ms/帧, 帧间对应关系匹配时间是0.05 ms。对于新获得的深度帧信息, 该算法可同时在线检测2× 104帧。
 | 图2 本文算法的匹配过程Fig.2 Matching process of proposed algorithm |
对应异常值的处理过程, 本文使用光照和拓扑对应特性来滤掉已有的对应关系组合。
首先, 对于帧对组合
其次, 计算帧
最后, 本文对拓扑结构和光照检测进行密集处理, 基于关键坐标点与滤波检测相互匹配的测量, 获取对应关系变换
式中:
(1)给定一组帧数据(块或关键帧内的帧, 取决于层次水平)之间的三维对应项, 姿态对准的目标是找到每个帧
式中:
本文将对齐问题定义为未知参数
式中:
注意, 参考帧表示块中的第1帧, 用于块内对齐; 或表示整个输入序列中的第1帧, 用于全局块内对齐。因此, 参考变换
在稀疏匹配项中, 本文对所有帧间的特征对应项的世界空间位置距离之和进行最小化处理:
式中:
式(4)的含义是寻找最优的刚性变换
(2)本文使用密集光度和几何约束进行精细尺度对准, 计算每个输入帧的颜色
式中:
对于密集光度一致性, 通过计算亮度
式中:
通过计算点到平面的几何度量获取切平面的精细度量对准:
式中:
这里忽略输入帧之外投影的对应项, 并且在每个优化步骤之后, 使用ICP约束项来测量帧间距离和法线约束。对于密集的光度和几何约束, 本文将
 | 图3 本文重建算法的层次匹配效果Fig.3 Matching results of proposed reconstruction algorithm |
全局姿态对准是未知相机参数的非线性最小二乘问题。为了实现对超过两万帧的长扫描序列进行在线全局相机姿态优化, 本文采用一种基于GPU的非线性迭代求解器, 由于稀疏模式需要不同的并行化策略, 本文采用高斯-牛顿方法(一阶可导, 二次收敛), 通过计算非线性最小二乘方来寻找最优姿态参数
为了便于表示, 本文以规范最小二乘法形式表示:
式中:
通过定义向量域
这里使用
式中:
用式(11)所示的局部近似代替
为了获得最小值
系统在GPU上并行处理共轭梯度(PCG)求解器, 并使用雅克比预处理器来求解式(13), 同时使用迭代策略求解系统矩阵
系统使用单一内核计算最佳步长, 更新相机下降方向和全局-局部切换来累积得到最终扫描结果, 使用PCG算法构建系统矩阵以及当前下降方向。首先考虑稀疏特征项, 为了避免填入, 基于两个单独的内核调用递增地乘以系统矩阵:第1个内核乘以
对于精密的光度和几何对准项, 相关残留的数量相当高。由于系统矩阵在PCG工作期间固定, 本文在每个非线性迭代开始时预先计算它。所需的内存是预分配的, 本文只通过分散写入更新非零项即可。注意, 随着共享内存局部特性的减少, 只需要少量的写入操作。
作为一种优化措施, 本文系统在每次优化结束之后执行对应项帧过滤, 该操作对于潜在的通信异常值(被错误地认为是有效的)的处理是鲁棒的。也就是说, 使用GPU的并行缩小操作来确定最大残差
本文使用全局摄像机的对准姿态优化策略完成大规模场景的鲁棒重建。检测帧间的对应关系变化过程, 使用体素融合与体素去融合的方式完成目标场景的三维体素变更。因此, 当算法搜索到较优的估计姿态时, 便可实现目标场景的精准重建, 减少了累积误差, 同时降低了漂移率。
基于体素数据结构表示的三维重建策略, 使用带符号距离场(TSDF)来表示目标对象的几何信息, 并将全部深度信息融合到该表示结构中, 实现对场景信息的完整表征。TSDF表示方式基于体素空间的拓扑结构表示, 用于存放TSDF信息的数据结构较复杂, 同时会影响算法的效率, 因此, 本文使用Lin等[18]提出的方法来完成重建, 空余三维空间无需表示, 算法基于三维体素索引策略, 使用稀疏体素网格存放每个TSDF值, 这里定义体素大小为8 cm× 8 cm× 8 cm。另外, 在实时更新相机姿态的过程中, 本文使用融合和去融合方法将深度信息整合到了TSDF空间表示中[19, 20]。
对于复杂场景中的每个空间体素,
体素的去融合更新操作如下所示:
本文算法针对当前帧执行融合操作, 将上一帧的信息融合到当前帧, 同时对上一帧执行去融合操作, 去掉冗余值, 融合后的场景信息较好地保留了原始的几何拓扑结构信息, 同时为下一帧的融合过程提供依据, 这种策略在保证重建精度的同时, 避免了不必要的整合, 提高了算法的重建效率。
为了测试本文系统的性能, 选取不同照明条件来完成大规模真实场景的三维重建过程。软硬件配置如下:操作系统为Windows 10; 编程环境为VS 2016; 中央处理器型号为INTEL Core i5; 图形处理器型号为NVIDIA 1070i/8G; 深度传感器为Asus Xtion Pro; 传感器的帧绘制速率为30 Hz/s, 捕获信息分辨率为640× 480。
重建的视觉反馈被流传输到系统界面以帮助扫描过程。本文采用数据压缩方式处理帧数据流, 以此减少带宽的限制。采用CUDA 8.0框架完成相机姿态的全局对应。本文选取了6个不同的三维场景实施重建, 其中包括4个房间M1~M4, 一个桌面M5, 一个纹理墙M6以及长80 m的帧序列, 重建结果显示相机姿态的对准率较好, 无显著的摄像机漂移现象。
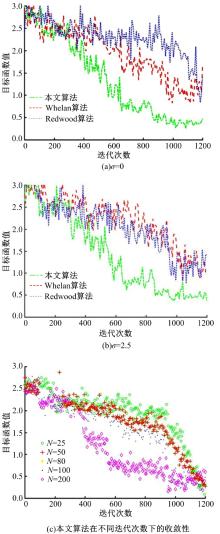
采用定量评估的方式测试本文算法的重建性能, 当预设重建点云数量和噪声干扰强度的前提下, 构建500种测试用例, 针对采样噪声组, 分成5组用例和5级噪声。本文给出了包括Whelan、Redwood以及本文算法的性能对比图, 如图4所示。在噪声强度的影响下, 三维重建点的位置也变化, 同时目标函数随迭代次数的增加而变化。根据试验结果显示, 算法的收敛性与重建三维点符合线性变换关系, 然而当噪声强度不同的情况下, 算法的收敛性也会受到影响。本文算法适用于大规模点云数据的实时三维重建, 且重建精度较高。
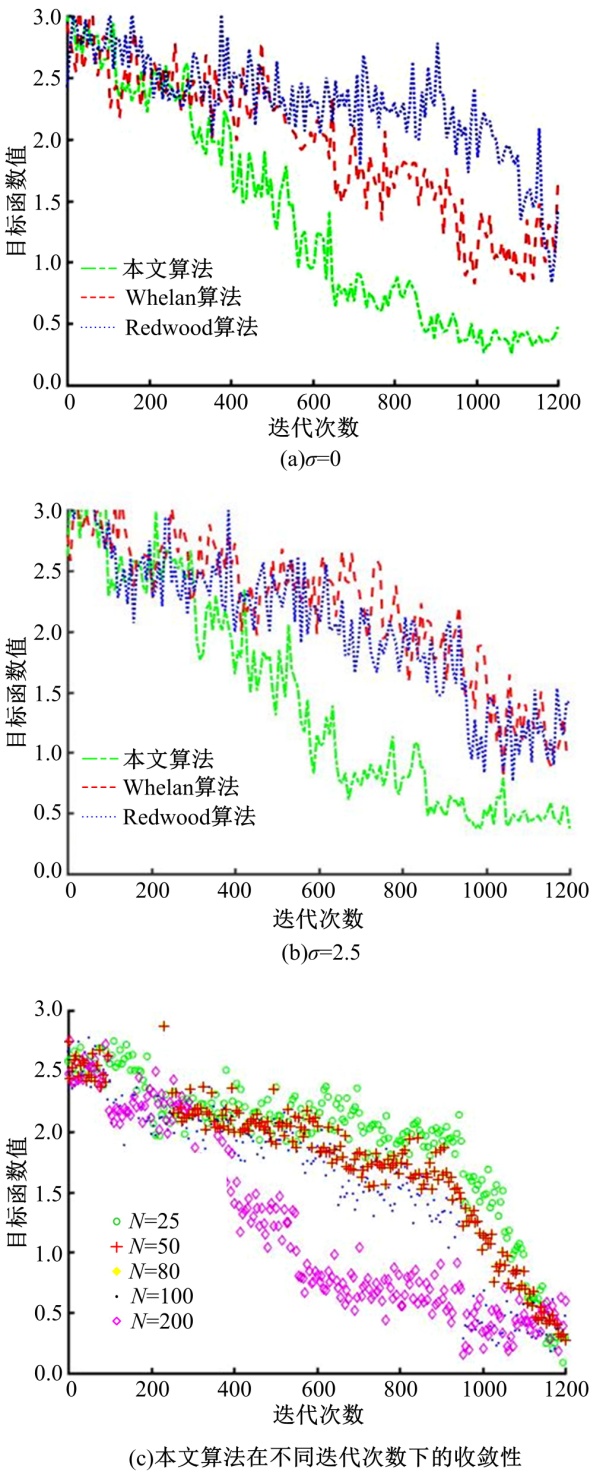 | 图4 Whelan、Redwood及本文算法的收敛性Fig.4 Comparison of Whelan、Redwood and our algorithm for convergence |
这里对图5所示的三维场进行重建, 以此来测试算法的重建精度。当输入数据不包含噪声干扰时, 即使外点数量增加, 也不会影响三维场景的重建精度; 另外, 当输入数据包含噪声干扰时, 场景的重建精度也无明显变化, 表明本文算法具有抗干扰特性, 尤其对噪声干扰及外点数量具有鲁棒性。
 | 图5 纹理墙模型M 6三维重建效果图Fig.5 Texture wall model M6 three dimensional reconstruction result |
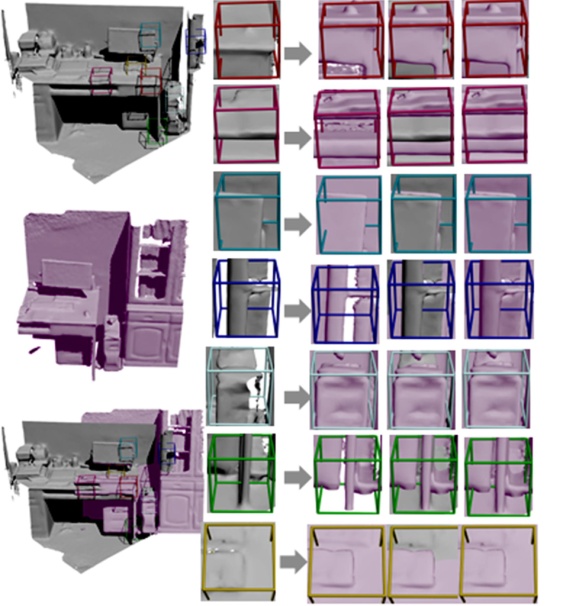
本组试验使用NVIDIA GeForce GTX Titan X和GTX Titan Black组合技术。Titan X用于体积重建, Titan Black用于对应搜索和全局姿态优化。对于所有的测试场景, 本文算法采用大于30 Hz的速率来获取目标场景, 在整体稠密更新的后续帧中, 绘制速率小于500 ms/帧, 三维重建结果如图6所示。从图6可以看出:本文算法与Whelan、Redwood算法相比, 重建质量相当甚至针对大规模缺损场景的重建, 本文算法表现得更好, 重建精度与离线重建算法的重建精度相当, 这是一般在线算法很难达到的精度, 重建效果显示无漂移, 对于结构纹理复杂的曲面, 重建效果较好、无伪影。
 | 图6 系统大规模重建效果图Fig.6 System large scale reconstruction map |
本文算法与Whelan、Redwood算法的比较结果显示:Whelan、Redwood算法在使用深度传感器获取场景并重建的过程中, 漂移现象严重, 尤其对规模较大的三维场景, 累积误差明显。本文算法使用全局相机姿态优化策略, 在保证重建精度的情况下, 满足了大规模场景的实时重建需求, 同时漂移现象较小, 如图7所示。
 | 图7 本文系统重建恢复(M5)Fig.7 Reconstruction recovery of our system(M5) |
为测试本文算法对遮挡情况的鲁棒性, 选取实物对目标场景进行遮挡测试。当目标场景被遮挡后, 本文算法可实现快速的恢复更新重建, 恢复速率较高, 以至于重建漂移不明显, 仅存在于小面积范围内, 当遮挡物被快速移除时, 本文算法具有不敏感特性, 几乎对场景重建精度无任何影响。由此可见, 本文算法的重建过程对遮挡现象具有鲁棒性, 且同时具有中断后快速更新复原特性, 适用于大规模复杂场景无遮挡、无伪影的快速重建。
本文算法能够鲁棒地处理循环闭包, 如图8所示。体素三维重建以持续的融合过程对相机获取的帧数据流进行更新处理, 同时完成几何结构的实时融合和去融合处理, 同时对循环闭包进行鲁棒重建处理。当摄像机的定位发生变动时, Whelan算法对小区域场景的重建精度较差, 漂移现象较严重; Redwood算法在三维重建精度方面比Whelan算法要好, 然而随着重建场景规模的扩大, 两种算法的重建速率下降, 因此不适应于大规模场景的实时重建。本文算法在初始帧获取阶段, 显示出些微错误检测现象, 然而随着传感器采用数据的增加, 相机姿态可以被较精确地定位, 重建精度明显提高, 因此本文算法适用于对重建精度和实时性能要求较高的大规模场景的实时三维重建。
 | 图8 三种算法的相机姿态优化比较Fig.8 Comparison of three algorithms about optimization of camera pose |
本文提出了一种基于全局相机姿态优化策略的实时三维重建算法, 在使用深度传感器获取目标场景信息的同时完成了在线大规模场景的鲁棒重建。使用SIFT捆绑调整策略实现了本地与全局目标姿态的精准对齐, 同时使用动态优化策略对扫描到的帧数据进行实时优化重建, 保证了大规模场景的重建精度, 同时使用融合和去融合算法实现对三维场景的在线更新渲染重建。本文算法对大规模场景的重建精度较高, 相当于离线重建水平, 同时保证了重建速度, 是一种适用于大规模场景重建的在线算法。本文算法的在线三维重建速率为415 ms/帧, ICP姿态平均估计次数为20次, 传感器姿态变换的时间为100.0 ms, 可用于机器人视觉系统的信息获取、人工智能和虚拟现实领域以及对实时性要求较高的三维重建过程。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|