Journal of Jilin University(Engineering and Technology Edition) ›› 2026, Vol. 56 ›› Issue (2): 289-312.doi: 10.13229/j.cnki.jdxbgxb.20250382
A review of digital human technology: modeling methods and driving strategies
Zhen-dong LI1,2( ),Zhen-xin ZHU1,Shi-hua ZHAO1,Yi-qiang WU1,2,Hao LIU1,2
),Zhen-xin ZHU1,Shi-hua ZHAO1,Yi-qiang WU1,2,Hao LIU1,2
- 1.School of Information Engineering,Ningxia University,Yinchuan 750021,China
2.Ningxia Key Laboratory of Artificial Intelligence and Information Security for Channeling Computing Resources from the East to the West,Yinchuan 750021,China
CLC Number:
- TP391.41



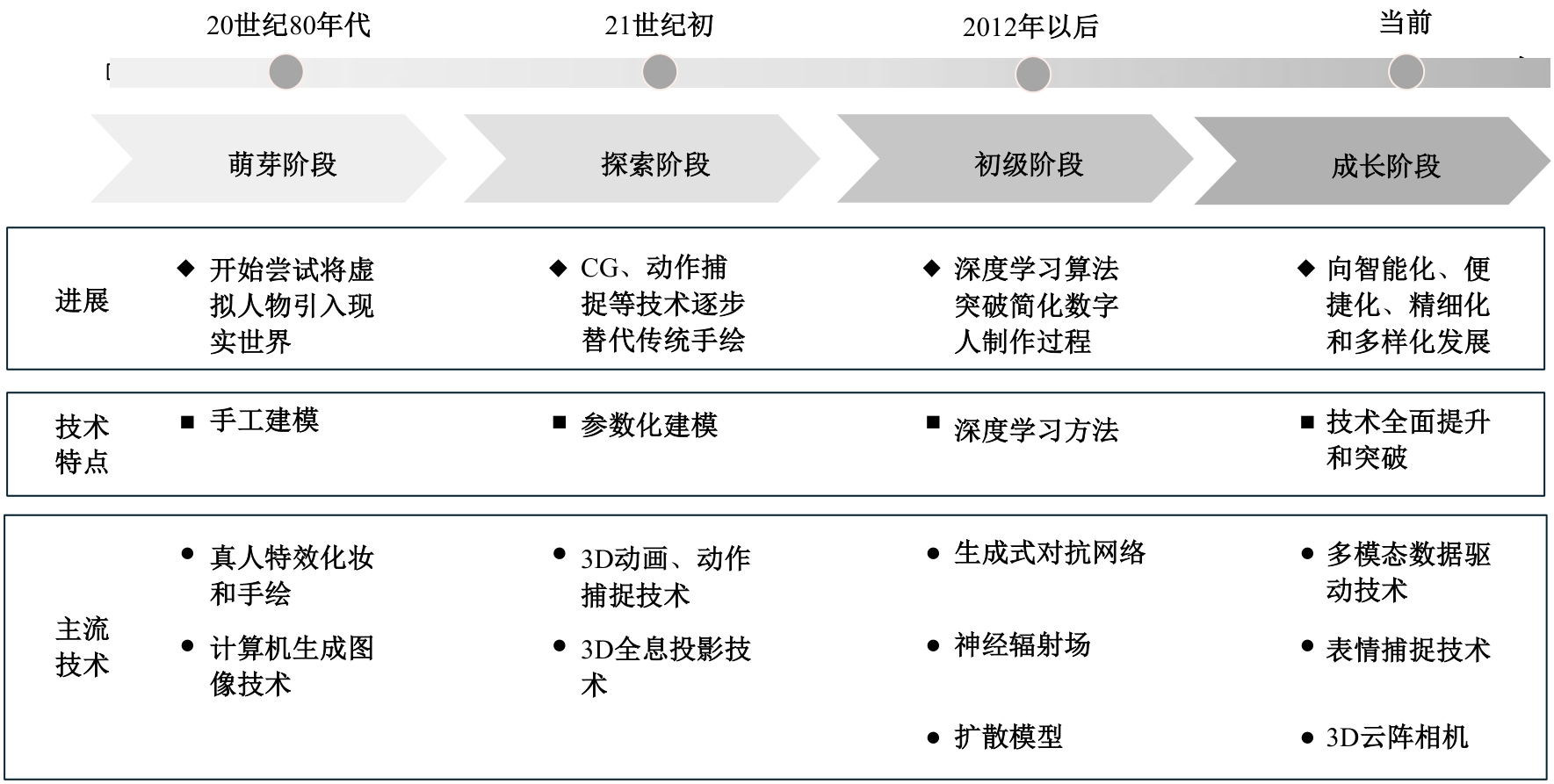
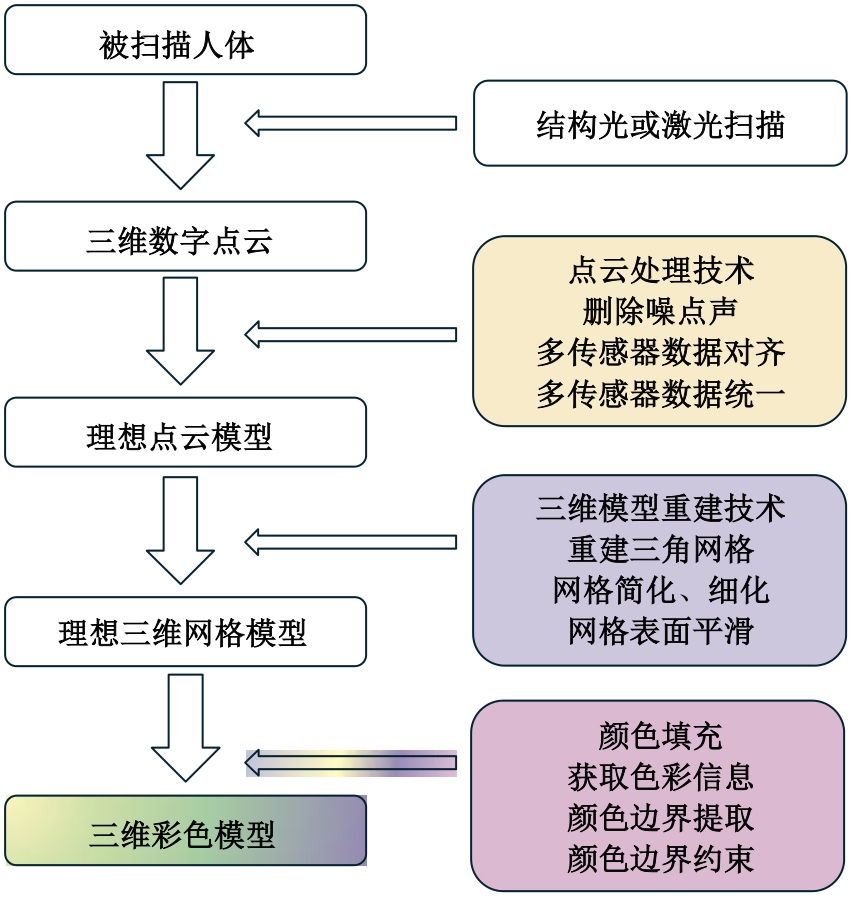


























| [1] | Mildenhall B, Srinivasan P P. Nerf: representing scenes as neural radiance fields for view synthesis[J]. Communications of the ACM, 2021, 65(1): 99-106. |
| [2] | Goodfellow I, Pouget A J. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-144. |
| [3] | Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33: 6840-6851. |
| [4] | Kingma D P, Welling M. Auto-encoding variational bayes[C]∥Proceedings of the International Conference on Learning Representations, Banff,Canada, 2014: No.13126114. |
| [5] | 徐继红, 张文斌. 非接触式三维人体扫描技术的综述[J]. 扬州职业大学学报, 2006, 2006(3): 49-53. |
| Xu Ji-hong, Zhang Wen-bin. A review of non-contact 3D human body scanning technology[J]. Journal of Yangzhou Polytechnic College, 2006, 2006(3): 49-53. | |
| [6] | Stefanie W, Peng C X, Chang S. Human shape correspondence with automatically predicted landmarks[J]. Machine Vision and Applications, 2012, 23(4): 821-830. |
| [7] | Wei Z, Chen H, Nan L, et al. PathNet: path-selective point cloud denoising[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(6): 4426-4442. |
| [8] | Besl P J, Mckay H D. A method for registration of 3-D shapes[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1992, 14(2): 239-256. |
| [9] | 林瑞, 王俊英, 孙水发, 等. 基于Kinect的骨骼配准的人体三维重建[J]. 信息通信, 2016, 2016(12): 206-209. |
| Lin Rui, Wang Jun-ying, Sun Shui-fa, et al. 3D human body reconstruction based on Kinect skeletal registration[J]. Changjiang Information & Communications, 2016, 2016(12): 206-209. | |
| [10] | 庞浩, 李吉平. ICP算法的改进及两台Kinect对人体的重建[J]. 大连工业大学学报, 2017, 36(6):459-463. |
| Pang Hao, Li Ji-ping. Improvement of ICP algorithm and human body reconstruction using two Kinects[J]. Journal of Dalian Polytechnic University, 2017, 36(6): 459-463. | |
| [11] | Kazhdan M, Hoppe H. Screened poisson surface reconstruction[J]. ACM Transactions on Graphics, 2013, 32(3): 1-13. |
| [12] | Anguelov D, Srinivasan P, Koller D, et al. SCAPE: shape completion and animation of people[J]. ACM Transactions on Graphics, 2005, 24(3): 408-416. |
| [13] | Loper M, Mahmood N, Romero J, et al. SMPL: a skinned multi-person linear model[J]. ACM Transactions on Graphics, 2015, 34(6): 1-16. |
| [14] | Bogo F, Kanazawa A, Lassner C, et al. Keep it SMPL: automatic estimation of 3D human pose and shape from a single image[C]∥Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, Netherlands, 2016: 561-578. |
| [15] | Lassner C, Romero J, Kiefel M, et al. Unite the people: closing the loop between 3D and 2D human representations[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6050-6059. |
| [16] | Blanz V, Vetter T. A morphable model for the synthesis of 3D faces[C]∥Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, New York, USA, 1999: 187-194. |
| [17] | Deng Y, Yang J, Xu S, et al. Accurate 3D face reconstruction with weakly-supervised learning: from single image to image set[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, USA, 2019: No.201900038. |
| [18] | Feng Y, Feng H, Black M J, et al. Learning an animatable detailed 3D face model from in-the-wild images[J]. ACM Transactions on Graphics, 2021, 40(4): 1-13. |
| [19] | Daněček R, Black M J, Bolkart T. Emoca: emotion driven monocular face capture and animation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 20311-20322. |
| [20] | Karras T, Aila T, Laine S, et al. Progressive growing of GANs for improved quality, stability, and variation[C]∥International Conference on Learning Representations, Vancouver, Canada, 2018: No.171010196. |
| [21] | Karras T, Laine S, Aittala M, et al. Analyzing and improving the image quality of stylegan[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 2020: 8110-8119. |
| [22] | Tulyakov S, Liu M Y, Yang X D, et al. MoCoGAN: Decomposing motion and content for video generation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1526-1535. |
| [23] | Huang H, He R, Sun Z, et al. Introvae: introspective variational autoencoders for photographic image synthesis[J]. Advances in Neural Information Processing Systems, 2018, 31: 52-63. |
| [24] | Jiang L M, Dai B, Wu W E, et al. Deceive d: adaptive pseudo augmentation for gan training with limited data[J]. Advances in Neural Information Processing Systems, 2021, 34: 21655-21667. |
| [25] | Esser P, Rombach R, Blattmann A, et al.Imagebart: bidirectional context with multinomial diffusion for autoregressive image synthesis[J]. Advances in Neural Information Processing Systems, 2021, 34: 3518-3532. |
| [26] | Lee D, Kim C. Autoregressive image generation using residual quantization[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 11523-11532. |
| [27] | Barron J T, Mildenhall B, Verbin D, et al. Mip-nerf 360: unbounded anti-aliased neural radiance fields[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 5470-5479. |
| [28] | Schwarz K, Liao Y, Niemeyer M, et al. Graf: generative radiance fields for 3D-aware image synthesis[J]. Advances in Neural Information Processing Systems, 2022, 33: 20154-20166. |
| [29] | Bergman A W, Kellnhofer P, Wang Y F, et al. Generative neural articulated radiance fields[J]. Advances in Neural Information Processing Systems, 2022, 35: 19900-19916. |
| [30] | Cai S, Obukhov A, Dai D, et al. Pix2nerf: unsupervised conditional p-gan for single image to neural radiance fields translation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 3981-3990. |
| [31] | Li Z, Zheng Z, Wang L, et al. Animatable gaussians: learning pose-dependent gaussian maps for high-fidelity human avatar modeling[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 19711-19722. |
| [32] | Shao Z, Wang Z, Li Z, et al. Splattingavatar: realistic real-time human avatars with mesh-embedded gaussian splatting[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 1606-1616. |
| [33] | Wen J, Zhao X, Ren Z, et al. Gomavatar: efficient animatable human modeling from monocular video using gaussians-on-mesh[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 2059-2069. |
| [34] | Lu Y, Tai Y W, Tang C K. Attribute-guided face generation using conditional cyclegan[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 282-297. |
| [35] | Liu Y, Li Q, Sun Z. Attribute-aware face aging with wavelet-based generative adversarial networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 11877-11886. |
| [36] | Men Y, Mao Y, Jiang Y, et al. Controllable person image synthesis with attribute-decomposed gan[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 5084-5093. |
| [37] | Mansimov E, Parisotto E, Ba J L, et al. Generating images from captions with attention[C]∥International Conference on Learning Representations, San Diego, USA, 2015: 1-12. |
| [38] | Xu T, Zhang P, Huang Q, et al. Attngan: fine-grained text to image generation with attentional generative adversarial networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1316-1324. |
| [39] | Canfes Z, Atasoy M F, Dirik A, et al. Text and image guided 3D avatar generation and manipulation[C]∥Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 4421-4431. |
| [40] | Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation[C]∥International Conference on Machine Learning, Virtual, 2021: 8821-8831. |
| [41] | Yu J, Xu Y, Koh J Y, et al. Scaling autoregressive models for content-rich text-to-image generation[J]. Transactions on Machine Learning Research, 2022, 6: No.220610789. |
| [42] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 6: 1-11. |
| [43] | Huang Z, Chan K C, Jiang Y, et al.Collaborative diffusion for multi-modal face generation and editing[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2023: 6080–6090. |
| [44] | Wu J Z, Ge Y X, Wang X T, et al. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation[C]∥Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2023: 7623-7633. |
| [45] | Song J, Meng C, Ermon S. Denoising diffusion implicit models[C]∥International Conference on Learning Representations, Virtual, 2021: No.201002502. |
| [46] | Lee Y, Terzopoulos D, Waters K. Realistic modeling for facial animation[C]∥Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, USA, 1995: 55-62. |
| [47] | Chuang E, Bregler C. Performance driven facial animation using blendshape interpolation[J]. Computer Science Technical Report, 2002, 2(2): 1-3. |
| [48] | Cootes T F, Edwards G J, Taylor C J. Active appearance models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(6): 681-685. |
| [49] | Pighin F, Hecker J, Lischinski D, et al. Synthesizing realistic facial expressions from photographs[C]∥Computer Graphics Proceedings, Annual Conference Series. Association for Computing Machinery Siggraph, Orlando, USA, 1998: 75-84. |
| [50] | Bouaziz S, Wang Y, Pauly M. Online modeling for realtime facial animation[J]. ACM Transactions on Graphics, 2013, 32(4): 1-10. |
| [51] | Thies J, Zollhofer M, Stamminger M, et al. Face2face: real-time face capture and reenactment of rgb videos[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2387-2395. |
| [52] | Wiles O, Koepke A S, Zisserman A. X2face: a network for controlling face generation using images, audio, and pose codes[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 670-686. |
| [53] | Siarohin A, Lathuilière S, Tulyakov S, et al. Animating arbitrary objects via deep motion transfer[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 2377–2386. |
| [54] | Siarohin A, Lathuilière S, Tulyakov S, et al. First order motion model for image animation[C]∥Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 7137-7147. |
| [55] | Zhao J, Zhang H. Thin-plate spline motion model for image animation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 3657-3666. |
| [56] | Hong F T, Zhang L, Shen L, et al. Depth-aware generative adversarial network for talking head video generation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 3397–3406. |
| [57] | Zhang B, Qi C, Zhang P, et al. Metaportrait: identity-preserving talking head generation with fast personalized adaptation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 22096-22105. |
| [58] | Doukas M C, Ververas E, Sharmanska V, et al. Free-headgan: neural talking head synthesis with explicit gaze control[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(8): 9743-9756. |
| [59] | Zakharov E, Shysheya A, Burkov E, at el. Fewshot adversarial learning of realistic neural talking head models[C]∥Proceedings of the IEEE International Conference on Computer Vision, Seoul, South Korea, 2019: 9459-9468. |
| [60] | Yao G M, Yuan Y, Shao T J, et al. Mesh guided one-shot face reenactment using graph convolutional networks[C]∥Proceedings of the 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 1773-1781. |
| [61] | Wang Q, Zhang L, Li B. Safa: structure aware face animation[C]∥2021 International Conference on 3D Vision, London, UK, 2021: 679-688. |
| [62] | Khakhulin T, Sklyarova V, Lempitsky V, et al. Realistic one-shot mesh-based head avatars[C]∥European Conference on Computer Vision, Tel Aviv, Israel, 2022: 345-362. |
| [63] | Li X, De M S, Liu S, et al. Generalizable one-shot 3D neural head avatar[J]. Advances in Neural Information Processing Systems, 2023, 36: 47239-47250. |
| [64] | Wu W, Zhang Y, Li C, et al. Reenactgan: learning to reenact faces via boundary transfer[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 603-619. |
| [65] | Wang Y, Yang D, Bremond F, et al. Latent image animator: learning to animate images via latent space navigation[C]∥ICLR 2022-The International Conference on Learning Representations,Virtual, 2022: No.220309043. |
| [66] | Meshry M, Suri S, Davis L S, et al. Learned spatial representations for few-shot talking-head synthesis[C]∥Proceedings of the IEEE International Conference on Computer Vision, Virtual, 2021: 13829-13838. |
| [67] | Zakharov E, Ivakhnenko A, Shysheya A, et al. Fast bi-layer neural synthesis of one-shot realistic head avatars[C]∥Computer Vision–ECCV 2020: 16th European Conference, Virtual, 2020: 524-540. |
| [68] | Ni H, Liu Y, Huang S X, et al. Cross-identity video motion retargeting with joint transformation and synthesis[C]∥Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 412-422. |
| [69] | Bounareli S, Argyriou V, Tzimiropoulos G. Finding directions in gan's latent space for neural face reenactment[J]. Arxiv Preprint, 2022,2: 202200046. |
| [70] | Gafni G, Thies J, Zollhöfer M, et al. Dynamic neural radiance fields for monocular 4D facial avatar reconstruction[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 2021: 8649-8658. |
| [71] | Hong Y, Peng B, Xiao H Y, et al. Headnerf: a real-time nerf-based parametric head model[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 20374-20384. |
| [72] | Li W, Zhang L, Wang D, et al. One-shot high-fidelity talking-head synthesis with deformable neural radiance field[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 17969-17978. |
| [73] | Mallya A, Wang T C, Liu M Y. Implicit warping for animation with image sets[J]. Advances in Neural Information Processing Systems, New Orleans, USA, 2022, 35: 22438-22450. |
| [74] | Rabiner L R. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Proceedings of the IEEE, 1989, 77(2): 257-286. |
| [75] | Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| [76] | Zaremba W, Sutskever I, Vinyals O. Recurrent neural network regularization[J]. Arxiv Preprint,2014,9:20142329. |
| [77] | Yamamoto E, Nakamura S, Shikano K. Lip movement synthesis from speech based on hidden Markov models[J]. Speech Communication, 1998, 26(2): 105-115. |
| [78] | Xie L, Liu Z Q. A coupled HMM approach to video-realistic speech animation[J]. Pattern Recognition, 2007, 40(8): 2325-2340. |
| [79] | Chung J S, Jamaludin A, Zisserman A. You said that?[C]∥British Machine Vision Association and Society for Pattern Recognition, London, UK, 2017: 170502966. |
| [80] | Cudeiro D, Bolkart T, Laidlaw C, et al. Capture, learning, and synthesis of 3D speaking styles[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 10101-10111. |
| [81] | Zhang Z, Hu Z, Deng W, et al. Dinet: deformation inpainting network for realistic face visually dubbing on high resolution video[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, Washington, USA, 2023, 37(3): 3543-3551. |
| [82] | Fan B, Wang L, Soong F K, et al. Photo-real talking head with deep bidirectional LSTM[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing, Brisbane, Australia, 2015: 4884-4888. |
| [83] | Zhou Y, Han X, Shechtman E, et al. Makelttalk: speaker-aware talking-head animation[J]. ACM Transactions On Graphics, 2020, 39(6): 1-15. |
| [84] | Chen L, Maddox R K, Duan Z, et al. Hierarchical cross-modal talking face generation with dynamic pixel-wise loss[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 7832-7841. |
| [85] | Prajwal K R, Mukhopadhyay R, Namboodiri V P, et al. A lip sync expert is all you need for speech to lip generation in the wild[C]∥Proceedings of the 28th ACM International Conference on Multimedia, Rio de Janeiro, Brazil, 2020: 484-492. |
| [86] | Tan S, Ji B, Pan Y. Emmn: emotional motion memory network for audio-driven emotional talking face generation[C]∥Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2023: 22146-22156. |
| [87] | Mittal G, Wang B. Animating face using disentangled audio representations[C]∥Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, Aspen, USA, 2020: 3290-3298. |
| [88] | Liu J, Wang X, Fu X, et al. FONT: flow-guided one-shot talking head generation with natural head motions[C]∥IEEE International Conference on Multimedia and Expo, Brisbane, Australia, 2023: 2099-2104. |
| [89] | Zhang W, Cun X, Wang X, et al. Sadtalker: learning realistic 3D motion coefficients for stylized audio-driven single image talking face animation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 8652-8661. |
| [90] | Fan Y, Lin Z, Saito J, et al. Faceformer: speech-driven 3D facial animation with transformers[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 18770-18780. |
| [91] | Bernardo B, Costa P. A speech-driven talking head based on a two-stage generative framework[C]∥Proceedings of the 16th International Conference on Computational Processing of Portuguese, Santiago, Spain, 2024: 580-586. |
| [92] | Guo Y, Chen K, Liang S, et al. Ad-nerf: audio driven neural radiance fields for talking head synthesis[C]∥Proceedings of the IEEE International Conference on Computer Vision, Virtual, 2021: 5784-5794. |
| [93] | Yao S, Zhong R Z, Yan Y, et al. Dfa-nerf: personalized talking head generation via disentangled face attributes neural rendering[J]. Arxiv Preprint, 2022, 1: No.220100791. |
| [94] | Li J, Zhang J, Bai X, et al. Efficient region-aware neural radiance fields for high-fidelity talking portrait synthesis[C]∥Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2023: 7568-7578. |
| [95] | Ye Z, Jiang Z, Ren Y, et al. Geneface: generalized and high-fidelity audio-driven 3D talking face synthesis[C]∥International Conference on Learning Representations, Kigali, Rwanda, 2023: No.230113430. |
| [96] | Yu Z, Yin Z, Zhou D, et al. Talking head generation with probabilistic audio-to-visual diffusion priors[C]∥Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2023: 7645-7655. |
| [97] | Shen S, Zhao W, Meng Z, et al. Difftalk: crafting diffusion models for generalized audio-driven portraits animation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 1982-1991. |
| [98] | Bigioi D, Basak S, Stypułkowski M, et al. Speech driven video editing via an audio-conditioned diffusion model[J]. Image and Vision Computing, 2024, 142: No.104911. |
| [99] | Cooke M, Barker J, Cunningham S, et al. An audio-visual corpus for speech perception and automatic speech recognition[J]. The Journal of the Acoustical Society of America, 2006, 120(5): 2421-2424. |
| [100] | Cao H, Cooper D G, Keutmann M K, et al. Crema-d: crowd-sourced emotional multimodal actors dataset[J]. IEEE Transactions on Affective Computing, 2014, 5(4): 377-390. |
| [101] | Harte N, Gillen E. TCD-TIMIT: an audio-visual corpus of continuous speech[J]. IEEE Transactions on Multimedia, 2015, 17(5): 603-615. |
| [102] | Chung J S, Zisserman A. Lip reading in the wild[C]∥Computer Vision-ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, China, 2017, 2(13): 87-103. |
| [103] | Busso C, Parthasarathy S, Burmania A, et al. MSP-IMPROV: an acted corpus of dyadic interactions to study emotion perception[J]. IEEE Transactions on Affective Computing, 2016, 8(1): 67-80. |
| [104] | Badr A, Hassan A A. VoxCeleb1: speaker age-group classification using probabilistic neural network[J]. International Arab Journal of Information Technology, 2022, 19(6): 854-860. |
| [105] | Suwajanakorn S, Seitz S M, Kemelmacher S I. Synthesizing obama: learning lip sync from audio[J]. ACM Transactions on Graphics, 2017, 36(4): 1-13. |
| [106] | Czyzewski A, Kostek B, Bratoszewski P, et al. An audio-visual corpus for multimodal automatic speech recognition[J]. Journal of Intelligent Information Systems, 2017, 49: 167-192. |
| [107] | Chung J S, Nagrani A, Zisserman A. VoxCeleb2: deep speaker recognition[J]. Arxiv Preprint, 2018, 6: 180605622. |
| [108] | Afouras T, Chung J S, Senior A, et al. Deep audio-visual speech recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 44(12): 8717-8727. |
| [109] | Afouras T, Chung J S, Zisserman A. LRS3-TED: a large-scale dataset for visual speech recognition[J]. Arxiv Preprint, 2018, 9: No.180900496. |
| [110] | Alghamdi N, Maddock S, Marxer R, et al. A corpus of audio-visual lombard speech with frontal and profile views[J]. The Journal of the Acoustical Society of America, 2018, 143(6): 523-529. |
| [111] | Poria S, Hazarika D, Majumder N, et al. Meld: a multimodal multi-party dataset for emotion recognition in conversations[J]. Association for Computational Linguistics, 2019, 7: 527-536. |
| [112] | Livingstone S R, Russo F A. The ryerson audio-visual database of emotional speech and song (RAVDESS): a dynamic, multimodal set of facial and vocal expressions in North American English[J]. Plos One, 2018, 13(5): No.e0196391. |
| [113] | Yang S, Zhang Y, Feng D, et al. LRW-1000: a naturally-distributed large-scale benchmark for lip reading in the wild[C]∥2019 14th IEEE International Conference on Automatic Face & Gesture Recognition, Lille, France, 2019: 1-8. |
| [114] | Rossler A, Cozzolino D, Verdoliva L, et al. Faceforensics++: learning to detect manipulated facial images[C]∥Proceedings of the IEEE International Conference on Computer Vision, Seoul, South Korea, 2019: 1-11. |
| [115] | Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 4401-4410. |
| [116] | Wang K, Wu Q, Song L, et al. Mead: a large-scale audio-visual dataset for emotional talking-face generation[C]∥European Conference on Computer Vision, Virtual, 2020: 700-717. |
| [117] | Zhang Z, Li L, Ding Y, et al. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 2021: 3661-3670. |
| [118] | Wang T C, Mallya A, Liu M Y. One-shot free-view neural talking-head synthesis for video conferencing[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Virtual, 2021: 10039-10049. |
| [119] | Zhu H, Wu W, Zhu W, et al. CelebV-HQ: a large-scale video facial attributes dataset[C]∥European Conference on Computer Vision, Tel Aviv, Israel, 2022: 650-667. |
| [120] | Wu C, Zheng N, Ardisson S, et al. Multiface: a dataset for neural face rendering[J]. Arxiv Preprint, 2022, 7: No.220711243. |
| [121] | Chen L, Cui G, Kou Z, et al. What comprises a good talking-head video generation?[C]∥IEEE Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 2020: No.200503201. |
| [122] | Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612. |
| [123] | Heusel M, Ramsauer H, Unterthiner T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[J]. Advances in Neural Information Processing Systems, 2017, 30: No.170608500. |
| [124] | Zhang R, Isola P, Efros A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 586-595. |
| [125] | Chen L, Li Z H, Maddox R K, et al. Lip movements generation at a glance[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 520-535. |
| [126] | Hong F T, Xu D. Implicit identity representation conditioned memory compensation network for talking head video generation[C]∥Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2023: 23062-23072. |
| [127] | Doukas M C, Zafeiriou S, Sharmanska V. Headgan: one-shot neural head synthesis and editing[C]∥Proceedings of the IEEE International Conference on Computer Vision, Virtual, 2021: 14398-14407. |
| [128] | 张雪. 维塔数字智能面部动画系统在电影《阿凡达:水之道》得到成功应用[J]. 现代电影技术, 2023, 2023(5): 63-64. |
| Zhang Xue. The successful application of weta digital's intelligent facial animation system in the film avatar: the way of water[J]. Advanced Motion Picture Technology, 2023, 2023(5): 63-64. | |
| [129] | 韦剑峰. 虚拟数字人技术在广电新媒体中的应用[J]. 卫星电视与宽带多媒体, 2024, 21(19): 22-24. |
| Wei Jian-feng. Application of virtual digital human technology in radio, television and new media[J]. Satellite TV & IP Multimedia, 2024, 21(19): 22-24. |
| [1] | Xiao-hui WEI,Bing-yi SUN,Jia-xu CUI. Recommending activity to users via deep graph neural network [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(1): 278-284. |
| [2] | LI Jun, LI Xiong-fei, DONG Yuan-fang, ZHAO Hai-ying. New performance evaluation method for classifier [J]. 吉林大学学报(工学版), 2012, 42(02): 463-468. |
|
||