
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高斯Sigma点选取的改进UPF算法
[曹洁 , 戴彬, 李晓旭]
, 戴彬, 李晓旭]
, 戴彬, 李晓旭]
|
|


作者简介:曹洁(1966-),女,教授,博士生导师.研究方向:信息融合理论与应用,智能交通,信息检测与估计. E-mail:caoj@lut.cn
针对标准粒子滤波存在的粒子退化现象,提出了一种改进的UPF算法。该算法采用基于高斯Sigma点选取的自适应无味卡尔曼滤波产生建议分布函数,然后利用Metropolis-Hastings(MH)方法优化粒子,提高了对系统后验概率密度的逼近程度。仿真结果表明:改进算法降低了粒子滤波算法的粒子退化程度,提高了跟踪精度。
An improved Unscented Particle Filter (UPF) algorithm is proposed to overcome the problem of particles degradation in the standard particle filter. The algorithm uses adaptive unscented Kalman filter based on Gaussian Sigma point selection to generate the proposal distribution function. Then it uses the Metropolis-Hastings (MH) algorithm to optimize particles, so that the approximation of the posterior probability density of the system is improved. Simulation results show that the improved UPF algorithm reduces particle degradation which exists in the particle filter algorithm, and improves tracking accuracy.
非线性、非高斯随机系统的状态估计问题在统计学、语音和图像处理、数字通信、计算机视觉、自适应估计、机器学习及自动控制等领域有着广泛应用[ 1]。解决一般非线性状态估计问题常用Kalman滤波的相关改进算法,包括扩展Kalman滤波(EKF)[ 2]、无味Kalman滤波(UKF)[ 3]等。这些算法基本思想是通过参数化的解析式对系统的非线性进行近似来进行状态估计。但在许多非线性和非高斯条件下,这些滤波算法在估计系统状态时误差较大,可能导致滤波发散。近年来,粒子滤波[ 4]被应用在解决非线性和非高斯系统状态估计问题上,但仍存在粒子退化现象。建议分布函数的选择是影响该问题一个重要因素,研究人员提出了很多基于建议分布函数选择的粒子滤波算法,其中有似然粒子滤波[ 5]、扩展粒子滤波(EPF)[ 6]、无味粒子滤波(UPF)[ 7]和高斯-厄米粒子滤波[ 8]等。其中UPF算法是目前被广泛应用的一种改进粒子滤波算法,但UPF算法的精度很大程度上取决于Sigma点的选取方式,现有的选取方式主要是对称选取,这种选取方式使Sigma点的采样点数过多,影响了算法的效率。
基于此,本文提出了一种改进的UPF算法。该算法采用高斯Sigma点选取的自适应无味卡尔曼滤波产生建议分布函数,然后利用MH方法[ 9]优化粒子,提高了对系统后验概率密度的逼近程度。为了评估本文提出的改进算法的性能,选择两个仿真系统将其与PF、EPF和UPF三种算法进行了比较。
粒子滤波是一种基于蒙特卡罗方法和递推贝叶斯估计的统计滤波方法。该方法核心思想是利用一系列随机样本的加权和来表示系统状态的后验概率密度,以样本均值代替积分计算,从而获得状态的最小方差估计。
假设非线性系统动态模型如下:
式中:
令
式中:粒子
式(3)中:
UPF算法是UKF算法和PF算法的结合。在PF算法中,为了求解方便,一般取先验概率密度为建议分布函数。但是,这种选取方法丢失了当前时刻的量测值,使得当前时刻的状态严重依赖于模型。如果模型不准确,或者量测噪声突然增大,这种选取方法将不能有效地表示概率密度函数的真实分布,会产生很大的估计偏差。UPF算法则是在PF的基础上利用UKF产生建议分布函数,每一次采样的粒子集都由UKF算法进行更新,所得的均值和方差用于下一次采样新粒子集。在重要性采样环节引入最新的观测量,可以在一定程度上抑制粒子退化。
UKF是无味变换和标准Kalman滤波体系的结合。无味变换的基本思想是根据
(1)初始化
计算Sigma点:
式中:
(2)时间更新
(3)观测更新
采用2.1节提出的基于高斯Sigma点选取的UKF算法产生建议分布函数,并利用MH方法对建议分布函数抽样产生的粒子进行优化,得出状态的估计值,提出了一种改进的UPF算法,称为UPF-MH算法。其具体实现步骤如下:
(1)初始化
在
(2)预测更新
对于给定的
预测协方差为:
(3)发散判断
由
进行修正
(4)量测更新
根据式(13)~(17),求得:
(5)采样粒子
计算权重:
归一化权值:
(6)给定一个
(7)状态更新
为了验证本文提出的UPF-MH算法,将其与PF、EPF、UPF算法进行比较,并采用以下两个系统进行仿真。
系统1:
其中,过程噪声
系统2:
其中,过程噪声
实验中,粒子数目分别设置为
综合评价指标(Performance evaluation)定义为:
式中:
均方误差越小,仿真时间越短,PE越小,说明算法的跟踪综合性能越高。
表1和表2分别为系统1和系统2采样粒子数
| 表1 4种算法的RMSE值和PE值对比(系统1) Table 1 Comparison of RMSE and PE of four algorithms(system1) |
| 表2 4种算法的RMSE值和PE值对比(系统2) Table 2 Comparison of RMSE and PE of four algorithms(system2) |
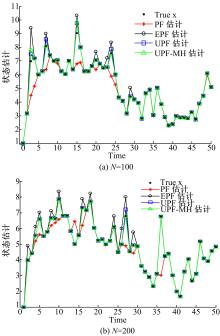
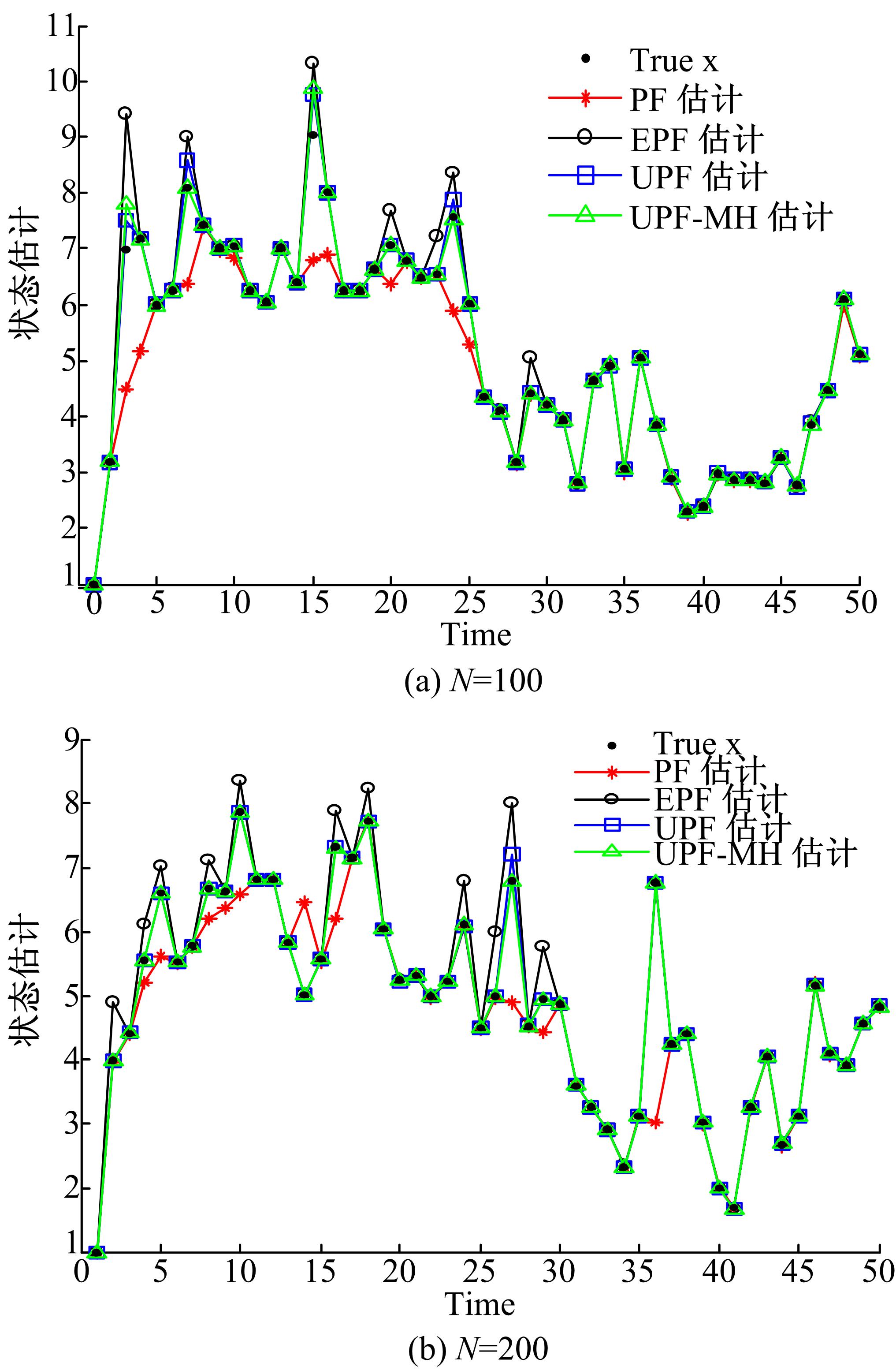 | 图1 4种算法的状态估计(系统1)Fig.1 State estimation of four algorithms(system1) |
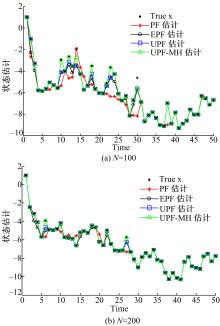
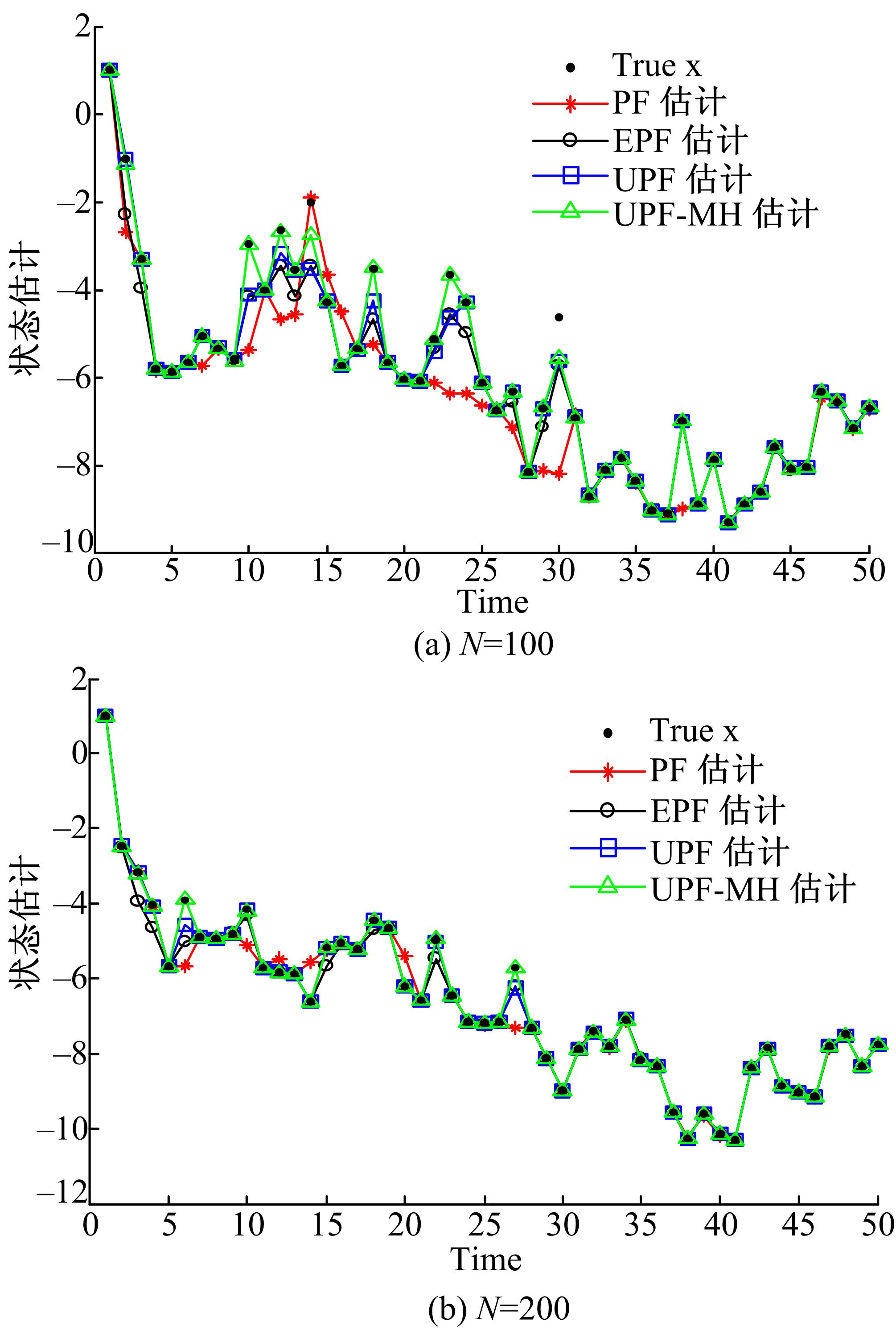 | 图2 4种算法的状态估计(系统2)Fig.2 State estimation of four algorithms(system2) |
从图1可以看出,在粒子数相同的情况下,4种算法都能在一定程度上对非线性系统状态进行估计,其中UPF和UPF-MH这两种算法的估计效果好于PF和EPF的估计效果,而UPF-MH估计效果比PF、EPF和UPF有明显提高。从表1可以看出,UPF-MH的RMSE和PE值都是最小的,说明UPF-MH有较高的估计精度。从图2以及表2可以看出,在系统2中,UPF-MH的估计精度同样比其他3种算法的估计精度高。
综上,UPF-MH算法比其他3种算法具有较高的估计精度和较好的性能。
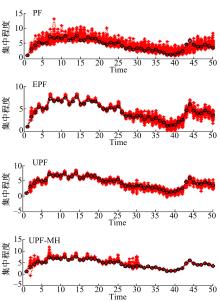
实验中将UPF-MH、PF、EPF和UPF四种算法中建议分布函数抽样产生粒子的状态值和真实状态值表示出来进行粒子集中程度的对比(粒子数设为
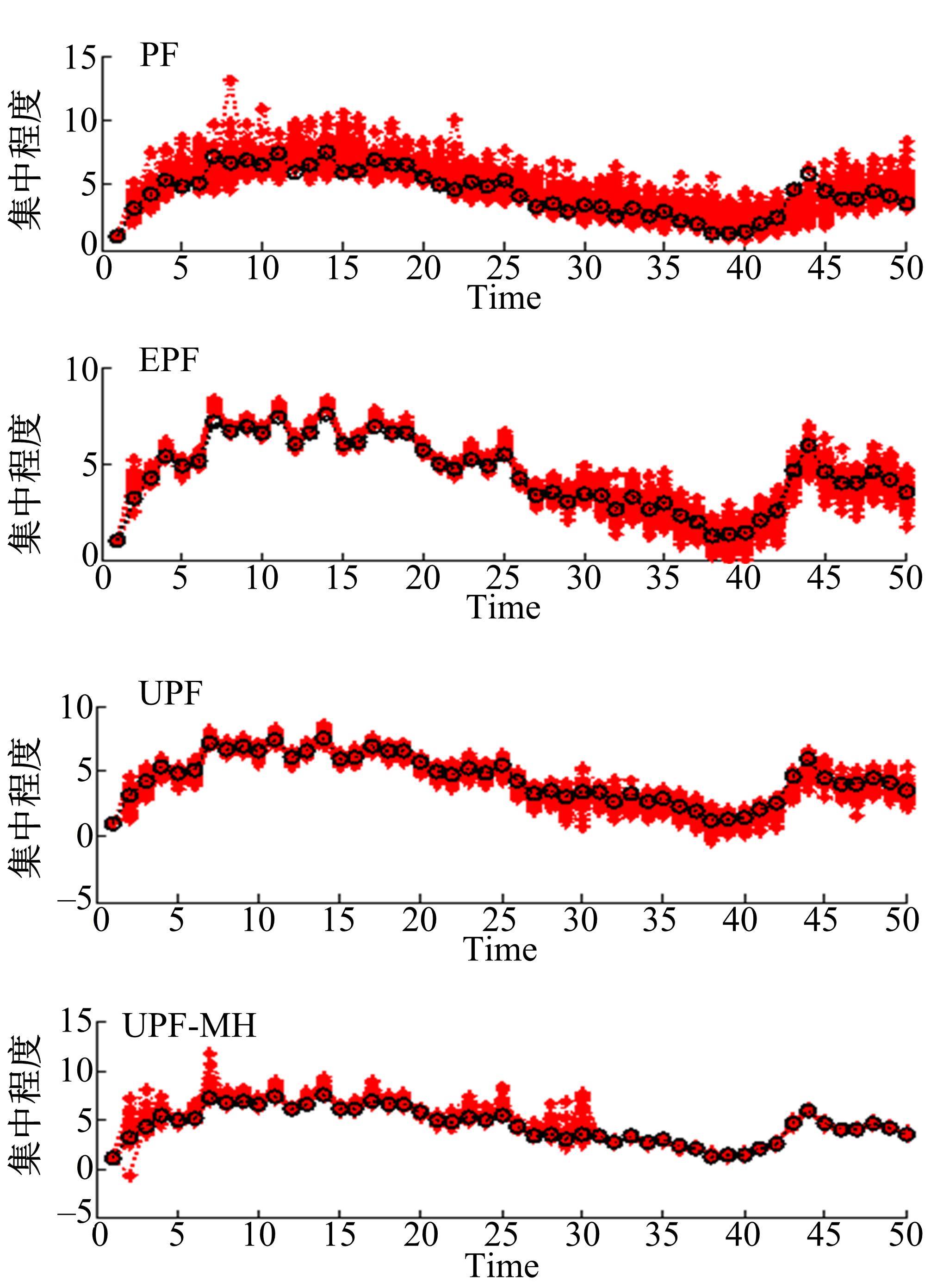 | 图3 系统1中的粒子集中程度对比Fig.3 Comparison of particle concentration in system1 |
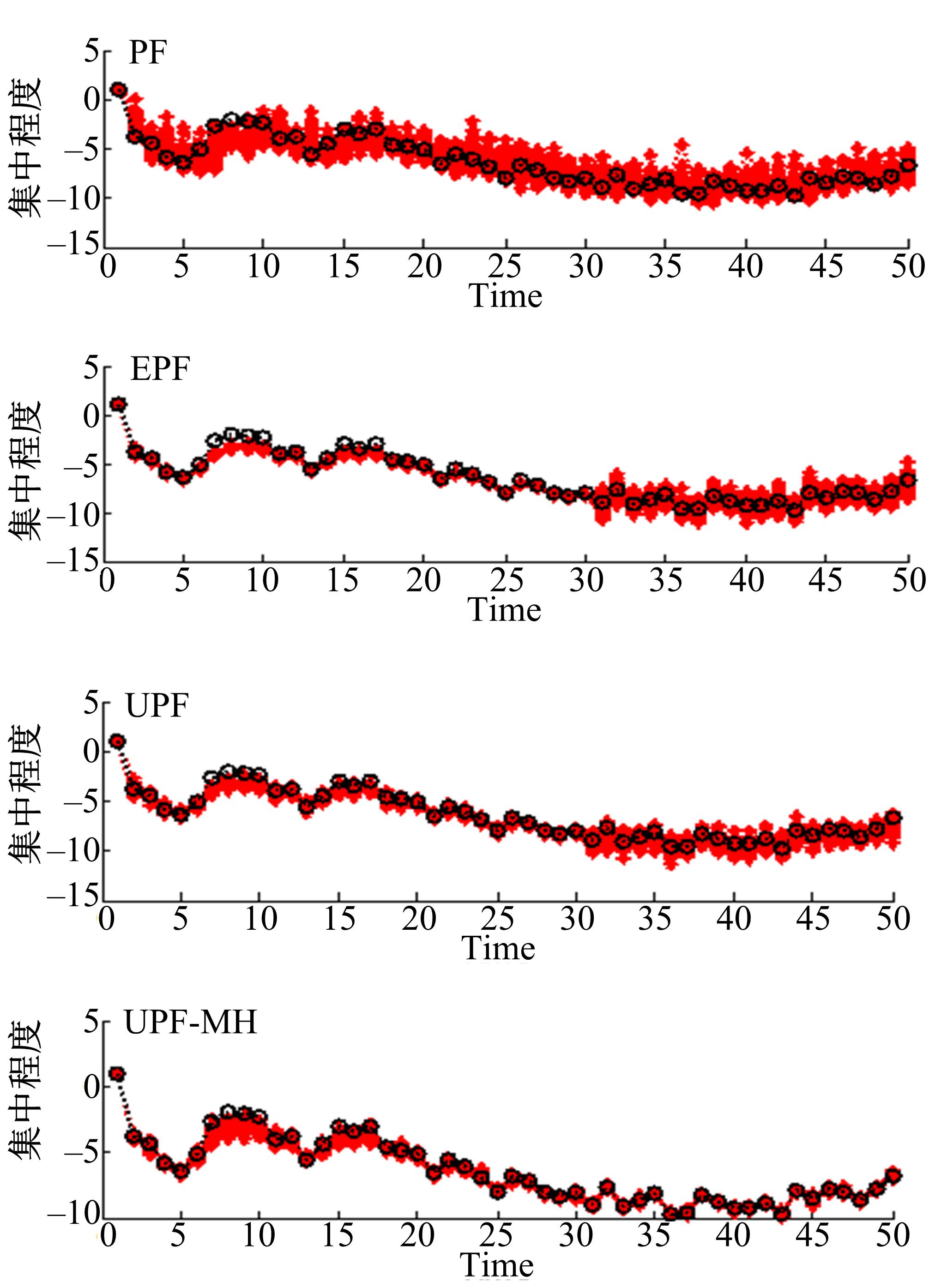 | 图4 系统2中的粒子集中程度对比Fig.4 Comparison of particle concentration in system2 |
从图3可以看出,在系统1中,PF算法有较多的粒子处于真实状态较远位置,也就是PF算法抽样粒子处在概率密度值非常小的区间,而EPF算法和UPF算法与PF算法相比,抽样粒子对真实后验概率分布接近程度有所改进。本文提出的UPF-MH算法相比PF、EPF、UPF算法抽样粒子更加集中在真实状态,也就是UPF-MH算法抽样粒子处在概率密度值非常大的区间。从图4可以看出,在系统2中,本文提出的UPF-MH算法相比PF、EPF、UPF算法抽样粒子更加集中在真实状态。可见,相比PF、EPF、UPF三种算法,UPF-MH算法降低了粒子退化现象。
综上,本文提出的UPF-MH算法抽样产生的粒子更能逼近真实状态的后验概率密度,提高了粒子的利用率,从而提高了估计精度。
提出了一种改进的UPF算法——UPF-MH,该算法通过基于高斯Sigma点选取的UKF算法产生建议分布函数,同时利用MH方法优化粒子。实验结果表明:UPF-MH算法比PF、EPF、UPF这三种算法估计精度更高,并有效降低了粒子退化现象。
本文通过构建建议分布函数来降低粒子退化现象。下一步工作将对重采样方法进行研究,通过改进重采样方法降低粒子退化现象,设计出一种有效的解决粒子退化现象的重采样算法,并与本文算法相结合应用到说话人跟踪领域。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|