{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Sigma点H ∞滤波的拟蒙特卡罗粒子滤波算法
[孔云波1  , 冯新喜
, 冯新喜1 , 鹿传国1 , 刘振涛2 ]
, 冯新喜|
|


作者简介:孔云波(1987-),男,博士研究生.研究方向:多传感器信息融合.E-mail:kongyunbo123@163.com
在滤波算法中,用Sigma点
A new filtering algorithm is proposed. In this algorithm, the probability density function is generated by the sigma point
粒子滤波是一种基于贝叶斯估计的非线性滤波算法,目前已被广泛应用于实现非线性、非高斯环境下的参数估计和状态估计。粒子滤波借助于一个容易采样的重要性密度函数得到满足后验概率分布的样本粒子,重要性密度函数选择的优劣直接决定了粒子滤波的性能。文献[1]最早提出了使用先验转移密度作为提议分布的Bootstrap粒子滤波算法。该算法简单、易于实现,但由于没有考虑最新的观测信息常导致粒子集偏离真实的后验概率。文献[2]提出了利用扩展卡尔曼滤波(Extended kalman filter,EKF)来产生重要密度函数。文献[3]提出了用无味卡尔曼滤波(Unscented kalman filter,UKF)来产生重要性函数,使滤波器的性能又进一步提高。文献[4]提出了一种基于扩展 H∞粒子滤波算法,该算法利用扩展 H∞滤波(Extended H∞ filter,EHF)产生重要性函数,使得在进一步提高滤波器性能的同时降低了算法的复杂度。此外,常用的建议分布有转移先验建议分布、混合建议分布、退火先验建议分布、似然函数建议分布、基于梯度的转移密度概率建议分布等[ 5]。这些方法在一定程度上避免了粒子退化现象,提高了粒子滤波算法的估计精度。
上述基于重要性采样的粒子滤波都存在一个主要问题是粒子退化现象。抑制退化现象的最主要方法是增加粒子数和重采样。重采样的目的是去掉权值较小的粒子数目,保留权值大的粒子。但经过重采样,权值大的粒子被多次复制,丧失了粒子的多样性。对此,文献[6]提出了在重采样后增加马尔科夫蒙特卡罗移动步骤的方法,该方法可以减弱粒子间的相关性,抑制样本的贫化,但不能保证其收敛性。文献[7]提出了使用高斯分布近似状态后验概率密度的高斯粒子滤波。文献[8]提出了一种结合准蒙特卡罗方法的粒子滤波算法,在重要性采样后,将生成的随机化蒙特卡罗序列分别映射到以权值大的粒子为核心的独立空间上,避免了直接对采样空间进行预测,同时又保证了样本的多样性。
本文提出了一种新的基于Sigma点 H∞滤波的拟蒙特卡罗粒子滤波算法,在重要性采样阶段,利用Sigma点 H∞滤波来产生重要性密度函数,然后利用拟蒙特卡罗重采样算法进行重采样。仿真试验表明,该算法在提高估计精度的同时,可以有效地抑制样本枯竭现象。
H∞滤波方法是将鲁棒控制中的 H∞范数应用于滤波,以解决系统噪声的统计特性不确定问题。该方法采用极大极小准则,无需知道噪声的统计特性等先验信息,在最大噪声作用下寻求干扰引起的误差范数最小。因此,该方法具有较强的鲁棒性。
考虑离散的线性系统:
式中: Xk为系统的状态向量; Fk为状态转移矩阵, Bk为系统噪声矩阵; Hk为量测矩阵; Wk和 Vk为互不相关的白噪声,其方差为 Qk和 Rk。
若系统过程噪声和测量噪声 Wk和 Vk满足
则 H∞滤波问题使系统的输出 Xk在各种可能的条件下满足:
式中:
由于最优 H∞滤波器在一般情况下难以求得解析形式的解。因此,最优 H∞滤波问题实质是一种次优滤波算法,设定一门限,使得代价函数满足:
在式(5)所示的约束条件下,可得 H∞滤波方程,即:
从递推表达式可以看出, H∞滤波器的滤波性能与 γ的取值具有较大的关系,当 γ取最小值时, H∞滤波器具有最好的鲁棒性,但此时方差估计不一定达到最小;而当 γ→ ¥时,方差估计达到最小,但滤波器的鲁棒性较差。所以, H∞滤波器可以理解为二范数和无穷范数间的折中,通过选取适当的 γ,可以同时具有鲁棒性和估计方差最小的特性。
类似于UKF滤波器,文献[9]将 H∞滤波应用到非线性估计领域,提出了Sigma点 H∞滤波方法。Sigma点转换根据加权统计线性回归(WSLR)的思想,通过真正的非线性函数,计算随机变量经过非线性变换后的均值和方差。由于加权统计线性回归考虑了随机变量的先验统计特性,因此能获得比截断泰勒级数更小的线性化误差。
设 n维随机向量 x,其统计特性为(
为了将Sigma点转换方法应用于 H∞滤波器,采用式(7)进行状态估计协方差阵递推[ 9]:
将Sigma点转换方法应用于 H∞滤波器,就可以得到基于Sigma点的 H∞非线性滤波方法。
拟蒙特卡罗[ 10](Quasi-Montor Carlo,QMC)的主要思想是用更加规则分布的确定性超均匀分布序列来构造蒙特卡罗(Montor Carlo,MC)方法中用随机序列所形成的近似。这种确定性方法可以选择采样空间最优的可能性分布点,避免发生在MC随机采样过程中粒子之间的间隙过大、粒子层叠等现象,提高了采样效率。为克服粒子退化问题,本文采用拟蒙特卡罗重采样(Quasi-Montor Carlo resample,QMCR)算法,具体参见文献[8]。
利用Sigma点 H∞滤波产生重要性函数,利用拟蒙特卡罗算法进行重采样,就得到了Sigma点 H∞拟蒙特卡罗粒子滤波算法(Quasi-Monte Carlo particle filter based on Sigma point H∞,SHQPF)。由于Sigma点 H∞滤波对不确定观测噪声具有较强的鲁棒性,而且在滤波过程中考虑了最新的观测值,所以根据该重要性函数产生的样本更接近于真实的采样样本。基于Sigma点 H∞拟蒙特卡罗粒子滤波算法的步骤如下:
步骤1 初始化。
k=0,从先验分布中产生样本:
步骤2 重要性采样。
i=1,2,…, Ns,在每一时刻用Sigma点 H∞滤波器算法更新粒子。
采样粒子:
步骤3 计算各粒子权重。
步骤4 重采样。
计算 Neff,并判断 Neff <NT是否成立,其中 NT表示门限值。若成立,则调用QMCR算法进行重采样,得到新的粒子集合{
步骤5 状态估计。
为了验证本文算法的性能,分4个试验讨论算法在不同仿真条件下的参数变化情况和滤波性能。试验一讨论了参数 γ对算法滤波性能的影响;试验二将QMCR算法和残差重采样算法、多项式重采样算法、系统重采样算法、分层重采样算法进行比较;试验三对所提算法与扩展卡尔曼粒子滤波(Extended kalman particle filter,EKPF)算法、无迹卡尔曼粒子滤波(Unscented particle filter,UPF)算法的估计误差、收敛情况和跟踪稳定性等性能进行比较;试验四对所提算法的有界收敛界进行了讨论。
过程模型:
量测模型:
式中: w( t) ~Γ(3,2); v( t) ~N(0,1)。
初始状态 x( t) =1,仿真时长 T=50,粒子数为300。分别计算算法在参数 γ取不同值时估计值与真值之间的均方根误差( RMSE),仿真次数为100次。
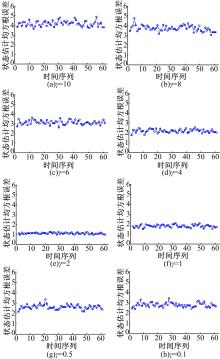
由1.1节理论分析可知,在本文算法中,参数 γ的取值对滤波性能影响较大。随着 γ的逐渐增大, H∞滤波器的状态估计会逼近最优估计值,但此时的鲁棒性变差。随着 γ的逐渐减小, H∞滤波器鲁棒性逐渐增加,但状态估计误差逐渐增大。一般情况下,通过使给定 γ的不断减小,使其逐步逼近Sigma点 H∞拟蒙特卡罗粒子滤波估计问题对应的 γ0时,就可以得到Sigma点 H∞拟蒙特卡罗粒子滤波的最优估计,其中前提条件是 γ>γ0,否则Sigma点 H∞拟蒙特卡罗粒子滤波将会无解。 图1给出了100次蒙特卡罗仿真下,算法滤波误差随参数 γ的变化情况。从 图1中可以看出,当参数 γ值从10逐渐减小到2时,算法滤波的均方根误差逐渐减小,当参数的值从2减小到0.1时,均方根误差逐渐增大,因此,可以推断最优解大概在 γ=2 .0附近。
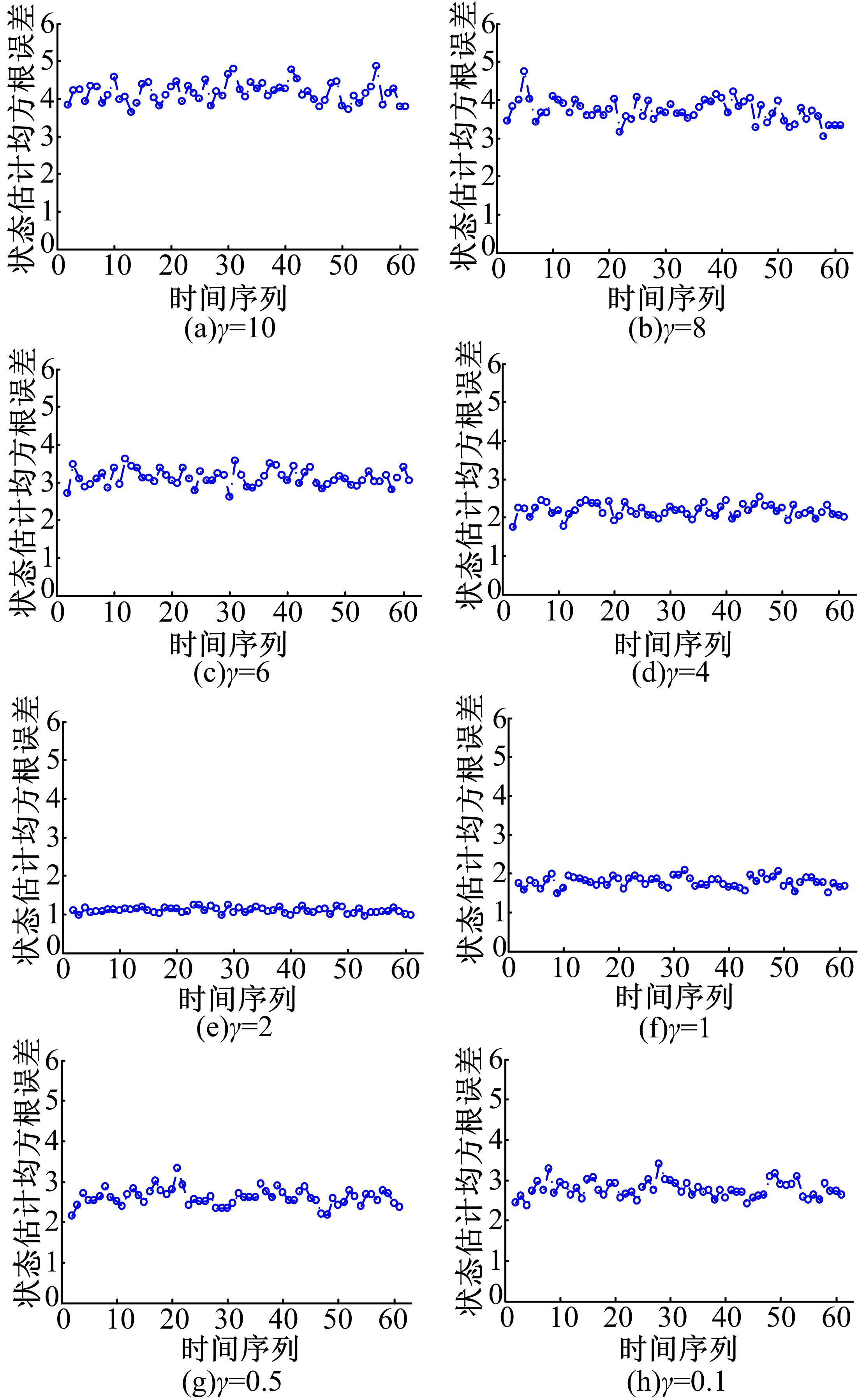 | 图1 SHQPF算法在 γ取不同值时均方根误差曲线图Fig.1 RMSE of SHQPF in the different γ |
选取具有典型的非线性特征的单变量非静态增长模型(UNGM),其过程模型和量测模型如下:
过程模型:
量测模型:
式中: w( t)和 v( t)为零均值高斯噪声。
该系统的特征是高度非线性,似然函数呈双峰。
重要性重采样的目的是去掉权值较小的粒子数目,保留权值大的粒子。重要性重采样不依赖于系统模型和具体的应用,仅与重采样算法本身有关[ 11]。本试验将拟蒙特卡罗重采样算法与系统重采样算法、残差重采样算法、多项式重采样算法和分层重采样算法进行比较,重点研究了在采样粒子取不同值时,5种重采样算法的优劣。
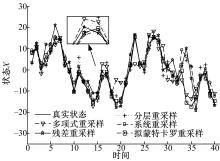
图2给出了5种算法的状态估计曲线。由 图2可以看出,采用5种重采样算法得到的均方根数据较为接近,为了更清楚地显示他们的差别,采用文献[11]的方法,对均方根数据作如下标准化处理:
式中: i=1,…, M; j=1,…, N; M、 N分别表示行数和列数;
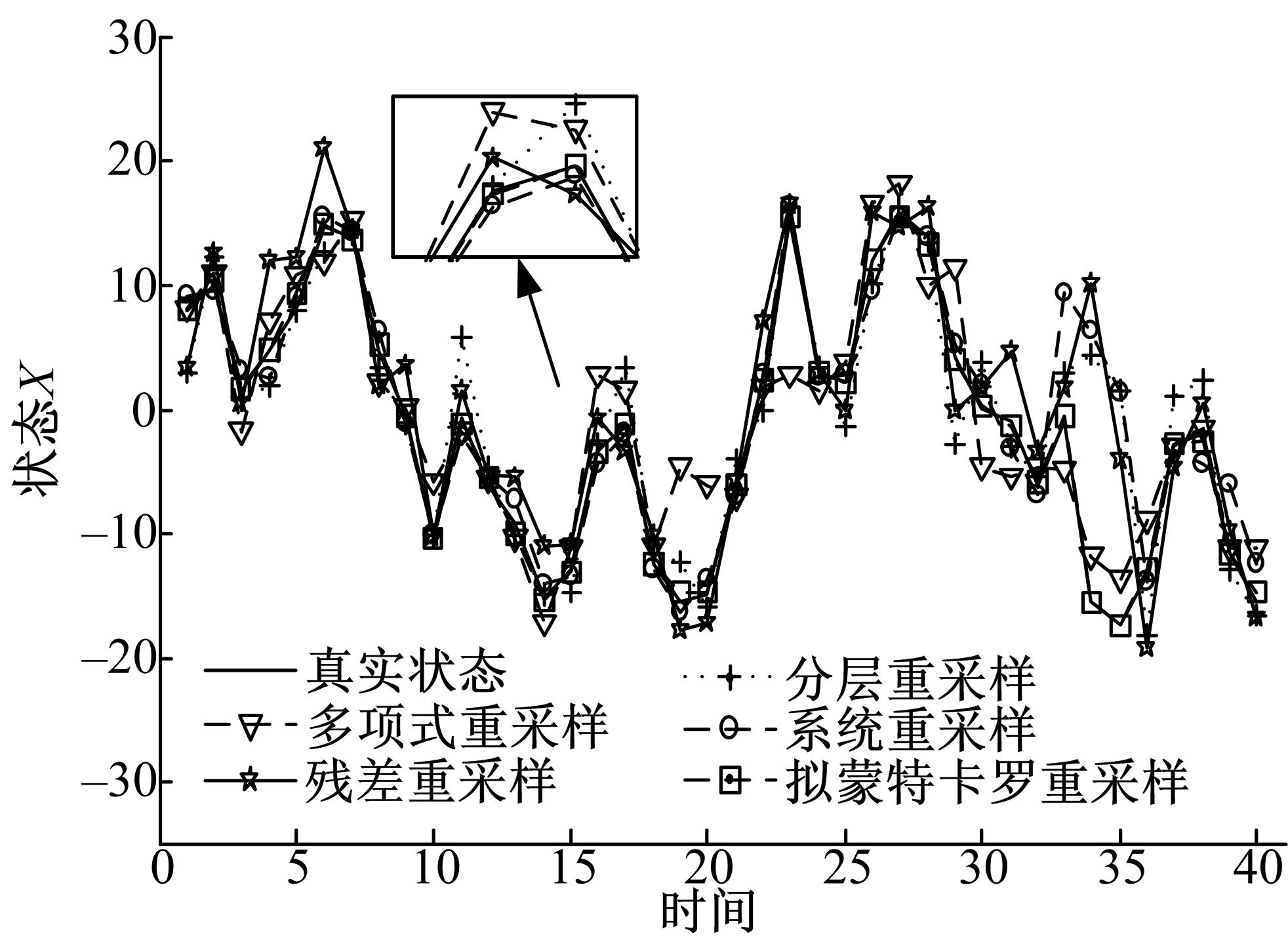 | 图2 状态估计曲线Fig.2 Line of state estimation |
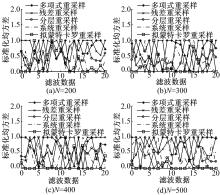
图3和 表1给出了采样粒子数分别取200、300、400、500时的标准化均方根误差图和平均有效样本数。从 图3可以看出,多项式重采样算法在粒子数 N为200、300、400和500时出现峰值较多,效果极差;残差重采样算法在粒子数 N为200和300时峰值较多,在 N为400和500时存在峰值,但已明显减少,因此,残差重采样算法综合表现一般;分层重采样算法在粒子数 N为200、300、400和500时只出现少数峰值,结果较好,优于残差重采样;系统重采样与分层重采样效果较为相似,但整体优于分层重采样;拟蒙特卡罗重采样算法随着采样粒子数的增多,峰值数逐渐减少,在粒子数 N为400时峰值为1个,在 N为500时峰值为0个。另外,从 图3中可以看出,拟蒙特卡罗算法的平均值远小于其他4种重采样算法,从整体上看,拟蒙特卡罗重采样算法得到的结果是最优的。
在粒子滤波方法中,有效采样粒子数(Effective sampling size,ESS)是衡量粒子退化程度的一种参数。 表1给出了5种算法在不同粒子数下的平均有效样本数。从 表1可以看出,随着粒子数 N的增加,各重采样算法的平均有效样本数逐渐增加,但当粒子数相同时,拟蒙特卡罗算法平均有效样本数大于其他4种算法。有效样本数越少,说明粒子退化现象越严重。由此可见,与残差重采样算法、多项式重采样算法、系统重采样算法、分层重采样算法相比,拟蒙特卡罗重采样算法更能抑制粒子退化现象。
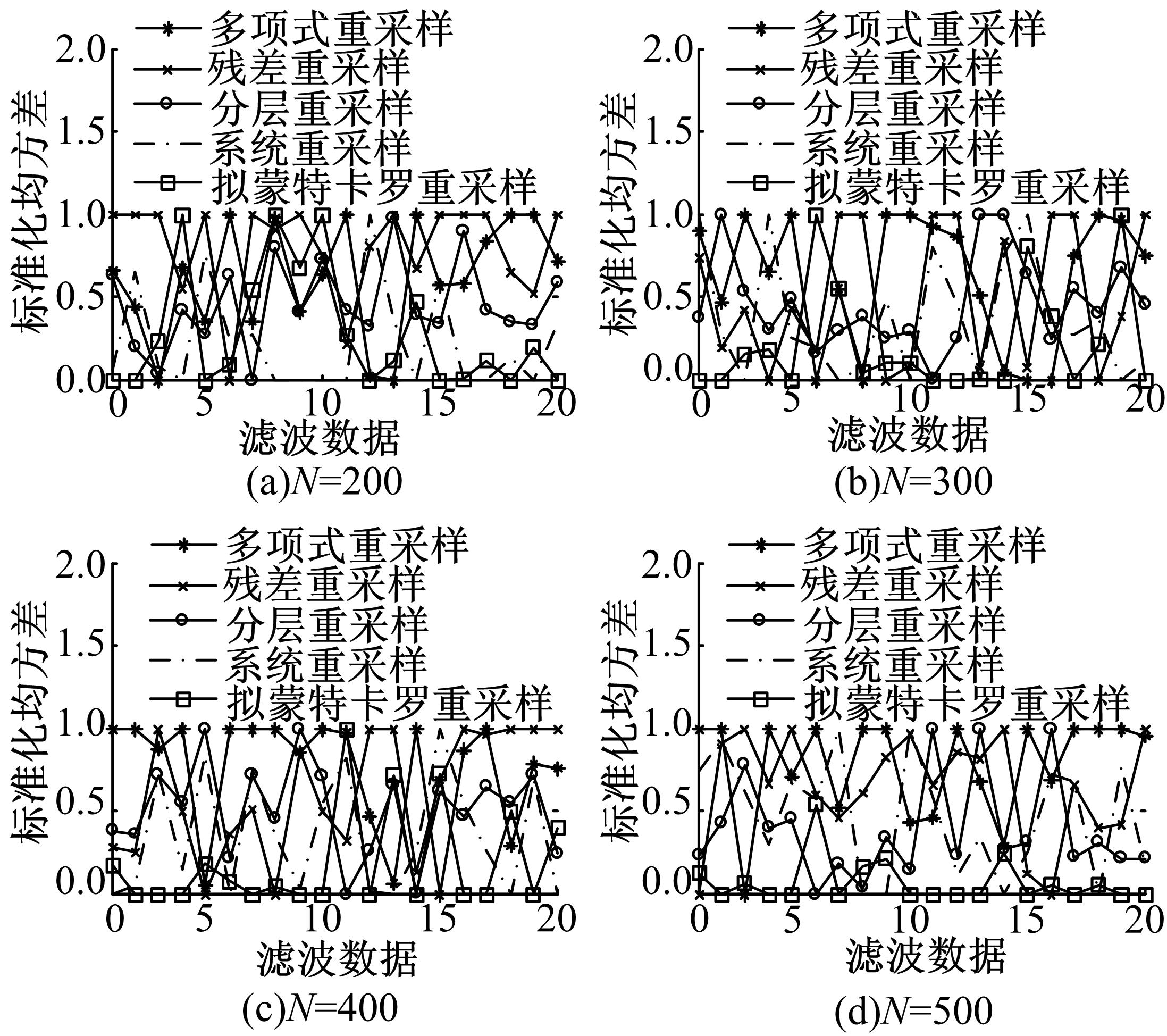 | 图3 标准化均方根误差曲线Fig.3 Line of standard REMS |
| 表1 平均有效样本数 Table 1 Mean number of effective sample |
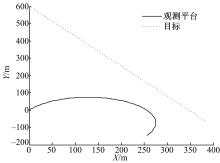
纯方位跟踪模型(Bearing-only tracking,BOT)是一种具有强非线性的目标跟踪模型。本试验考虑二维平面上的一个点目标的运动情况,假设传感器仅能获得目标的方位信息。传感器的扫描周期 T=1 s,方位角标准差为0.03 rad,跟踪时间为300 s。目标做匀速直线运动,其初始位置为(0 m,600 m),速度为2.57 m/s,航向为5π/6;为了保证系统的可观测性,传感器必须满足一定的机动条件。设置传感器系统初始位置为(0 m,0 m),初始速度为1.542 m/s,初始航向为π/6,在1~300 s做匀速转弯运动,角加速度为1/300π rad/s2。目标与传感器的运动轨迹如 图4所示。
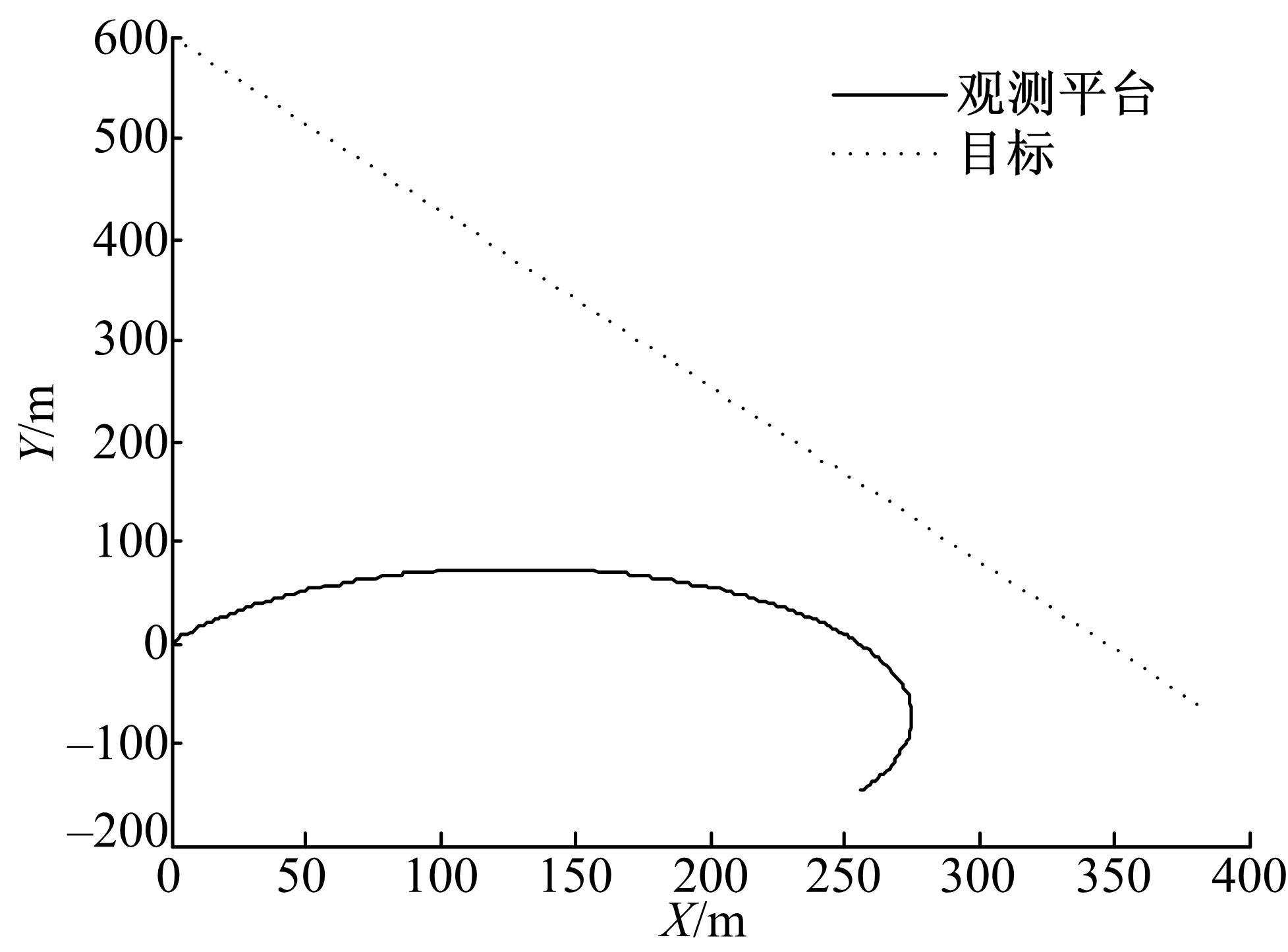 | 图4 目标和传感器的运动轨迹Fig.4 Trace of target and sensor |
表2给出了各滤波算法的滤波精度和滤波时间随采样粒子数的变化情况。从 表2可以看出,所有滤波方法的估计误差都会随着粒子数目的增加而逐渐减少。当粒子数相同时,EKPF、UPF、SHQPF的滤波误差明显减小,但运算所需时间依次增加,即精度的提高是以牺牲运算时间为代价的。与EKPF和UPF相比,SHQPF均方根误差明显较低,说明SHQPF明显提高了目标跟踪的精度,且运行时间与UPF相当。同时在100次仿真试验中,UPF和SHQPF具有较好的收敛性,没有出现跟踪发散现象,而EKPF出现了7次跟踪发散现象。
| 表2 各算法跟踪性能比较 Table 2 Estimation performance comparison of all kinds filter |
在粒子滤波算法中,由于各粒子间的交互作用使得统计独立的假设不再成立,所以粒子滤波算法收敛性的分析非常复杂。文献[12]在大量工程实践的基础上提出了粒子滤波算法的有限收敛界(Limited convergence bound,LCB)的概念。因此本文使用有限收敛界进一步分析算法的收敛问题。
选取试验二给出的单变量非静态增长模型(UNGM),该系统是一个复杂的非线性递推Bayesian滤波问题,其特征是高度非线性和其最优解不存在。采用SHQPF对非线性系统进行状态估计,并求出该算法的有限收敛界 NLCB。该试验以粒子数50为起点,粒子增量为50,波动误差为0.01,蒙特卡洛仿真次数为100。使用均方根误差( RMSE)的时间平均作为衡量SHQPF估计误差的指标,令 NT为用于时间平均的样点数;
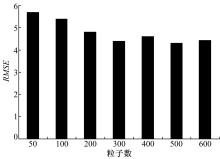
依据有限收敛界的定义可以计算得 NLCB=200,即所提算法有界收敛。另外,从 图5可以看出,随着粒子数的增大,平均 RMSE值逐渐降低,当粒子数小于200时,平均 RMSE值降低明显,粒子数的增加使得滤波精度明显提高,超过200后,滤波精度增加趋于平缓,说明SHQPF随着粒子数的增大而逐渐收敛,但这种变化趋势并非是均匀的。在实际情况中,当粒子数超过某个门限后,在粒子数增加有限的情况下,对滤波估计性能的影响已经很弱,这与一般粒子滤波是一致的。
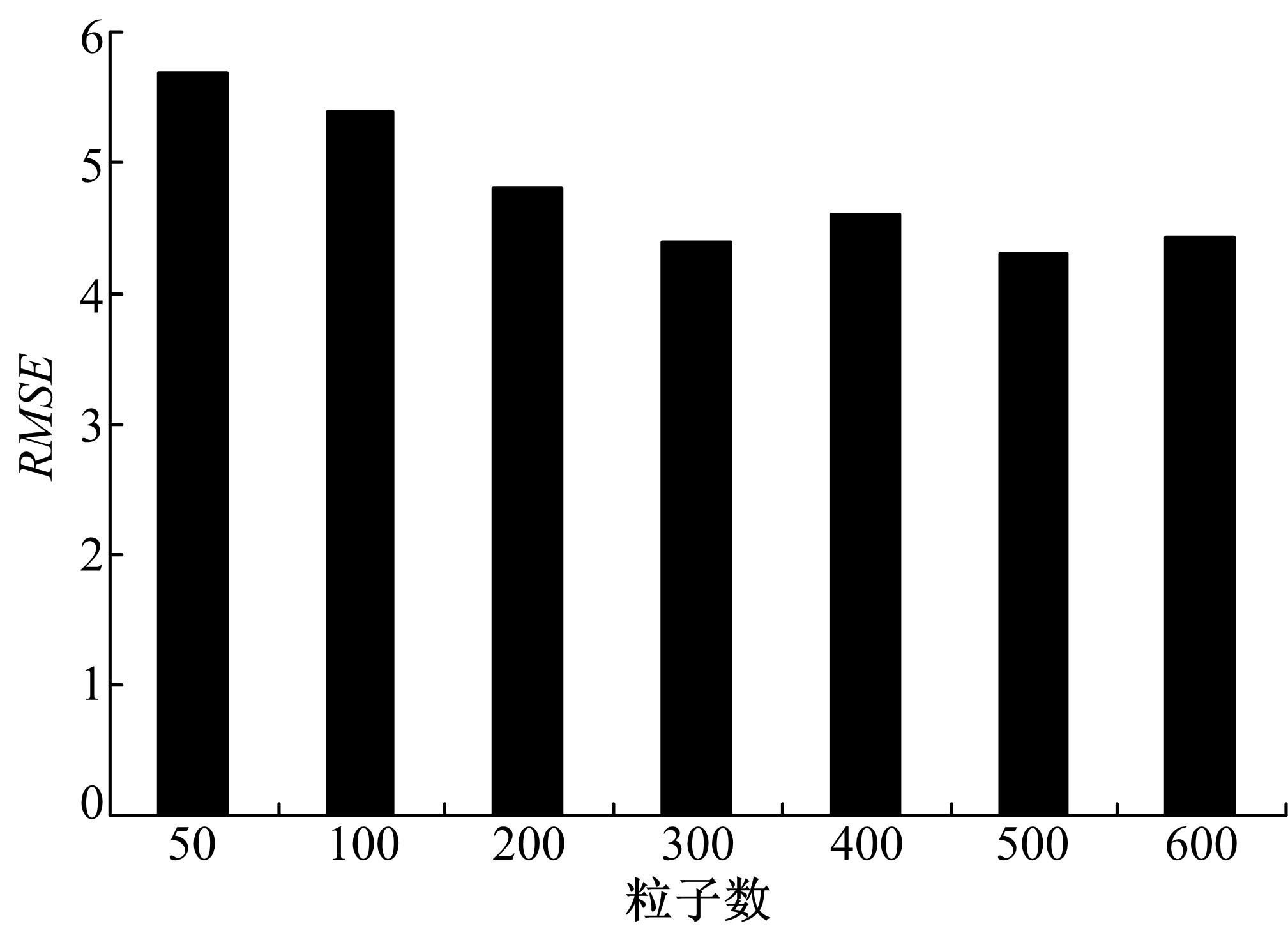 | 图5 平均 RMSE值和粒子数Fig.5 Mean RMSE and particle number |
提出了一种新的基于Sigma点 H∞滤波的拟蒙特卡罗粒子滤波算法。算法利用Sigma点 H∞滤波产生重要性密度函数,由于Sigma点 H∞滤波对不确定观测噪声具有较强的鲁棒性,而且在滤波过程中考虑了最新的观测值,因此由其产生的重要性函数更逼近于真实的后验概率分布。同时,该算法无需知道噪声的统计特性等先验信息,摆脱了应用环境的束缚。另外,在重采样阶段引入拟蒙特卡罗重采样又克服了传统粒子滤波算法粒子退化现象,提高了滤波器的估计能力。仿真结果表明,本文算法是有效且可行的。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|