Journal of Jilin University(Engineering and Technology Edition) ›› 2023, Vol. 53 ›› Issue (3): 863-870.doi: 10.13229/j.cnki.jdxbgxb20221282
Rapid trajectory programming for hypersonic umanned areial vehicle in ascent phase based on proximal policy optimization
Zhi-yong SHE( ),Tong-ming ZHU,Wang-kui LIU
),Tong-ming ZHU,Wang-kui LIU
- Beijing Institute of Aerospace Technology,The Third Academy of China CASIC,Beijing 100074,China
CLC Number:
- V19
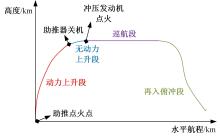
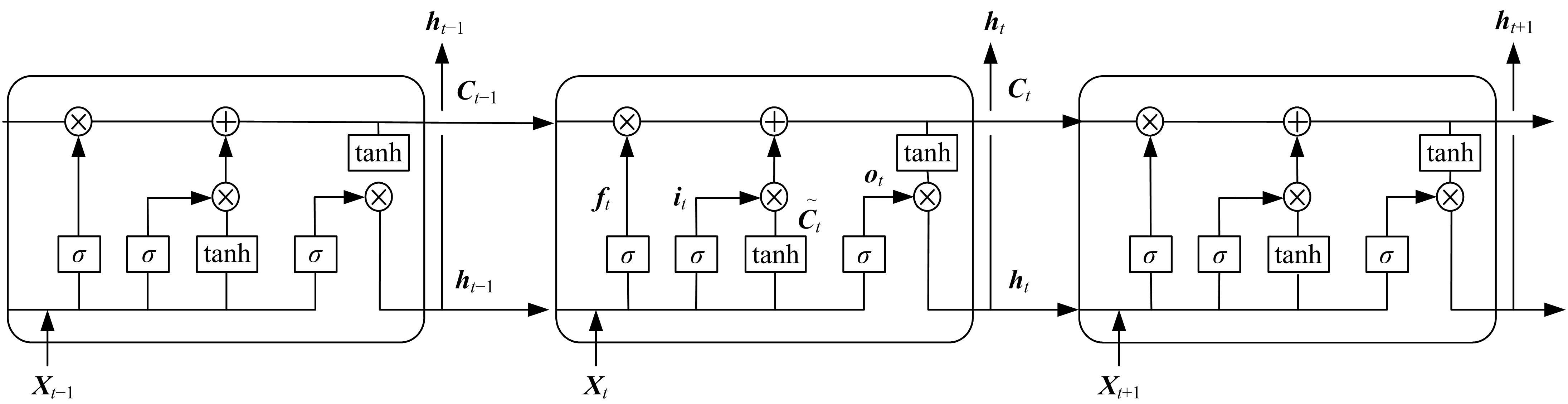
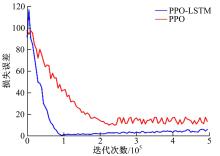
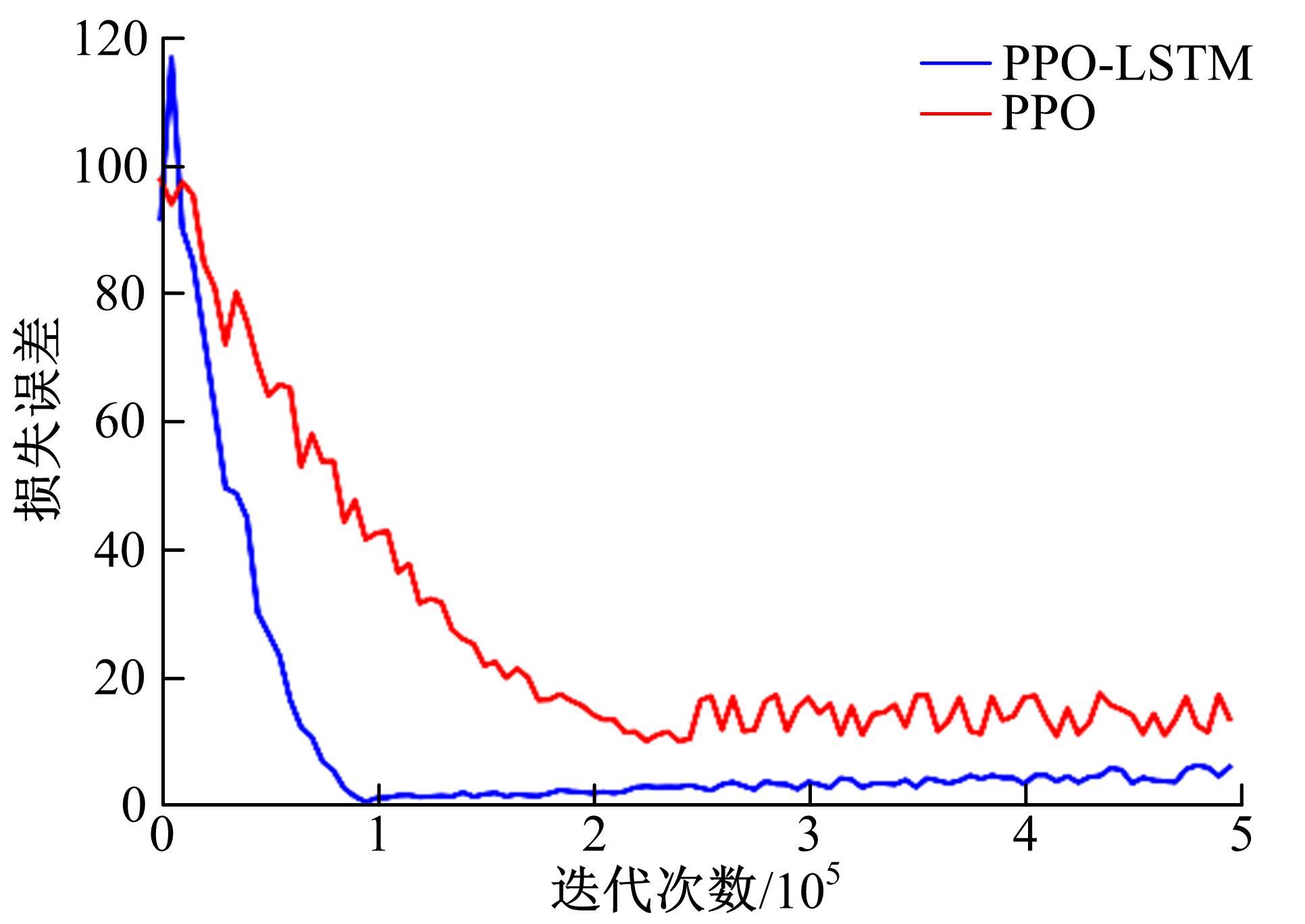
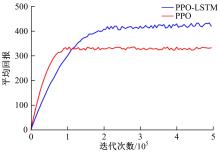
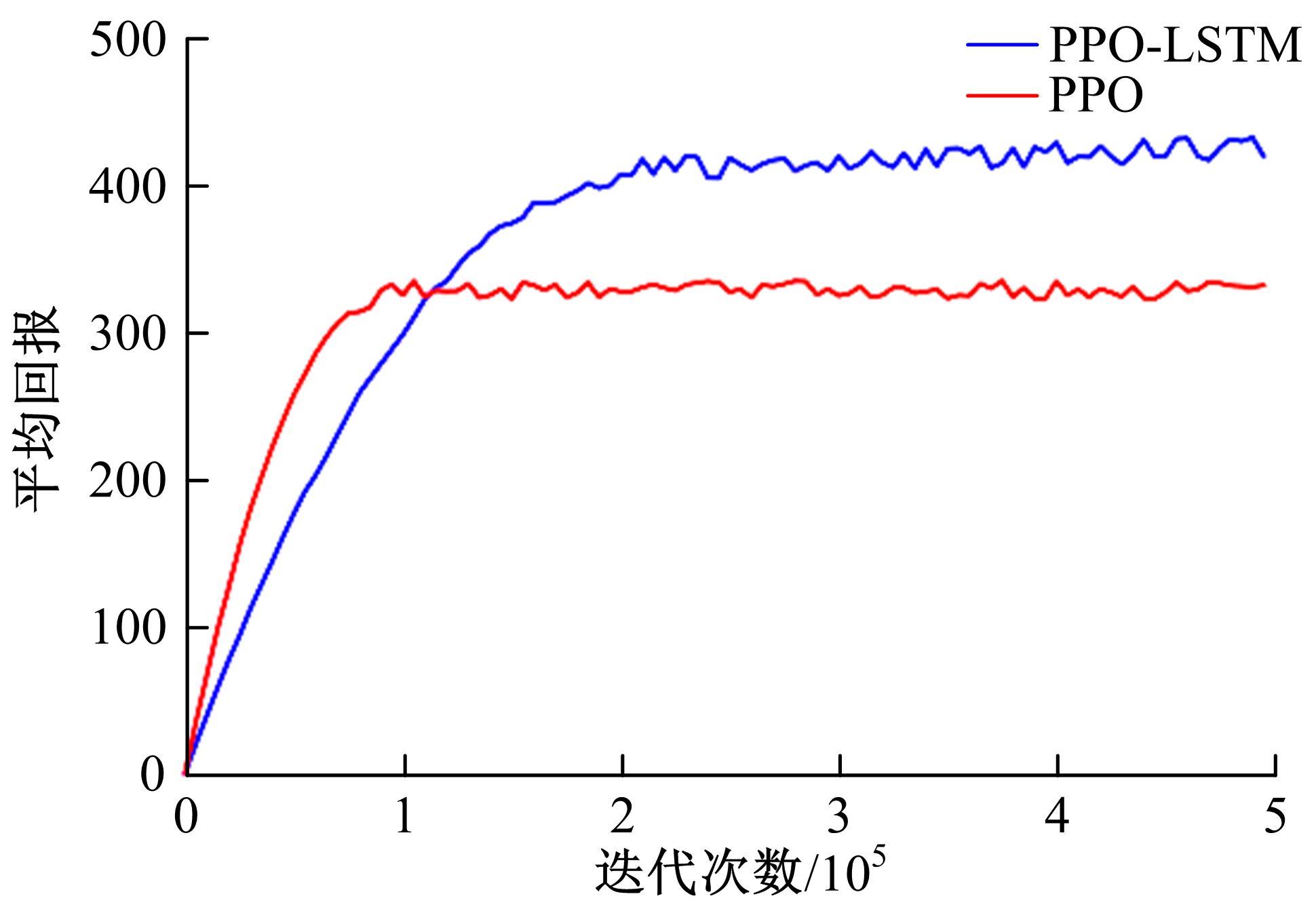
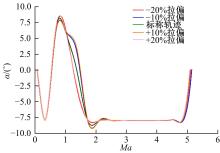
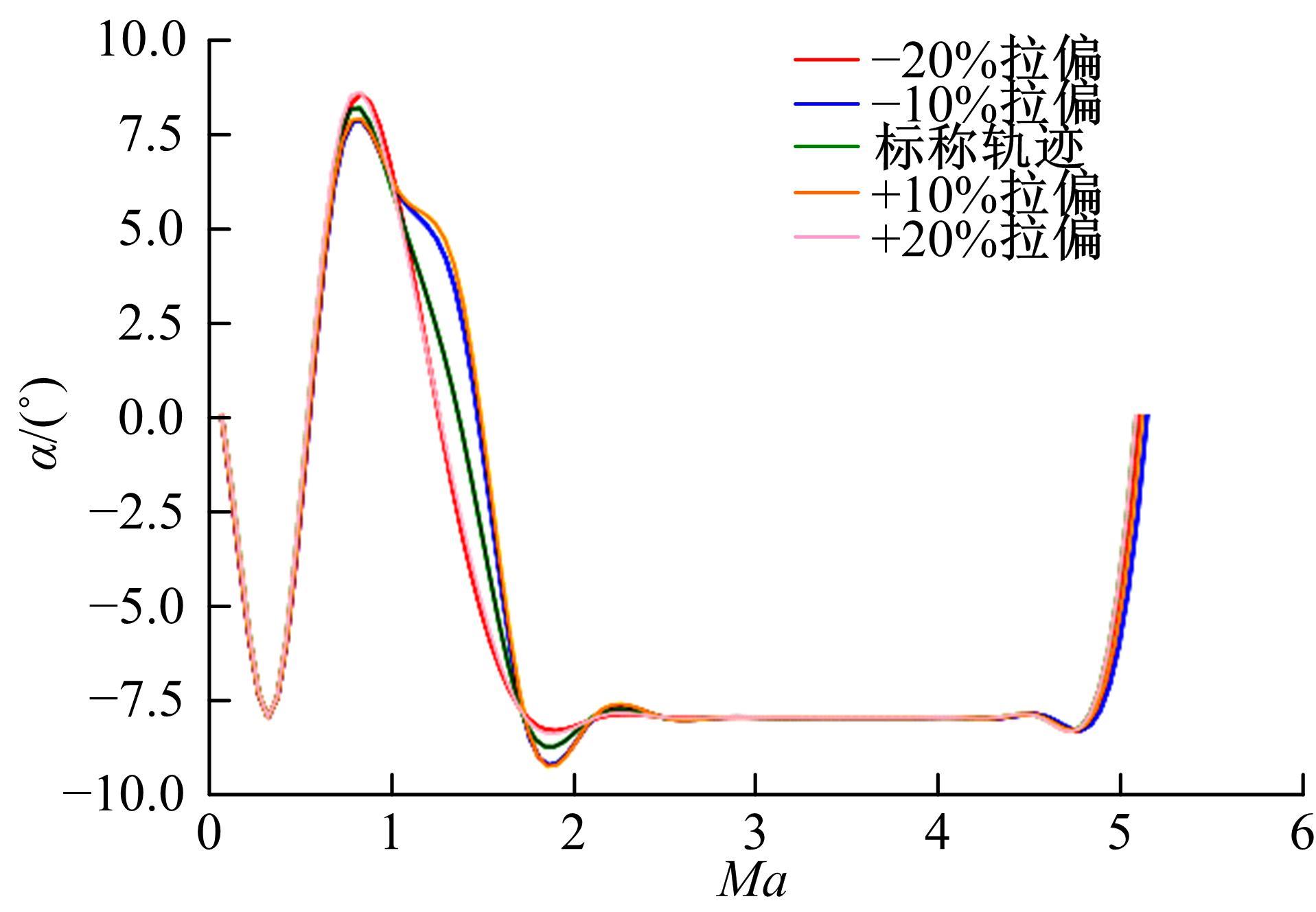
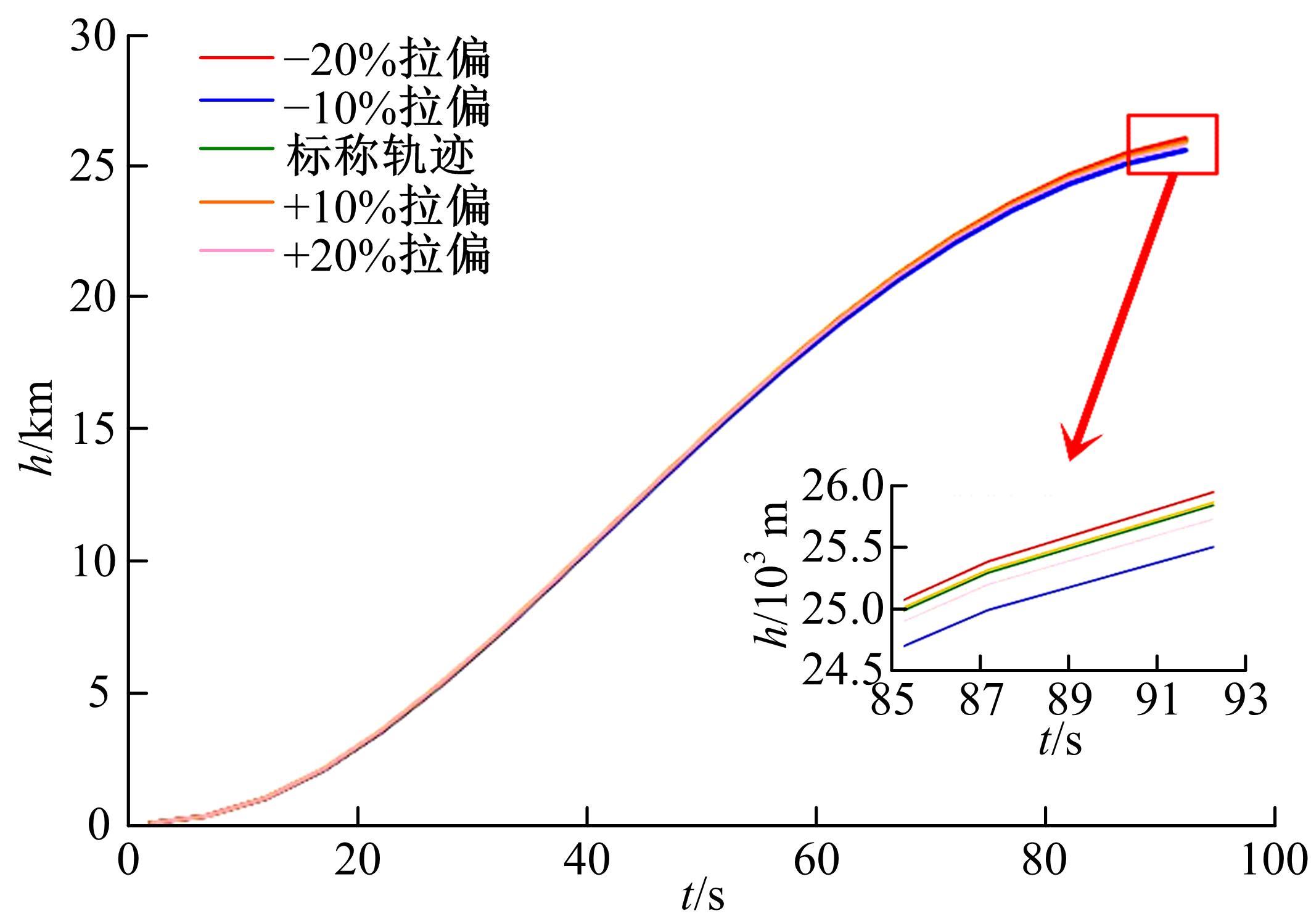
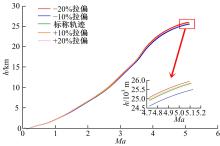
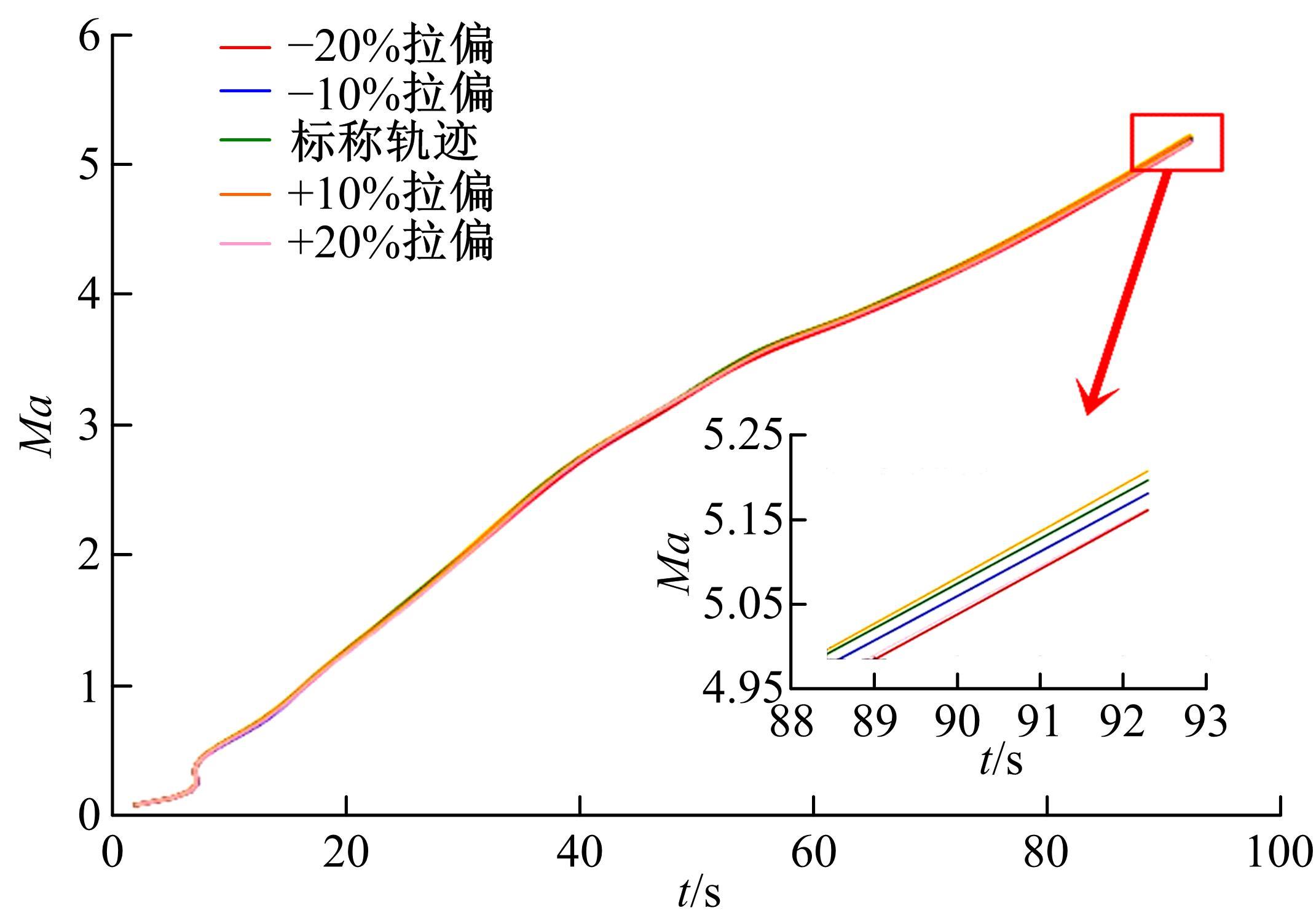
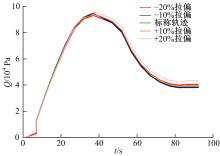
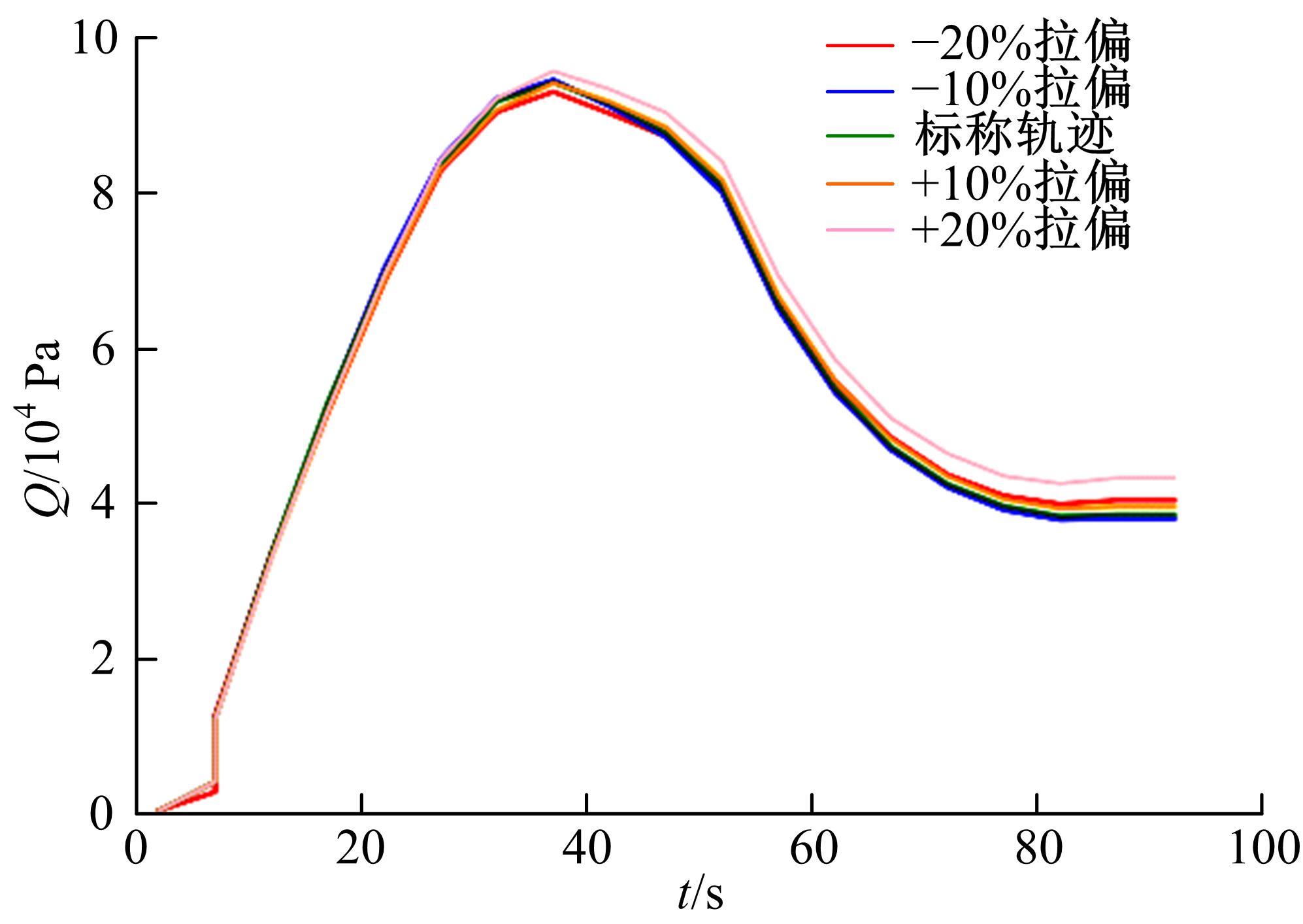
| 1 | 张国成, 姚彦龙, 王慧. 美国两级入轨水平起降可重复使用空天运载器发展综述[J].飞机设计, 2018, 38(2): 1-6. |
| Zhang Guo-cheng, Yao Yan-long, Wang Hui. A survey on development of two-stage-to-orbit horizontal take-off horizontal landing reusable launch vehicle in USA[J]. Aircraft Design, 2018, 38(2): 1-6. | |
| 2 | 谭永华, 李平, 杜飞平. 重复使用天地往返运输系统动力技术发展研究[J]. 载人航天, 2019, 25(1): 1-11. |
| Tan Yong-hua, Li Ping, Du Fei-ping. Research on development of propulsion technology for reusable space transportation system[J]. Manned Spaceflight, 2019, 25(1): 1-11. | |
| 3 | Shahriar K, Maj D M. Six-DOF modeling and simulation of a generic hypersonic vehicle for conceptual design studies[C]∥AIAA Paper, 2004-4805. |
| 4 | Randall T, Lawrence D, Charles R. X-43A hypersonic vehicle technology development[J]. Acta Astronautic, 2006, 59(1-5): 181-191. |
| 5 | Keshmiri S, Colgren R, Mirmirani D. Six-DOF modeling and simulation of a generic hypersonic for control and navigation purposes[C]∥AIAA Paper, 2006-6694. |
| 6 | 宗群, 田栢苓, 窦立谦, 等. 基于Gauss伪谱法的临近空间飞行器上升段轨迹优化[J]. 宇航学报,2010, 31(7) : 1775-1781. |
| Zong Qun, Tian Bai-ling, Dou Li-qian, et al. Ascent phase trajectory optimization for near space vehicle based on Gauss pseudospectral method[J]. Journal of Astronautics, 2010, 31(7): 1775-1781. | |
| 7 | Pan B F, Lu P. Improvements to optimal launch ascent guidance[C]∥AIAA Paper, 2010-8174. |
| 8 | Fabrizio P, Edmondo M, Christie M,et al. Ascent trajectory optimization for a single-stage-to-orbit vehicle with hybrid propulsion[C]∥AIAA Paper: 2012-5828. |
| 9 | 李惠峰, 李昭莹. 高超声速飞行器上升段最优制导间接法研究[J]. 宇航学报, 2011, 32(2): 297-309. |
| Li Hui-feng, Li Zhao-ying. Indirect method of optimal ascent guidance for hypersonic vehicle[J]. Journal of Astronautics, 2011, 32(2): 297-309. | |
| 10 | 万里鹏, 兰旭光, 张翰博, 等. 深度强化学习理论及其应用综述[J]. 模式识别与人工智能, 2019,32(1): 73-87. |
| Wan Li-peng, Lan Xu-guang, Zhang Han-bo, et al. A review of deep reinforcement learning theory and application[J]. Pattern Recognition and Artificial Intelligence, 2019, 32(1): 73-87. | |
| 11 | Gaudet B, Furfaro R. Missile homing-phase guidance law design using reinforcement learning[J/OL]. [2022-09-18]. |
| 12 | Yu X, Lv Z, Wu Y H, et al. Neural network modeling and backstepping control for quadrotor[J/OL]. [2022-09-18]. |
| 13 | 周宏宇, 王小刚, 赵亚丽, 等. 组合动力运载器上升段轨迹智能优化方法[J]. 宇航学报, 2020, 41(1):61-70. |
| Zhou Hong-yu, Wang Xiao-gang, Zhao Ya-li, et al. Ascent trajectory optimization for a multi-combined-cycle-based launch vehicle using a hybrid heuristic algorithm[J]. Journal of Astronautics, 2020, 41(1): 61-70. | |
| 14 | 刘扬, 何泽众, 王春宇. 基于DDPG算法的末制导律设计研究[J]. 计算机学报,2021, 44(9): 54-65. |
| Liu Yang, He Ze-zhong, Wang Chun-yu. Terminal guidance law design based on DDPG algorithm[J]. Chinese Journal of Computers, 2021, 44(9): 54-65. | |
| 15 | Liang C, Wang W, Liu Z,et al. Learning to guide:guidance law based on deep meta-learning and model predictive path integral control[J]. IEEE Access, 2019, 7: 47353-47365. |
| 16 | 张建强, 王振国, 李清廉. 空气深度预冷组合循环发动机吸气式模态建模及性能分析[J]. 国防科技大学学报, 2018, 40(1): 1-9. |
| Zhang Jian-qiang, Wang Zhen-guo, Li Qing-lian. Modeling and performance analysis of deeply precooled combined cycle engine in the air-breathing mode[J]. Journal of National University of Defense Technology, 2018, 40(1): 1-9. | |
| 17 | Sutton R S, Barto A G. Reinforcement Learning:an Introduction[M].2nd Edition.Cambridge: MIT Press, 2018. |
| 18 | Wu Yu-hu, Shen Tie-long. Policy iteration algorithm for optimal control of stochastic logical dynamical systems[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017(99): 1-6. |
| 19 | Gers F, Schmidhuber J, Cummins F. Learning to forget: continual prediction with LSTM[J]. Neural Computation, 2000, 12(10): 2451-2471. |
| 20 | Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J/OL]. [2022-09-22]. |
| 21 | Dossa R, Huang S Y, Ontanon S, et al. An empirical investigation of early stopping optimizations in proximal policy optimization[J/OL]. [2022-09-22]. |
| [1] | Yi YANG,Si⁃cai WANG,Ying NAN. Optimal algorithm of searching route for large amphibious aircraft [J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(3): 963-971. |
|
||