吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (8): 2753-2760.doi: 10.13229/j.cnki.jdxbgxb.20250273
• 计算机科学与技术 • 上一篇
基于改进PositionRank算法的高校教师自我评价关键词提取方法
齐晓亮1( ),陈海鹏2,石泽男2(),王守佳1
),陈海鹏2,石泽男2(),王守佳1
- 1.吉林大学 人力资源处,长春 130012
2.吉林大学 计算机科学与技术学院,长春 130012
Keyword extraction method for university faculty self-evaluations based on the improved PositionRank algorithm
Xiao-liang QI1(),Hai-peng CHEN2,Ze-nan SHI2(),Shou-jia WANG1
- 1.Human Resources Department,Jinlin University,Changchun 130012,China
2.College of Computer Science and Technology,Jilin University,Changchun 130012,China
摘要:
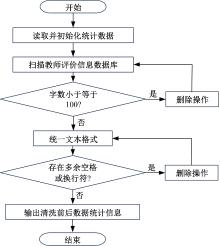
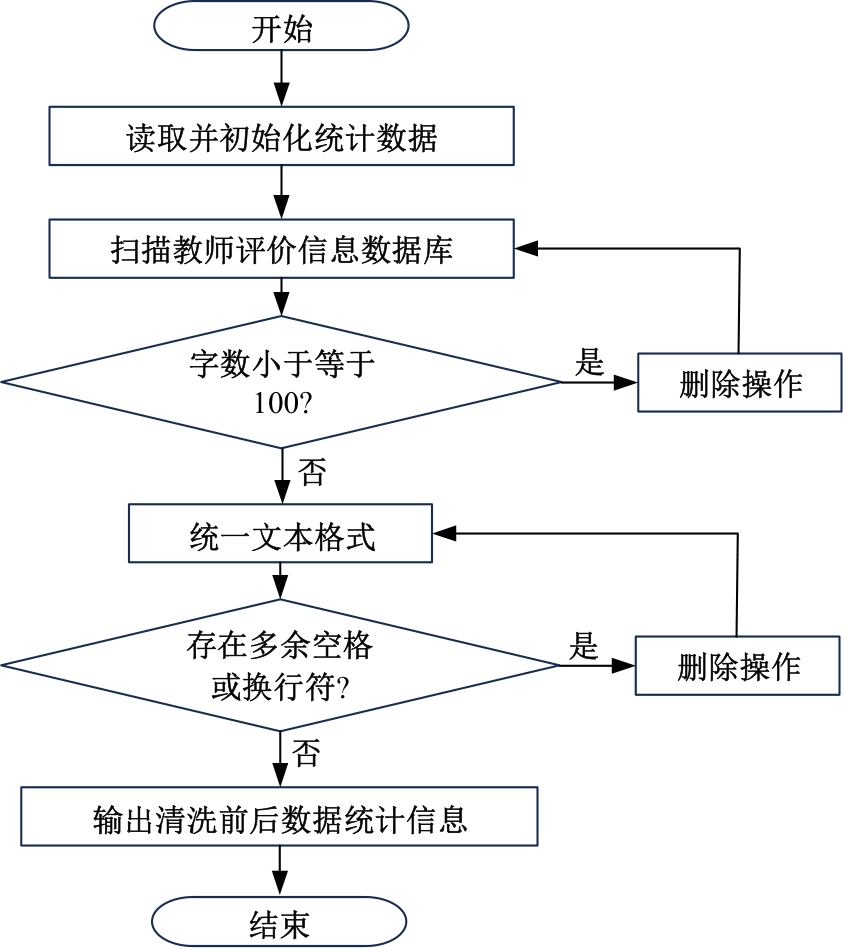
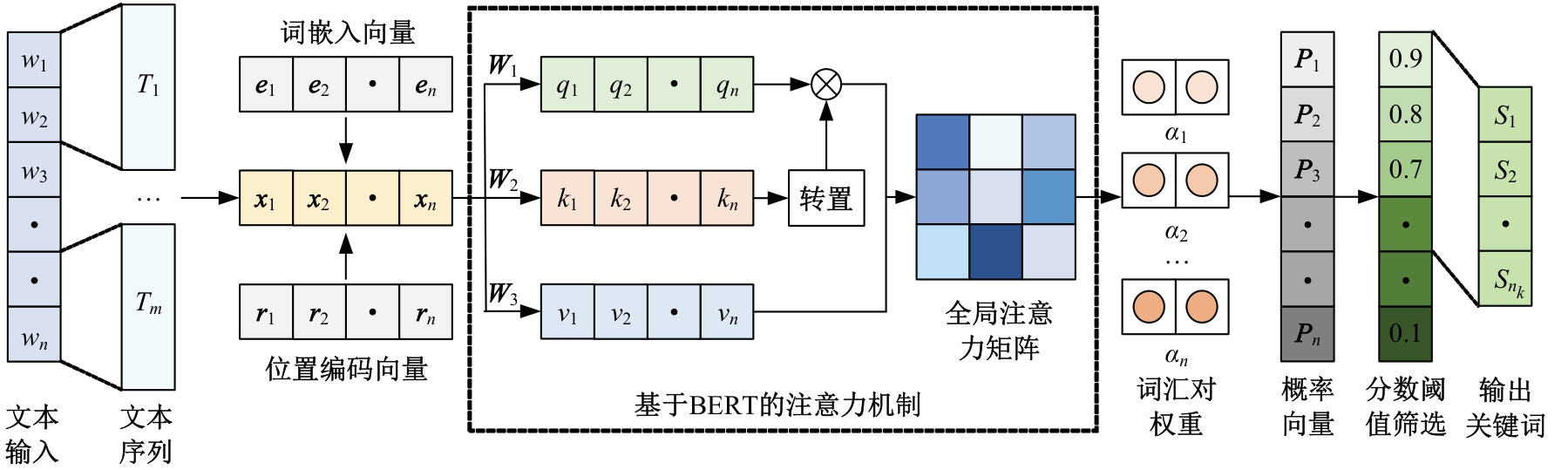
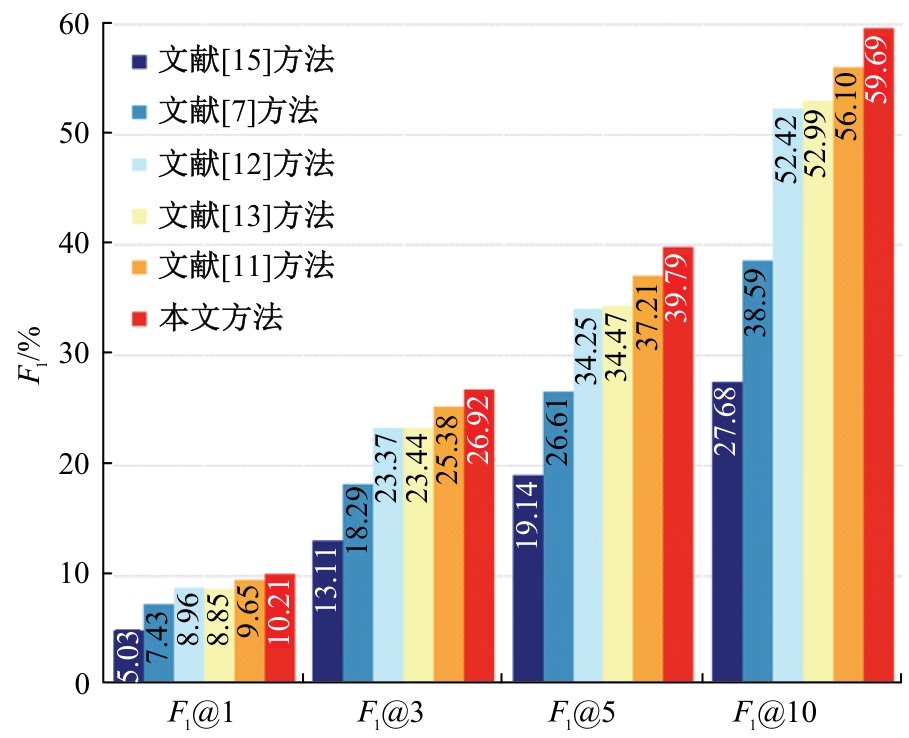
针对教师自我评价存在评价过程主观性较强、工作效率低下以及精准度不高等问题,本文提出了基于改进PositionRank算法的高校教师自我评价关键词提取方法。首先,对教师自我评价数据进行采集和清洗,去除冗余与异常数据以提高数据质量;其次,采用基于图的关键词抽取算法生成高质量标签数据;最后,通过改进后的PositionRank算法自适应学习词组间的注意力权重,实现关键词的精准提取。实验结果表明:该方法能高效识别教师评价中的关键内容,显著提高关键词提取的准确性,同时具备较强的评价一致性,有助于揭示教师的核心优势与改进方向,为完善高校教师评价体系提供了有力的技术支撑。
中图分类号:
- G64
| [1] | 胡瑞, 李彩云. 高校教师评价改革的“破”与“立”——基于新公共服务理论的分析框架[J]. 现代教育管理, 2024 (8): 99-107. |
| Hu Rui, Li Cai-yun. The "breaking" and "establishing" of teachers' evaluation reform in universities—analysis framework based on new public service theory[J]. Modern Education Management, 202, (8): 99-107. | |
| [2] | 黄春晨, 鲁长风, 田友谊. 人工智能赋能高等教育的政策嬗变与展望——基于“主题-工具-评价”的三维分析框架[J]. 高教探索, 2025(1): 48-59. |
| Huang Chun-chen, Lu Chang-feng, Tian You-yi. Policy transformation and future prospects of artificial intelligence empowering higher education[J]. Higher Education Exploration, 2025 (1): 48-59. | |
| [3] | 常耀成, 张宇翔, 王红, 等. 特征驱动的关键词提取算法综述[J]. 软件学报, 2018, 29(7): 2046-2070. |
| Chang Yao-cheng, Zhang Yu-xiang, Wang Hong, et al. Features oriented survey of state-of-the-art keyphrase extraction algorithms[J]. Journal of Software, 2018, 29(7): 2046-2070. | |
| [4] | 刘静, 徐学, 蔺跟荣. 现代信息技术赋能高校教师评价改革的实施路径探析[J]. 黑龙江高教研究, 2024, 42(9): 149-153. |
| Liu Jing, Xu Xue, Lin Gen-rong. Implementation approaches of modern information technology empowering the teacher evaluation reformin higher education institutions[J]. Heilongjiang Researches on Higher Education, 2024, 42(9): 149-153. | |
| [5] | 胡少虎, 张颖怡, 章成志. 关键词提取研究综述[J]. 数据分析与知识发现, 2021, 5(3): 45-59. |
| Hu Shao-hu, Zhang Ying-yi, Zhang Cheng-zhi. Review of keyword extraction studies[J]. Data Analysis and Kno- wledge Discovery, 2021, 5(3): 45-59. | |
| [6] | 于强, 林民, 李艳玲. 基于深度学习的关键词生成研究综述[J]. 计算机工程与应用, 2022, 58(14): 27-39. |
| Yu Qiang, Lin Min, Li Yan-ling. Review of keyphrase generation based on deep learning[J]. Computer Engineering and Applications, 2022, 58(14): 27-39. | |
| [7] | Salton G, Wong A, Yang C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620. |
| [8] | Page L, Brin S, Motwani R, et al. The PageRank citation ranking: bringing order to the web[C]∥The Web Conference,Technical Report, Toronto,Canada,1999:161-172. |
| [9] | Mihalcea R, Tarau P. Textrank: Bringing order into text[C]∥Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 2004: 404-411. |
| [10] | Bougouin A, Boudin F, Daille B. Topicrank: graph-based topic ranking for keyphrase extraction[C]∥International Joint Conference on Natural Language Processing,Nagoya, Japan, 2013: 543-551. |
| [11] | Florescu C, Caragea C. Positionrank: an unsupervised approach to keyphrase extraction from scholarly documents[C]∥Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (volume 1: long papers), Vancouver, Canada,2017: 1105-1115. |
| [12] | Liu Z, Huang W, Zheng Y, et al. Automatic keyphrase extraction via topic decomposition[C]∥Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, USA,2010: 366-376. |
| [13] | Sterckx L, Demeester T, Deleu J, et al. Topical word importance for fast keyphrase extraction[C]∥ Proceedings of the 24th International Conference on World Wide Web,Florence, Italy, 2015: 121-122. |
| [14] | Wan X, Xiao J. Single document keyphrase extraction using neighborhood knowledge[C]∥Proceedings of the AAAI Conference on Artificial Intelligence,San Diego, USA, 2008, 8: 855-860. |
| [15] | Bennani-Smires K, Musat C, Hossmann A, et al. Simple unsupervised keyphrase extraction using sentence embeddings[J/OL].[2025-02-26].arXiv preprint arXiv:. |
| [16] | Campos R, Mangaravite V, Pasquali A, et al. Yake! collection-independent automatic keyword extractor[C]∥Proceedings of the European Conference on Information Retrieval, Grenoble, France, 2018: 806-810. |
| [17] | 李渊本. 正则函数在统计机关人事信息数据清洗中的应用[J]. 统计与咨询, 2024(6): 36-38. |
| Li Yuan-ben. Application of regular expressions in data cleaning of statistical agency human resource information[J]. Statistics and Consultation, 2024(6): 36-38. | |
| [18] | 周宁,石雯茜,朱昭昭. 基于粗糙数据推理的TextRank关键词提取算法[J]. 中文信息学报, 2020, 34(9): 44-52. |
| Zhou Ning, Shi Wen-qian, Zhu Zhao-zhao. TextRank keyword extraction algorithm based on rough data-deduction[J]. Journal of Chinese Information Pro- cessing, 2020, 34(9): 44-52. | |
| [19] | 丁晓阳,王兰成. 网络论坛文本特征词权重计算优化方法研究[J]. 情报理论与实践, 2021, 44(5): 187-192. |
| Ding Xiao-yang, Wang Lan-cheng. Research on opti- mized calculation method for weight of terms in BBS text[J]. Information Studies: Theory & Application, 2021, 44(5): 187-192. | |
| [20] | 祖弦,谢飞. 一种基于全局和局部特征表示的关键词抽取算法[J]. 云南大学学报:自然科学版, 2023, 45(4): 825-836. |
| Zu Xian, Xie Fei. A keyphrase extraction algorithm based on global and local feature representation[J]. Journal of Yunnan University(Natural Sciences Edition), 2023, 45(4): 825-836. | |
| [21] | 焦宇超, 阎刚. 基于BERT与要素提取的相似案例匹配[J]. 智能计算机与应用, 2025, 15(1): 130-135. |
| Jiao Yu-chao, Yan Gang. Similar case matching based on BERT and feature extraction[J]. Intelligent Computer and Applications, 2025, 15(1): 130-135. | |
| [22] | 袁家政, 须德, 鲍泓. 基于结构与文本关键词相关度的XML网页分类研究[J]. 计算机研究与发展, 2006,43 (8): 1361-1367. |
| Yuan Jia-zheng, Xu De, Bao Hong. An efficient XML documents classification method based on structure and keywords frequency[J]. Journal of Computer Research and Development, 2006, 43(8): 1361-1367. |
| [1] | 龚勃文1,2,林赐云1,2,李静3,杨兆升1,2. 基于核自组织映射-前馈神经网络的交通流短时预测[J]. 吉林大学学报(工学版), 2011, 41(4): 938-943. |
| [2] | 张明国,耿云海,贾琳恒 . 基于RBF网络上界自适应学习的预警卫星滑模控制[J]. 吉林大学学报(工学版), 2007, 37(04): 959-964. |
|
||