吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (3): 1001-1008.doi: 10.13229/j.cnki.jdxbgxb.20240121
• 计算机科学与技术 •
基于TextRank算法和相似度的中文文本主题句自动提取
丁海兰1( ),祁坤钰2
),祁坤钰2
- 1.兰州交通大学 文学院,兰州 730070
2.西北民族大学 中国民族信息技术研究院,兰州 730030
Automatic extraction of Chinese text topic sentences based on TextRank algorithm and similarity
Hai-lan DING1(),Kun-yu QI2
- 1.School of Chinese Language and Literature,Lanzhou Jiaotong University,Lanzhou 730070,China
2.China Institute of Information Technology for Nationalities,Northwest Minzu University,Lanzhou 730030,China
摘要:
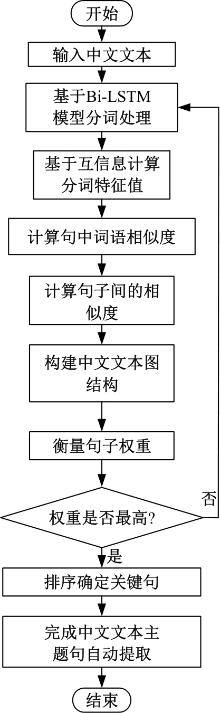
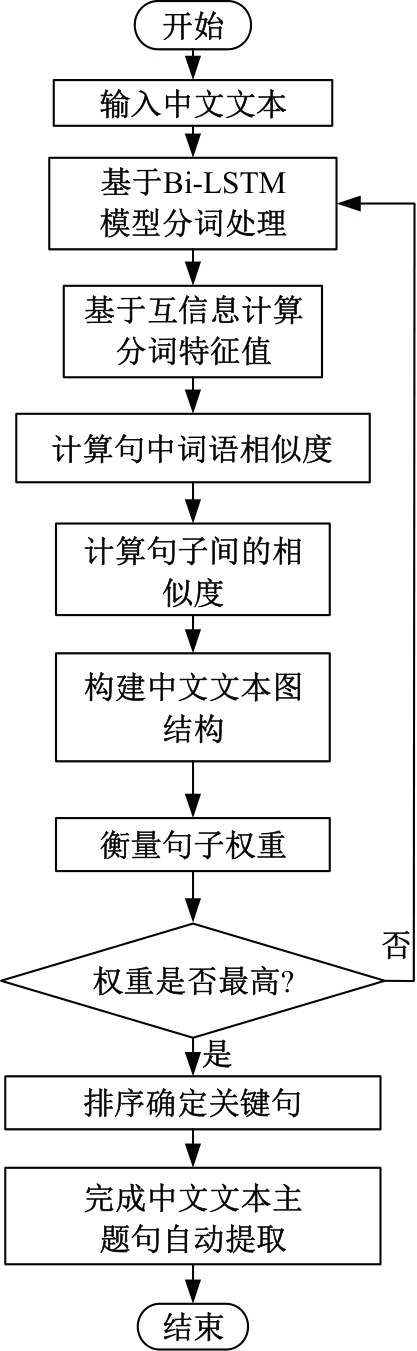
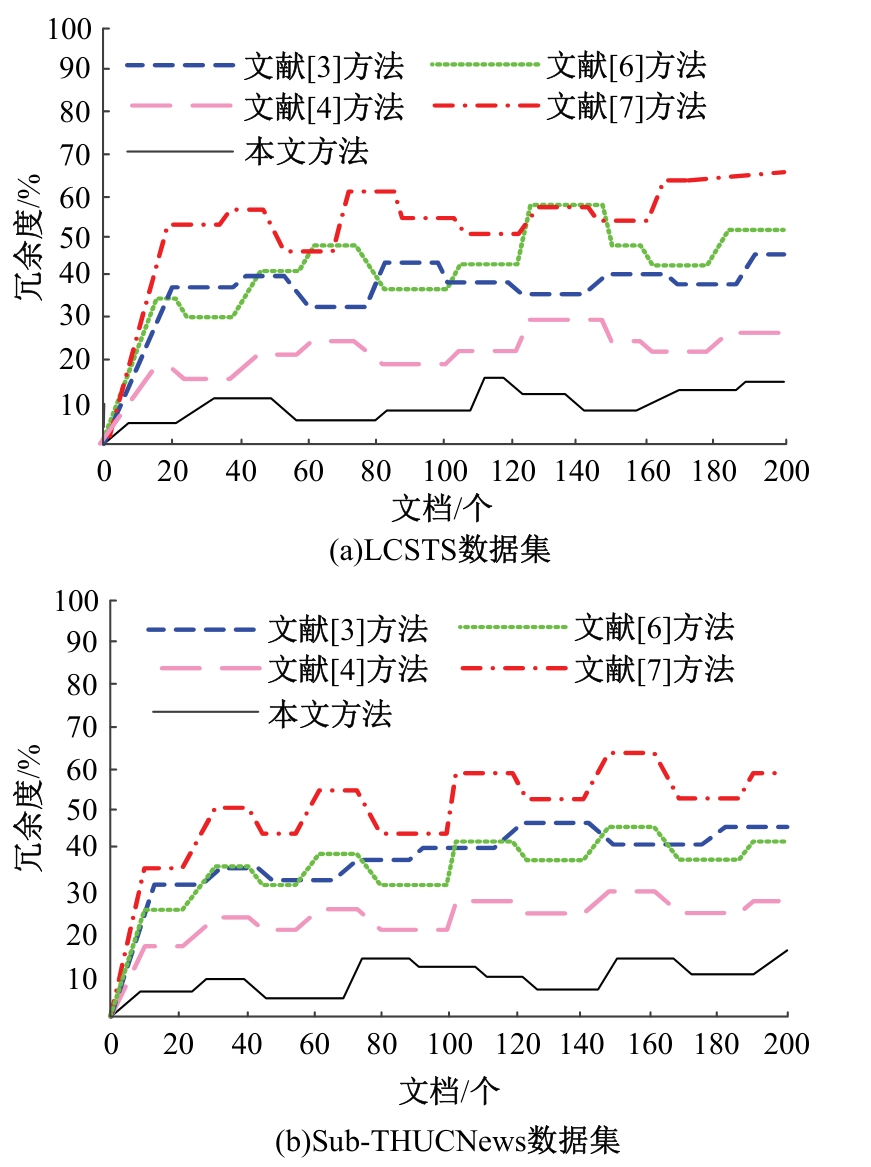
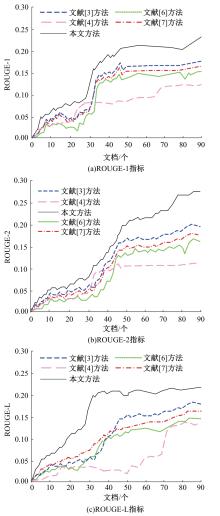
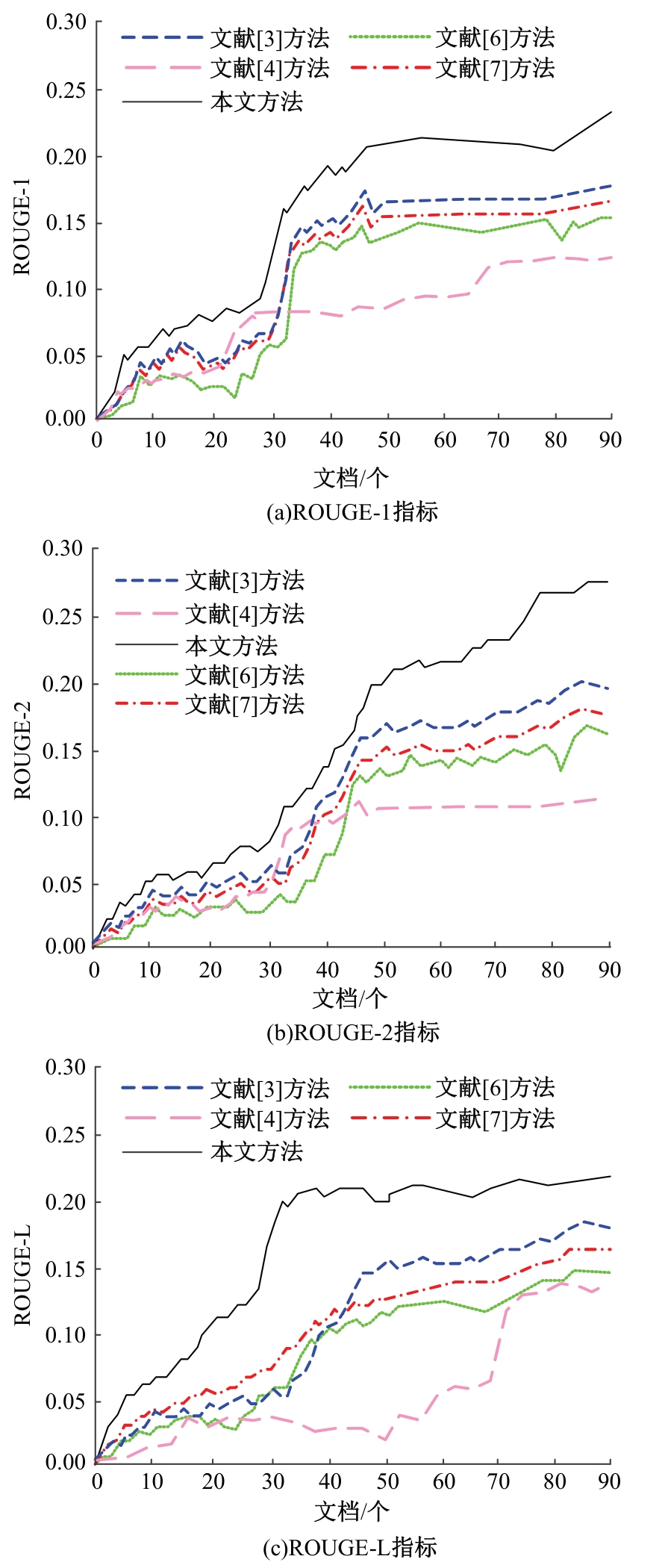
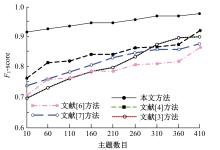
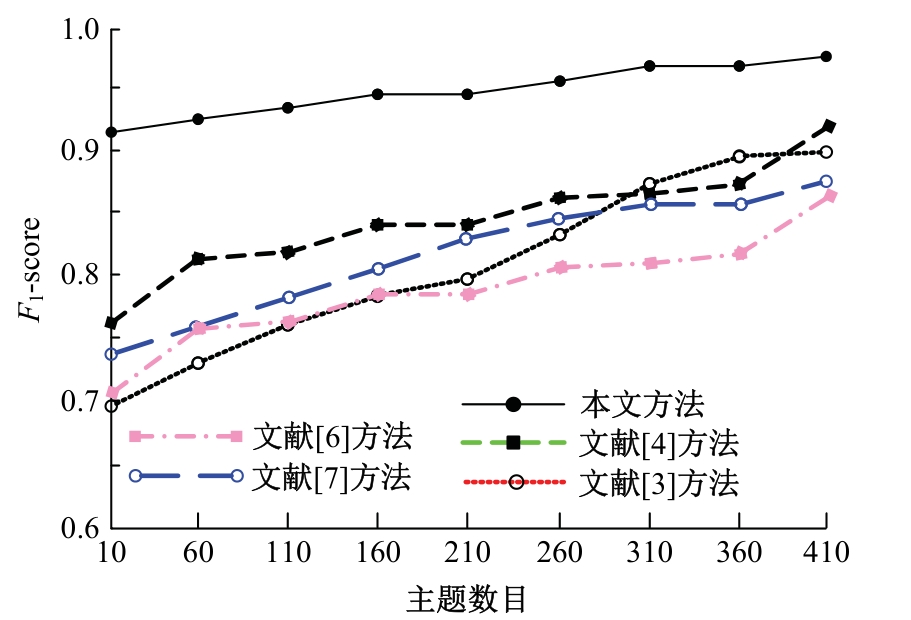
针对不同领域的语义规则和潜在主题结构复杂,导致主题句生成的易扩充性和可移植性不佳、中文文本主题句与中文文本的相似度较低、中文文本的主题句提取冗余度较高的问题,提出了基于TextRank算法和相似度的中文文本主题句自动提取方法。采用双向长短期记忆网络(Bi-LSTM)模型进行中文文本分词,将连续的中文文本切分成独立的词语,通过互信息方法进行中文文本特征,计算特征值,提取任务最相关、最有代表性的特征(如关键词、线索词)。将关键词、线索词作为主题句提取的重要线索和依据,基于TextRank算法和相似度,考虑各项权重和权重系数,完成中文文本主题句自动提取。实验结果表明,本文方法的中文文本主题句自动提取冗余度低,文档的完备性、易扩充性、可移植性均处于良好的状态,且ROUGE-1、ROUGE-2、ROUGE-L结果均较高,可以保证中文文本主题句自动提取效果,应用程度较高。
中图分类号:
- TP301
| 1 | 陈梦彤, 谷晓燕, 刘甜甜. 基于改进TextRank的关键句提取方法[J]. 郑州大学学报: 理学版, 2023, 55(1): 15-20. |
| Chen Meng-tong, Gu Xiao-yan, Liu Tian-tian. The method of key sentence extraction based on improved textrank[J]. Journal of Zhengzhou University (Natural Science Edition), 2023,55 (1): 15-20. | |
| 2 | 阮光册, 黄韵莹. 融合Sentence-BERT和LDA的评论文本主题识别[J].现代情报, 2023, 43(5): 46-53. |
| Ruan Guang-ce, Huang Yun-ying. Topic recognition of comment text based on Sentence-BERT and LDA[J]. Journal of Modern Information, 2023,43 (5): 46-53. | |
| 3 | 葛斌, 何春辉, 黄宏斌. 融合关键信息的PGN文本主题句生成方法[J].计算机工程与设计, 2022, 43(6): 1601-1608. |
| Ge Bin, He Chun-hui, Huang Hong-bin. PGN text topic sentence generation method based on key information[J]. Computer Engineering and Design, 2022, 43 (6): 1601-1608. | |
| 4 | 井钰, 王名扬, 周文远. 基于BBCM-TextRank的文本摘要提取算法研究[J]. 东北师大学报: 自然科学版, 2022, 54(3): 67-75. |
| Jing Yu, Wang Ming-yang, Zhou Wen-yuan. Research on text fabstract extraction algorithm based on BBCM-TextRank[Z]. Journal of Northeast Normal University (Natural Science Edition), 2022, 54 (3): 67-75. | |
| 5 | Sun J, Li Y, Shen Y, et al.Selection gate-based networks for semantic relation extraction[J].International Journal of Embedded Systems, 2021, 14(3): 211. |
| 6 | Xiong A, Liu D, Tian H, et al.News keyword extraction algorithm based on semantic clustering and word graph model[J].Tsinghua Science and Technology, 2021, 26(6): 886-893. |
| 7 | Ning B, Zhao D, Liu X, et al.EAGS: an extracting auxiliary knowledge graph model in multi-turn dialogue generation[J].World Wide Web, 2023, 26(4):1545-1566. |
| 8 | Taufiq U, Pulungan R, Suyanto Y. Named entity recognition and dependency parsing for better concept extraction in summary obfuscation detection[J].Expert Systems with Applications, 2023, 217(5): No.119579. |
| 9 | 张军, 赖志鹏, 李学, 等.基于新词发现的跨领域中文分词方法[J].电子与信息学报, 2022, 44(9): 3241-3248. |
| Zhang Jun, Lai Zhi-peng, Li Xue, et al. Cross-domain chinese word segmentation based on new word discovery[J]. Journal of Electronics & Information Technology, 2022, 44(9): 3241-3248. | |
| 10 | 郝永彬, 周兰江, 刘畅. 一种基于LSTM的端到端多任务老挝语分词方法[J]. 中文信息学报, 2021, 35(9): 75-81. |
| Hao Yong-bin, Zhou Lan-jiang, Liu Chang. An end-to-end multi task method for laotian word segmentation via LSTM[J]. Journal of Chinese Information Processing, 2021,35 (9): 75-81. | |
| 11 | 徐久成, 孟祥茹, 瞿康林, 等. 基于模糊邻域相对依赖互信息的特征选择方法[J]. 模糊系统与数学, 2023, 37(1): 121-135. |
| Xu Jiu-cheng, Meng Xiang-ru, Qu Kang-lin, et al. Feature selection method based on fuzzy neighborhood relative dependency mutual information[J]. Fuzzy Systems and Mathematics, 2023,37 (1): 121-135. | |
| 12 | 孙林, 施恩惠, 司珊珊, 等. 基于AP聚类和互信息的弱标记特征选择方法[J]. 南京师大学报: 自然科学版, 2022, 45(3): 108-115. |
| Sun Lin, Shi En-hui, Si Shan-shan, et al. Weak label feature selection method based on AP clustering and mutual information[J].Journal of Nanjing Normal University (Natural Science Edition), 2022, 45(3): 108-115. | |
| 13 | 赵占芳, 刘鹏鹏, 李雪山. 基于改进TextRank的铁路文献关键词抽取算法[J]. 北京交通大学学报, 2021, 45(2): 80-86. |
| Zhao Zhan-fang, Liu Peng-peng, Li Xue-shan. Keywords extraction algorithm of railway literature based on improved TextRank[J]. Journal of Beijing Jiaotong University, 2021,45 (2): 80-86. | |
| 14 | 叶子诚, 闫桂英. 基于图模型的关键词提取算法研究[J]. 系统科学与数学, 2021, 41(4): 967-975. |
| Ye Zi-cheng, Yan Gui-ying. Study on keyword extraction algorithm based on graphical model[J]. Journal of Systems Science and Mathematical Sciences, 2021, 41(4): 967-975. | |
| 15 | 孙旭, 沈彬, 严馨, 等. 基于Transformer和TextRank的微博观点摘要方法[J]. 广西师范大学学报:自然科学版, 2023, 41(4): 96-108. |
| Sun Xu, Shen Bin, Yan Xin, et al. Microblog opinion summarization method based on transformer and textrank[J]. Journal of Guangxi Normal University(Natural Science Edition), 2023,41(4): 96-108. |
| [1] | 谭泗桥, 张席, 李钎, 艾陈. 基于最大互信息系数的信息推送模型构建[J]. 吉林大学学报(工学版), 2018, 48(2): 558-563. |
| [2] | 安如, 王慧麟, 王盈, 陈春烨, 张琴, 徐晓峰. 16阶归一化互信息和改进PSO算法的快速图像匹配[J]. 吉林大学学报(工学版), 2013, 43(增刊1): 357-364. |
| [3] | 王金芳, 虢明, 聂新礼. 帧间差分相位谱帧长和帧移的最优设置方法[J]. 吉林大学学报(工学版), 2013, 43(增刊1): 6-10. |
| [4] | 王宏,赵海滨,刘冲. 采用小波熵和频带能量提取脑电信号特征[J]. 吉林大学学报(工学版), 2011, 41(03): 828-831. |
| [5] | 杨金宝, 刘常春, 胡顺波. 基于算术调和均值距离测度的弹性图像配准[J]. 吉林大学学报(工学版), 2009, 39(05): 1390-1394. |
| [6] | 何凯, 王树勋, 戴逸松. 估计1/ƒ类分形信号信噪比的新方法[J]. 吉林大学学报(工学版), 2004, (1): 35-39. |
|
||