Journal of Jilin University(Engineering and Technology Edition) ›› 2025, Vol. 55 ›› Issue (3): 986-992.doi: 10.13229/j.cnki.jdxbgxb.20240216
Previous Articles Next Articles
Optimization algorithm for speech facial video generation based on dense convolutional generative adversarial networks and keyframes
Yuan JI1,2( ),Ya-qi YU1
),Ya-qi YU1
- 1.Microelectronics Research and Development Center,Shanghai University,Shanghai 200444,China
2.School of Mechatronic Engineering and Automation,Shanghai University,Shanghai 200444,China
CLC Number:
- TP391
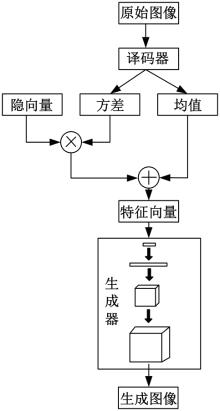


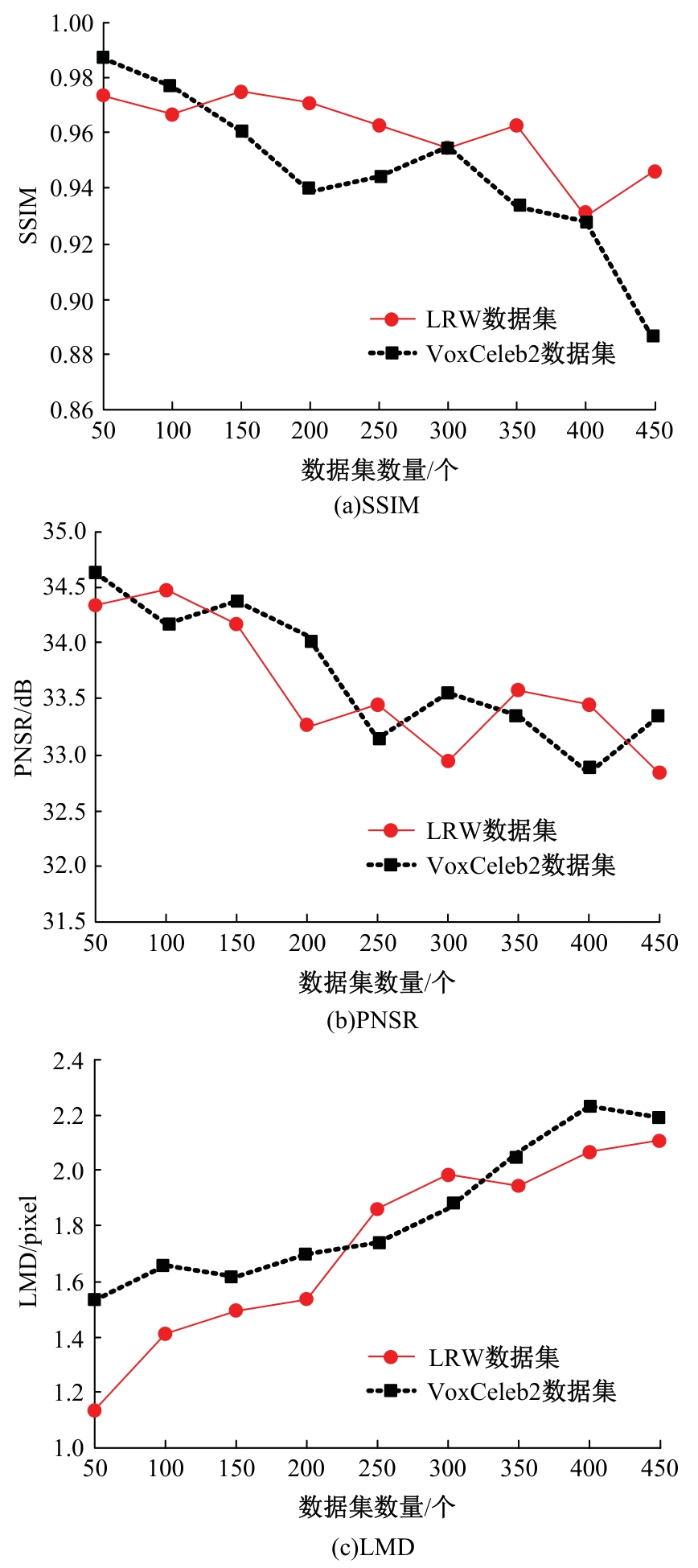
| 1 | 李海烽, 张雪英, 段淑斐, 等. 融合生成对抗网络与时间卷积网络的普通话情感识别[J]. 浙江大学学报:工学版,2023,57(9): 1865-1875. |
| Li Hai-feng, Zhang Xue-ying, Duan Shu-fei, et al. Fusing generative adversarial network and temporal convolutional network for Mandarin emotion recognition[J]. Journal of Zhejiang University(Engineering Science), 2023,57 (9): 1865-1875. | |
| 2 | 孙锐, 孙琦景, 单晓全, 等.基于多残差动态融合生成对抗网络的人脸素描-照片合成方法[J]. 模式识别与人工智能, 2022,35(3): 207-222. |
| Sun Rui, Sun Qi-jing, Shan Xiao-quan, et al. Face sketch-photo synthesis method based on multi-residual dynamic fusion generative adversarial networks[J]. Pattern Recognition and Artificial Intelligence, 2022, 35 (3): 207-2022. | |
| 3 | Fan X Q, Raza S A, Yan H. Edge-aware motion based facial micro-expression generation with attention mechanism[J].Pattern Recognition Letters,2022,162:97-104. |
| 4 | 刘安阳, 赵怀慈, 蔡文龙, 等. 基于主动判别机制的自适应生成对抗网络图像去模糊算法[J]. 计算机应用, 2023, 43(7): 2288-2294. |
| Liu An-yang, Zhao Huai-ci, Cai Wen-long, et al. Adaptive image deblurring generative adversarial network algorithm based on active discrimination mechanism[J]. Journal of Computer Applications, 2023,43 (7): 2288-2294. | |
| 5 | 陈北京, 李天牧, 王金伟, 等. 基于四元数的强泛化性GAN生成人脸检测算法[J]. 计算机辅助设计与图形学学报, 2022, 34(5): 734-742. |
| Chen Bei-jing, Li Tian-mu, Wang Jin-wei, et al. GAN-generated face detection with strong generalization ability based on quaternions[J]. Journal of Computer-Aided Design & Computer Graphics, 2022, 34 (5): 734-742. | |
| 6 | 王鹏, 喻乐延, 舒华忠, 等. 注意力融合双流特征的局部GAN生成人脸检测算法[J]. 东南大学学报: 自然科学版, 2023, 53(3): 543-551. |
| Wang Peng, Yu Le-yan, Shu Hua-zhong, et al. Locally GAN-generated face detection algorithm based on dual-stream features fused by attention[J]. Journal of Southeast University(Natural Science Edition), 2023,53 (3): 543-551. | |
| 7 | Zeng D, Zhao S T, Zhang J J, et al. Expression-tailored talking face generation with adaptive cross-modal weighting[J].Neurocomputing, 2022, 511(28): 117-130. |
| 8 | Andrea V, Carlos B. Multimodal attention for lip synthesis using conditional generative adversarial networks[J].Speech Communication: An International Journal,2023,153:No. 102959. |
| 9 | 温佩芝, 陈君谋, 肖雁南, 等.基于生成式对抗网络和多级小波包卷积网络的水下图像增强算法[J]. 浙江大学学报: 工学版, 2022, 56(2): 213-224. |
| Wen Pei-zhi, Chen Jun-mou, Xiao Yan-nan, et al. Underwater image enhancement algorithm based on GAN and multi-level wavelet CNN[J]. Journal of Zhejiang University (Engineering Science), 2022, 56 (2): 213-224. | |
| 10 | Fang Z, Liu Z, Liu T T, et al. Facial expression GAN for voice-driven face generation[J].The Visual Computer,2022,38(3):1151-1164. |
| 11 | Tang H, Shao L, Torr P H, et al. Bipartite graph reasoning GANs for person pose and facial image synthesis[J].International Journal of Computer Vision,2023,131(3): 644-658. |
| 12 | 侯向丹, 刘昊然, 刘洪普. 基于卷积自编码生成式对抗网络的高分辨率破损图像修复[J]. 中国图象图形学报, 2022, 27(5): 1645-1656. |
| Hou Xiang-dan, Liu Hao-ran, Liu Hong-pu. High-resolution damaged images restoration based on convolutional auto-encoder generative adversarial network[J]. Journal of Image and Graphics, 2022, 27 (5): 1645-1656. | |
| 13 | Li B, Zhang W, Li X B, et al. ECG signal reconstruction based on facial videos via combined explicit and implicit supervision[J].Knowledge-based Systems, 2023, 272(19): No.110608. |
| 14 | 张昊, 段锦, 刘举, 等. 基于密集梯度生成对抗网络的偏振图像融合算法[J]. 光学技术, 2023, 49(3): 354-360. |
| Zhang Hao, Duan Jin, Liu Ju, et al. Polarization image fusion algorithm based on dense gradient generative adversarial networks[J]. Optical Technique, 2023,49 (3): 354-360. | |
| 15 | Wu S K, Liu W M, Wang Q Q, et al. RefFaceNet: reference-based face image generation from line art drawings[J].Neurocomputing,2022,488(1):154-167. |
| 16 | Han Y M, Zhuo T, Zhang P, et al. One-shot video graph generation for explainable action reasoning[J]. Neurocomputing, 2022, 488(1): 212-225. |
| 17 | 王宏飞, 程鑫, 赵祥模, 等.光流与纹理特征融合的人脸活体检测算法[J]. 计算机工程与应用, 2022, 58(6): 170-176. |
| Wang Hong-fei, Cheng Xin, Zhao Xiang-mo, et al. Face liveness detection based on fusional optical flow and texture features[J]. Computer Engineering and Applications, 2022, 58 (6): 170-176. | |
| 18 | Xing L, Lin H R, Zhang D, et al. Facial characteristics of air gun array wavelets in the time and frequency domain under real conditions[J].Journal of Applied Geophysics,2022,199: No.104591. |
| 19 | 刘斌, 王耀威. 基于生成对抗网络的图像超分辨率重建算法[J]. 计算机仿真, 2023, 40(10): 269-273. |
| Liu Bin, Wang Yao-wei. Super resolution image reconstruction algorithm based on generated countermeasure network[J].Computer Simulation,2023,40(10): 269-273. |
| [1] | Xue-jun LI,Lin-fei QUAN,Dong-mei LIU,Shu-you YU. Improved Faster⁃RCNN algorithm for traffic sign detection [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 938-946. |
| [2] | Tao XU,Shuai-di KONG,Cai-hua LIU,Shi LI. Overview of heterogeneous confidential computing [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 755-770. |
| [3] | Hua CAI,Rui-kun ZHU,Qiang FU,Wei-gang WANG,Zhi-yong MA,Jun-xi SUN. Human pose estimation corrector algorithm based on implicit key point interconnection [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 1061-1071. |
| [4] | Guang-wen LIU,Xin-yue XIE,Qiang FU,Hua CAI,Wei-gang WANG,Zhi-yong MA. Spatiotemporal Transformer with template attention for target tracking [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 1037-1049. |
| [5] | Yang LI,Xian-guo LI,Chang-yun MIAO,Sheng XU. Low⁃light image enhancement algorithm based on dual branch channel prior and Retinex [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 1028-1036. |
| [6] | De-qiang CHENG,Gui LIU,Qi-qi KOU,Jian-ying ZHANG,He JIANG. Lightweight image super⁃resolution network based on adaptive large kernel attention fusion [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 1015-1027. |
| [7] | Yi CAO,Yu XIA,Qing-yuan GAO,Pei-tao YE,Fan YE. Skeleton-based action recognition based on hyper-connected graph convolutional network [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 731-740. |
| [8] | Meng-xue ZHAO,Xiang-jiu CHE,Huan XU,Quan-le LIU. A method for generating proposals of medical image based on prior knowledge optimization [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 722-730. |
| [9] | Hua CAI,Yan-yang ZHENG,Qiang FU,Sheng-yu WANG,Wei-gang WANG,Zhi-yong MA. Three-dimensional object detection algorithm based on multi-scale candidate fusion and optimization [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 709-721. |
| [10] | Xiao-dong CAI,Qing-song ZHOU,Yan-yan ZHANG,Yun XUE. Social recommendation based on global capture of dynamic, static and relational features [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 700-708. |
| [11] | Li-min ZHENG,Shuang CHEN,Gang LI. Multiple object detection of violated vehicles in traffic surveillance video based on YOLOv5 network algorithm [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 693-699. |
| [12] | Xiang-jiu CHE,Yu-ning WU,Quan-le LIU. A weighted isomorphic graph classification algorithm based on causal feature learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 681-686. |
| [13] | Xiao-ran GUO,Tie-jun WANG,Yue YAN. Entity relationship extraction method based on local attention and local remote supervision [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(1): 307-315. |
| [14] | Hao WANG,Bin ZHAO,Guo-hua LIU. Temporal and motion enhancement for video action recognition [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(1): 339-346. |
| [15] | Xi ZHANG,Shao-ping KU. Facial super-resolution reconstruction method based on generative adversarial networks [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(1): 333-338. |
|
||