Journal of Jilin University(Engineering and Technology Edition) ›› 2025, Vol. 55 ›› Issue (7): 2372-2377.doi: 10.13229/j.cnki.jdxbgxb.20240603
Query algorithm for massive Web multi-attribute data that integrates user interests
Jian-ping SUN1( ),Zhi-he LI2
),Zhi-he LI2
- 1.School of Artificial Intelligence,Beijing Normal University,Beijing 100088,China
2.Research Institute of Information Technology and Intelligence,Shanxi Normal University,Taiyuan 030031,China
CLC Number:
- TP391
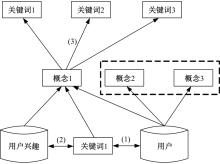
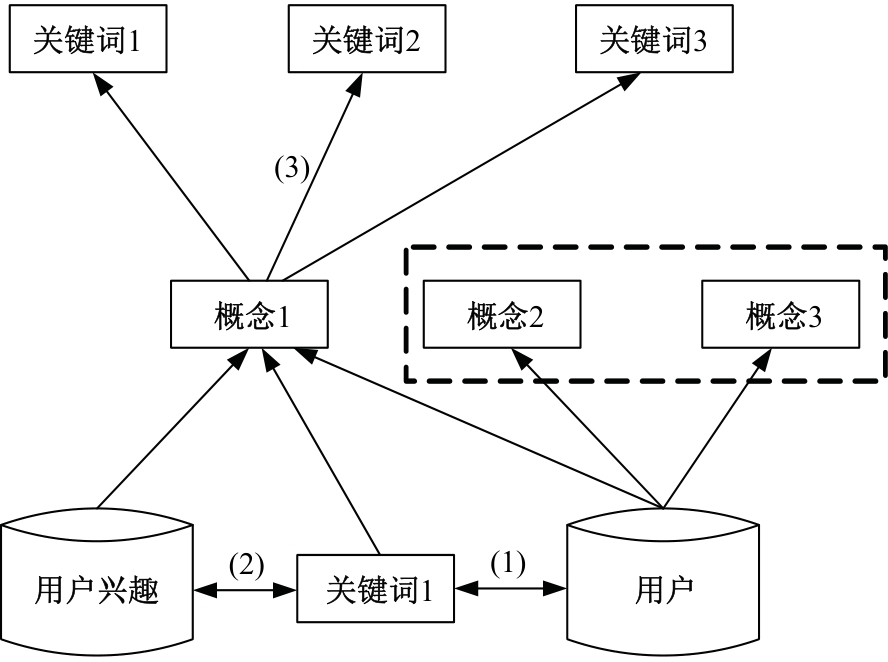


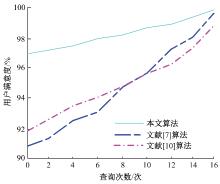
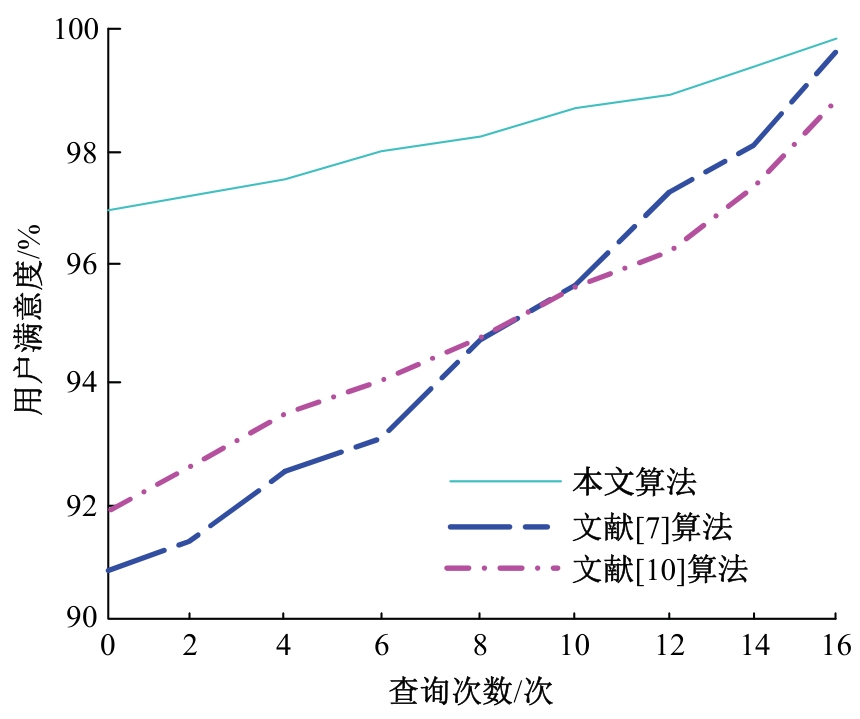
| [1] | 赵红梅, 肖明, 白宇, 等. 面向用户偏好的动态网页数据交互式查询算法[J]. 吉林大学学报: 理学版, 2024, 62(2): 417-422. |
| Zhao Hong-mei, Xiao Ming, Bai Yu, et al. Interactive query algorithm for dynamic web page data based on user preference[J]. Journal of Jilin University(Science Edition),2024,62(2):417-422. | |
| [2] | 孙琛琛, 申德荣, 肖迎元, 等. 面向查询式实体解析的多属性数据索引技术[J]. 软件学报, 2022, 33(6): 2331-2347. |
| Sun Chen-chen, Shen De-rong, Xiao Ying-yuan, et al. Multi-attribute data indexing for query based entity resolution[J]. Journal of Software,2022,33(6):2331-2347. | |
| [3] | 王子泓, 邵蓥侠, 何吉元, 等. 基于多空间属性信息融合的序列推荐[J]. 计算机科学, 2024, 51(3):102-108. |
| Wang Zi-hong, Shao Ying-xia, He Ji-yuan, et al. Sequential recommendation based on multi-space attribute information fusion[J]. Computer Science,2024,51(3):102-108. | |
| [4] | 翁彬月, 秦永彬, 黄瑞章, 等. NEMTF: 基于多维度文本特征的新闻网页信息提取方法[J]. 计算机应用研究, 2022, 39(4): 1043-1048. |
| Weng Bin-yue, Qin Yong-bin, Huang Rui-zhang,et al. NEMTF:method of news Web content extraction based on multi-dimensional text features[J]. Application Research of Computers,2022,39(4):1043-1048. | |
| [5] | 蒲岍岍, 雷航, 李贞昊, 等.增强列表信息和用户兴趣的个性化新闻推荐算法[J]. 计算机科学, 2022, 49(6): 142-148. |
| Pu Yan-yan, Lei Hang, Li Zhen-hao,et al. Personalized news recommendation algorithm with enhanced list[J]. Computer Science, 2022, 49(6):1 42-148. | |
| [6] | 聂卉, 邱以菲. 融合用户兴趣及评论效用的评论信息推荐[J]. 图书情报工作, 2021, 65(10): 68-78. |
| Nie Hui, Qiu Yi-fei. Integrating user interests with review helpfulness for review recommendation[J]. Library and Information Service,2021, 65(10): 68-78. | |
| [7] | 杨矫云, 郭思伊, 李廉. 基于Pac算法的流数据top-k实时查询[J].华中科技大学学报:自然科学版,2021, 49(2):56-61. |
| Yang Jiao-yun, Guo Si-yi, Li Lian. Pac based top-k real-time query algorithm for streaming data [J]. Journal of Huazhong University of Science and Technology(Nature Science Edition),2021, 49(2):56-61. | |
| [8] | 高俊杰, 杨帆. 基于群体智能的半结构化数据查询优化算法[J]. 计算机仿真, 2021, 38(8): 381-385. |
| Gao Jun-jie, Yang Fan. Semi-structured data query optimization algorithm based on swarm intelligence [J]. Computer Simulation,2021, 38(8): 381-385. | |
| [9] | 罗芳, 李春花, 周可, 等.基于多属性的海量Web数据关联存储及检索系统[J]. 计算机工程与科学, 2022, 36(3): 404-410. |
| Luo Fang, Li Chun-hua, Zhou Ke, et al. An associated storage and retrieval system of massive Web data based on multi-attributes[J]. Computer Engineering and Science,2022, 36(3): 404-410. | |
| [10] | Tung V, Salvatore A, Giulio J,et al. Spoken conversational context improves query auto-completion in web search[J]. ACM Transactions on Information Systems, 2021, 39(3): 1-32. |
| [11] | 张星, 张兴. dckpdp:改进k-prototype聚类的差分隐私混合属性数据发布方法[J]. 计算机应用研究, 2022, 39(1): 249-253. |
| Zhang Xing, Zhang Xing. Differential privacy mixed attribute data publishing method for improved k-prototype clustering[J]. Application Research of Computers, 2022, 39(1): 249-253. | |
| [12] | 虞文波, 游进国, 牛祥虞. 基于强化学习的数据库多属性索引推荐[J]. 计算机应用研究, 2023, 40(6): 1789-1793. |
| Yu Wen-bo, You Jin-guo, Niu Xiang-yu. Mira:database multi-attribute index recommendation based on reinforcement learning[J]. Application Research of Computers, 2023, 40(6): 1789-1793. | |
| [13] | 麻天, 余本国, 张静, 等. 基于混合聚类与融合用户兴趣的协同过滤推荐算法[J]. 电子技术应用, 2022, 48(4): 29-33. |
| Ma Tian, Yu Ben-guo, Zhang Jing, et al. Collaborative filtering recommendation algorithm based on hybrid clustering and user preferences fusion[J]. Application of Electronic Technique,2022, 48(4): 29-33. | |
| [14] | 凌宇, 单志龙. 基于兴趣增强的知识概念推荐系统[J].计算机应用, 2023, 43(12): 3697-3702. |
| Ling Yu, Shan Zhi-long. Knowledge concept recommendation system based on interest enhancement[J]. Journal of Computer Applications, 2023, 43(12): 3697-3702. | |
| [15] | 张彬, 徐建民, 吴姣. 大数据环境下基于知识图谱的用户兴趣扩展模型研究[J]. 现代情报, 2021, 41(8): 36-44. |
| Zhang Bin, Xu Jian-min, Wu Jiao. Research on user interest expansion model based on knowledge graph in big data environment[J]. Modern Information, 2021, 41(8): 36-44. |
| [1] | Xiang-jiu CHE,Liang LI. Graph similarity measurement algorithm combining global and local fine-grained features [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(7): 2365-2371. |
| [2] | Lan-fang ZHANG,Gen-ze LI,Ting-yu LIU,Bo YU. Mechanism and modeling of car⁃following behavior under local multi⁃vehicle influence [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 963-973. |
| [3] | Feng LYU,Nian LI,Zhuang-zhuang FENG,Yang-hang ZHANG. Method of collaborative filtering recommendation of personalized product-service system based on user [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(7): 1935-1942. |
| [4] | Chao-jian FANG,Xin-rong HU. Privacy-sensitive data filtering algorithm based on fuzzy approximation [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(4): 1174-1180. |
| [5] | Fu-heng QU,Tian-yu DING,Yang LU,Yong YANG,Ya-ting HU. Fast image codeword search algorithm based on neighborhood similarity [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(8): 1865-1871. |
| [6] | Ling ZHAI,Xu CUI. Text information similarity search algorithm based on segment estimation and PageRank [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(4): 910-915. |
| [7] | Su-ming KANG,Ye-e ZHANG. Hadoop⁃based local timing link prediction algorithm across social networks [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(3): 626-632. |
| [8] | Gui-xiang SHEN,Jun ZHENG,Ying-zhi ZHANG,Jie SONG,Zhe-wen LI. Risk analysis of machining center failure mode based on multi⁃attribute group decision making [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(2): 338-344. |
| [9] | Hai-long WANG,Lin LIU,Min LIN,Dong-mei PEI. Music personalized recommendation algorithm based on k⁃means clustering algorithm [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(5): 1845-1850. |
| [10] | Hong-wei ZHAO,Peng WANG,Li-li FAN,Huang-shui HU,Ping-ping LIU. Similarity retention instance retrieval method [J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(6): 2045-2050. |
| [11] | GUI Chun, HUANG Wang-xing. Network clustering method based on improved label propagation algorithm [J]. Journal of Jilin University(Engineering and Technology Edition), 2018, 48(5): 1600-1605. |
| [12] | WANG Xu, OUYANG Ji-hong, CHEN Gui-fen. Measurement of graph similarity based on vertical dimension sequence dynamic time warping method [J]. 吉林大学学报(工学版), 2018, 48(4): 1199-1205. |
| [13] | TAN Si-qiao, ZHANG Xi, LI Qian, AI Chen. Information push model-building based on maximum mutual information coefficient [J]. 吉林大学学报(工学版), 2018, 48(2): 558-563. |
| [14] | WANG Xu, OUYANG Ji-hong, CHEN Gui-fen. Heuristic algorithm of all common subsequences of multiple sequences for measuring multiple graphs similarity [J]. 吉林大学学报(工学版), 2018, 48(2): 526-532. |
| [15] | LUAN Wen-peng, LIU Yong-lei, WANG Peng, JIN Zhi-gang, WANG Jian. Novel universal security mechanism for energy internet based on trusted platform module [J]. 吉林大学学报(工学版), 2017, 47(6): 1933-1938. |
|
||