吉林大学学报(工学版) ›› 2024, Vol. 54 ›› Issue (8): 2355-2363.doi: 10.13229/j.cnki.jdxbgxb.20230341
前后文记忆矩阵引导的胸部放射影像报告生成模型
刘利军1,2( ),张云峰1,黄青松1
),张云峰1,黄青松1
- 1.昆明理工大学 信息工程与自动化学院,昆明 650500
2.云南省计算机技术应用重点实验室,昆明 650500
Anterior-posterior memory matrix model for chest radiology image report generation
Li-jun LIU1,2(),Yun-feng ZHANG1,Qing-song HUANG1
- 1.School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500,China
2.Yunnan Key Laboratory of Computer Technologies Application,Kunming 650500,China
摘要:
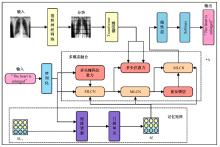
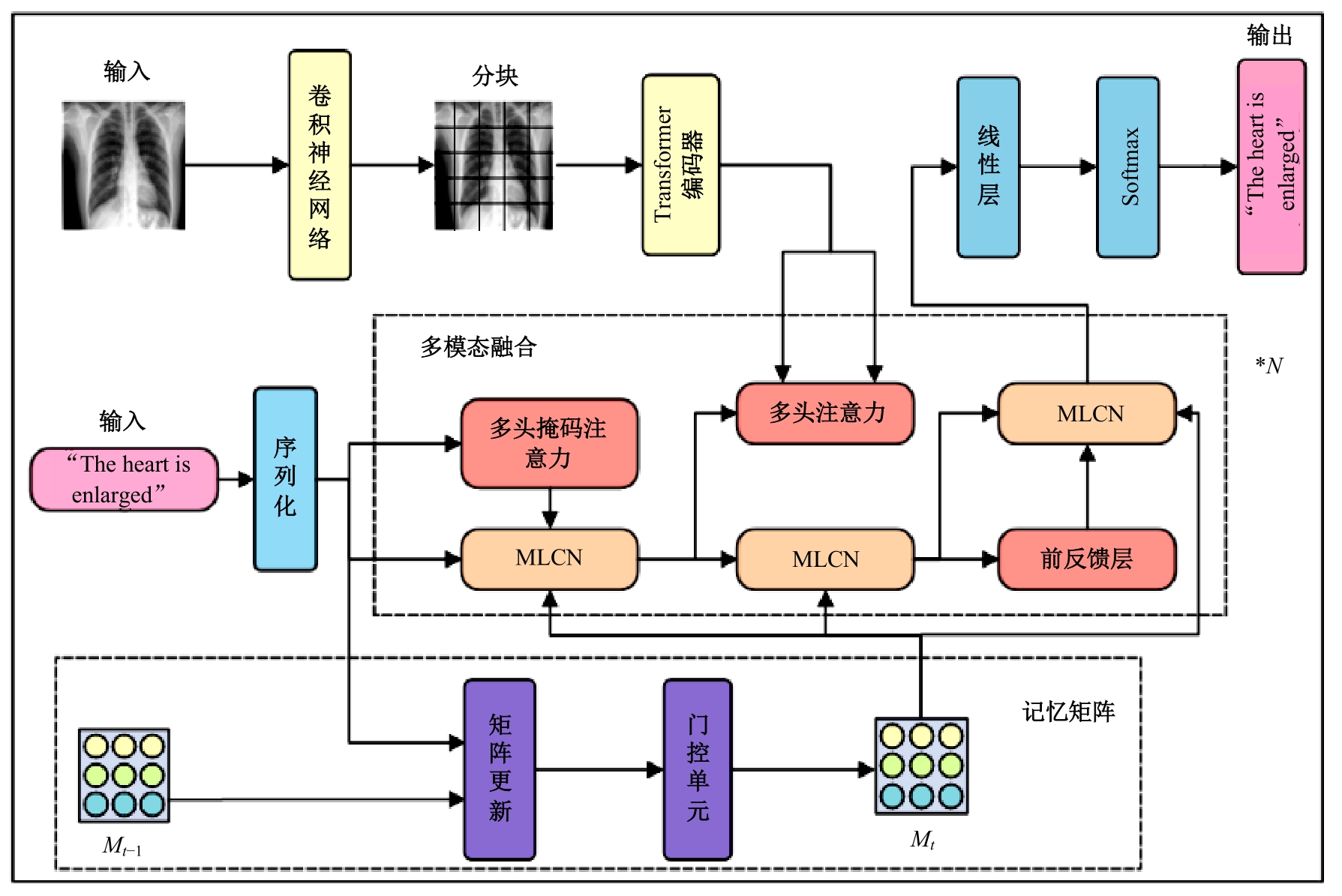
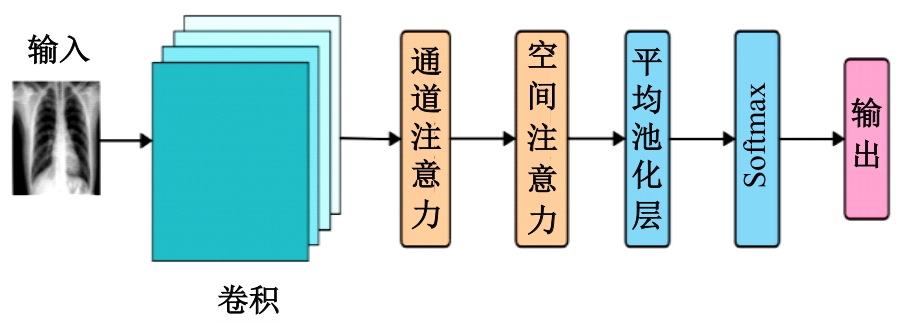
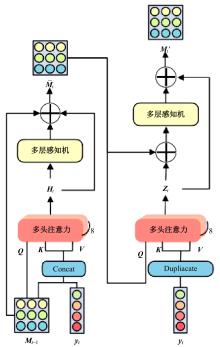
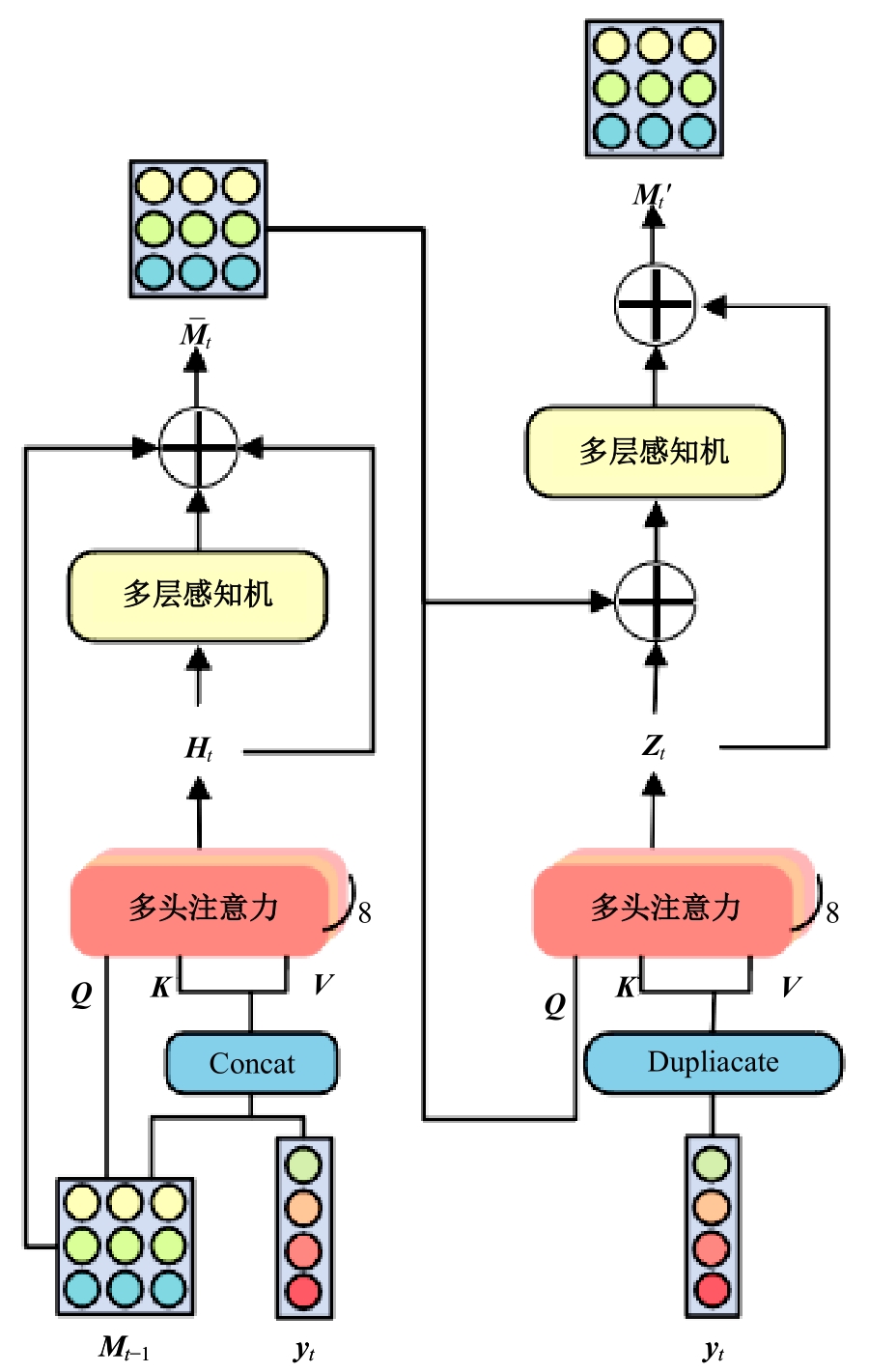
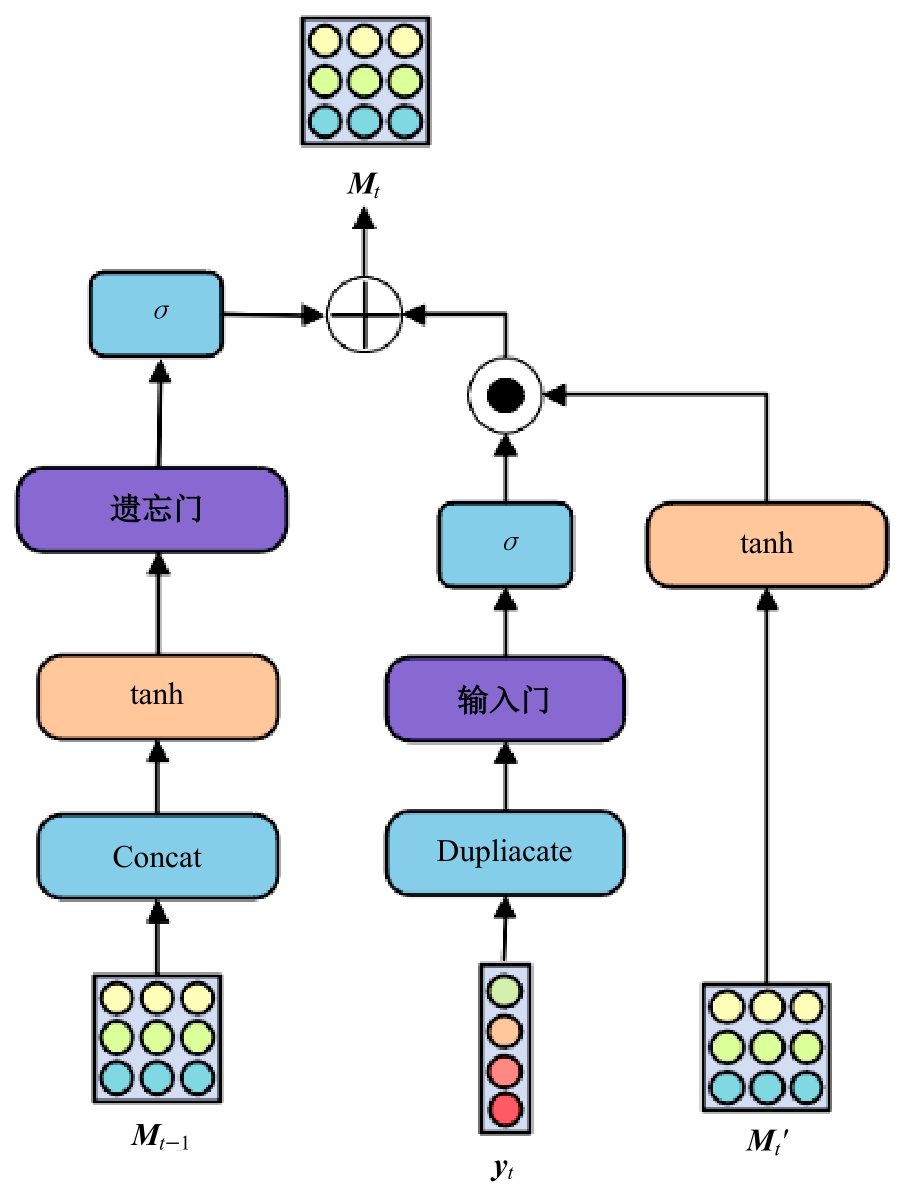
针对现有的放射影像报告生成方法主要关注前文信息在报告生成过程中的指导作用,忽略了后文信息在报告描述生成中的作用,存在语义信息不完整、关键信息缺失等问题,提出了一种前后文记忆矩阵引导的胸部放射影像报告生成模型(RadRG)。为了在生成过程中获得更丰富的语义信息,提出记忆矩阵生成模块(MA),使用记忆矩阵记录报告的模式信息和语义信息,并使用门控单元对其进行调控,以防止训练过程中出现梯度消失或信息爆炸。将本文模型在IU X-Ray和MIMIC-CXR公开数据集上进行了测试,实验结果表明:与现有主流模型对比,本文模型在BIEU指标达到了2.6%的提升。
中图分类号:
- TP391





| 1 | 刘桂霞, 田郁欣, 王涛, 等. 基于双输入3D卷积神经网络的胰腺分割算法[J]. 吉林大学学报: 工学版, 2023, 53(12): 3565-3572. |
| Liu Gui-xia, Tian Yu-xin, Wang Tao,et al. Pancreas segmentation algorithm based on dual input 3D convolutional neural network[J]. Journal of Jilin University (Engineering and Technology Edition), 2023, 53(12): 3565-3572. | |
| 2 | Kaur N, Mittal A, Singh G. Methods for automatic generation of radiological reports of chest radiographs: a comprehensive survey[J]. Multimedia Tools and Applications, 2022, 81(10): 13409-13439. |
| 3 | Li M, Liu R, Wang F, et al. Auxiliary signal-guided knowledge encoder-decoder for medical report generation[J]. World Wide Web, 2023, 26(1): 253-270. |
| 4 | Li C Y, Liang X, Hu Z, et al. Knowledge-driven encode, retrieve, paraphrase for medical image report generation[DB/OL].[2023-03-22].. |
| 5 | Wang Z, Zhou L, Wang L, et al. A self-boosting framework for automated radiographic report generation[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Nashville, USA,2021: 2433-2442. |
| 6 | Messina P, Pino P, Parra D, et al. A survey on deep learning and explainability for automatic report generation from medical images[J]. ACM Computing Surveys (CSUR), 2022, 54(10s): 1-40. |
| 7 | Kuo C W, Kira Z. Beyond a pre-trained object detector: cross-modal textual and visual context for image captioning[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,New Orleans,USA,2022: 17969-17979. |
| 8 | Luo Y, Ji J, Sun X, et al. Dual-level collaborative transformer for image captioning[DB/OL].[2023-03-22].. |
| 9 | Lu J, Xiong C, Parikh D, et al. Knowing when to look: adaptive attention via a visual sentinel for image captioning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Honolulu, USA, 2017: 375-383. |
| 10 | Diao H, Zhang Y, Ma L, et al. Similarity reasoning and filtration for image-text matching[DB/OL].[2023-03-23].. |
| 11 | Wang L, Li Y, Lazebnik S. Learning deep structure-preserving image-text embeddings[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA,2016: 5005-5013. |
| 12 | Wang H, Zhang Y, Ji Z, et al. Consensus-aware visual-semantic embedding for image-text matching[C]∥Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 2020: 18-34. |
| 13 | Kim W, Son B, Kim I. Vilt: Vision-and-language transformer without convolution or region supervision[DB/OL].[2023-03-23].∥. |
| 14 | Srinivasan P, Thapar D, Bhavsar A, et al. Hierarchical X-ray report generation via pathology tags and multi head attention[C]∥Proceedings of the Asian Conference on Computer Vision. Berlin:Springer, 2020: 600-616. |
| 15 | Chen Z, Song Y, Chang T H, et al. Generating radiology reports via memory-driven transformer[DB/OL].[2023-03-23].. |
| 16 | Liu F, You C, Wu X, et al. Auto-encoding knowledge graph for unsupervised medical report generation[J]. Advances in Neural Information Processing Systems, 2021, 34: 16266-16279. |
| 17 | Vu Y N T, Wang R, Balachandar N, et al. Medaug: contrastive learning leveraging patient metadata improves representations for chest X-ray interpretation[DB/OL].[2023-03-24].. |
| 18 | Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]∥Proceedings of the European conference on computer vision (ECCV). Berlin: Springer,2018: 3-19. |
| 19 | 肖明尧, 李雄飞, 朱芮. 基于NSST域像素相关分析的医学图像融合[J]. 吉林大学学报:工学版, 2023, 53(9): 2640-2648. |
| Xiao Ming-yao, Li Xiong-fei, Zhu Rui. Medical image fusion based on pixel correlation analysis in NSST domain[J]. Journal of Jilin University (Engineering and Technology Edition), 2023, 53(9): 2640-2648. | |
| 20 | Demner-Fushman D, Kohli M D, Rosenman M B, et al. Preparing a collection of radiology examinations for distribution and retrieval[J]. Journal of the American Medical Informatics Association, 2016, 23(2): 304-310. |
| 21 | Liu F, Wu X, Ge S, et al. Exploring and distilling posterior and prior knowledge for radiology report generation[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Nashville, USA, 2021: 13753-13762. |
| 22 | Chen Z, Shen Y, Song Y, et al. Cross-modal memory networks for radiology report generation[DB/OL].[2023-03-24].. |
| 23 | Yang S, Wu X, Ge S, et al. Radiology report generation with a learned knowledge base and multi-modal alignment[J]. Medical Image Analysis, 2023, 86: No.102798. |
| 24 | Jing B, Xie P, Xing E. On the automatic generation of medical imaging reports[DB/OL].[2023-03-24].. |
| 25 | Li Y, Liang X, Hu Z, et al. Hybrid retrieval-generation reinforced agent for medical image report generation[DB/OL].[2023-03-24].. |
| 26 | Jing B, Wang Z, Xing E. Show, describe and conclude : on exploiting the structure information of chest X-ray reports[DB/OL].[2023-03-24].. |
| 27 | Anderson P, He X, Buehler C, et al. Bottom-up and top-down attention for image captioning and visual question answering[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Salt Lake City, USA,2018: 6077-6086. |
| [1] | 侯春萍,杨庆元,黄美艳,王致芃. 基于语义耦合和身份一致性的跨模态行人重识别方法[J]. 吉林大学学报(工学版), 2022, 52(12): 2954-2963. |
|