吉林大学学报(工学版) ›› 2022, Vol. 52 ›› Issue (6): 1434-1441.doi: 10.13229/j.cnki.jdxbgxb20210098
• 计算机科学与技术 • 上一篇
基于多球分裂的增量式k-means聚类算法
曲福恒1( ),钱超越1,杨勇1,2(),陆洋1,宋剑飞1,胡雅婷3
),钱超越1,杨勇1,2(),陆洋1,宋剑飞1,胡雅婷3
- 1.长春理工大学 计算机科学技术学院,长春 130022
2.长春师范大学 教育学院,长春 130032
3.吉林农业大学 信息技术学院,长春 130118
Incremental k⁃means clustering algorithm based on multi⁃sphere splitting
Fu-heng QU1(),Chao-yue QIAN1,Yong YANG1,2(),Yang LU1,Jian-fei SONG1,Ya-ting HU3
- 1.College of Computer Science and Technology,Changchun University of Science and Technology,Changchun 130022,China
2.College of Education,Changchun Normal University,Changchun 130032,China
3.College of Information Technology,Jilin Agricultural University,Changchun 130118,China
摘要:
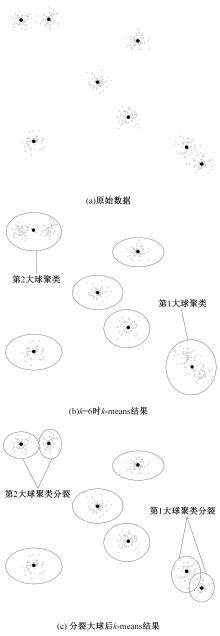
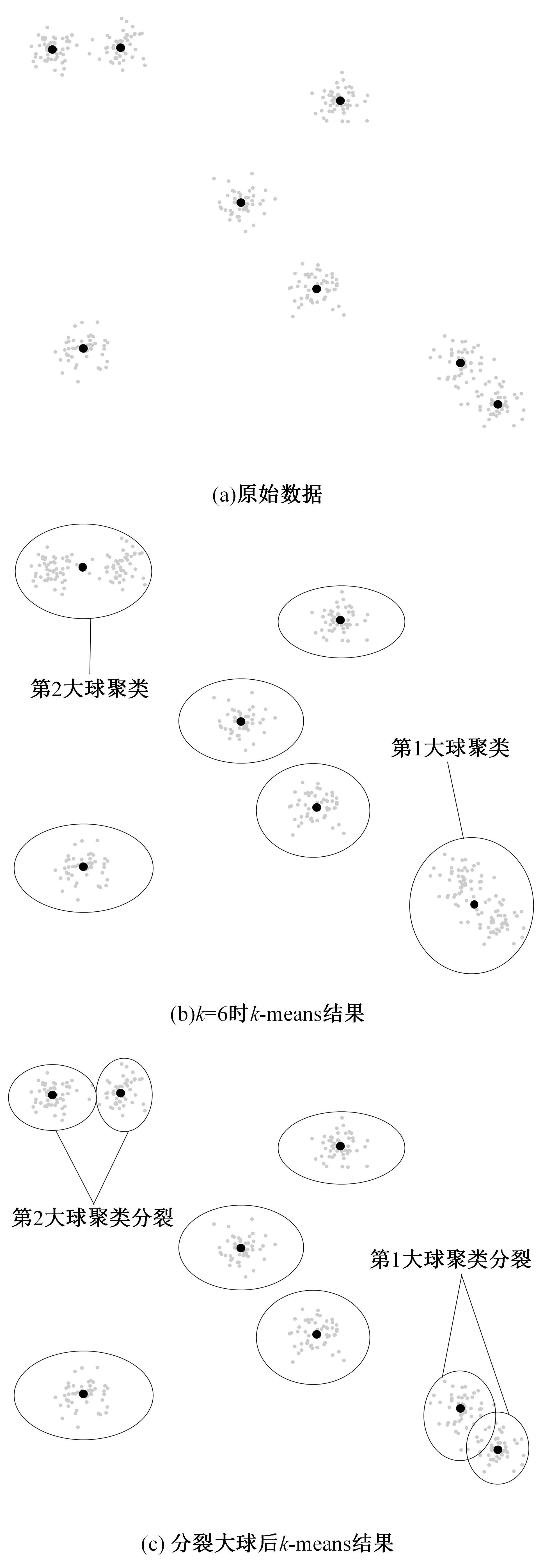
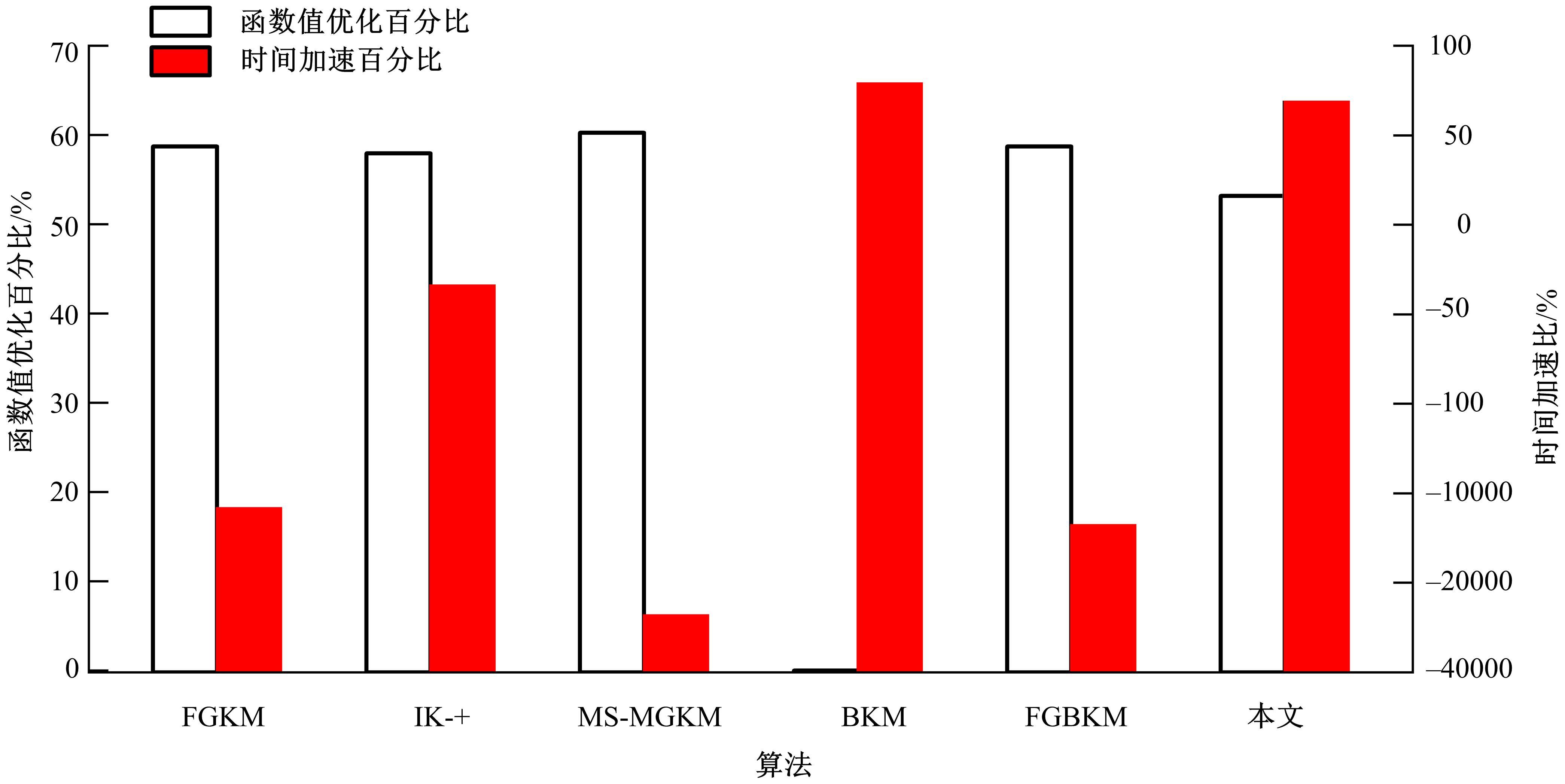
针对Ball k-means(BKM)算法对初始化中心敏感、求解精度不高的问题,提出了一种基于多球分裂的增量式k-means聚类算法。该算法利用BKM需要记录各球聚类半径的特点,从给定的初始聚类中心个数开始,按照固定步长一次性产生多个增量聚类中心,直至得到
中图分类号:
- TP391

| 1 | 金晓民,张丽萍. 基于最小生成树的多层次k-means聚类算法及其在数据挖掘中的应用[J]. 吉林大学学报: 理学版,2018,56(5): 1187-1192. |
| Jin Xiao-min, Zhang Li-ping. Multi-level k-means clustering algorithm based on minimum spanning tree and its application in data mining[J]. Journal of Jilin University(Science Edition),2018, 56(5): 1187-1192. | |
| 2 | 张杰,卓灵,朱韵攸. 一种k-means聚类算法的改进与应用[J]. 电子技术应用,2015,41(1): 125-128, 131. |
| Zhang Jie, Zhuo Ling, Zhu Yun-xiao. Improvement and application of a k-means clustering algorithm[J]. Application of Electronic Technology, 2015, 41(1): 125-128, 131. | |
| 3 | 刘仲民,李战明,李博皓,等. 基于稀疏矩阵的谱聚类图像分割算法[J]. 吉林大学学报: 工学版,2017,47(4): 1308-1313. |
| Liu Zhong-min, Li Zhan-ming, Li Bo-hao, et al. Spectral clustering image segmentation based on sparse matrix[J]. Journal of Jilin University(Engineering and Technology Edition), 2017, 47(4): 1308-1313. | |
| 4 | Elkan C. Using the triangle inequality to accelerate k-means[C]∥Proceedings of the 20th International Conference on Machine Learning,La Jolla, California, 2003: 147-153. |
| 5 | Hamerly G. Making k-means even faster[C]∥Proceedings of the 2010 SIAM International Conference on Data Mining, Columbus, Ohio, USA, 2010: 130-140. |
| 6 | Drake J, Hamerly G. Accelerated k-means with adaptive distance bounds[C]∥5th NIPS Workshop on Optimization for Machine Learning, Lake Tahoe, California, America, 2012. |
| 7 | Newling J, Fleuret F. Fast k-means with accurate bounds[C]∥ICML'16: Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, America, 2016: 936-944. |
| 8 | Ding Y F, Zhao Y, Shen X P, et al. Yinyang k-means: a drop-in replacement of the classic k-means with consistent speedup[C]∥Proceedings of the 32nd International Conference on Machine Learning, Lila, France, 2015: 579-587. |
| 9 | Xia S Y, Peng D W, Meng D Y, et al. Ball k-means: fast adaptive clustering with no bounds[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 87-99. |
| 10 | Likas A, Vlassis N, Verbeek J J. The global k-means clustering algorithm[J]. Pattern Recognition, 2003, 36(2): 451-461. |
| 11 | Bagirov A M. Modified global k-means algorithm for minimum sum-of-squares clustering problems[J]. Pattern Recognition, 2008, 41(10): 3192-3199. |
| 12 | Bagirov A M, Ugon J, Webb D. Fast modified global k-means algorithm for incremental cluster construction[J]. Pattern Recognition, 2011, 44(4): 866-876. |
| 13 | Ordin B, Bagirov A M. A heuristic algorithm for solving the minimum sum-of-squares clustering problems[J]. Journal of Global Optimization, 2015, 61(2): 341-361. |
| 14 | Xie J, Jiang S, Xie W, et al. An efficient global k-means clustering algorithm[J]. Journal of Computers, 2011, 6(2): 271-279. |
| 15 | Yang X, Li Y, Sun Y, et al. Fast and robust rbf neural network based on global k-means clustering with adaptive selection radius for sound source angle estimation[J]. IEEE Transactions on Antennas and Propagation, 2018, 66(6): 3097-3107. |
| 16 | 于剑,程乾生. 模糊聚类方法中的最佳聚类数的搜索范围[J]. 中国科学,2002,32(2): 275-280. |
| Yu Jian, Cheng Qian-sheng. The search range of optimal cluster number in fuzzy clustering method[J]. China Science, 2002, 32(2): 275-280. | |
| 17 | Hartigan J A, Wong M A. Algorithm AS 136: a k-means clustering algorithm[J]. Applied Statistics, 1979, 28(1): 100-108. |
| 18 | Ismkhan H. Ik-means-+: an iterative clustering algorithm based on an enhanced version of the k-means[J]. Pattern Recognition, 2018, 79: 402-413. |
| [1] | 徐卓君,杨雯婷,杨承志,田彦涛,王晓军. 雷达脉内调制识别的改进残差神经网络算法[J]. 吉林大学学报(工学版), 2021, 51(4): 1454-1460. |
| [2] | 袁哲明,袁鸿杰,言雨璇,李钎,刘双清,谭泗桥. 基于深度学习的轻量化田间昆虫识别及分类模型[J]. 吉林大学学报(工学版), 2021, 51(3): 1131-1139. |
| [3] | 刘富,刘璐,侯涛,刘云. 基于优化MSR的夜间道路图像增强方法[J]. 吉林大学学报(工学版), 2021, 51(1): 323-330. |
| [4] | 翟凤文,党建武,王阳萍,金静,罗维薇. 基于扩展轮廓的快速仿射不变特征提取[J]. 吉林大学学报(工学版), 2019, 49(4): 1345-1356. |
| [5] | 刘富, 兰旭腾, 侯涛, 康冰, 刘云, 林彩霞. 基于优化k-mer频率的宏基因组聚类方法[J]. 吉林大学学报(工学版), 2018, 48(5): 1593-1599. |
| [6] | 顾播宇,孙俊喜,李洪祚,刘红喜,刘广文. 基于特征加权模块双方向二维主成分分析的人脸识别[J]. 吉林大学学报(工学版), 2014, 44(3): 828-833. |
| [7] | 常志勇, 陈东辉, 张凌, 佟月英, 翁小辉, 佟金. 基于多传感器融合的鸡肉新鲜度检测方法[J]. 吉林大学学报(工学版), 2013, 43(增刊1): 493-496. |
| [8] | 陈万忠, 孙保峰, 高韧杰, 雷俊. 基于NNE技术的手臂运动模式识别算法研究[J]. 吉林大学学报(工学版), 2013, 43(增刊1): 69-73. |
| [9] | 李阳, 田彦涛, 陈万忠. 基于半监督boosting表面肌电信号多类模式识别[J]. 吉林大学学报(工学版), 2013, 43(05): 1415-1426. |
| [10] | 杨冬风, 马秀莲. 基于分形纹理分析的蛋壳裂纹识别[J]. 吉林大学学报(工学版), 2011, 41(增刊1): 348-352. |
| [11] | 王丹, 张祥合, 张立, 任露泉. 多维多分辨仿生识别方法及其应用[J]. 吉林大学学报(工学版), 2011, 41(02): 408-0412. |
| [12] | 王利民,臧雪柏,曹春红2. 基于广义信息论的决策森林数据挖掘模型[J]. 吉林大学学报(工学版), 2010, 40(01): 155-0158. |
| [13] | 王旭,陈永刚,杨印生 . 含有区间数的DEA-DA模型及灵敏度[J]. 吉林大学学报(工学版), 2009, 39(03): 716-0720. |
| [14] | 李伦波,马广富 . 基于RBPNN的退化交通标志图像的识别算法[J]. 吉林大学学报(工学版), 2008, 38(06): 1429-1433. |
| [15] | 谭梅, 尹义龙, 杨卫辉. 基于区域水平的指纹纹线距离估计方法[J]. 吉林大学学报(工学版), 2005, 35(05): 537-0541. |
|
||