吉林大学学报(工学版) ›› 2021, Vol. 51 ›› Issue (4): 1375-1386.doi: 10.13229/j.cnki.jdxbgxb20200314
• 计算机科学与技术 • 上一篇
基于随机性特征的加密和压缩流量分类
李光松1( ),李文清1(),李青2
),李文清1(),李青2
- 1.信息工程大学 网络空间安全学院,郑州 450001
2.信息工程大学 信息系统工程学院,郑州 450001
Encrypted and compressed traffic classification based on random feature set
Guang-song LI1(),Wen-qing LI1(),Qing LI2
- 1.School of Cyber Security,Information Engineering University,Zhengzhou 450001,China
2.School of Information Systems Engineering,Information Engineering University,Zhengzhou 450001,China
摘要:
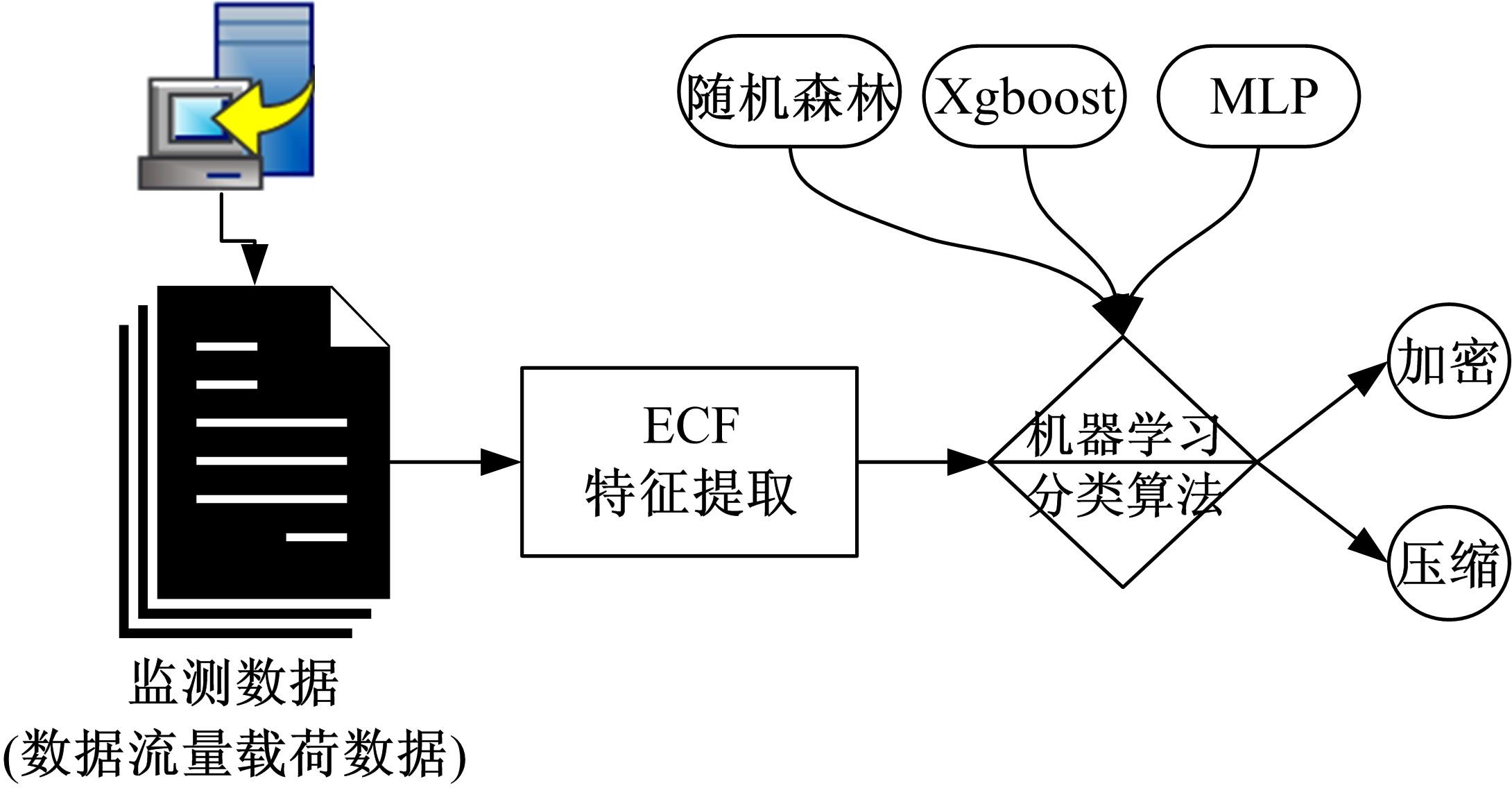
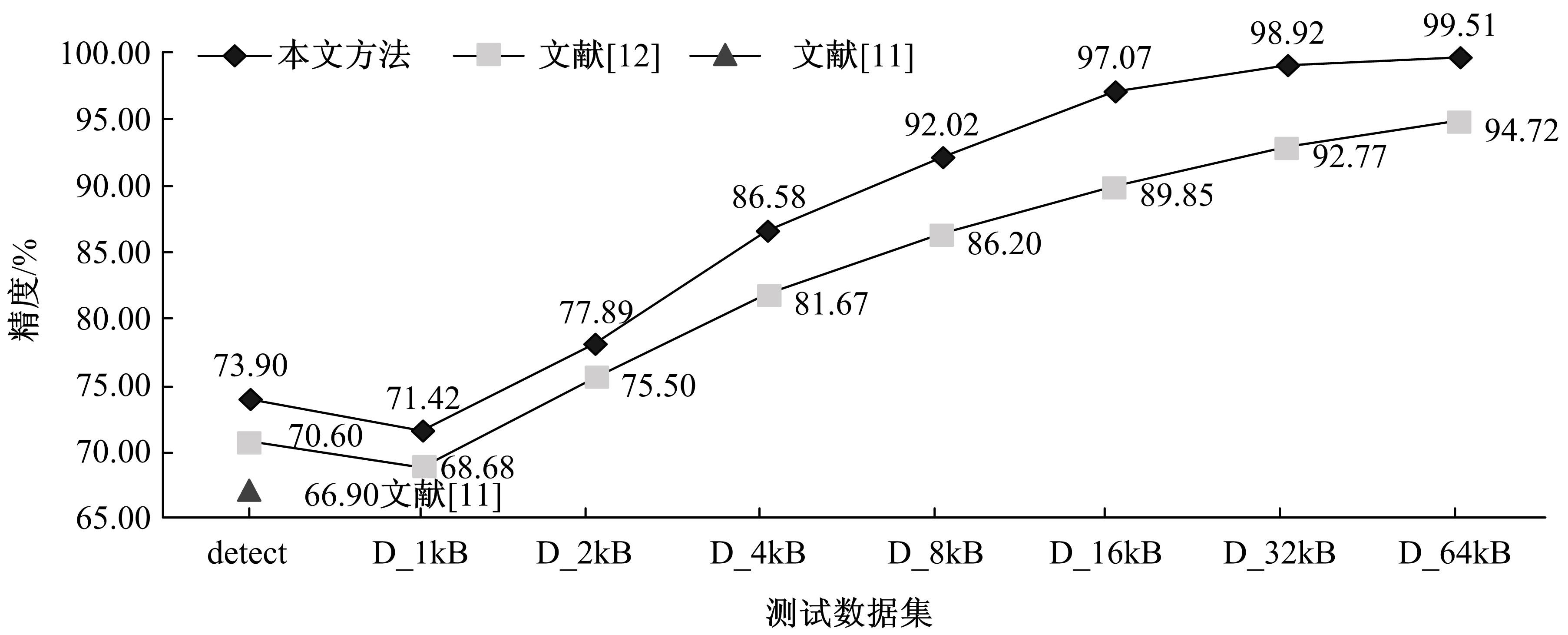
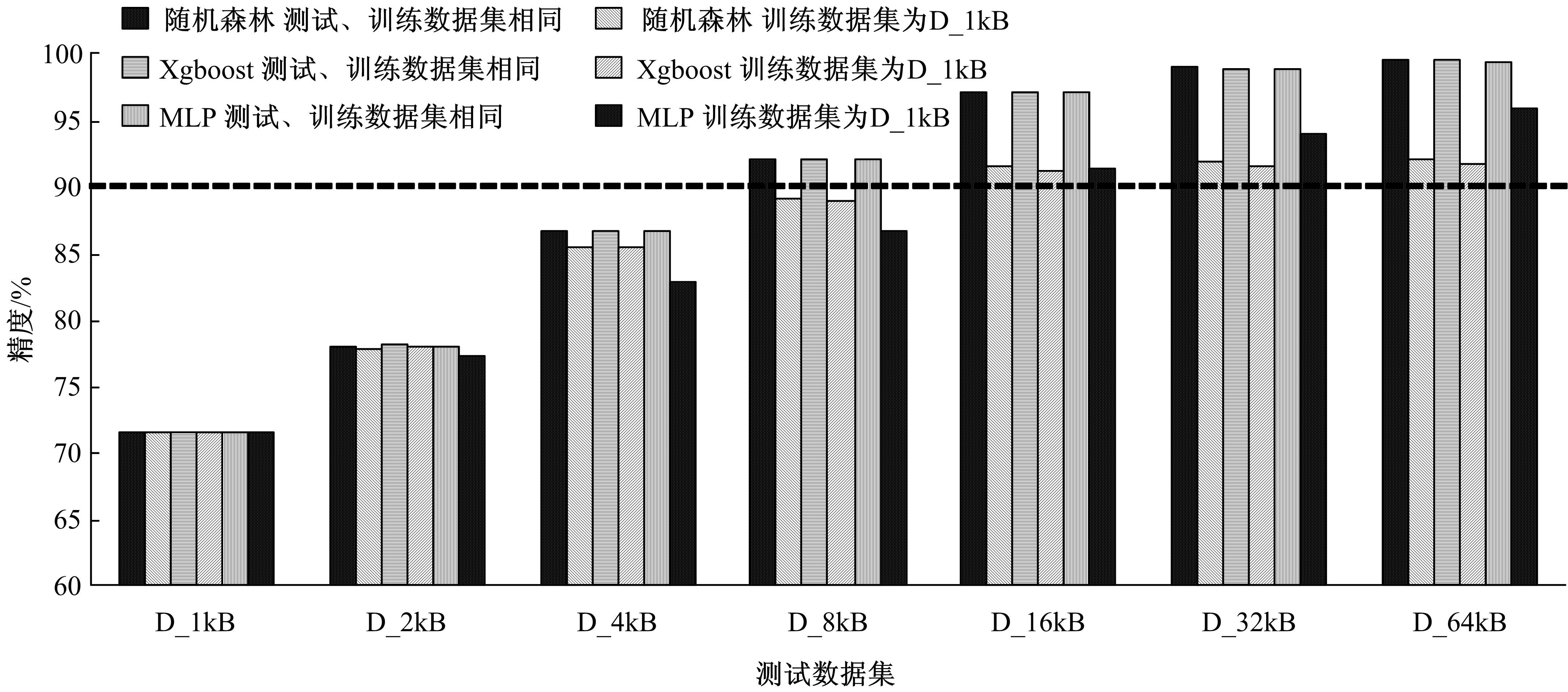
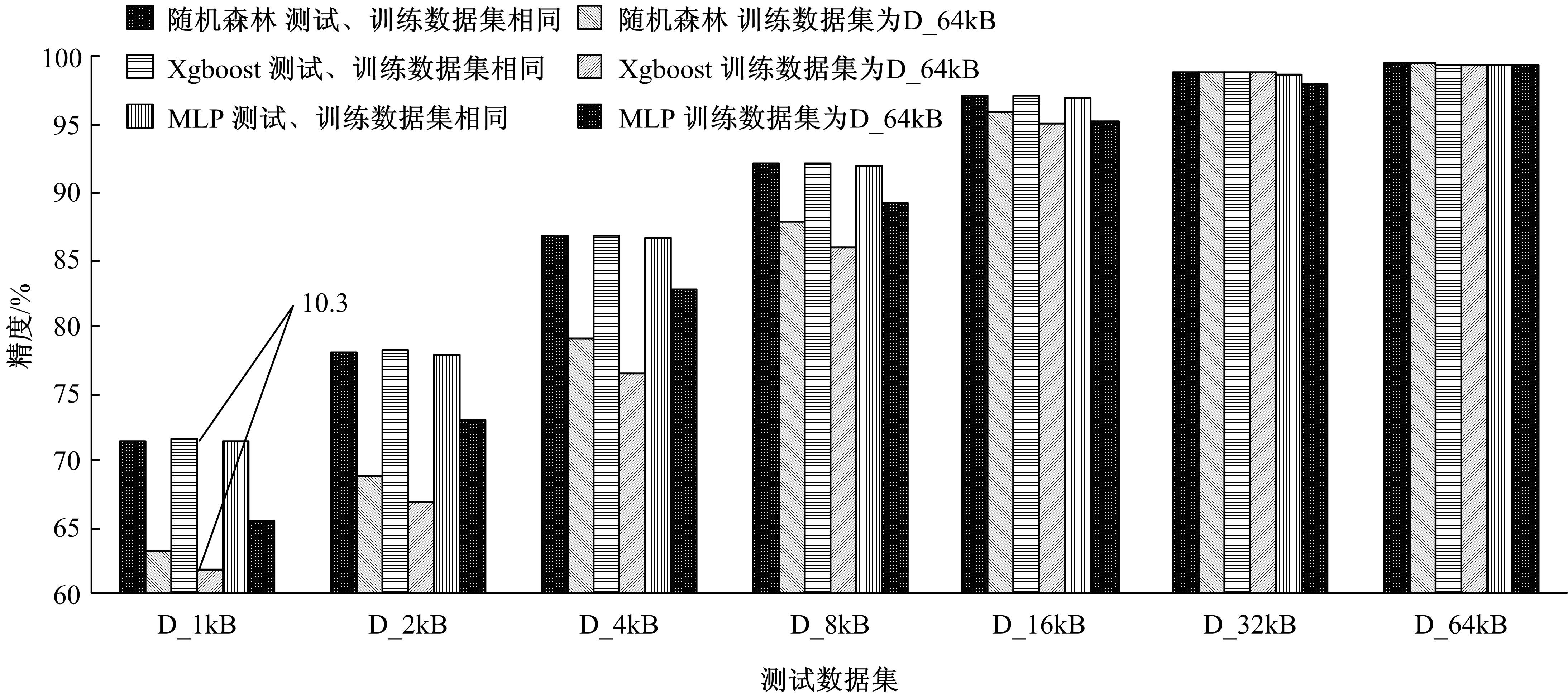
当网络传输数据应用加密或压缩算法后,其载荷数据均呈现出较强的随机性,利用现有的流量检测方法,很难将加密和压缩流量有效区分。针对上述问题,基于加密数据与压缩数据随机性的差异性特征,提出了ECF特征集,在不依赖网络传输协议、数据包头、压缩标识等信息的情况下,使用当前主流机器学习算法构建分类模型,实现了有效的加密和压缩流量分类。实验测试表明,本文方法在分类精度上优于现有分类方法,并且具有很好的泛化性和迁移性。
中图分类号:
- TP309.7










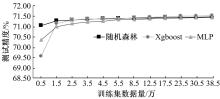
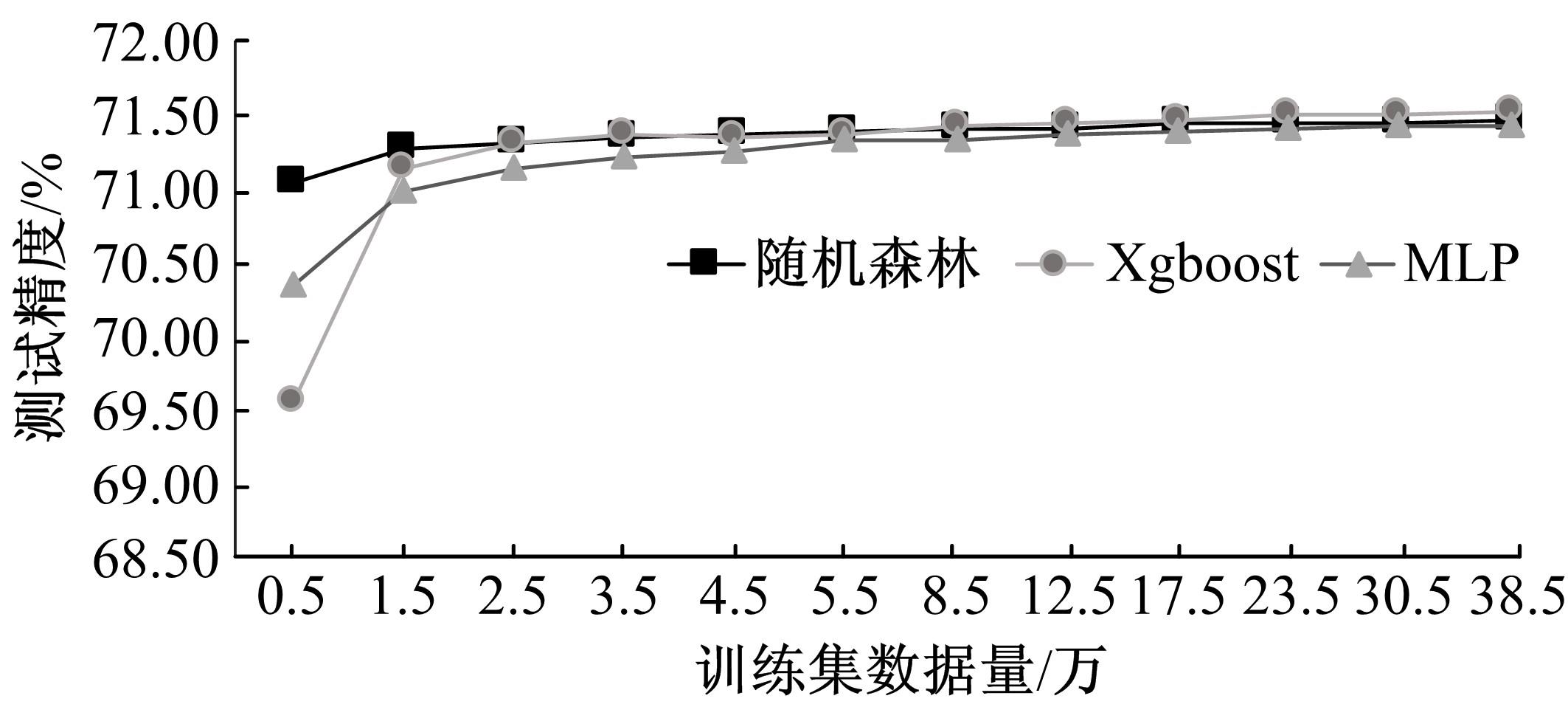
| 1 | 王勇, 周慧怡, 俸皓,等. 基于深度卷积神经网络的网络流量分类方法[J]. 通信学报,2018, 39(1):14-23. |
| Wang Yong, Zhou Hui-yi, Feng Hao, et al. Network traffic classification method basing on CNN[J]. Journal on Communications, 2018, 39(1):14-23. | |
| 2 | Sandvine. 2018 Global Internet Phenomena Report[R]. Ontario Canda: Sandvine Incorporated ULC Waterloo, 2018. |
| 3 | 潘吴斌, 程光, 郭晓军, 等. 网络加密流量识别研究综述及展望[J]. 通信学报, 2016, 37(9):154-167. |
| Pan Wu-bin, Cheng Guang, Guo Xiao-jun, et al. Review and perspective on encrypted traffic identification research[J]. Journal on Communications, 2016, 37(9):154-167. | |
| 4 | Dorfinger P, Panholzer G, John W. Entropy estimation for real-time encrypted traffic identification (short paper)[C]∥International Workshop on Traffic Monitoring and Analysis, Berlin,Germany,2011: 164-171. |
| 5 | 朱玉娜, 韩继红, 袁霖, 等. 基于熵估计的安全协议密文域识别方法[J]. 电子与信息学报, 2016, 38(8): 1865-1871. |
| Zhu Yu-na, Han Ji-hong, Yuan Lin, et al. Protocol Ciphertext Field Identification by Entropy Estimating[J]. Journal of Electronics & Information Technology, 2016, 38(8): 1865-1871. | |
| 6 | 赵博, 郭虹, 刘勤让, 等. 基于加权累积和检验的加密流量盲识别算法[J]. 软件学报, 2013, 24(6): 1334-1345. |
| Zhao Bo, Guo Hong, Liu Qin-rang, et al. Protocol independent identification of encrypted traffic based on weighted eumnlative sum test[J]. Journal of Software, 2013, 24(6): 1334-1345. | |
| 7 | King T, D'Agostino R B, Stephens M A. Goodness-of-fit techniques[J]. Journal of Educational Statistics, 1987, 12(4):412-416. |
| 8 | Shannon C E. Communication Theory of Secrecy Systems[J]. The Bell System Technical Journal, 1949, 28(4):656-715. |
| 9 | Malhotra P. Detection of encrypted streams for egress monitoring[D]. Malhotra, Paras:Iowa State University, 2007. |
| 10 | Conte T M, Wolfe A. Techniques for detecting encrypted data[P]. US:8799671,2014-08-05. |
| 11 | Hahn D, Apthorpe N, Feamster N. Detecting compressed cleartext traffic from consumer internet of things devices[J]. arXiv preprint arXiv:, 2018. |
| 12 | Casino F, Choo K K R, Patsakis C. HEDGE: efficient traffic classification of encrypted and compressed packets[J]. IEEE Transactions on Information Forensics and Security, 2019, 14(11): 2916-2926. |
| 13 | Wang R, Shoshitaishvili Y, Kruegel C, et al. Steal this movie: automatically bypassing DRM protection in streaming media services[C]∥ Proceedings of the 22nd USENIX conference on Security, Berkeley,USA,2013: 687-702. |
| 14 | Wang Y, Zhang Z, Guo L, et al. Using entropy to classify traffic more deeply[C]∥IEEE Sixth International Conference on Networking, Architecture, and Storage, Dalian, China, 2011: 45-52. |
| 15 | Khakpour A R, Liu A X. An information-theoretical approach to high-speed flow nature identification[J]. IEEE/ACM Transactions on Networking (TON), 2013, 21(4): 1076-1089. |
| 16 | 雷博, 范九伦. 一维Renyi熵阈值法中参数的自适应选取[J]. 光子学报, 2009, 38(9):2439-2443. |
| Lei Bo, Fan Jiu-lun. Self-adaptation preferences in one-dimensional Renyi entropy thresholding[J]. Acta Photonica Sinica, 2009, 38(9): 2439-2443. | |
| 17 | Rukhin A L, Soto J, Nechvatal J R, et al. SP 800-22 Rev. 1a. A statistical test suite for random and pseudorandom number generators for cryptographic applications[S]. National Institute of Standards and Technology,USA,2010-09-16. |
| 18 | 周志华. 机器学习[M]. 北京:清华大学出版社, 2016. |
| 19 | 石竑松, 张翀斌, 杨永生,等. 随机性检测及其片面性[J]. 清华大学学报:自然科学版, 2011, 51(10):1269-1273. |
| Shi Hong-song, Zhang Chong-bin,Yang Yong-sheng, et al. On randomness test and its incompleteness[J]. Journal of Tsinghua University(Science and Technology), 2011,51(10):1269-1273. |
| [1] | 朱小龙,谢忠. 基于机器学习的地理空间数据抽取算法[J]. 吉林大学学报(工学版), 2021, 51(3): 1011-1016. |
| [2] | 李阳,李硕,井丽巍. 基于贝叶斯模型与机器学习算法的金融风险网络评估模型[J]. 吉林大学学报(工学版), 2020, 50(5): 1862-1869. |
| [3] | 方伟,黄羿,马新强. 基于机器学习的虚拟网络感知数据缺陷自动检测[J]. 吉林大学学报(工学版), 2020, 50(5): 1844-1849. |
| [4] | 刘洲洲,尹文晓,张倩昀,彭寒. 基于离散优化算法和机器学习的传感云入侵检测[J]. 吉林大学学报(工学版), 2020, 50(2): 692-702. |
| [5] | 赵东, 臧雪柏, 赵宏伟. 基于果蝇优化的随机森林预测方法[J]. 吉林大学学报(工学版), 2017, 47(2): 609-614. |
| [6] | 夏靖波, 柏骏, 赵小欢, 吴吉祥. 基于相关向量机的在线网络流量分类方法[J]. 吉林大学学报(工学版), 2014, 44(2): 459-464. |
| [7] | 吴旗, 刘健男, 寇文龙, 张宗升. 改进的单类支持向量机的网络流量检测[J]. 吉林大学学报(工学版), 2013, 43(增刊1): 124-127. |
| [8] | 涂威威, 黎铭, 周志华. 软件缺陷因素挖掘[J]. 吉林大学学报(工学版), 2012, 42(增刊1): 382-386. |
| [9] | 刘元宁, 沈廷杰, 张浩, 李鑫, 魏庆凯, 赫羽喆. microRNA靶基因特征提取新方法[J]. 吉林大学学报(工学版), 2012, 42(02): 418-422. |
| [10] | 郭孔辉, 王先云. 基于支持向量机回归的减振器非参数模型[J]. 吉林大学学报(工学版), 2011, 41(增刊1): 1-4. |
| [11] | 倪萍,廖建新,朱晓民,. 一种不需协商的业务等级协商测量方法[J]. 吉林大学学报(工学版), 2011, 41(01): 264-0269. |
|
||