Journal of Jilin University(Engineering and Technology Edition) ›› 2026, Vol. 56 ›› Issue (2): 516-522.doi: 10.13229/j.cnki.jdxbgxb.20240251
Video captioning method based on enhanced object learning and attention networks
Xiao-dong CAI( ),Shun-hong LONG,Kun-jun LIANG
),Shun-hong LONG,Kun-jun LIANG
- School of Information and Communication,Guilin University of Electronic Technology,Guilin 541004,China
CLC Number:
- TP391
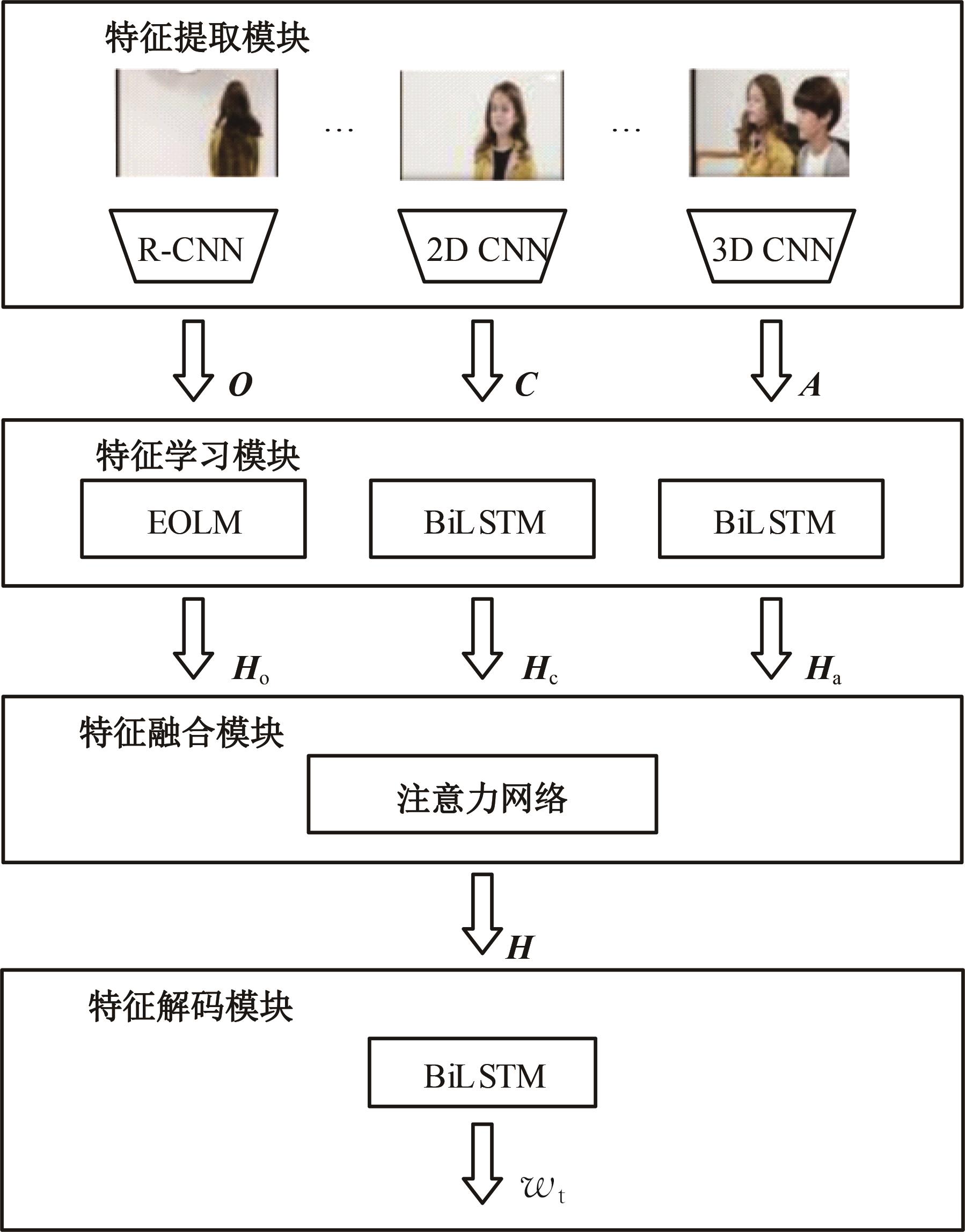
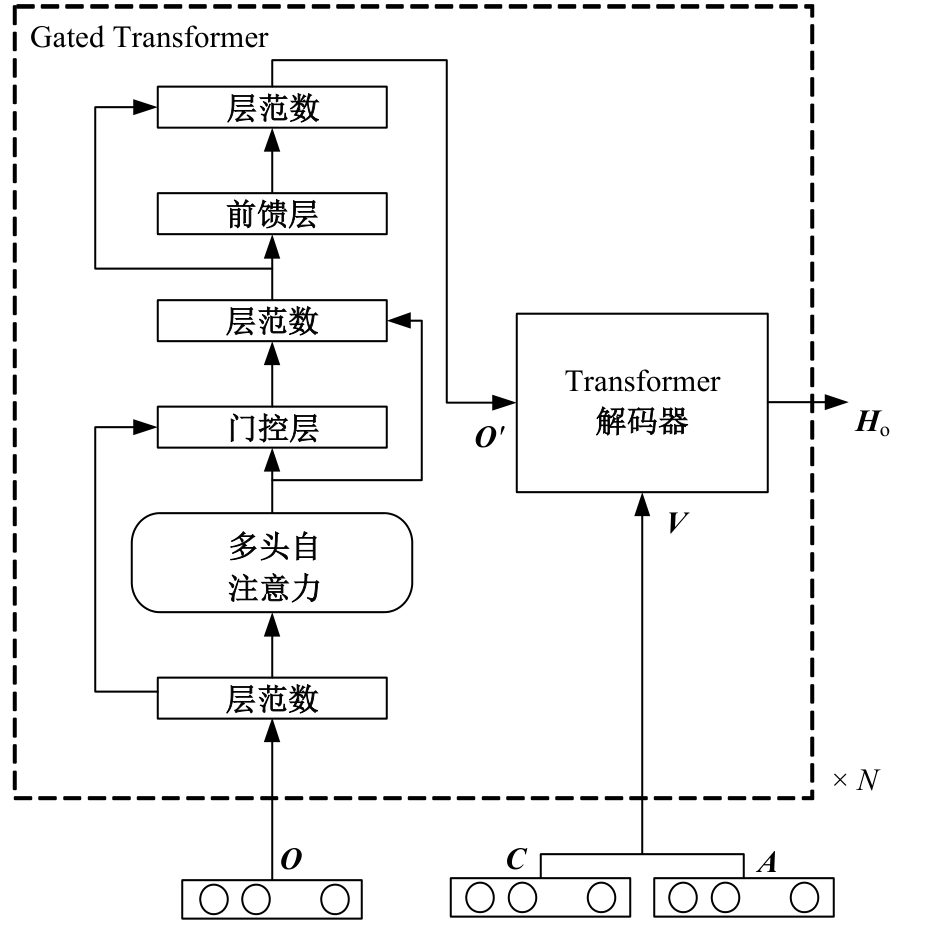
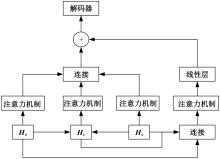
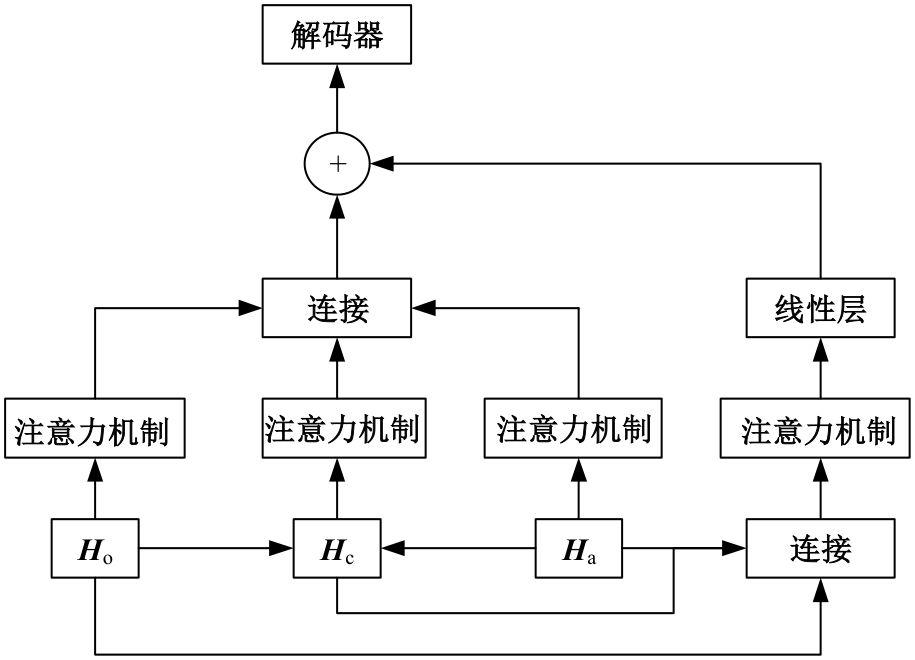


| [1] | Zhang J, Peng Y. Video captioning with object-aware spatio-temporal correlation and aggregation[J]. IEEE Transactions on Image Processing, 2020, 29: 6209-6222. |
| [2] | Zanfir M, Marinoiu E, Sminchisescu C. Spatio-temporal attention models for grounded video captioning[C]∥Computer Vision-ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 2017: 104-119. |
| [3] | Yang Z, Han Y, Wang Z. Catching the temporal regions-of-interest for video captioning[C]∥Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, USA, 2017: 146-153. |
| [4] | Zhang W, Wang X E, Tang S, et al. Relational graph learning for grounded video description generation[C]∥Proceedings of the 28th ACM International Conference on Multimedia, Seattle, USA, 2020: 3807-3828. |
| [5] | Zhang Z, Shi Y, Yuan C, et al. Object relational graph with teacher-recommended learning for video captioning[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 13278-13288. |
| [6] | Kanani C S, Saha S, Bhattacharyya P. Global object proposals for improving multi-sentence video descriptions[C]∥International Joint Conference on Neural Network, Montreal, Canada, 2021: 1-7. |
| [7] | Parisotto E, Song F, Rae J, et al. Stabilizing transformers for reinforcement learning[C]∥International Conference on Machine Learning, Vienna, Austria, 2020: 7487-7498. |
| [8] | Ye H, Li G, Qi Y, et al. Hierarchical modular network for video captioning[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 17939-17948. |
| [9] | Lin K, Li L, Lin C C, et al. SwinBERT: end-to-end transformers with sparse attention for video captioning[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 17949-17958. |
| [10] | Gu X, Chen G, Wang Y, et al. Text with knowledge graph augmented transformer for video captioning[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, USA, 2023: 18941-18951. |
| [11] | Jing S, Zhang H, Zeng P, et al. Memory-based augmentation network for video captioning[J]. IEEE Transactions on Multimedia, 2023, 26: 2367-2379. |
| [12] | Shen Y, Gu X, Xu K, et al. Accurate and fast compressed video captioning[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 15558-15567. |
| [13] | Wang J, Jiang W, Ma L, et al. Bidirectional attentive fusion with context gating for dense video captioning[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7190-7198. |
| [14] | Wang B, Ma L, Zhang W, et al. Controllable video captioning with pos sequence guidance based on gated fusion network[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 2641-2650. |
| [15] | Li L, Gao X, Deng J, et al. Long short-term relation transformer with global gating for video captioning[J]. IEEE Transactions on Image Processing, 2022, 31: 2726-2738. |
| [16] | Xu J, Yao T, Zhang Y, et al. Learning multimodal attention LSTM networks for video captioning[C]∥Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, USA, 2017: 537-545. |
| [17] | Sun Z, Chen S, Zhong L. Visual-aware attention dual-stream decoder for video captioning[C]∥IEEE International Conference on Multimedia and Expo, Taipei, Taiwan, 2022: 1-6. |
| [1] | Zong-wei YAO,Chen CHEN,Zhen-yun GAO,Hong-peng JIN,Hao RONG,Xue-fei LI,Hong-pu HUANG,Qiu-shi BI. Visual recognition of excavator keypoints based on synthetic image datasets [J]. Journal of Jilin University(Engineering and Technology Edition), 2026, 56(1): 76-85. |
| [2] | Lin-hong WANG,Yu-yang LIU,Zi-yu LIU,Ying-jia LU,Yu-heng ZHANG,Gui-shu HUANG. Defect recognition of lightweight bridges based on YOLOv5 [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(9): 2958-2968. |
| [3] | Jing LIAN,Ji-bao ZHANG,Ji-zhao LIU,Jia-jun ZHANG,Zi-long DONG. Text-based guided face image inpainting [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2732-2740. |
| [4] | Yuan-ning LIU,Xing-zhe WANG,Zi-yu HUANG,Jia-chen ZHANG,Zhen LIU. Stomach cancer survival prediction model based on multimodal data fusion [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2693-2702. |
| [5] | Jing-shu YUAN,Wu LI,Xing-yu ZHAO,Man YUAN. Semantic matching model based on BERTGAT-Contrastive [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(7): 2383-2392. |
| [6] | Hui-zhi XU,Dong-sheng HAO,Xiao-ting XU,Shi-sen JIANG. Expressway small object detection algorithm based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 2003-2014. |
| [7] | Ru-bo ZHANG,Shi-qi CHANG,Tian-yi ZHANG. Review on image information hiding methods based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1497-1515. |
| [8] | Jian LI,Huan LIU,Yan-qiu LI,Hai-rui WANG,Lu GUAN,Chang-yi LIAO. Image recognition research on optimizing ResNet-18 model based on THGS algorithm [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1629-1637. |
| [9] | Bin WEN,Yi-fu DING,Chao YANG,Yan-jun SHEN,Hui LI. Self-selected architecture network for traffic sign classification [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1705-1713. |
| [10] | Zhen-jiang LI,Li WAN,Shi-rui ZHOU,Chu-qing TAO,Wei WEI. Dynamic estimation of operational risk of tunnel traffic flow based on spatial-temporal Transformer network [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(4): 1336-1345. |
| [11] | Meng-xue ZHAO,Xiang-jiu CHE,Huan XU,Quan-le LIU. A method for generating proposals of medical image based on prior knowledge optimization [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 722-730. |
| [12] | Hu JIN,Yu-sheng SHEN,Yong FANG,Li YU,Jia-mei ZHOU. Identification of small cracks in highway tunnel lining based on deep learning SSD algorithm [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(11): 3653-3659. |
| [13] | Xiao-Dong CAI,Ye-yang HUANG,Li-fang DONG. Semantic similarity model based on augmented positives and interlayer negatives [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(11): 3705-3714. |
| [14] | Lai-wei JIANG,Ce WANG,Hong-yu YANG. Review of multi-object tracking based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(11): 3429-3445. |
| [15] | Wei WANG,Yu-jie SUN,Xin WANG. Lightweight frequency and spatial feature fused multi-scale remote sensing scene classification network [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(10): 3361-3371. |
|
||