Journal of Jilin University(Engineering and Technology Edition) ›› 2026, Vol. 56 ›› Issue (2): 523-532.doi: 10.13229/j.cnki.jdxbgxb.20240748
A bidirectional feature fusion method for object position estimation
Jun MIAO1,2( ),Jie YAN1,Rong-hua DU1(),Lei LI3,Jun CHU3
),Jie YAN1,Rong-hua DU1(),Lei LI3,Jun CHU3
- 1.School of Aeronautical Manufacturing and Mechanical Engineering,Nanchang Hangkong University,Nanchang 330063,China
2.Key Laboratory of Lunar and Deep Space Exploration,CAS,Beijing 100190,China
3.Institute of Computer Vision,Nanchang Hangkong University,Nanchang 330063,China
CLC Number:
- TP391.41
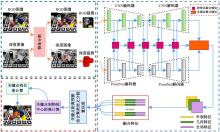
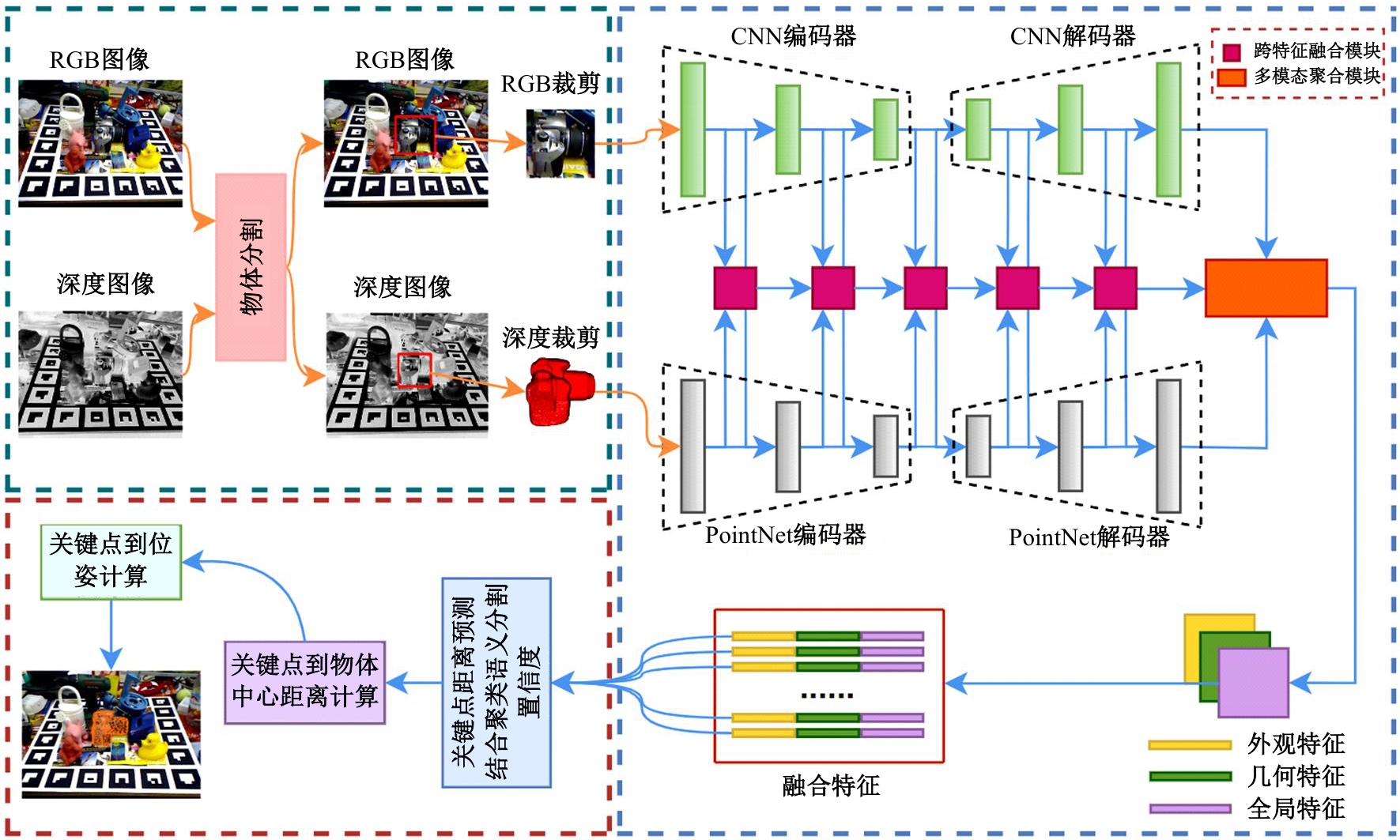
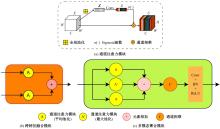
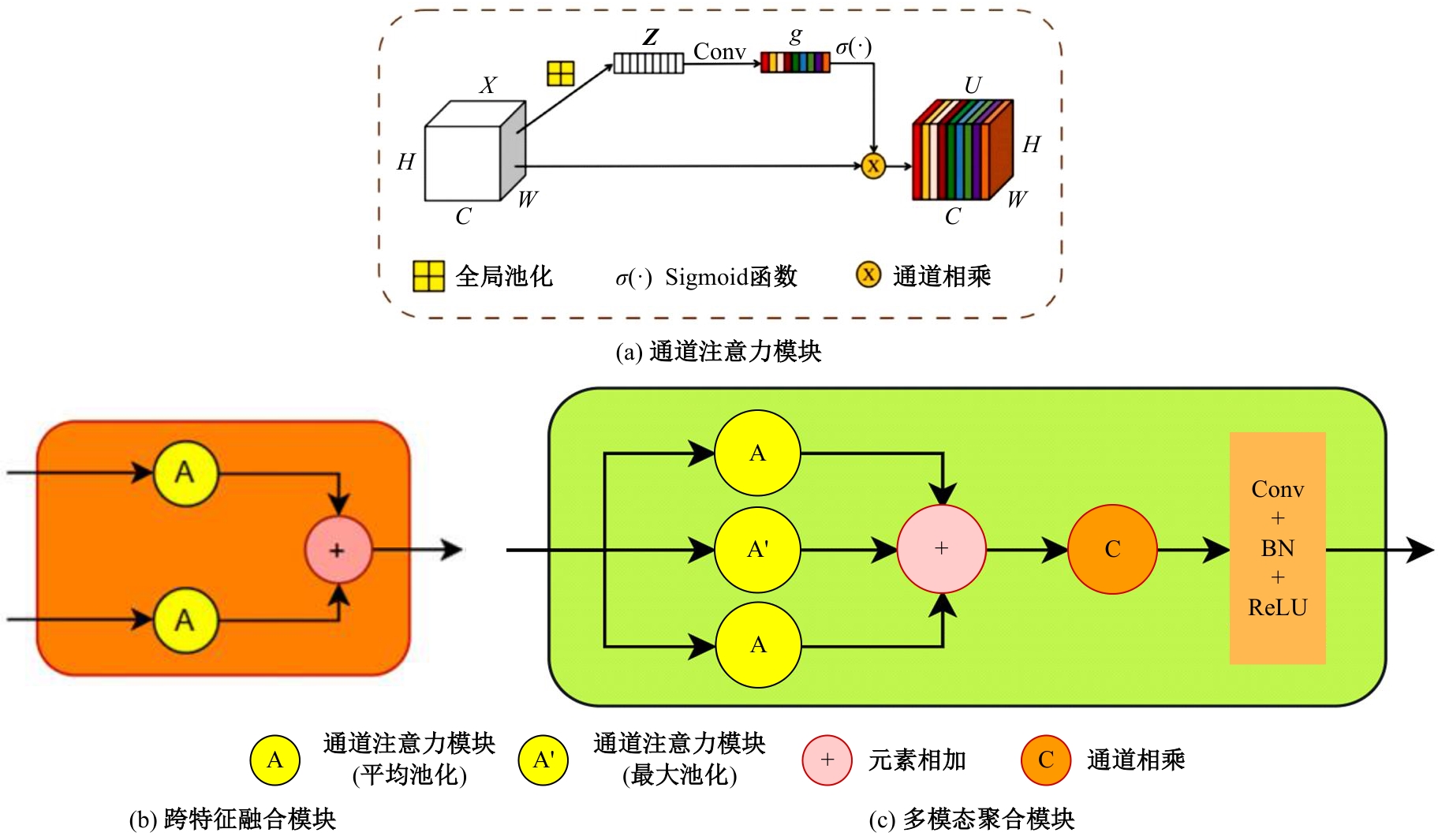
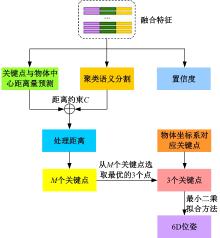
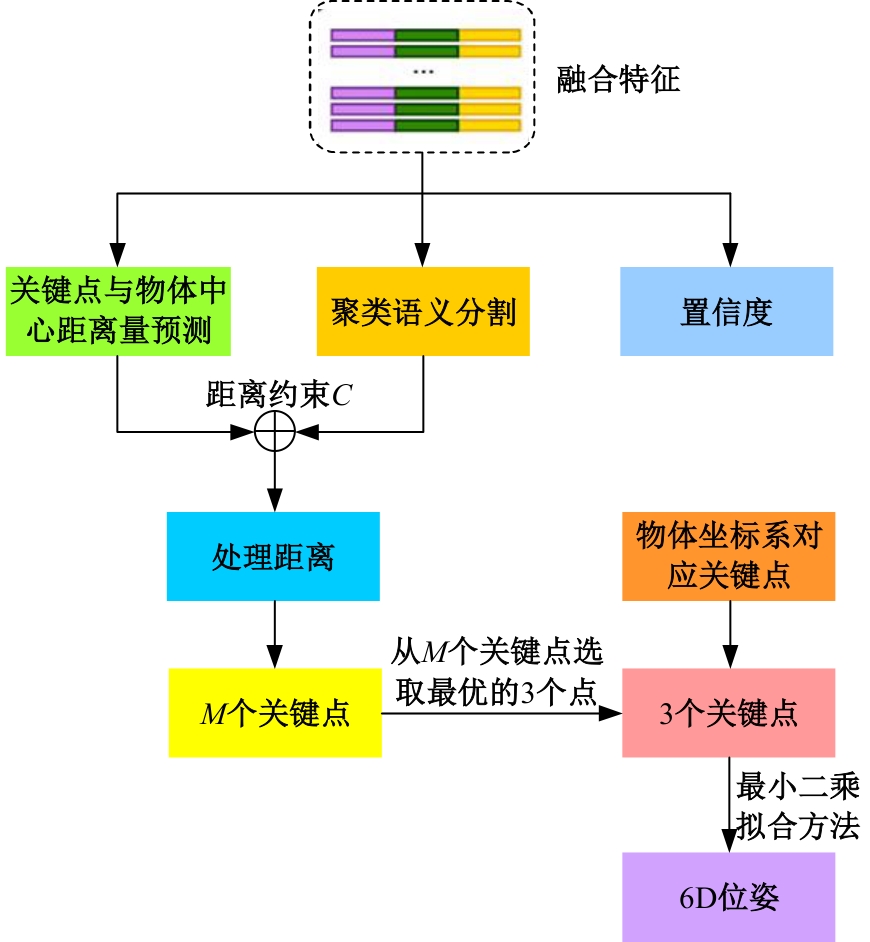




| [1] | Guan J, Hao Y M, Wu Q X, et al. A survey of 6DoF object pose estimation methods for different application scenarios[J]. Sensors, 2024, 24(4): 1076. |
| [2] | Marullo G, Tanzi L, Piazzolla P, et al. 6D object position estimation from 2D images: A literature review[J]. Multimedia Tools and Applications, 2023, 82(16): 24605-24643. |
| [3] | 王静, 金玉楚, 郭苹, 等. 基于深度学习的相机位姿估计方法综述[J]. 计算机工程与应用, 2023, 59(7): 1-14. |
| Wang Jing, Jin Yu-chu, Guo Ping, et al. A review of camera pose estimation methods based on deep learning[J]. Computer Engineering and Applications, 2023, 59(7): 1-14. | |
| [4] | Wang C, Xu D E, Zhu Y K, et al. Dense Fusion: 6D object pose estimation by iterative dense fusion[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE,2019: 3343-3352. |
| [5] | He Y S, Huang H B, Fan H Q, et al. FB6D: A full flow bidirectional fusion network for 6D pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEEE, 2021: 3003-3013. |
| [6] | Peng S D, Liu Y, Huang Q X, et al. PVNet: Pixel-wise voting network for 6DoF pose estimation[J]. Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(6): 3212-3223. |
| [7] | Lin S F, Wang Z R, Ling Y G, et al. E2EK: End-to-end regression network based on keypoint for 6D pose estimation[J]. IEEE Robotics and Automation Letters, 2022, 7(3): 6526-6533. |
| [8] | Xiang Y, Schmidt T, Narayanan V, et al. Pose CNN: A convolutional neural network for 6D object pose estimation in cluttered scenes[J]. ArXiv Preprint, 2017, 11: 171100199. |
| [9] | Zakharov S, Shugurov I, Ilic S. DPOD: 6D pose object detector and refiner[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE, 2019: 1941-1950. |
| [10] | 王连明, 吴鑫. 基于姿态估计的物体 3D 运动参数测量方法[J]. 吉林大学学报:工学版, 2023, 53(7): 2099-2108. |
| Wang Lian-ming, Wu Xin. Measurement of 3D motion parameters of an object based on attitude estimation[J]. Journal of Jilin University (Engineering and Technology Edition), 2023, 53(7): 2099-2108. | |
| [11] | Ding Z F, Sun Y X, Xu S J, et al. Recent advances and perspectives in deep learning techniques for 3D point cloud data processing[J]. Robotics, 2023, 12(4): 100. |
| [12] | Zhou J, Chen K, Xu L L, et al. Deep fusion transformer network with weighted vector-wise keypoints voting for robust 6D object pose estimation[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE, 2023: 13967-13977. |
| [13] | 白琳, 刘林军, 李轩昂, 等. 基于自监督学习的单目图像深度估计算法[J]. 吉林大学学报:工学版, 2023, 53(4): 1139-1145. |
| Bai Lin, Liu Lin-jun, Li Xuan-ang, et al. A depth estimation algorithm for monocular images based on self-supervised learning[J]. Journal of Jilin University (Engineering and Technology Edition), 2023, 53(4): 1139-1145. | |
| [14] | Song C, Song J R, Huang Q X. HybridPose: 6D object pose estimation under hybrid representations[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2020: 431-440. |
| [15] | 张宸嘉, 朱磊, 俞璐. 卷积神经网络中的注意力机制综述[J]. 计算机工程与应用学报, 2021, 57(20):64-72. |
| Zhang Chen-jia, Zhu Lei, Yu Lu. A review of attention mechanisms in convolutional neural networks[J]. Journal of Computer Engineering & Applications, 2021, 57(20):64-72. | |
| [16] | Hinterstoisser S, Lepetit V, Ilic S, et al. Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes[C]∥Computer Vision-ACCV 2012: 11th Asian Conference on Computer Vision. Piscataway, NJ: IEEE, 2013: 548-562. |
| [17] | Calli B, Singh A, Walsman A, et al. The YCB object and model set: Towards common benchmarks for manipulation research[C]∥ International Conference on Advanced Robotics. Piscataway, NJ: IEEE, 2015: 510-517. |
| [1] | Qiu-zhan ZHOU,Xin-meng LI,Hao-qing-zi SHEN,Hui-nan WU,Yuan-yuan LI,Jing RONG,Chun-hua HU,Ping-ping LIU. Non-intrusive load decomposition of unbalanced data based on attention mechanism [J]. Journal of Jilin University(Engineering and Technology Edition), 2026, 56(1): 239-246. |
| [2] | Zhi-gang FENG,Meng-yuan REN,Bing DONG,Ming-yue YU. Rolling bearing fault diagnosis based on multi-band feature map and improved SqueezeNet [J]. Journal of Jilin University(Engineering and Technology Edition), 2026, 56(1): 96-108. |
| [3] | Zhen HUO,Li-sheng JIN,Qiang HUA, HEYang. Edge feature⁃guided semantic segmentation method for intelligent vehicle [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(9): 3032-3041. |
| [4] | Qing-lin AI,Yuan-xiao LIU,Jia-hao YANG. Small target swmantic segmentation method based MFF-STDC network in complex outdoor environments [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2681-2692. |
| [5] | Yan PIAO,Ji-yuan KANG. RAUGAN:infrared image colorization method based on cycle generative adversarial networks [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2722-2731. |
| [6] | Shan-na ZHUANG,Jun-shuai WANG,Jing BAI,Jing-jin DU,Zheng-you WANG. Video-based person re-identification based on three-dimensional convolution and self-attention mechanism [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(7): 2409-2417. |
| [7] | Zhi-gang FENG,Shou-qi WANG,Ming-yue YU. Rolling bearing fault diagnosis based on variational mode extraction and lightweight network [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 1883-1891. |
| [8] | Ya-li XUE,Tong-an YU,Shan CUI,Li-zun ZHOU. Infrared small target detection based on cascaded nested U-Net [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1714-1721. |
| [9] | Hua CAI,Yu-yao WANG,Qiang FU,Zhi-yong MA,Wei-gang WANG,Chen-jie ZHANG. Semantic segmentation network based on attention mechanism and feature fusion [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(4): 1384-1395. |
| [10] | He-shan ZHANG,Meng-wei FAN,Xin TAN,Zhan-ji ZHENG,Li-ming KOU,Jin XU. Dense small object vehicle detection in UAV aerial images using improved YOLOX [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(4): 1307-1318. |
| [11] | Yang LI,Xian-guo LI,Chang-yun MIAO,Sheng XU. Low⁃light image enhancement algorithm based on dual branch channel prior and Retinex [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 1028-1036. |
| [12] | Xiang WANG,Guo-zhen TAN,Yan-fei PENG,Hao REN,Jian-ping LI. Autonomous driving decision⁃making model based on language reasoning and cognitive memory [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(12): 3918-3927. |
| [13] | Yun-hong LI,Mei WANG,Xue-ping SU,Li-min LI,Fu-xing ZHANG,Te-ji HAO. Road extraction from remote sensing images combining attention and context fusion [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(12): 4034-4044. |
| [14] | Duo PENG,Ming-shuo LIU,Kun XIE. Observation station parameter error joint multi-feature fusion attention mechanism TDOA/FDOA multi-aircraft passive localization algorithm [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(11): 3751-3761. |
| [15] | Ming-hui SUN,Jing-yuan BIAN,Jia-xing CHE,Zhen-jie SHU. Trajectory prediction and interception algorithm for large maneuvering multi-rotor UAV [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(10): 3416-3422. |
|
||