Journal of Jilin University(Engineering and Technology Edition) ›› 2025, Vol. 55 ›› Issue (7): 2409-2417.doi: 10.13229/j.cnki.jdxbgxb.20230881
Video-based person re-identification based on three-dimensional convolution and self-attention mechanism
Shan-na ZHUANG1,2( ),Jun-shuai WANG1,2,Jing BAI1,2(),Jing-jin DU1,2,Zheng-you WANG1,2
),Jun-shuai WANG1,2,Jing BAI1,2(),Jing-jin DU1,2,Zheng-you WANG1,2
- 1.School of Information Science and Technology,Shijiazhuang Tiedao University,Shijiazhuang 050043,China
2.Hebei Provincial Key Laboratory of Electromagnetic Environmental Effects and Information Processing,Shijiazhuang 050043,China
CLC Number:
- TP391.4
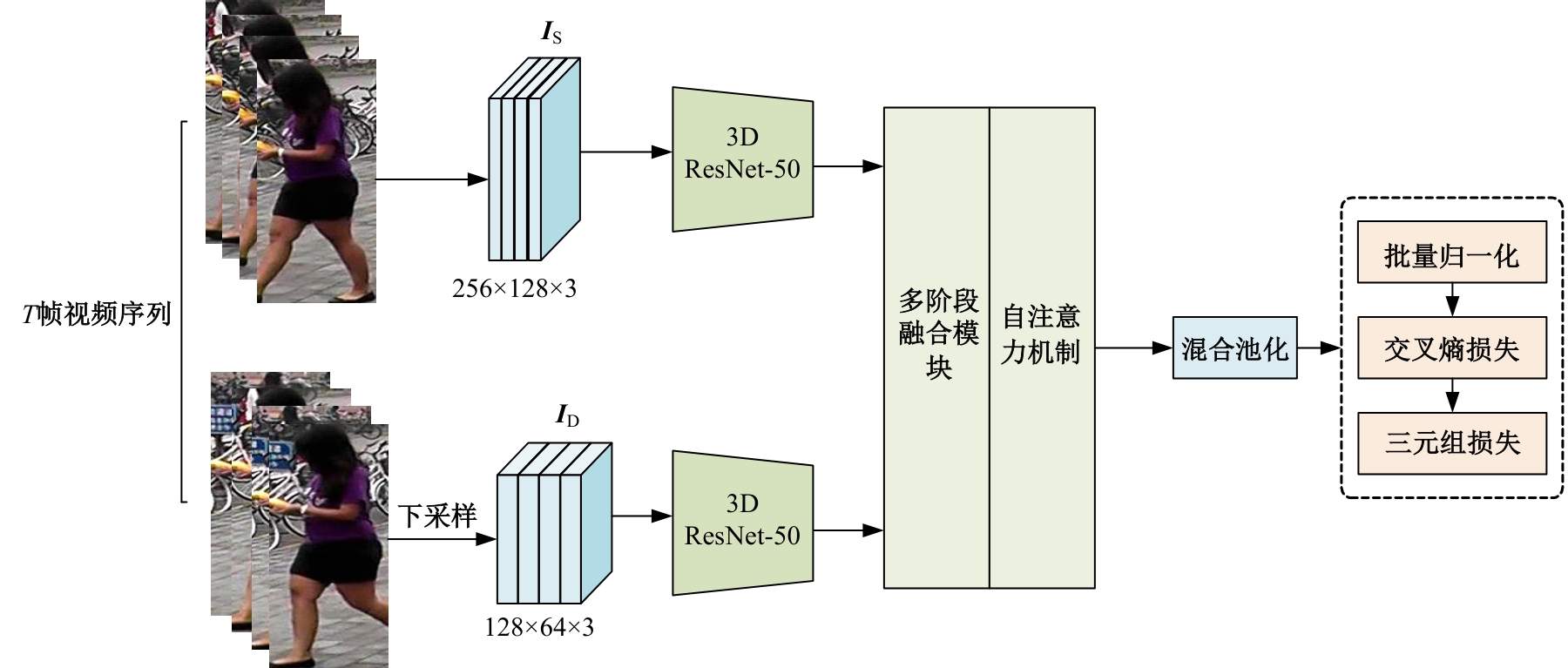
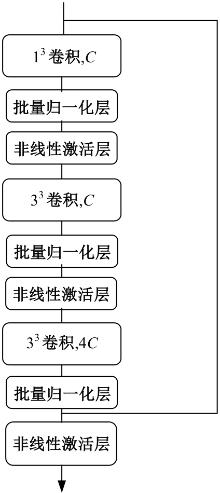
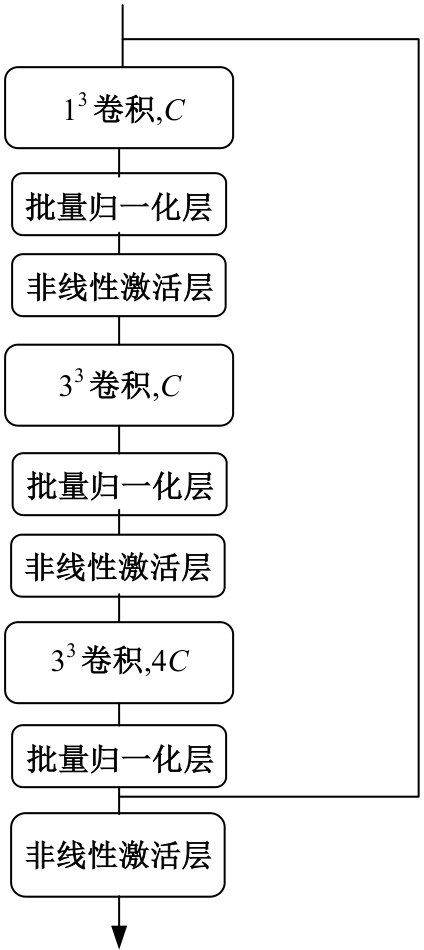
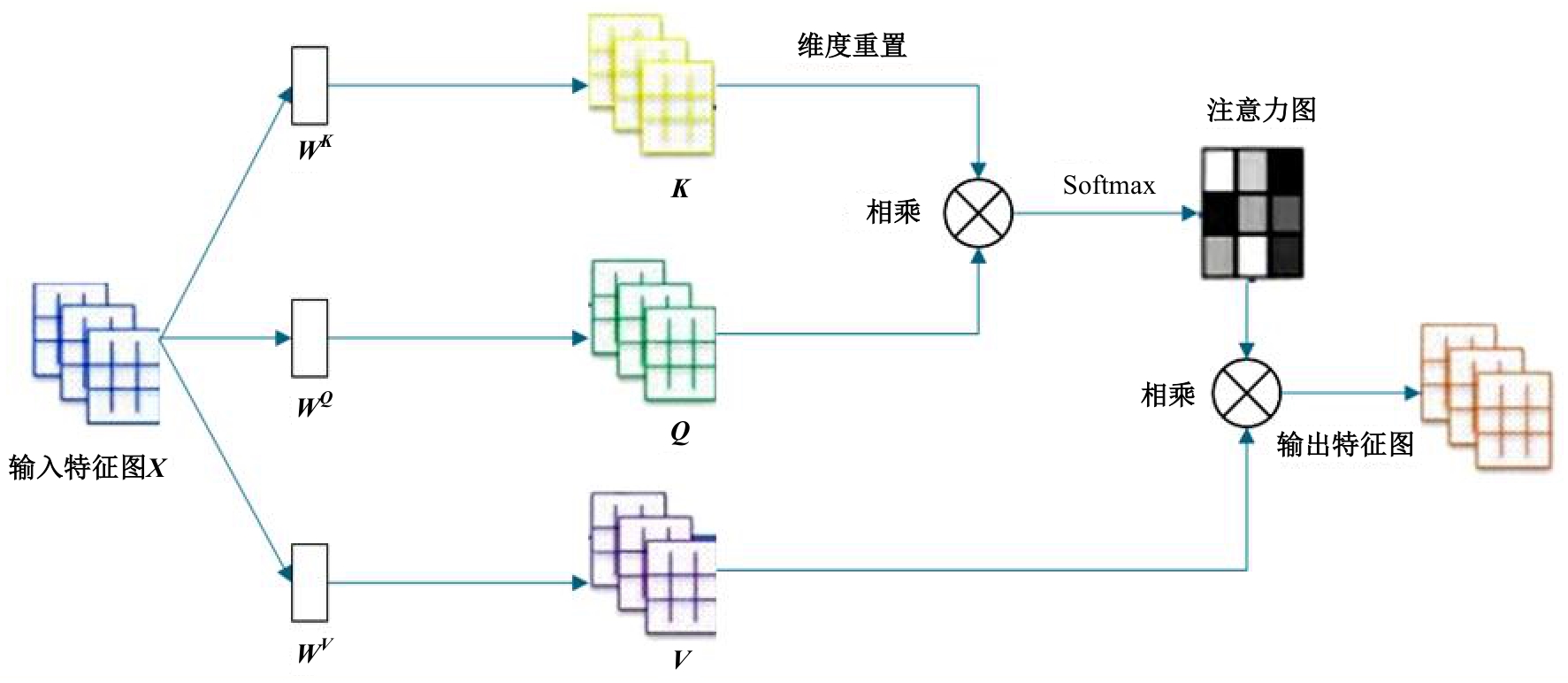
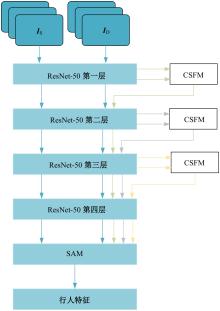
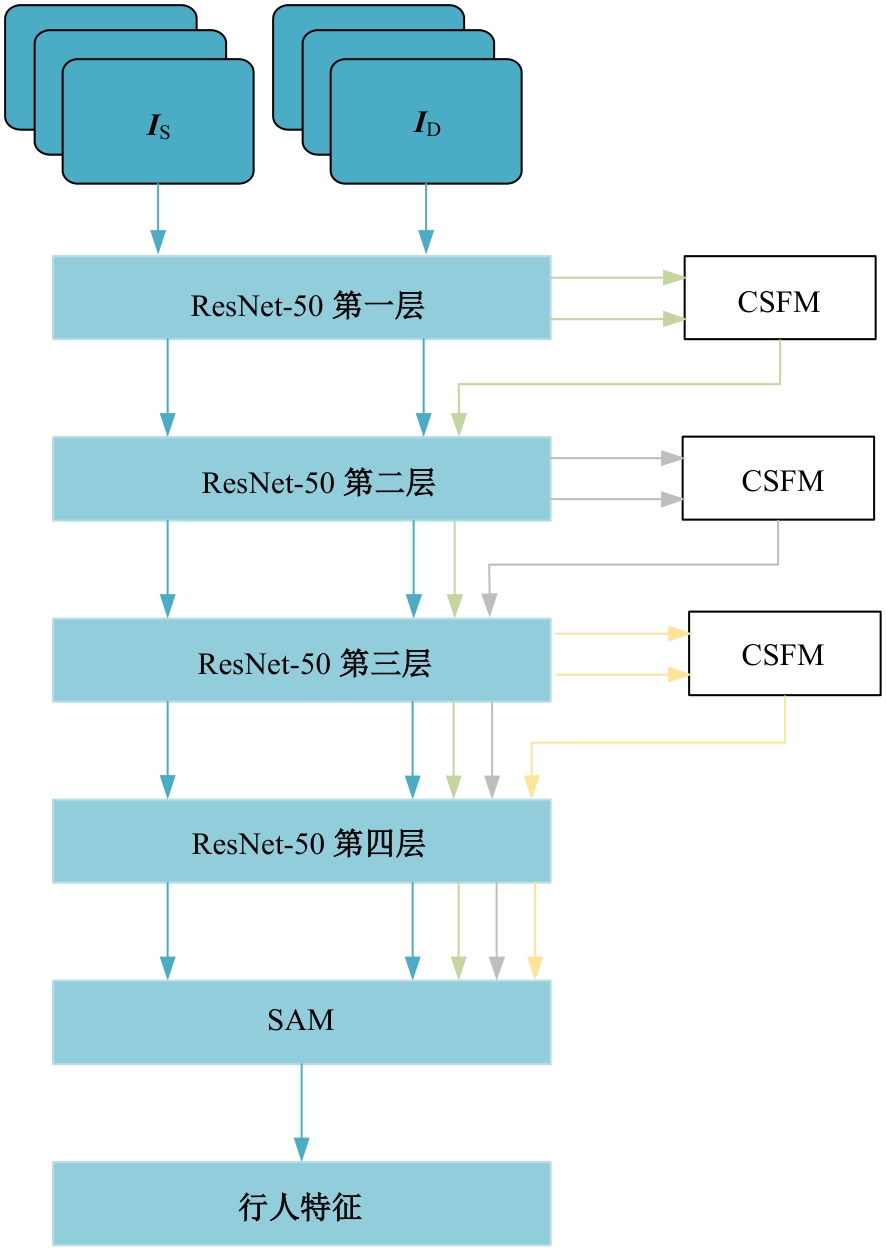
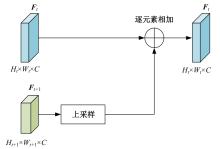
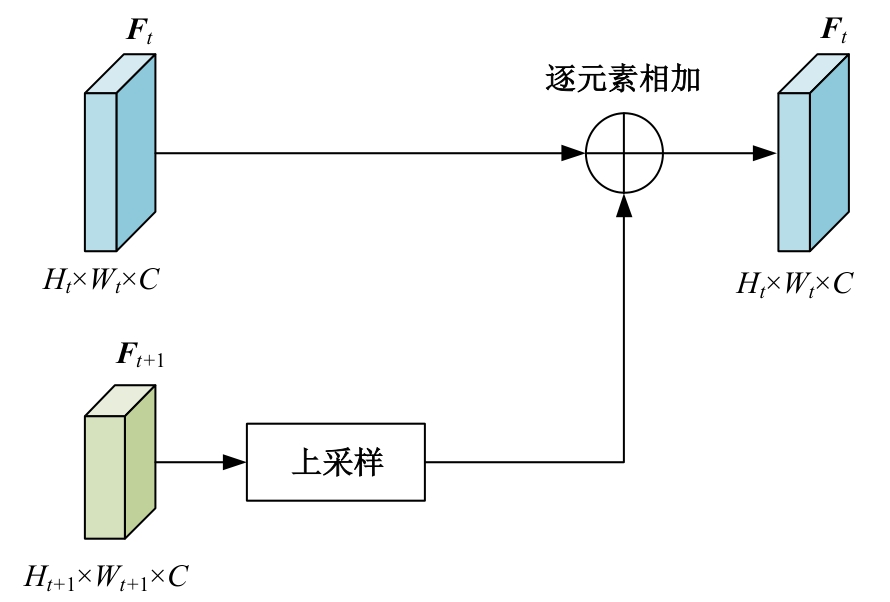
| [1] | 于鹏, 朴燕. 基于多尺度特征的行人重识别属性提取新方法[J]. 吉林大学学报: 工学版, 2023, 53(4): 1155-1162. |
| Yu Peng, Yan Piao. New method for extracting person re-identification attributes based on multi-scale features[J]. Journal of Jilin University (Engineering and Technology Edition), 2023, 53(4): 1155-1162. | |
| [2] | Isobe T, Han J, Zhuz F, et al. Intra-clip aggregation for video person re-identification[C]∥Proceeding of the IEEE International Conference on Image Processing (ICIP). Piscatanay, NJ: IEEE, 2020: 2336-2340. |
| [3] | Li X, Zhou W, Zhou Y, et al. Relation-guided spatialattention and temporal refinement for video-based person re-identification[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11434-11441. |
| [4] | Hou R, Chang H, Ma B, et al. Temporal complementary learning for video person re-identification[C]∥The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 388-405. |
| [5] | Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[C]∥Proceeding of the 53rd Annual Meeting of the Association for Computation Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 2015: 1556-1566. |
| [6] | Carreira J, Zisserman A. Quo vadis, action recogniti-on? A new model and the kinetics dataset[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii,USA,2017: 6299-6308. |
| [7] | Li J, Zhang S, Huang T. Multi-scale 3d convolution network for video based person re-identification[C]∥Proceedings of the AAAI Conference on Artificial Int-elligence, Hawaii,USA, 2019, 33(1): 8618-8625. |
| [8] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, Los Angeles,USA, 2017: 30-38. |
| [9] | 侯春萍, 杨庆元, 黄美艳, 等. 基于语义耦合和身份一致性的跨模态行人重识别方法[J]. 吉林大学学报:工学版, 2022, 52(12): 2954-2963. |
| Hou Chun-ping, Yang Qing-yuan, Huang Mei-yan, et al. Cross⁃modality person re⁃identification based on semantic coupling and identity⁃consistence constraint[J]. Journal of Jilin University (Engineering and Technology Edition), 2022, 52(12): 2954-2963. | |
| [10] | Zheng L, Bie Z, Sun Y, et al. Mars: a video benchmark for large-scale person re-identification[C]∥The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 868-884. |
| [11] | Wu Y, Lin Y, Dong X, et al. Exploit the unknown gradually: One-shot video-based person re-identification by stepwise learning[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5177-5186. |
| [12] | Wang T, Gong S, Zhu X, et al. Person re-identification by video ranking[C]∥The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 688-703. |
| [13] | Zhong Z, Zheng L, Kang G, et al. Random erasing data augmentation[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, New York,USA, 2020, 34(7): 13001-13008. |
| [14] | Kingma D P, Ba J. Adam: a method for stochastic optimization[J/OL].[2014-03-22]. . |
| [15] | Chen Z, Zhou Z, Huang J, et al. Frame-guided regi-on-aligned representation for video person re-identification[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, New York,USA, 2020: 10591-10598. |
| [16] | Hou R, Ma B, Chang H, et al. Vrstc: occlusion-free video person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Angeles,USA, 2019: 7183-7192. |
| [17] | Yang J, Zheng W S, Yang Q, et al. Spatial-temporal graph convolutional network for video-based person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 3289-3299. |
| [18] | Zhang Z, Lan C, Zeng W, et al. Multi-granularity reference-aided attentive feature aggregation for video-based person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle,USA, 2020: 10407-10416. |
| [19] | Chen G, Rao Y, Lu J,et al.Temporal coherence or temporal motion:Which is more critical for video-based person re-identification?[C]∥The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 660-676. |
| [20] | Liu X, Zhang P, Yu C,et al.Watching you: global-guided reciprocal learning for video-based person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Shenzhen, China, 2021: 13334-13343. |
| [21] | Hou R, Chang H, Ma B, et al. Learning efficient spatial-temporal representation for video person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 21-24. |
| [22] | Jiang X, Qiao Y, Yan J,et al. SSN3D: self-separated network to align parts for 3D convolution in video person re-identification[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2021, 35(2): 1691-1699. |
| [23] | Bai S, Ma B, Chang H, et al. Salient-to-broad transition for video person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans,USA, 2022: 7339-7348. |
| [24] | Ning J, Li F, Liu R, et al. Temporal extension topology learning for video-based person reidentificat-ion[C]∥Proceedings of the Asian Conference on Co-mputer Vision, Macao, China, 2022: 207-219. |
| [25] | Pan H, Chen Y, He Z. Multi-granularity graph pooling for video-based person re-identification[J]. Neural Networks, 2023, 160: 22-33. |
| [26] | Yang F, Li W, Liang B, et al. Spatiotemporal interaction transformer network for video-based person re-identification in internet of things[J]. IEEE Internet of Things Journal, 2023,10(14):12537-12547. |
| [27] | Wang K, Ding C, Pang J, et al. Context sensing att-ention network for video-based person re-identification[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2023, 19(4): 1-20. |
| [1] | Xiang-jiu CHE,Liang LI. Graph similarity measurement algorithm combining global and local fine-grained features [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(7): 2365-2371. |
| [2] | Wen-hui LI,Chen YANG. Few-shot remote sensing image classification based on contrastive learning text perception [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(7): 2393-2401. |
| [3] | Hai-peng CHEN,Shi-bo ZHANG,Ying-da LYU. Multi⁃scale context⁃aware and boundary⁃guided image manipulation detection method [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 2114-2121. |
| [4] | Feng-feng ZHOU,Zhe GUO,Yu-si FAN. Feature representation algorithm for imbalanced classification of multi⁃omics cancer data [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 2089-2096. |
| [5] | Jian WANG,Chen-wei JIA. Trajectory prediction model for intelligent connected vehicle [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 1963-1972. |
| [6] | Xiang-jiu CHE,Yu-peng SUN. Graph node classification algorithm based on similarity random walk aggregation [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 2069-2075. |
| [7] | Ping-ping LIU,Wen-li SHANG,Xiao-yu XIE,Xiao-kang YANG. Unbalanced image classification algorithm based on fine⁃grained analysis [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 2122-2130. |
| [8] | Yue HOU,Jin-song GUO,Wei LIN,Di ZHANG,Yue WU,Xin ZHANG. Multi-view video speed extraction method that can be segmented across lane demarcation lines [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1692-1704. |
| [9] | Hong-wei ZHAO,Ming-zhu ZHOU,Ping-ping LIU,Qiu-zhan ZHOU. Medical image segmentation based on confident learning and collaborative training [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1675-1681. |
| [10] | Zi-hao SHEN,Yong-sheng GAO,Hui WANG,Pei-qian LIU,Kun LIU. Deep deterministic policy gradient caching method for privacy protection in Internet of Vehicles [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1638-1647. |
| [11] | You-wei WANG,Ao LIU,Li-zhou FENG. New method for text sentiment classification based on knowledge distillation and comment time [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1664-1674. |
| [12] | Jun WANG,Chang-fu SI,Kai-peng WANG,Qiang FU. Intrusion detection method based on ensemble learning and feature selection by PSO-GA [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(4): 1396-1405. |
| [13] | Tao XU,Shuai-di KONG,Cai-hua LIU,Shi LI. Overview of heterogeneous confidential computing [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 755-770. |
| [14] | Meng-xue ZHAO,Xiang-jiu CHE,Huan XU,Quan-le LIU. A method for generating proposals of medical image based on prior knowledge optimization [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 722-730. |
| [15] | Xiao-dong CAI,Qing-song ZHOU,Yan-yan ZHANG,Yun XUE. Social recommendation based on global capture of dynamic, static and relational features [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(2): 700-708. |
|
||