Journal of Jilin University(Engineering and Technology Edition) ›› 2025, Vol. 55 ›› Issue (12): 4034-4044.doi: 10.13229/j.cnki.jdxbgxb.20240442
Road extraction from remote sensing images combining attention and context fusion
Yun-hong LI( ),Mei WANG,Xue-ping SU,Li-min LI,Fu-xing ZHANG,Te-ji HAO
),Mei WANG,Xue-ping SU,Li-min LI,Fu-xing ZHANG,Te-ji HAO
- School of Electronics and Information,Xi'an Polytechnic University,Xi'an 710048,China
CLC Number:
- TP751
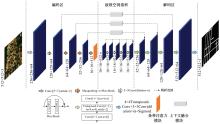
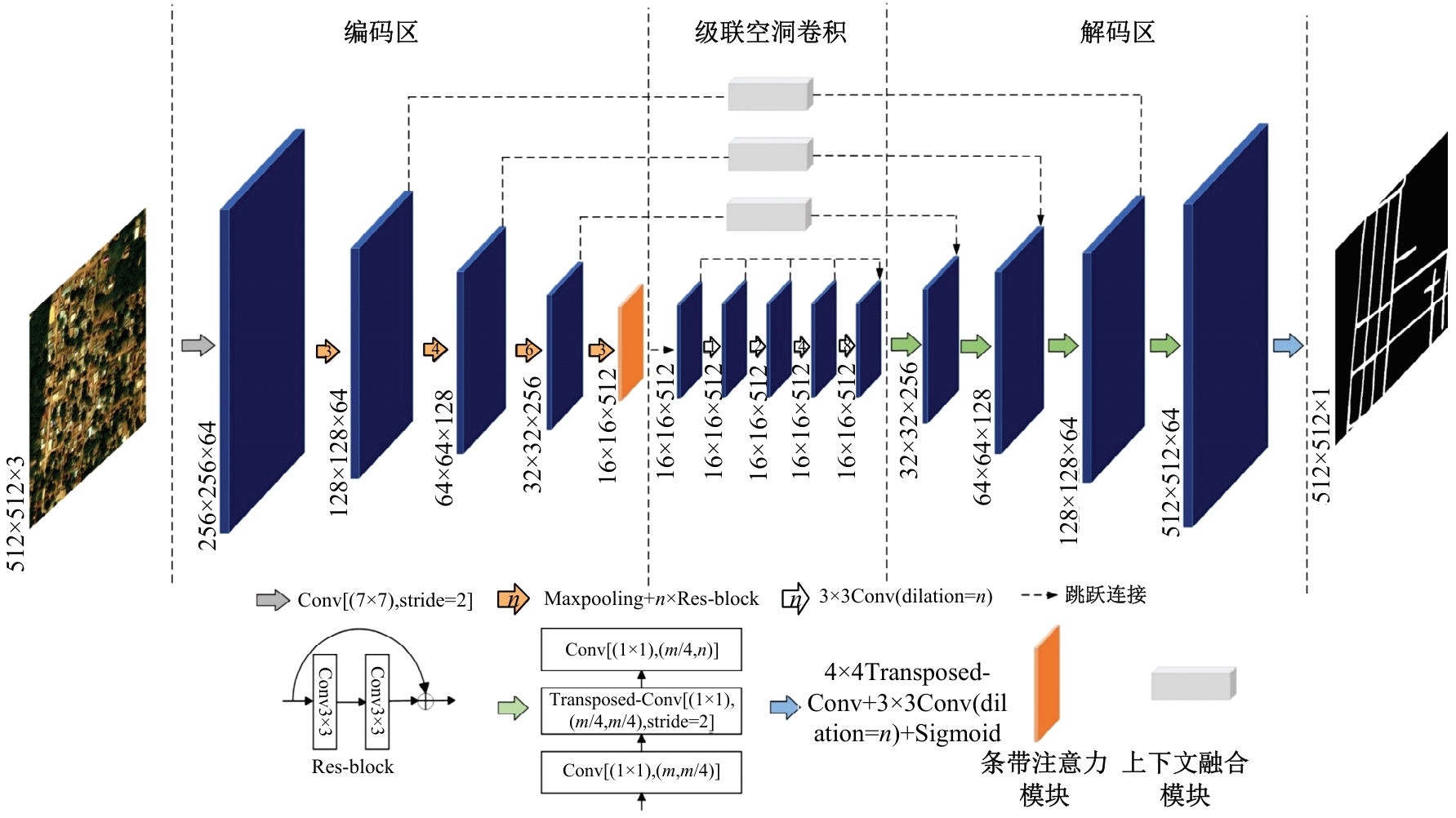
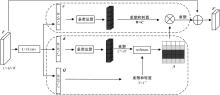
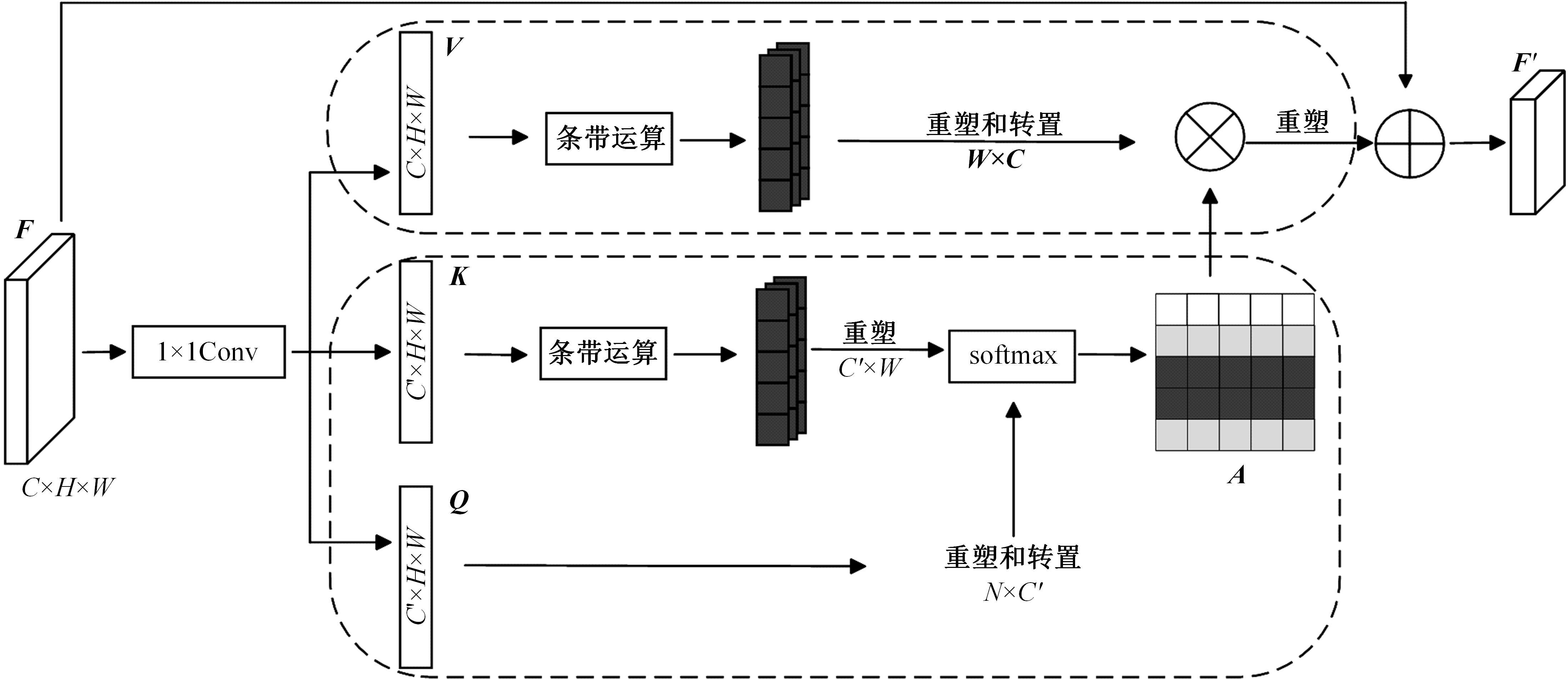
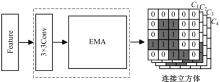
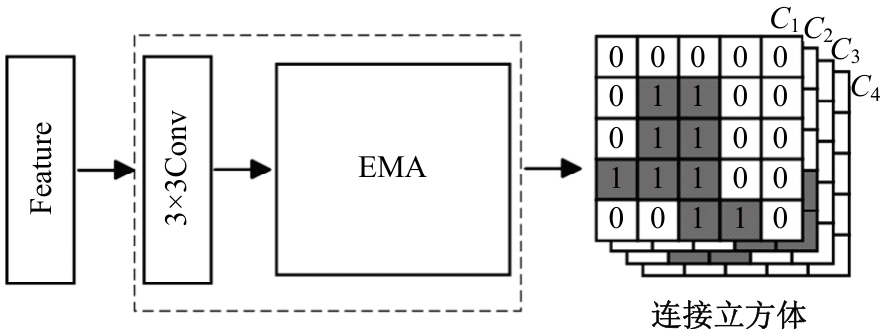
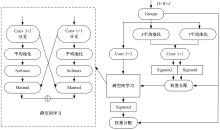
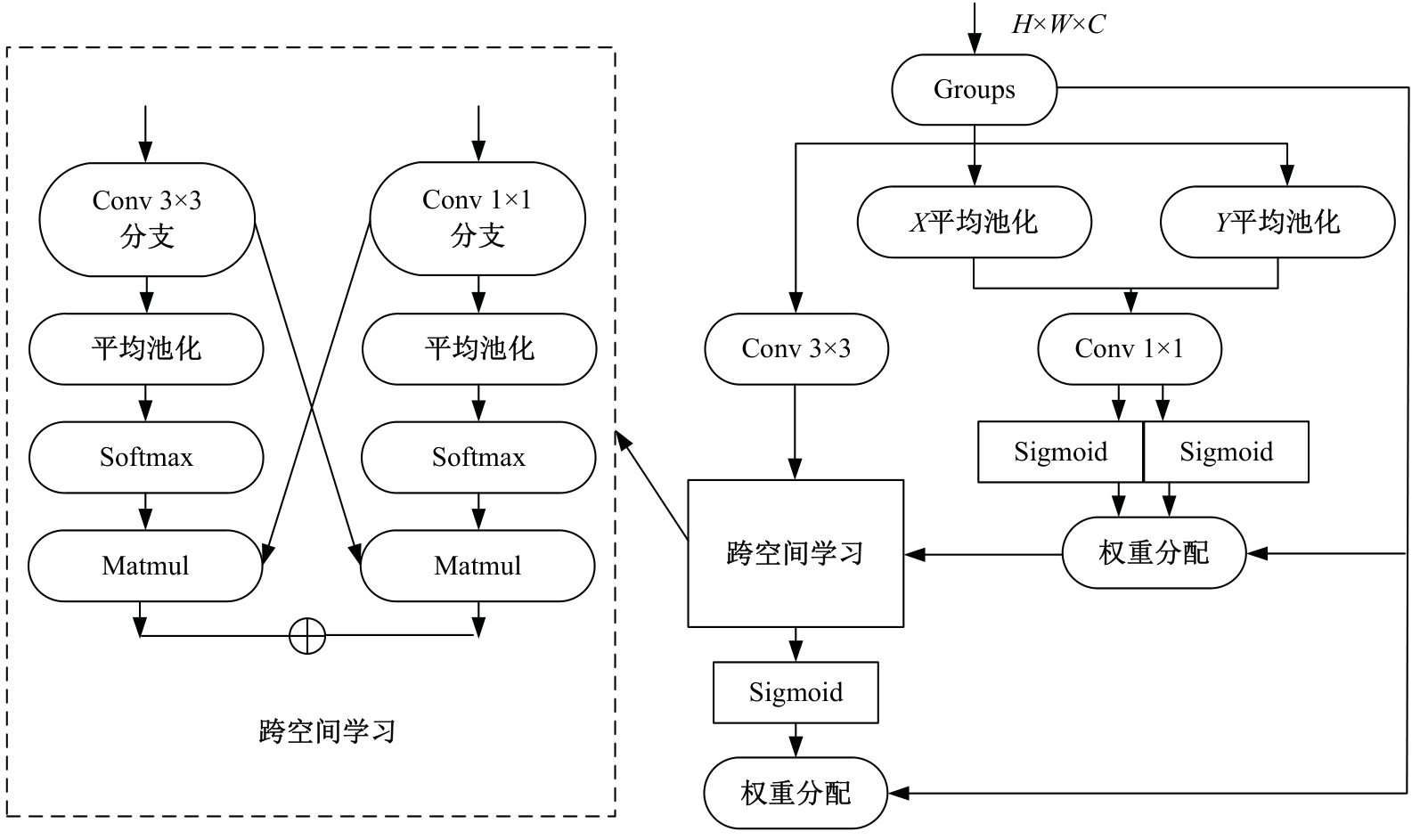
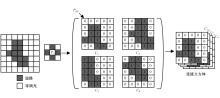
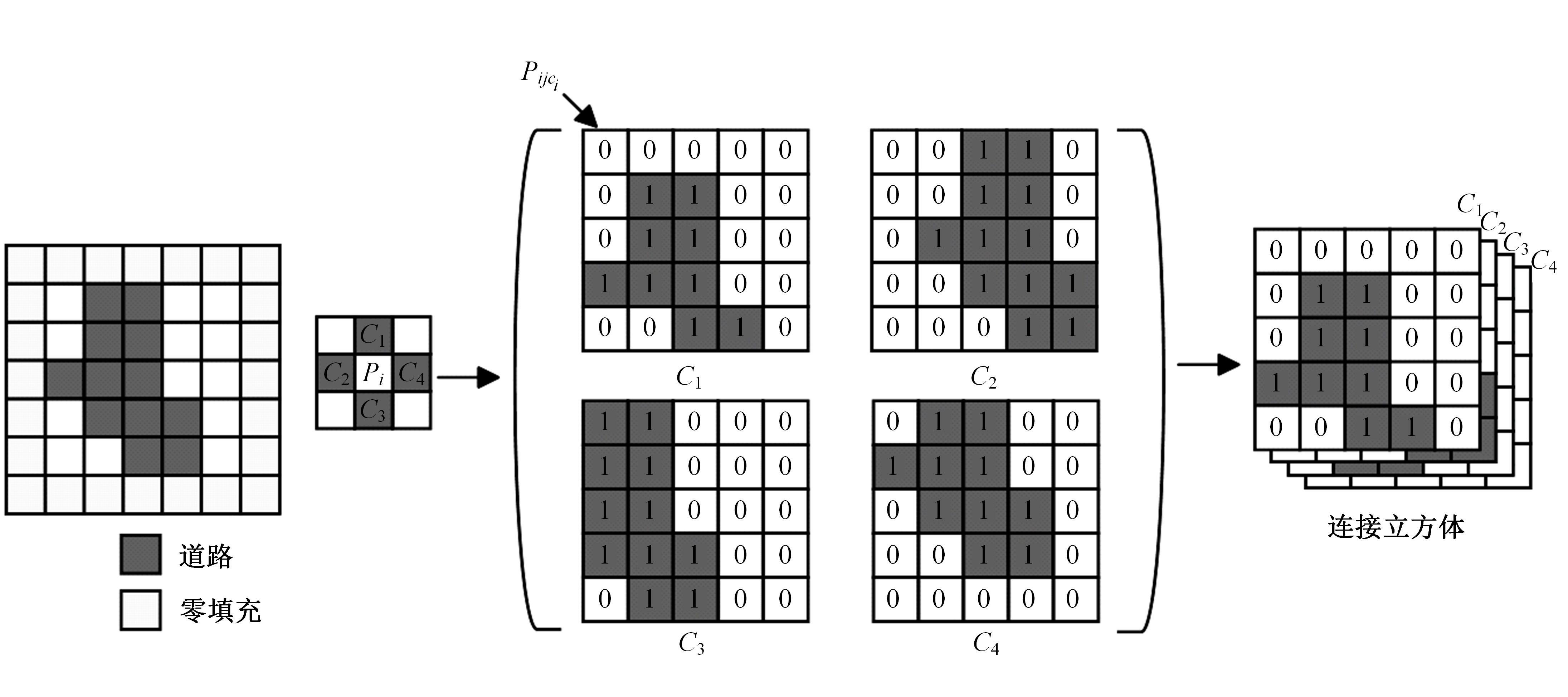





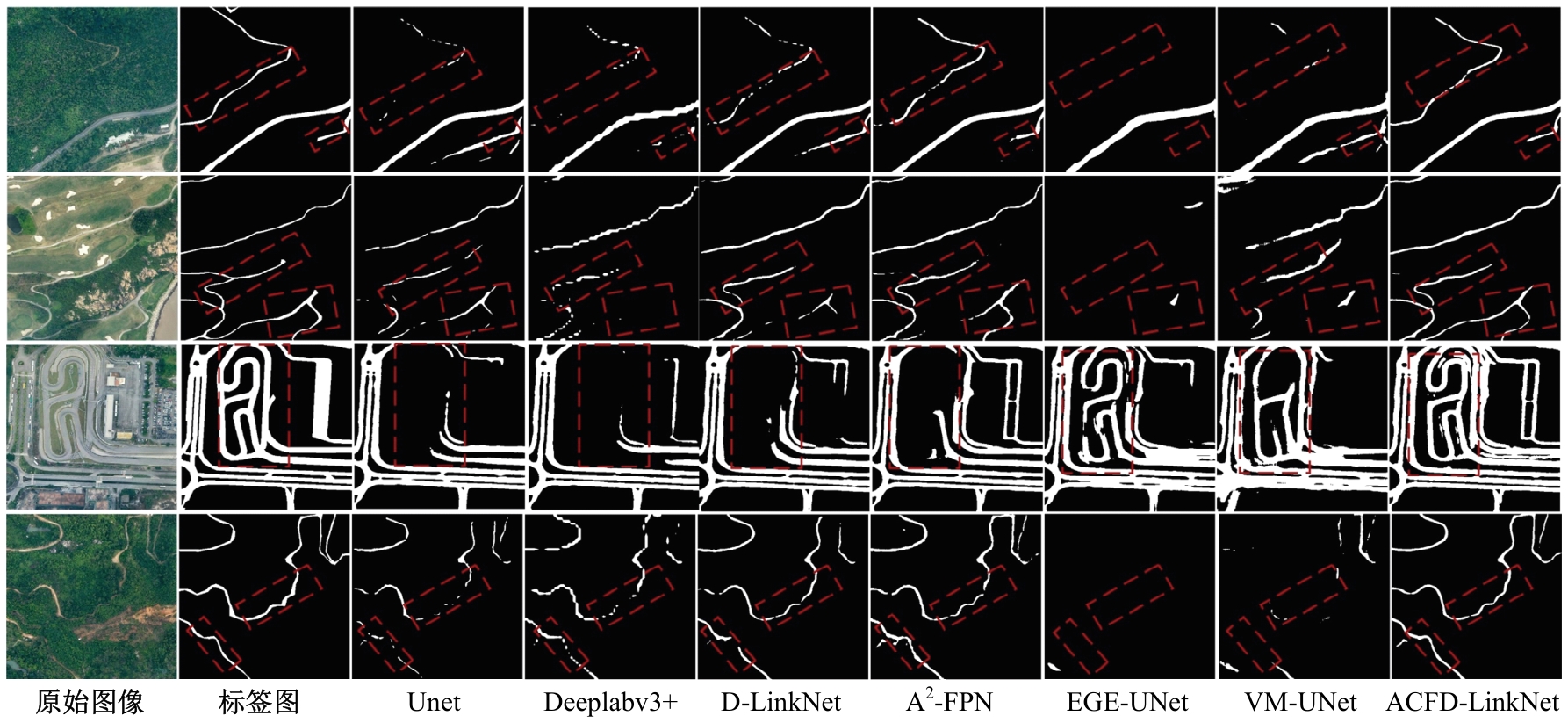


| [1] | Chen R, Li X, Hu Y, et al. Road extraction from remote sensing images in wildland-urban interface areas[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 19: 1-5. |
| [2] | Zhao K, Liu J, Wang Q, et al. Road damage detection from post-disaster high-resolution remote sensing images based on tld framework[J]. IEEE Access, 2022, 10: 43552-43561. |
| [3] | Zhang X, Jiang Y, Wang L, et al. Complex mountain road extraction in high-resolution remote sensing images via a light roadformer and a new benchmark[J]. Remote Sensing, 2022, 14(19): No.4729. |
| [4] | 宦海, 盛宇, 顾晨曦. 基于遥感图像道路提取的全局指导多特征融合网络[J]. 浙江大学学报: 工学版, 2024, 58(4): 696-707. |
| Huan Hai, Sheng Yu, Gu Chen-xi.Global guidance multi-feature fusion networ kbased on remote sensing image road extraction[J]. Journal of Zhejiang University(Engineering Science Edition), 2024, 58(4):696-707. | |
| [5] | 谭国金, 欧吉, 艾永明, 等. 基于改进DeepLabv3+模型的桥梁裂缝图像分割方法[J]. 吉林大学学报: 工学版, 2024, 54(1): 173-179. |
| Tan Guo-jin, Ji Ou, Ai Yong-ming, et al. Bridge crack image segmentation method based on improved DeepLabv3+ model[J]. Journal of Jilin University (Engineering and Technology Edition), 2024,54(1):173-179. | |
| [6] | 刘洋, 毛克明. 基于自适应反馈机制的小差异化图像纹理特征信息数据检索[J]. 江苏大学学报: 自然科学版, 2025, 46(1): 73-81. |
| Liu Yang, Mao Ke-ming. Retrieval of texture feature information data for small differentiated images based on adaptive feedback mechanism[J]. Journal of Jiangsu University(Natural Science Edition), 2025, 46(1): 73-81. | |
| [7] | 杨洋, 何童瑶, 詹永照, 等. 基于软聚类的深度图增强方法[J]. 江苏大学学报: 自然科学版, 2024, 45(2): 183-190. |
| Yang Yang, He Tong-yao, Zhan Yong-zhao, et al. Depth image enhancement method based on soft clustering[J]. Journal of Jiangsu University(Natural Science Edition), 2024, 45(2): 183-190. | |
| [8] | Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston,USA,2015: 3431-3440. |
| [9] | Wang S, Mu X, Yang D, et al. Road extraction from remote sensing images using the inner convolution integrated encoder-decoder network and directional conditional random fields[J]. Remote Sensing, 2021, 13(3): No.465. |
| [10] | Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]∥18th International Conference on Medical Image Computing and Computer-assisted Intervention-MICCAI, Munich, Germany, 2015: 234-241. |
| [11] | Zhou L, Zhang C, Wu M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City,USA, 2018: 182-186. |
| [12] | Chaurasia A, Culurciello E. Linknet: Exploiting encoder representations for efficient semantic segmentation[C]∥2017 IEEE Visual Communications and Image Processing, St. Petersburg,USA,2017: 1-4. |
| [13] | Wu K, Cai F. Dual Attention D-LinkNet for road segmentation in remote sensing images[C]∥2022 IEEE 14th International Conference on Advanced Infocomm Technology, Chongqing, China,2022: 304-307. |
| [14] | Kampffmeyer M, Dong N, Liang X, et al. ConnNet: a long-range relation-aware pixel-connectivity network for salient segmentation[J]. IEEE Transactions on Image Processing, 2018, 28(5): 2518-2529. |
| [15] | Maji D, Sigedar P, Singh M. Attention Res-UNet with guided decoder for semantic segmentation of brain tumors[J]. Biomedical Signal Processing and Control, 2022, 71: No.103077. |
| [16] | Dai L, Zhang G, Zhang R. RADANet: road augmented deformable attention network for road extraction from complex high-resolution remote-sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 1-13. |
| [17] | Song Q, Mei K, Huang R. AttaNet: Attention-augmented network for fast and accurate scene parsing[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, Menlo Park,USA,2021, 35(3): 2567-2575. |
| [18] | Ouyang D, He S, Zhang G, et al. Efficient multi-scale attention module with cross-spatial learning[C]∥ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island,Greece,2023: 1-5. |
| [19] | Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]∥Proceedings of the European Conference on Computer Vision, Munich,Germany,2018: 801-818. |
| [20] | Zhou G, Chen W, Gui Q, et al. Split depth-wise separable graph-convolution network for road extraction in complex environments from high-resolution remote-sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 1-15. |
| [21] | Li R, Wang L, Zhang C, et al. A2-FPN for semantic segmentation of fine-resolution remotely sensed images[J]. International Journal of Remote Sensing, 2022, 43(3): 1131-1155. |
| [22] | Ruan J, Xie M, Gao J, et al. Ege-unet: an efficient group enhanced unet for skin lesion segmentation[C]∥International Conference on Medical Image Computing and Computer-Assisted Intervention,Vancouver,Canada,2023: 481-490. |
| [23] | Ruan J, Xiang S. Vm-unet: Vision mamba unet for medical image segmentation[J/OL].[2024-03-25]. |
| [1] | Zhen HUO,Li-sheng JIN,Qiang HUA, HEYang. Edge feature⁃guided semantic segmentation method for intelligent vehicle [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(9): 3032-3041. |
| [2] | Qing-lin AI,Yuan-xiao LIU,Jia-hao YANG. Small target swmantic segmentation method based MFF-STDC network in complex outdoor environments [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2681-2692. |
| [3] | Yan PIAO,Ji-yuan KANG. RAUGAN:infrared image colorization method based on cycle generative adversarial networks [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(8): 2722-2731. |
| [4] | Wen-hui LI,Chen YANG. Few-shot remote sensing image classification based on contrastive learning text perception [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(7): 2393-2401. |
| [5] | Shan-na ZHUANG,Jun-shuai WANG,Jing BAI,Jing-jin DU,Zheng-you WANG. Video-based person re-identification based on three-dimensional convolution and self-attention mechanism [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(7): 2409-2417. |
| [6] | Jin-lan AN,Lan-bin WANG,Song ZHOU,Yan-qing HUANG. Microstructure of titanium alloy heat affected zone repaired by laser deposition and properties of subsequent heat treatment [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 1931-1939. |
| [7] | Ying YU,Chun-ping WANG,Ren-ke KOU,Bo-xiong YANG,Lei WANG,Fu-jun ZHAO,Qiang FU. Semantic segmentation algorithm for multi temporal high⁃resolution satellite remote sensing images [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 2131-2137. |
| [8] | Zhi-gang FENG,Shou-qi WANG,Ming-yue YU. Rolling bearing fault diagnosis based on variational mode extraction and lightweight network [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(6): 1883-1891. |
| [9] | Li TIAN,Yu-hui JIA. Improved YOLOv5s algorithm for target detection in hyperspectral remote sensing images [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1742-1748. |
| [10] | Ya-li XUE,Tong-an YU,Shan CUI,Li-zun ZHOU. Infrared small target detection based on cascaded nested U-Net [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1714-1721. |
| [11] | He-shan ZHANG,Meng-wei FAN,Xin TAN,Zhan-ji ZHENG,Li-ming KOU,Jin XU. Dense small object vehicle detection in UAV aerial images using improved YOLOX [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(4): 1307-1318. |
| [12] | Wei-zhi NIE,Fei YIN,Yi-shan SU. Review of task⁃driven imaging sonar for underwater target recognition approaches [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(4): 1163-1175. |
| [13] | Hua CAI,Yu-yao WANG,Qiang FU,Zhi-yong MA,Wei-gang WANG,Chen-jie ZHANG. Semantic segmentation network based on attention mechanism and feature fusion [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(4): 1384-1395. |
| [14] | Yang LI,Xian-guo LI,Chang-yun MIAO,Sheng XU. Low⁃light image enhancement algorithm based on dual branch channel prior and Retinex [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 1028-1036. |
| [15] | Yan YANG,Wang-liang SHEN. Multi⁃scale detail enhancement and layered noise suppression algorithm for image dehazing [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(12): 4010-4023. |
|
||