Journal of Jilin University(Engineering and Technology Edition) ›› 2024, Vol. 54 ›› Issue (7): 2049-2056.doi: 10.13229/j.cnki.jdxbgxb.20221141
Visual Transformer based on a recurrent structure
Lei JIANG1( ),Zi-qi WANG1,Zhen-yu CUI2,Zhi-yong CHANG3,4,Xiao-hu SHI5,6()
),Zi-qi WANG1,Zhen-yu CUI2,Zhi-yong CHANG3,4,Xiao-hu SHI5,6()
- 1.Faculty of Mechanics and Mathematics,Moscow State University,Moscow 119991,Russia
2.Faculty of Computational Mathematics and Cybernetics,Moscow State University,Moscow 119991,Russia
3.College of Biological and Agricultural Engineering,Jilin University,Changchun 130022,China
4.Key Laboratory of Bionic Engineering,Ministry of Education,Jilin University,Changchun 130022,China
5.College of Computer Science and Technology,Jilin University,Changchun 130012,China
6.Key Laboratory of Symbol Computation and Knowledge Engineering of the Ministry of Education,Jilin University,Changchun 130012,China
CLC Number:
- TP391


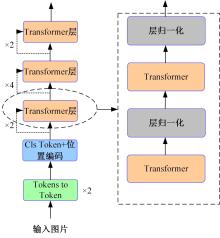
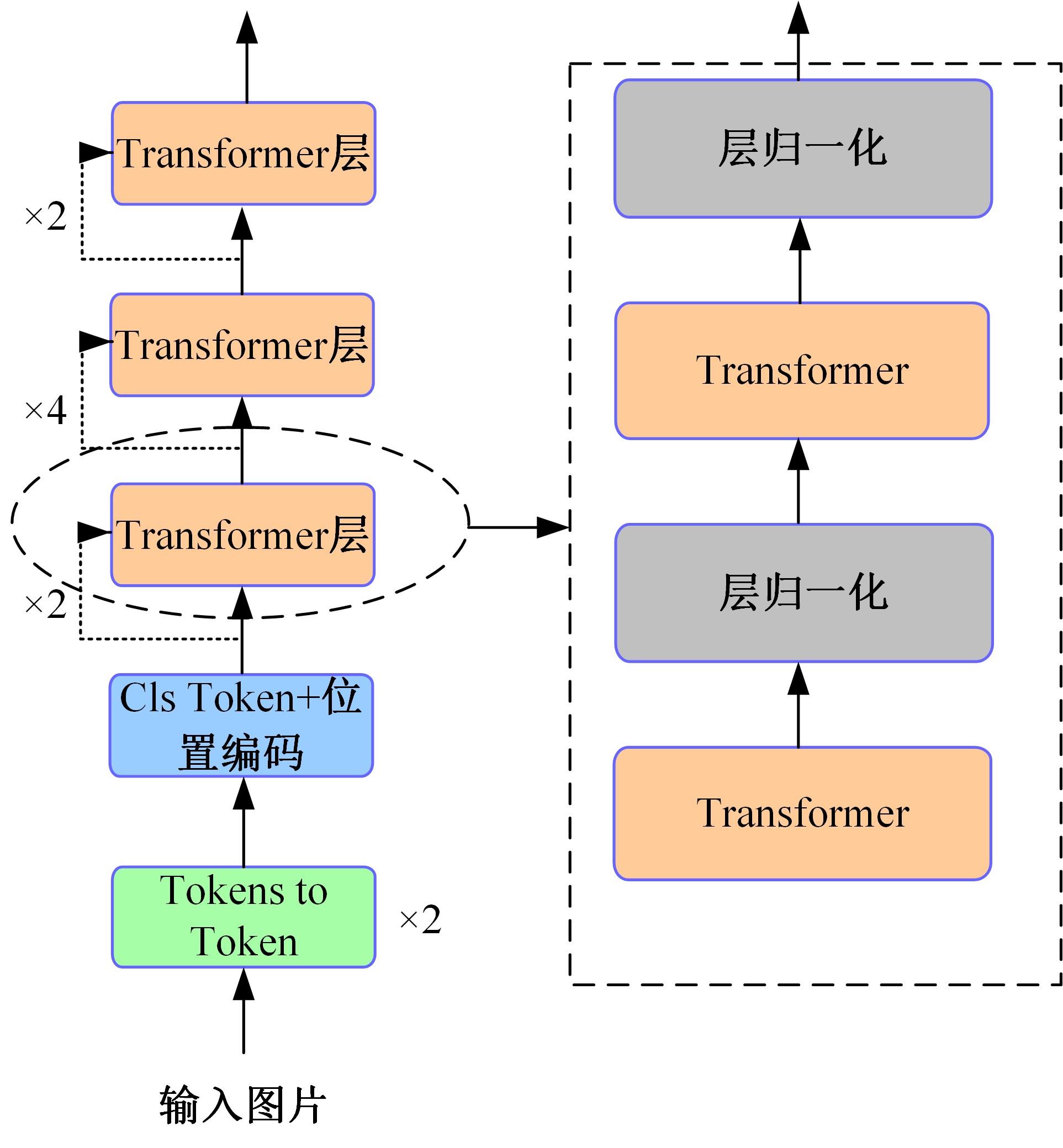
| 1 | Vaswani A, Shazeer N, Parmar N,et al. Attention is all you need[DB/OL]. [2022-01-10]. . |
| 2 | Radford A, Kim J W, Hallacy C,et al. Learning transferable visual models from natural language supervision[DB/OL]. [2022-01-10].. |
| 3 | Ramesh A, Pavlov M, Goh G,et al. Zero-shot text-to-image generation[DB/OL]. [2022-01-10]. . |
| 4 | Liu Z, Lin Y, Cao Y,et al. Swin transformer: hierarchical vision transformer using shifted windows[DB/OL]. [2022-01-10]. . |
| 5 | Yuan L, Chen Y, Wang T,et al. Tokens-to-token vit: training vision transformers from scratch on ImageNet[DB/OL]. [2022-01-10]. . |
| 6 | He K, Chen X, Xie S,et al. Masked autoencoders are scalable vision learners[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA,2022:16000-16009. |
| 7 | Lee-Thorp J, Ainslie J, Eckstein I,et al. FNet: mixing tokens with Fourier transforms[DB/OL]. [2022-01-10]. . |
| 8 | Child R, Gray S, Radford A,et al. Generating long sequences with sparse transformers[DB/OL]. [2022-01-10]. . |
| 9 | Han S, Pool J, Tran J,et al. Learning both weights and connections for efficient neural networks[C]∥ Advances in Neural Information Processing Systems, Montreal, Canada, 2015:1135-1143. |
| 10 | Yang H, Yin H, Molchanov P,et al. NViT: vision transformer compression and parameter redistribution[DB/OL]. [2022-01-10]. . |
| 11 | Nagel M, Fournarakis M, Amjad R A,et al. A white paper on neural network quantization[DB/OL]. [2022-01-10]. . |
| 12 | Mehta S, Rastegari M. MobileViT: light-weight, general-purpose, and mobile-friendly vision transformer[DB/OL]. [2022-01-10]. . |
| 13 | Callaway, Edward M. Feedforward, feedback and inhibitory connections in primate visual cortex[J]. Neural Networks, 2004, 17(5,6): 625-632. |
| 14 | Briggs F. Role of feedback connections in central visual processing[J]. Annual Review of Vision Science, 2020, 6(1): 313-334. |
| 15 | Kubilius J, Schrimpf M, Nayebi A, et al. Cornet: modeling the neural mechanisms of core object recognition[DB/OL]. [2022-01-10]. . |
| 16 | Messina N, Amato G, Carrara F,et al. Recurrent vision transformer for solving visual reasoning problems[DB/OL]. [2022-01-10]. . |
| 17 | Hauser, Michael, Asok R. Principles of riemannian geometry in neural networks[C]∥ Advances in Neural Information Processing Systems, Long Beach, USA, 2017:30. |
| 18 | Devlin J, Chang M W, Lee K,et al. BERT: pre-training of deep bidirectional transformers for language understanding [DB/OL]. [2022-01-12]. . |
| 19 | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: transformers for image recognition at scale[DB/OL]. [2022-01-12]. . |
| 20 | He K M, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770-778. |
| 21 | Balduzzi D, et al. The shattered gradients problem: if resnets are the answer, then what is the question? [C]∥International Conference on Machine Learning, Sydney, Australia, 2017: 342-350. |
| 22 | Tarnowski W, Warcho P, Jastrzbski S,et al. Dynamical isometry is achieved in residual networks in a universal way for any activation function[DB/OL]. [2022-01-12]. . |
| 23 | Zaeemzadeh A, Rahnavard N, Shah M. Norm-preservation: why residual networks can become extremely deep?[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 43(11): 3980-3990. |
| 24 | Deng J, Wei D, Richard S,et al. Imagenet: a large-scale hierarchical image database[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, USA, 2009: 248-255. |
| 25 | Loshchilov I, Hutter F. Decoupled weight decay regularization[DB/OL]. [2022-01-12]. . |
| 26 | Ren S, He K, Girshick R, et al. Faster r-cnn: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149. |
| [1] | Yun-zuo ZHANG,Yu-xin ZHENG,Cun-yu WU,Tian ZHANG. Accurate lane detection of complex environment based on double feature extraction network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(7): 1894-1902. |
| [2] | Ming-hui SUN,Hao XUE,Yu-bo JIN,Wei-dong QU,Gui-he QIN. Video saliency prediction with collective spatio-temporal attention [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(6): 1767-1776. |
| [3] | Yan-feng LI,Ming-yang LIU,Jia-ming HU,Hua-dong SUN,Jie-yu MENG,Ao-ying WANG,Han-yue ZHANG,Hua-min YANG,Kai-xu HAN. Infrared and visible image fusion based on gradient transfer and auto-encoder [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(6): 1777-1787. |
| [4] | Zi-chao ZHANG,Jian CHEN. A mapping method using 3D orchard point cloud based on hawk-eye-inspired stereo vision and super resolution [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1469-1481. |
| [5] | Hai-tao WANG,Hui-zhuo LIU,Xue-yong ZHANG,Jian WEI,Xiao-yuan GUO,Jun-zhe XIAO. Forward-looking visual field reproduction for vehicle screen-displayed closed cockpit using monocular vision [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1435-1442. |
| [6] | Dian-wei WANG,Chi ZHANG,Jie FANG,Zhi-jie XU. UAV target tracking algorithm based on high resolution siamese network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1426-1434. |
| [7] | Yun-long GAO,Ming REN,Chuan WU,Wen GAO. An improved anchor-free model based on attention mechanism for ship detection [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1407-1416. |
| [8] | Xi-guang ZHANG,Long-fei ZHANG,Yu-xi MA,Yin-ting FAN. Design of fuzzy clustering algorithm for massive cloud data based on density peak [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1401-1406. |
| [9] | Fu-heng QU,Yue-tao PAN,Yong YANG,Ya-ting HU,Jian-fei SONG,Cheng-yu WEI. An efficient global K-means clustering algorithm based on weighted space partitioning [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1393-1400. |
| [10] | Yu WANG,Kai ZHAO. Postprocessing of human pose heatmap based on sub⁃pixel location [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1385-1392. |
| [11] | Tao CHEN,Zhi-gang ZHOU,Nan-nan LEI. Multi-objective optimization of parameters of automotive mechanical automatic transmission system based on particle swarm optimization [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1214-1220. |
| [12] | Shao-cheng HAN,Peng ZHANG,Huan LIU,Bo WANG. Stereo image zero watermarking algorithm based on Tucker decomposition and double scrambling encryption technology [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(4): 1065-1077. |
| [13] | Xiao-xu LI,Wen-juan AN,Ji-jie WU,Zhen LI,Ke ZHANG,Zhan-yu MA. Channel attention bilinear metric network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(2): 524-532. |
| [14] | Xiong-fei LI,Zi-xuan SONG,Rui ZHU,Xiao-li ZHANG. Remote sensing change detection model based on multi⁃scale fusion [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(2): 516-523. |
| [15] | Liu LIU,Kun DING,Shan-shan LIU,Ming LIU. Event detection method as machine reading comprehension [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(2): 533-539. |
|
||