Journal of Jilin University(Engineering and Technology Edition) ›› 2025, Vol. 55 ›› Issue (10): 3283-3295.doi: 10.13229/j.cnki.jdxbgxb.20240086
Human pose estimation based on graph structure guidance and location information enhancement
Xin GUAN( ),Zi-jian ZHOU,Qiang LI()
),Zi-jian ZHOU,Qiang LI()
- School of Microelectronics,Tianjin University,Tianjin 300072,China
CLC Number:
- TP391.4
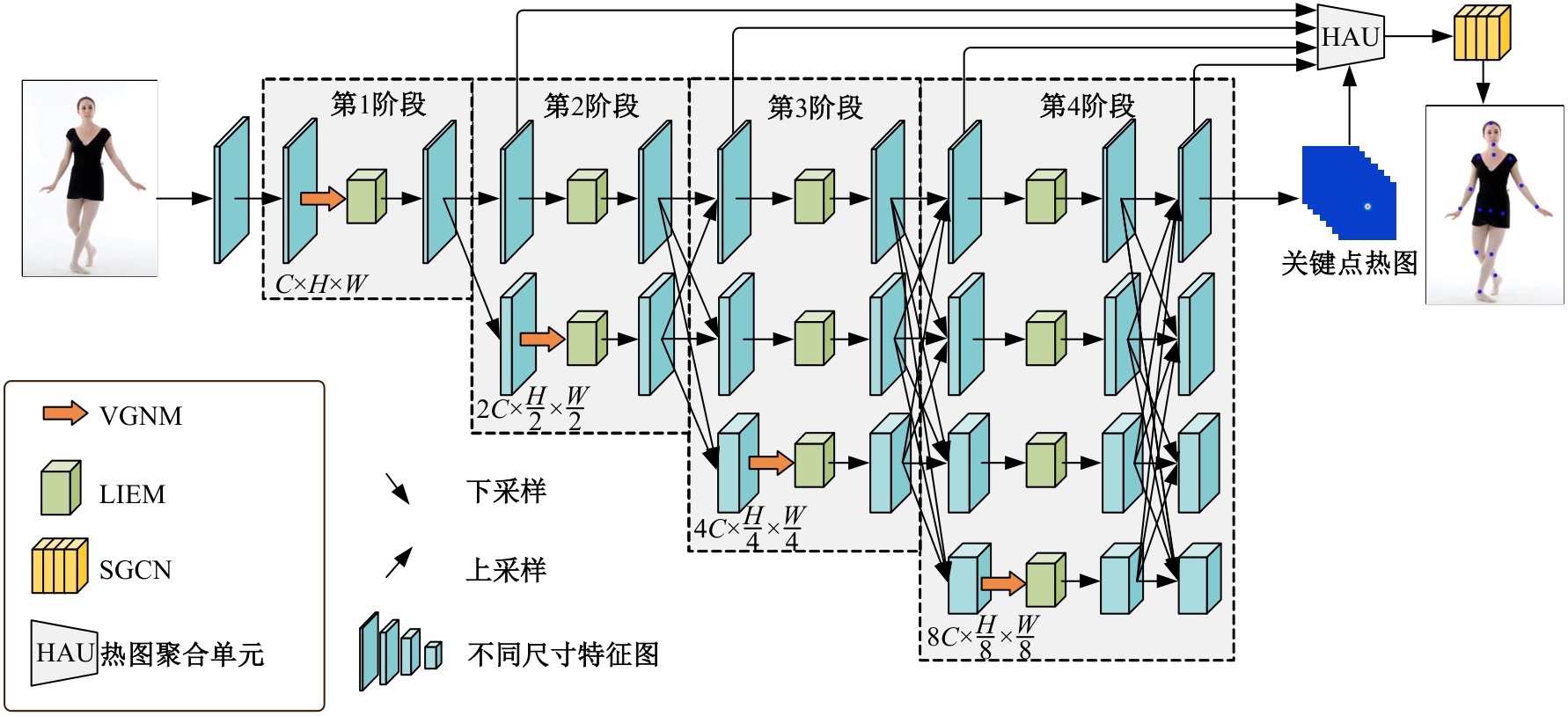
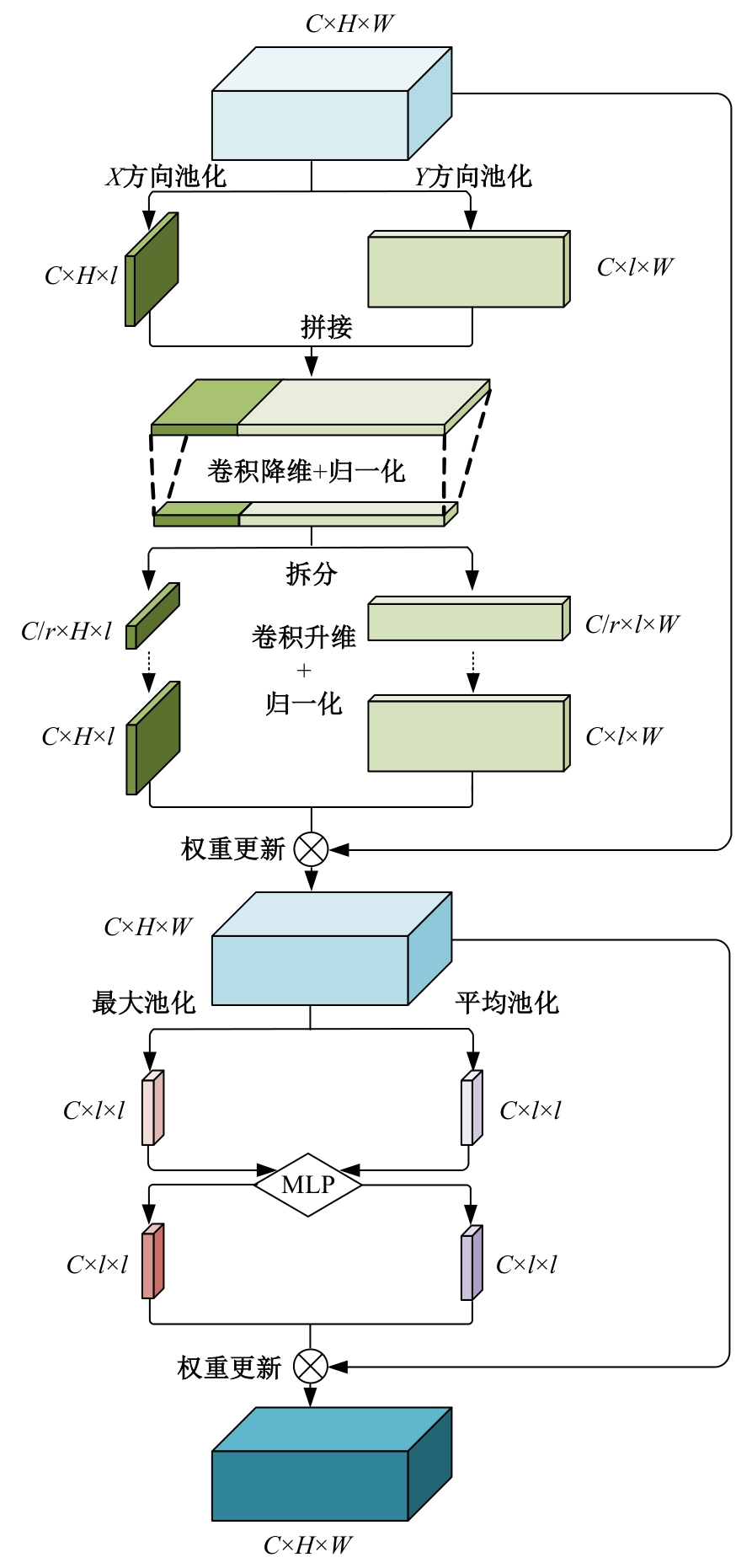
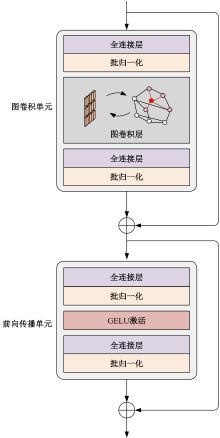
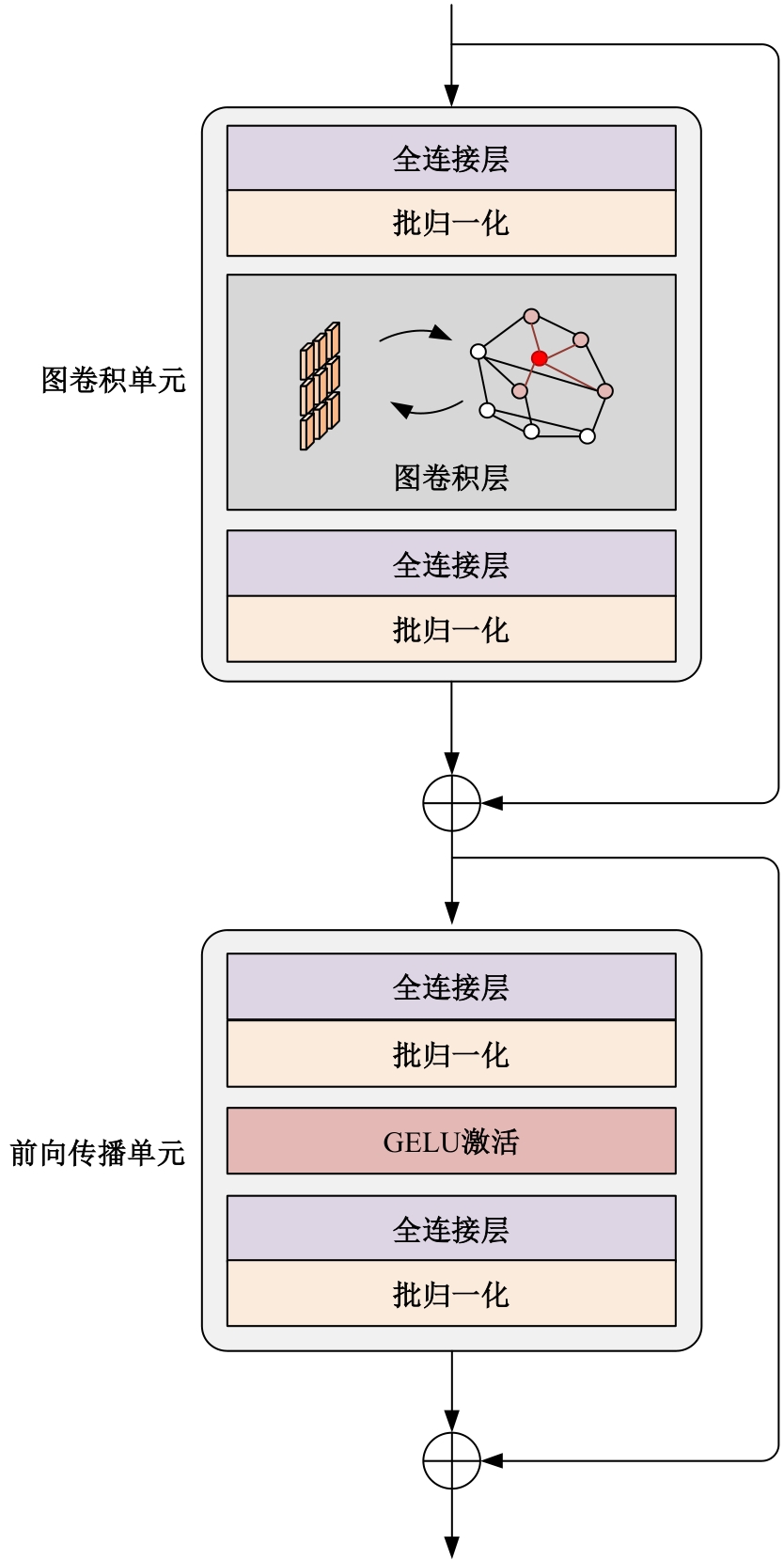
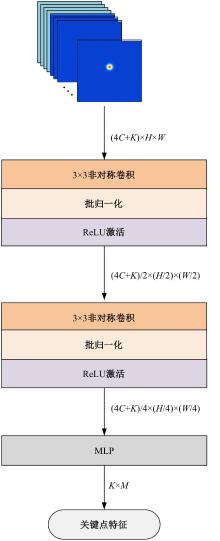
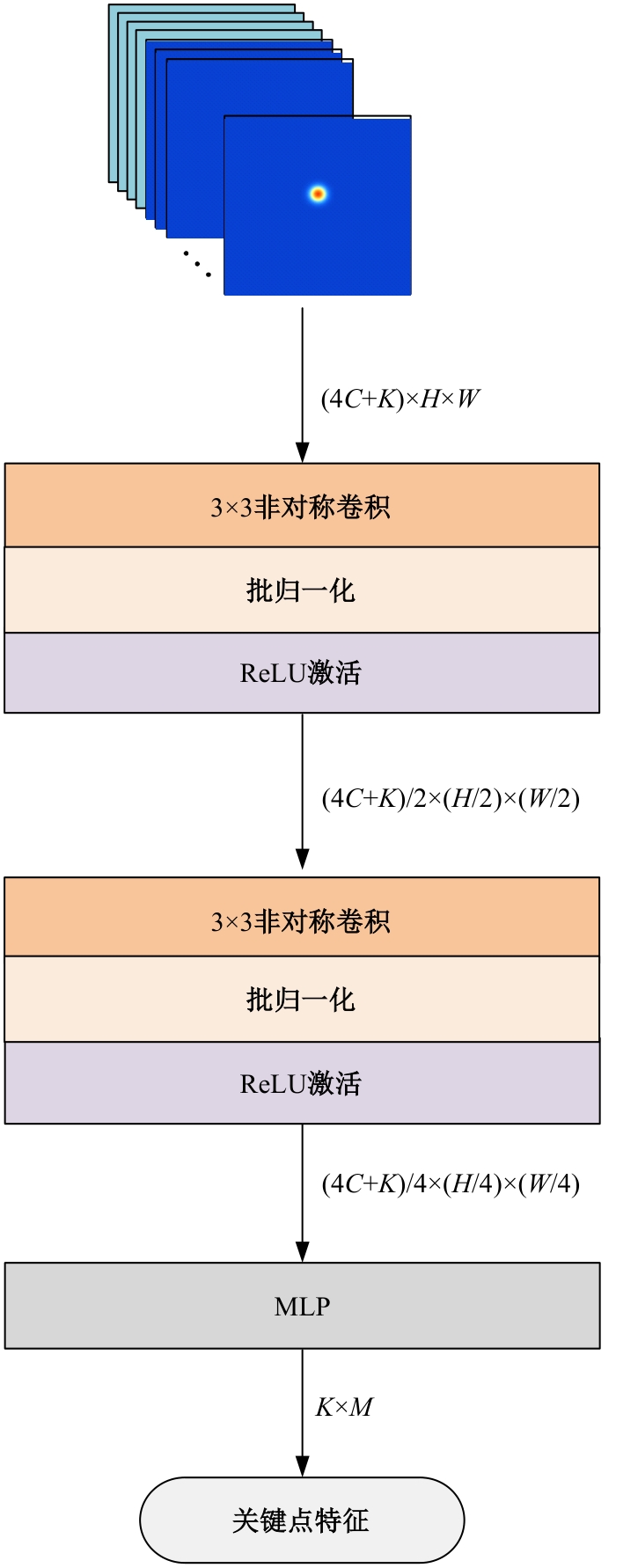
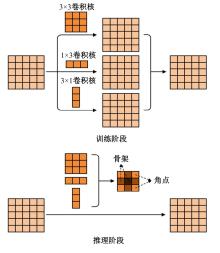
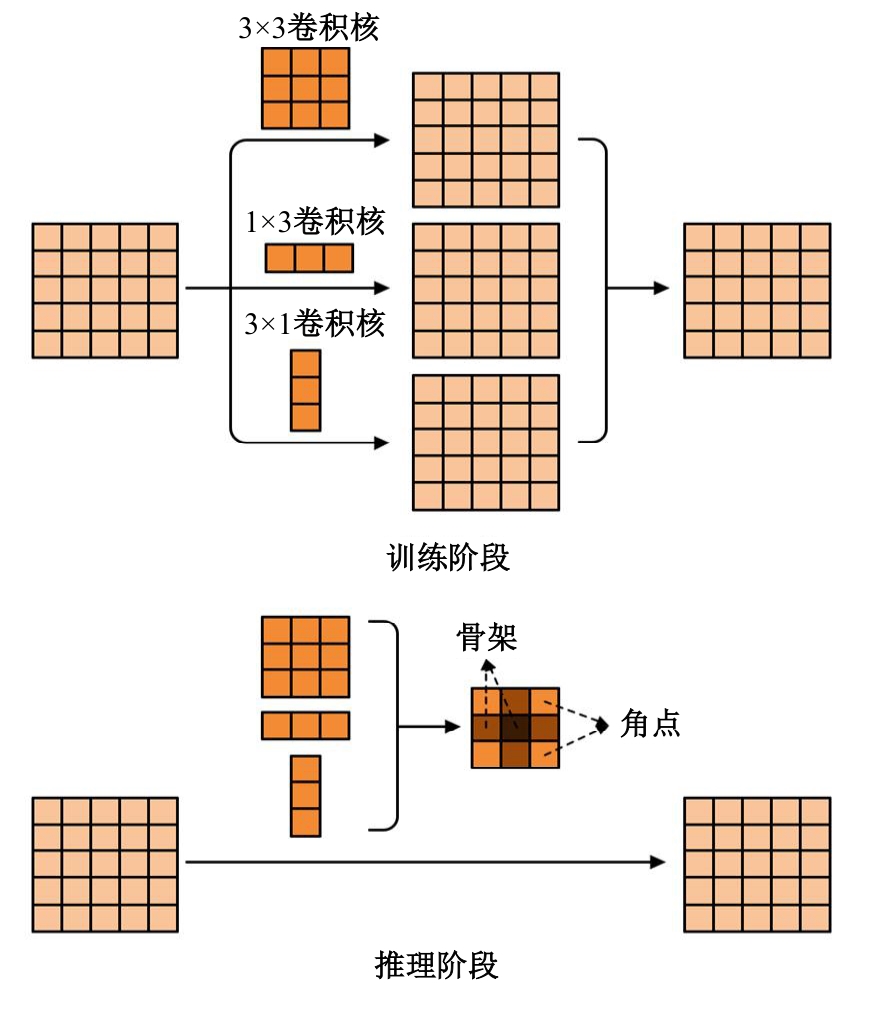
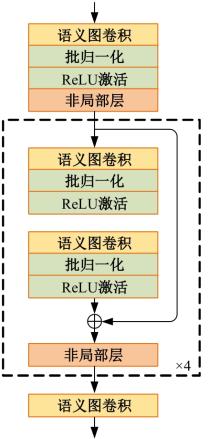
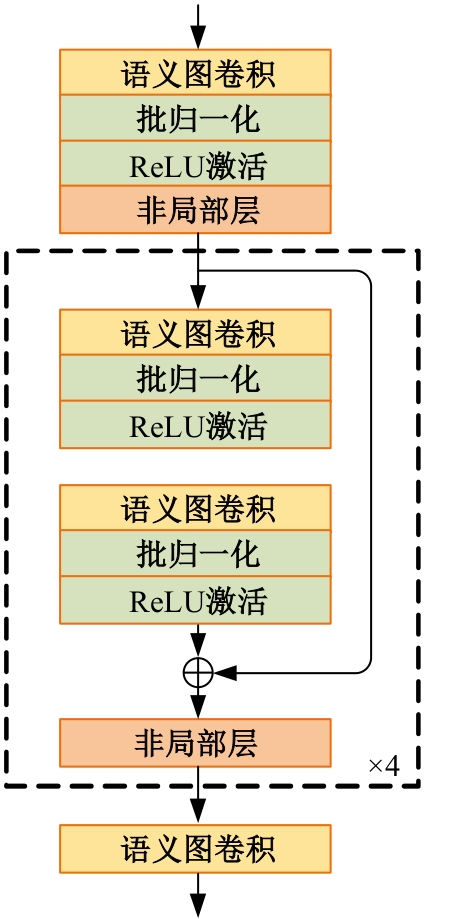




| [1] | Eduardo RDS, Adams LS, Stoffel R A, et al. Monocular multi-person pose estimation: a survey[J]. Pattern Recognition, 2021, 118: No.108046. |
| [2] | 田皓宇, 马昕, 李贻斌. 基于骨架信息的异常步 态识别方法[J]. 吉林大学学报: 工学版, 2022, 52(4): 725-737. |
| Tian Hao-yu, Ma Xin, Li Yi-bin. Abnormal gait recognition method based on skeleton information[J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(4): 725-737. | |
| [3] | Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| [4] | Toshev A, Szegedy C. DeepPose: Human pose estimation via deep neural networks[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 1653-1660. |
| [5] | Tompson J, Jain A, Lecun Y, et al. Joint training of a convolutional network and a graphical model for human pose estimation[C]∥Neural Information Processing Systems,Montreal, Canada, 2014: 1799-1807. |
| [6] | Newell A, Yang K, Deng J. Stacked hourglass networks for human pose estimation[C]∥European Conference on Computer Vision, Amsterdam, Netherlands, 2016: 483-499. |
| [7] | Chen Y L, Wang Z C, Peng Y X, et al. Cascaded pyramid network for multi-person pose estimation[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7103-7112. |
| [8] | Xiao B, Wu H P, Wei Y C. Simple baselines for human pose estimation and tracking[C]∥European Conference on Computer Vision, Munich, Germany, 2018: 472-487. |
| [9] | Sun K, Xiao B, Liu D, et al. Deep high-resolution representation learning for human pose estimation [C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5686-5796. |
| [10] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]∥Neural Information Processing Systems(NeurIPS),Long Beach, USA, 2017: 5998-6008. |
| [11] | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: transformers for image recognition at scale[C]∥International Conference on Learning Representations, Online, 2021. |
| [12] | Li Y J, Zhang S K, Wang Z C, et al. Tokenpose: Learning keypoint tokens for human pose estimation[C]∥Proceedings of the IEEE International Conference on Computer Vision(ICCV),Montreal, Canda, 2021: 11293-11302. |
| [13] | Yuan Y H, Fu R, Huang L, et al. Hrformer: high-resolution transformer for dense prediction[J]. Advances in Neural Information Processing Systems, 2021, 34: 7281-7293. |
| [14] | Yang S, Quan Z B, Nie M, et al. Transpose: Keypoint localization via transformer[C]∥Proceedings of the IEEE International Conference on Computer Vision, Montreal, Canda, 2021: 11782-11792. |
| [15] | Li G H, Müller M, Thabet A, et al. DeepGCNs: Can GCNs Go As Deep As CNNs?[C]∥IEEE International Conference on Computer Vision, Seoul, South Korea, 2019: 9266-9275. |
| [16] | Qiu L T, Zhang X Y Y, Li Y R, et al. Peeking into occluded joints: A novel framework for crowd pose estimation[C]∥European Conference on Computer Vision, Glasgow, UK, 2020: 488-504. |
| [17] | Bin Y R, Chen Z M, Wei X S, et al. Structure-aware human pose estimation with graph convolutional networks[J]. Pattern Recognition, 2020, 106: No.107410. |
| [18] | Wang J, Long X, Gao Y, et al. Graph-PCNN: Two stage human pose estimation with graph pose refinement[C]∥European Conference on Computer Vision, Glasgow, UK, 2020: 492-508. |
| [19] | Banik S, GarcÍa A M, Knoll A. 3D human pose regression using graph convolutional network[C]∥IEEE International Conference on Image Processing(ICIP), Anchorage, USA, 2021: 924-928. |
| [20] | Hou Q B, Zhou D Q, Feng J S. Coordinate attention for efficient mobile network design[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Nashville, USA, 2021: 13708-13717. |
| [21] | Han K, Wang Y H, Guo J Y, et al. Vision gnn: An image is worth graph of nodes[J]. Advances in Neural Information Processing Systems, 2022, 35: 8291-8303. |
| [22] | Huang G, Liu Z, Laurens V D M, et al. Densely connected convolutional networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, USA, 2017: 4700-4708. |
| [23] | Ding X H, Guo Y C, Ding G G, et al. ACNet: Strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks[C]∥International Conference on Computer Vision, Seoul, South Korea, 2019: 1911-1920. |
| [24] | Zhao L, Peng X, Tian Y, et al. Semantic graph convolutional networks for 3D Human Pose Regression[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3420-3430. |
| [25] | Wang X L, Girshick R, Gupta A, et al. Non-local neural networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, USA, 2018: 7794-7803. |
| [26] | Yang J W, Lu J S, Lee S, et al. Graph R-CNN for scene graph generation[C]∥European Conference on Computer Vision, Munich, Germany, 2018: 690-706. |
| [27] | Velikovi P, Cucurull G, Casanova A, et al. Graph attention networks[J]. Stat, 2017, 1050(20): No.10-48550. |
| [28] | Andriluka M, Pishchulin L, Gehler P, et al. 2D human pose estimation: New benchmark and state of the art analysis[C]∥IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 3686-3693. |
| [29] | Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: Common objects in context[C]∥Proceedings of the European Conference on Computer Vision(ECCV), Zurich, the Switzerland, 2014: 740-755. |
| [30] | Zhang K, He P, Yao P, et al. Learning enhanced resolution-wise features for human pose estimation[C]∥IEEE International Conference on Image Processing, Abu Dhabi, United Arab Emirates, 2020: 2256-2260. |
| [31] | Wang R, Wu W Y, Wang X Y. Enhancing multi-scale information exchange and feature fusion for human pose estimation[J]. The Visual Computer, 2023, 39(10): 4751-4765. |
| [32] | Tran T D, Vo X T, Nguyen D L, et al. High-resolution network with attention module for human pose estimation[C]∥Asian Control Conference, Jeju Island, South Korea, 2022: 459-464. |
| [33] | Dong K W, Sun Y J, Cheng X Z, et al. Combining detailed appearance and multi-scale representation: A structure-context complementary network for human pose estimation[J]. Applied Intelligence, 2023, 53(7): 8097-8113. |
| [34] | Soomro K, Zamir A R, Shah M. UCF101: a dataset of 101 human actions classes from videos in the wild[J/OL].[2023-08-16]. . |
| [1] | Yue HOU,Xin ZHANG,Yue WU. Traffic flow prediction based on spatio-temporal dynamic constraint graph feedback [J]. Journal of Jilin University(Engineering and Technology Edition), 2026, 56(1): 183-198. |
| [2] | Yue HOU,Jin-song GUO,Wei LIN,Di ZHANG,Yue WU,Xin ZHANG. Multi-view video speed extraction method that can be segmented across lane demarcation lines [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(5): 1692-1704. |
| [3] | Hua CAI,Rui-kun ZHU,Qiang FU,Wei-gang WANG,Zhi-yong MA,Jun-xi SUN. Human pose estimation corrector algorithm based on implicit key point interconnection [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 1061-1071. |
| [4] | Guang-wen LIU,Xin-yue XIE,Qiang FU,Hua CAI,Wei-gang WANG,Zhi-yong MA. Spatiotemporal Transformer with template attention for target tracking [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(3): 1037-1049. |
| [5] | Lai-wei JIANG,Ce WANG,Hong-yu YANG. Review of multi-object tracking based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(11): 3429-3445. |
| [6] | Sheng-jie ZHU,Xuan WANG,Fang XU,Jia-qi PENG,Yuan-chao WANG. Multi-scale normalized detection method for airborne wide-area remote sensing images [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(8): 2329-2337. |
| [7] | Pei-guang JING,Yu-dou TIAN,Shao-chu WANG,Yun LI,Yu-ting SU. Traffic flow prediction algorithm based on dynamic diffusion graph convolution [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(6): 1582-1592. |
| [8] | Ming-hui SUN,Hao XUE,Yu-bo JIN,Wei-dong QU,Gui-he QIN. Video saliency prediction with collective spatio-temporal attention [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(6): 1767-1776. |
| [9] | Yun-long GAO,Ming REN,Chuan WU,Wen GAO. An improved anchor-free model based on attention mechanism for ship detection [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1407-1416. |
| [10] | Dian-wei WANG,Chi ZHANG,Jie FANG,Zhi-jie XU. UAV target tracking algorithm based on high resolution siamese network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1426-1434. |
| [11] | Yu WANG,Kai ZHAO. Postprocessing of human pose heatmap based on sub⁃pixel location [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(5): 1385-1392. |
| [12] | Lin MAO,Hong-yang SU,Da-wei YANG. Temporal salient attention siamese tracking network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(11): 3327-3337. |
| [13] | Wen-cai SUN,Xu-ge HU,Zhi-fa YANG,Fan-yu MENG,Wei SUN. Optimization of infrared-visible road target detection by fusing GPNet and image multiscale features [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(10): 2799-2806. |
| [14] | Yu-ting SU,Ji WANG,Wei ZHAO,Pei-guang JING. Dynamic graph convolutional neural network for image sentiment distribution prediction [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(9): 2601-2610. |
| [15] | Jing-hong LIU,An-ping DENG,Qi-qi CHEN,Jia-qi PENG,Yu-jia ZUO. Anchor⁃free target tracking algorithm based on multiple attention mechanism [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(12): 3518-3528. |
|
||