Journal of Jilin University(Engineering and Technology Edition) ›› 2022, Vol. 52 ›› Issue (10): 2428-2437.doi: 10.13229/j.cnki.jdxbgxb20210630
Self-supervised 3D face reconstruction based on multi-scale feature fusion and dual attention mechanism
Da-ke ZHOU( ),Chao ZHANG,Xin YANG
),Chao ZHANG,Xin YANG
- College of Automation Engineering,Nanjing University of Aeronautics and Astronautics,Nanjing 211100,China
CLC Number:
- TP391.4
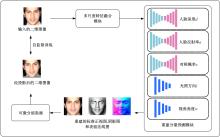
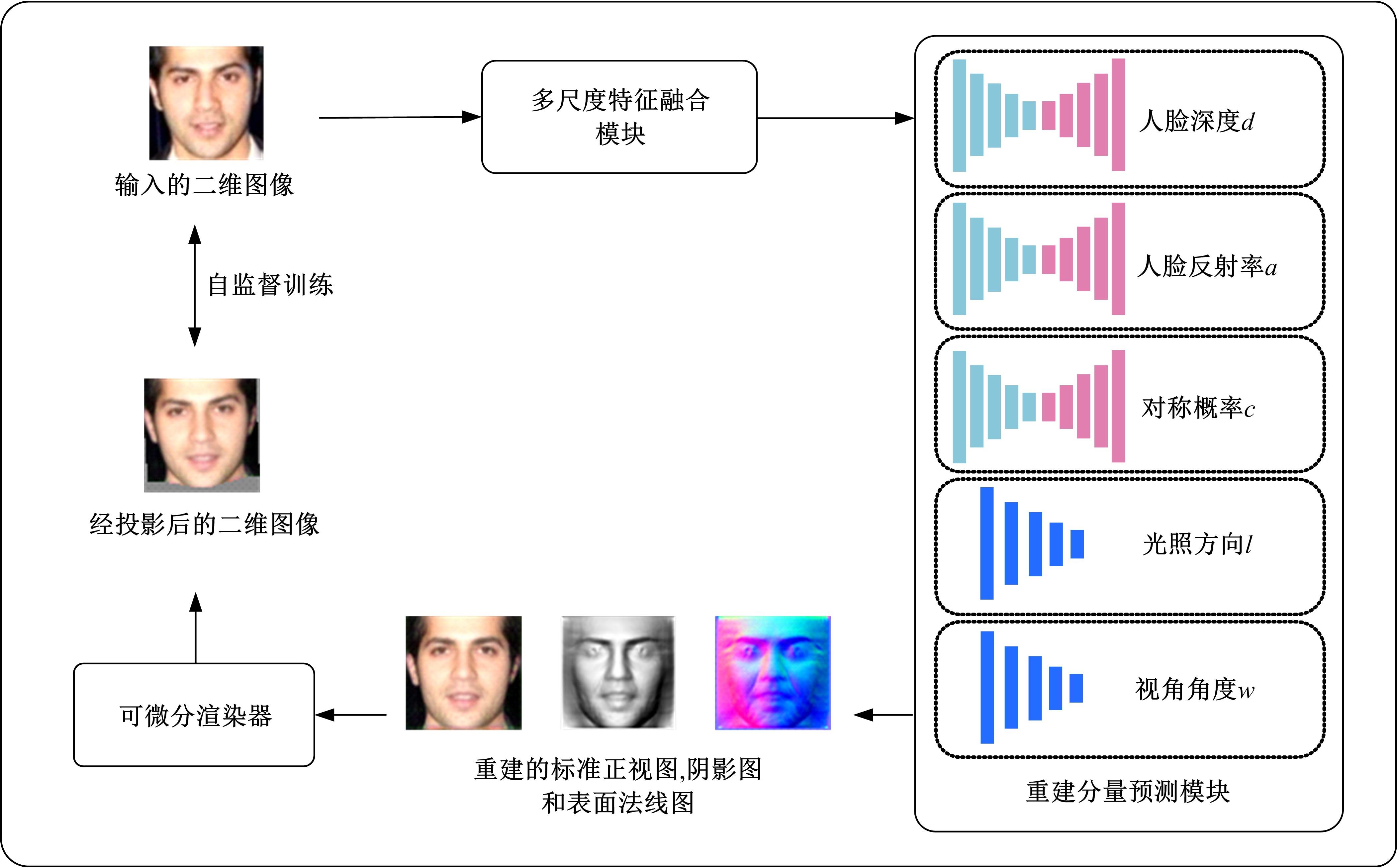
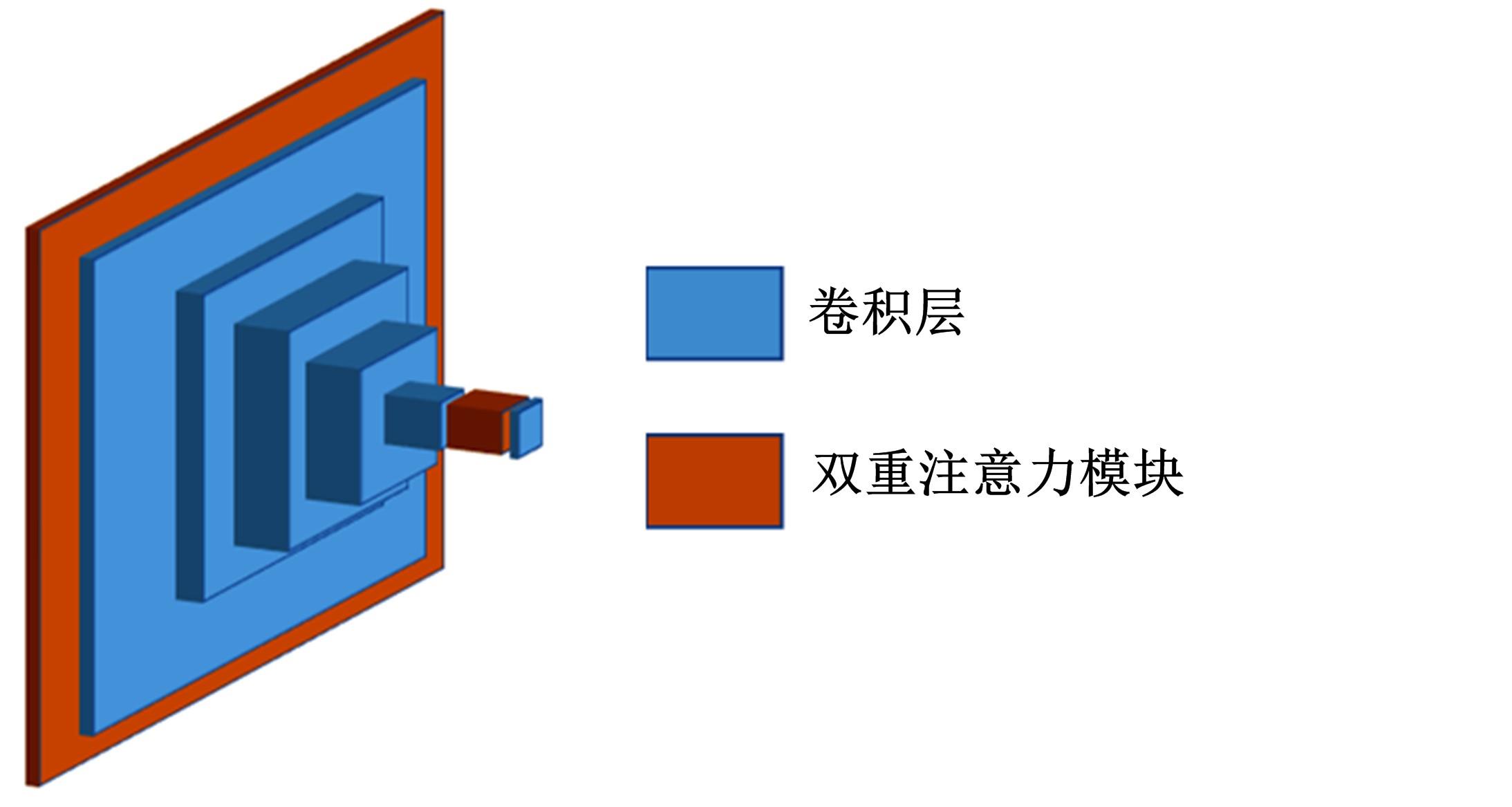

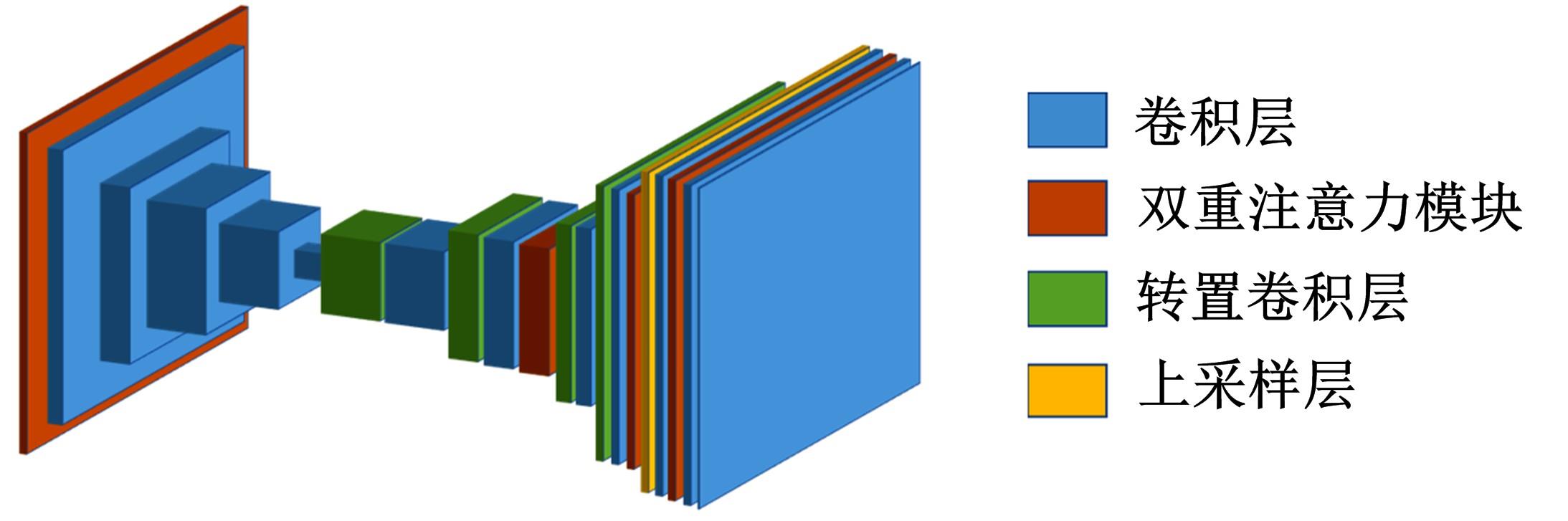
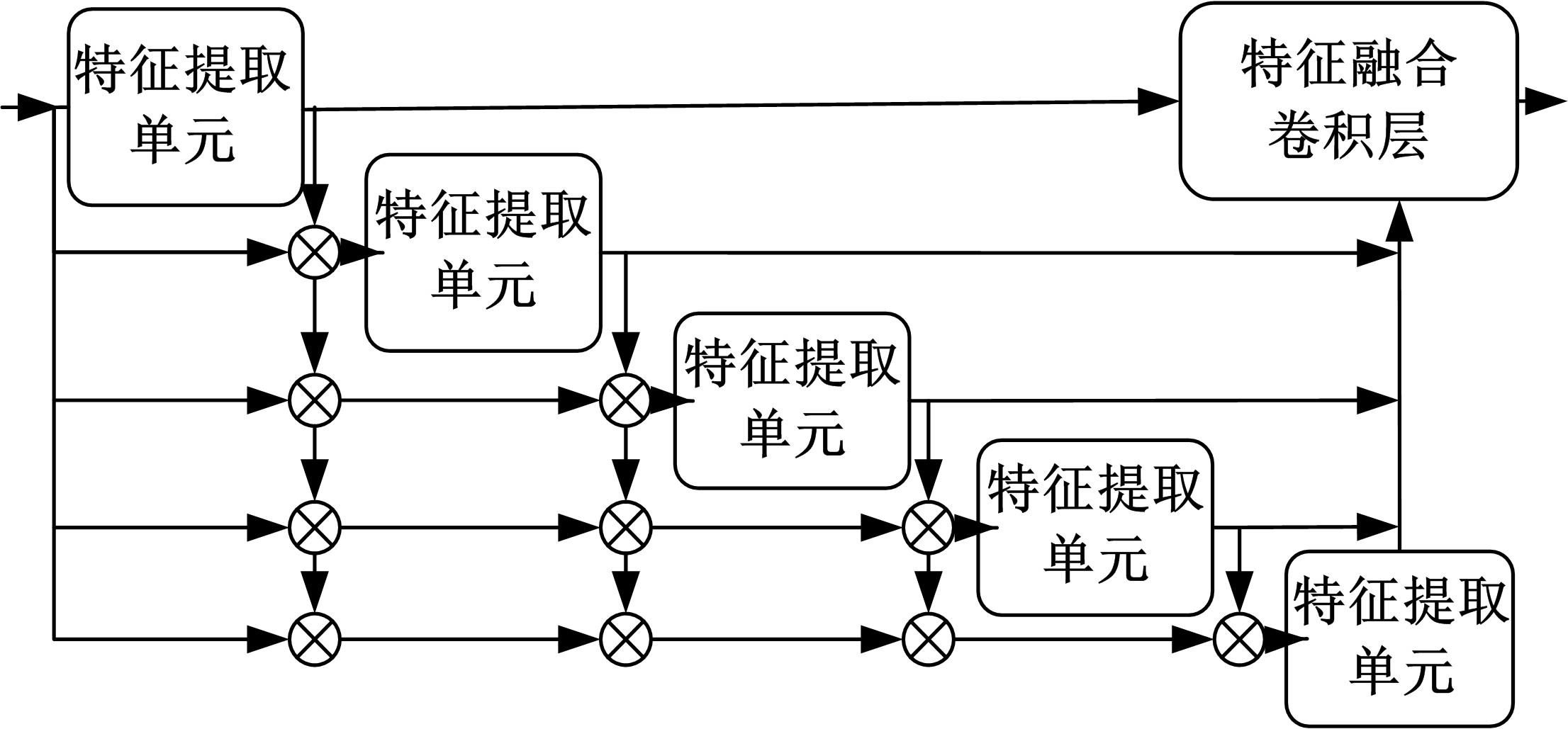
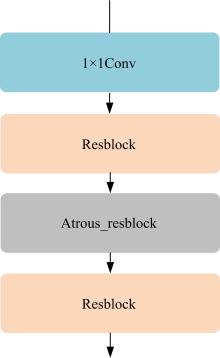
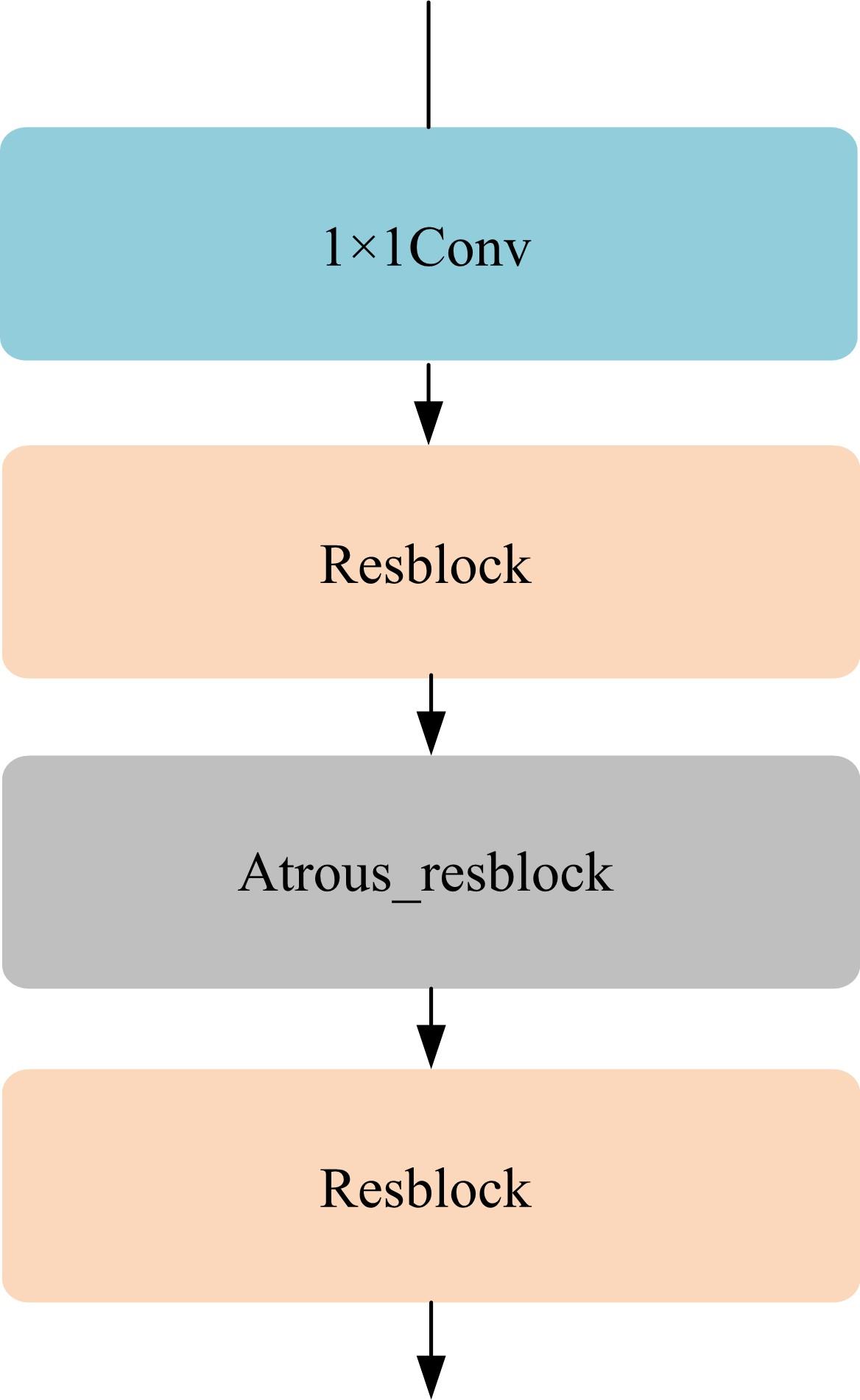
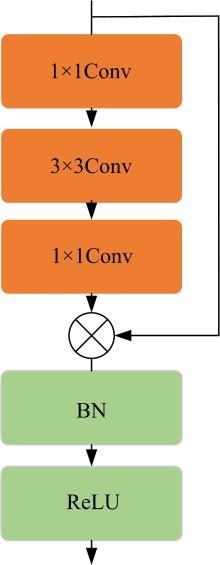
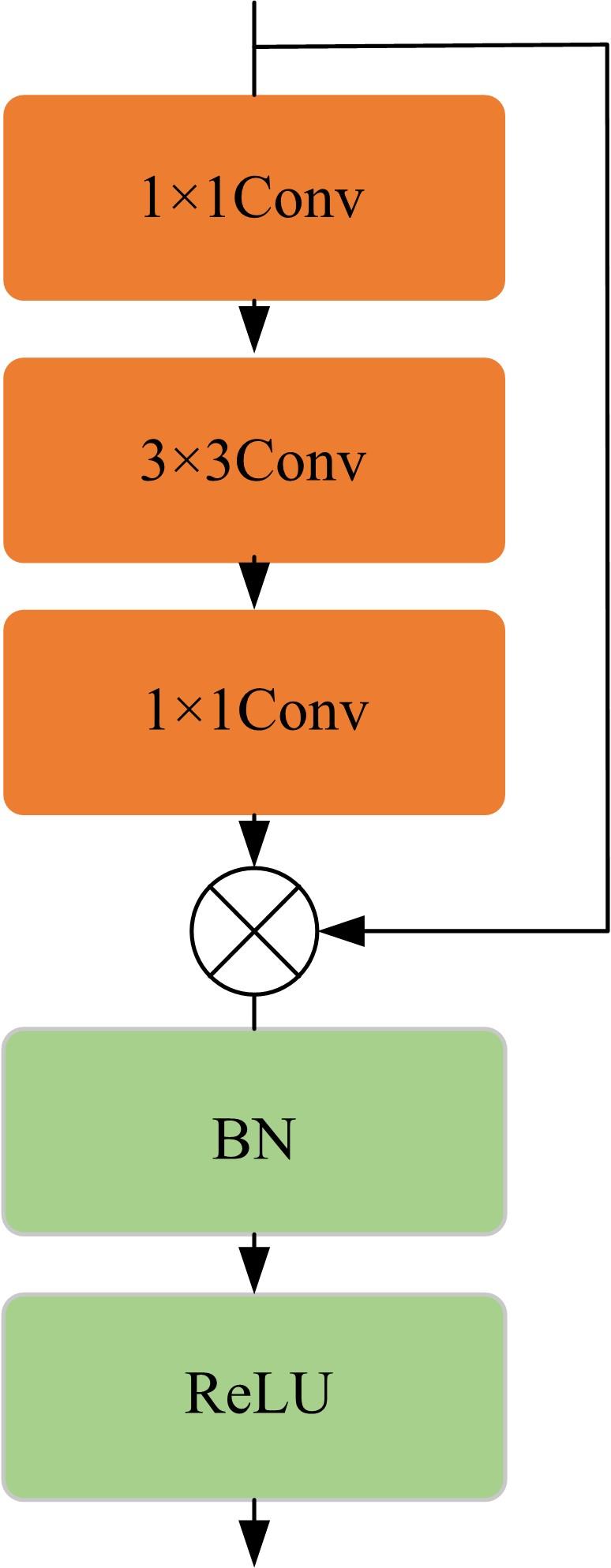
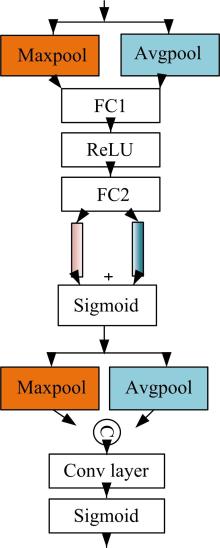
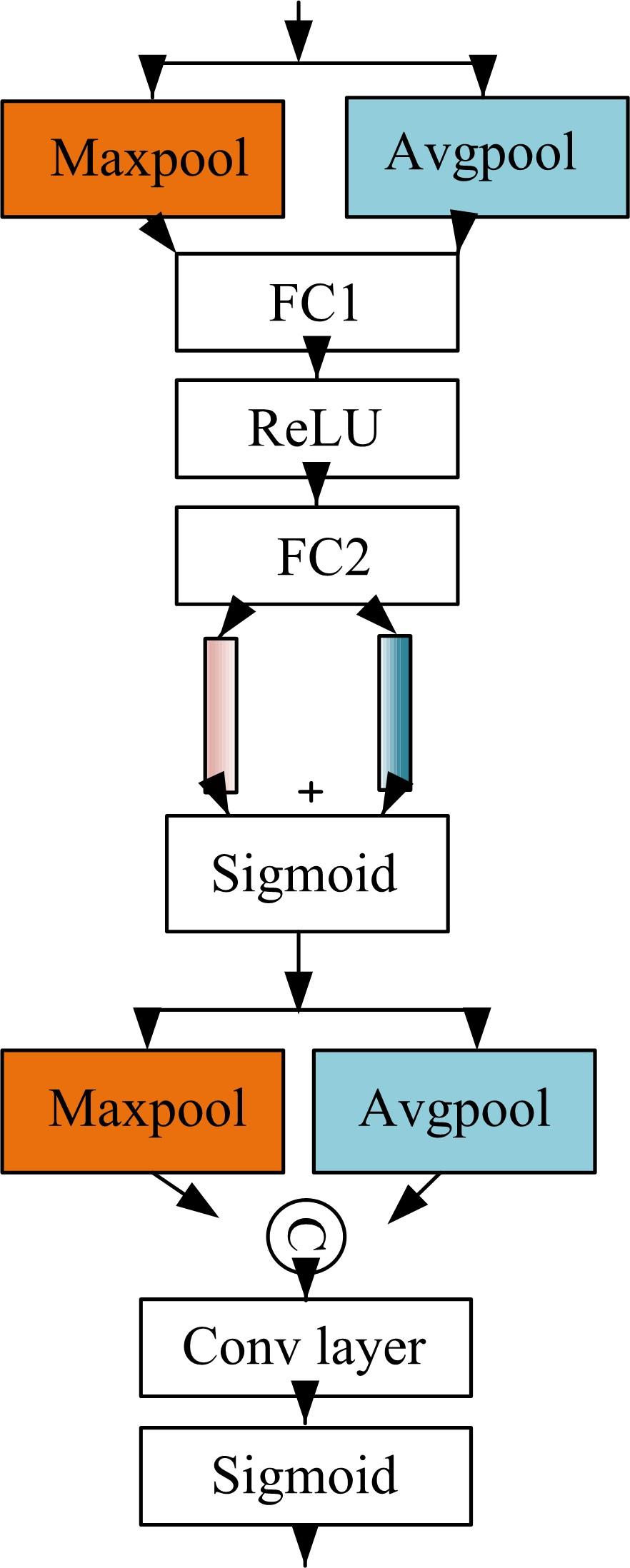




| 1 | 徐成华, 王蕴红, 谭铁牛. 三维人脸建模与应用[J]. 中国图象图形学报, 2004, 9(8): 893-903. |
| Xu Cheng-hua, Wang Yun-hong, Tan Tie-niu. Overview of research on 3D face modeling[J]. Journal of Image and Graphics, 2004, 9(8): 893-903. | |
| 2 | 王琨, 郑南宁. 基于SFM算法的三维人脸模型重建[J]. 计算机学报, 2005, 28(6): 1048-1053. |
| Wang Kun, Zheng Nan-ning. 3D face modeling based on SFM algorithm[J]. Chinese Journal of Computers, 2005, 28(6): 1048-1053. | |
| 3 | Zhu Wen-bin, Wu Hsiang-tao, Chen Ze-yu, et al. Reda: reinforced differentiable attribute for 3D face reconstruction[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 4958-4967. |
| 4 | Zhu Xiang-yu, Lei Zhen, Liu Xiao-ming, et al. Face alignment across large poses: a 3D solution[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 146-155. |
| 5 | Richardson E, Sela M, Or-El R, et al. Learning detailed face reconstruction from a single image[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1259-1268. |
| 6 | Blanz V, Vetter T. A morphable model for the synthesis of 3D faces [C]∥Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, New York, USA, 1999: 187-194. |
| 7 | Booth J, Roussos A, Ponniah A, et al. Large scale 3D morphable models[J]. International Journal of Computer Vision, 2018, 126(2): 233-254. |
| 8 | Tran L, Liu Xiao-ming. On learning 3D face morphable model from in-the-wild images [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(1): 157-171. |
| 9 | Cao Chen, Weng Yan-lin, Zhou Shun, et al. Facewarehouse: a 3D facial expression database for visual computing[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 20(3): 413-425. |
| 10 | Tuan Tran A, Hassner T, Masi I, et al. Regressing robust and discriminative 3D morphable models with a very deep neural network[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 5163-5172. |
| 11 | Chang F J, Tran A T, Hassner T, et al. Expnet: Landmark-free, deep, 3D facial expressions[C]∥The 13th IEEE International Conference on Automatic Face and Gesture Recognition, Xi'an, China, 2018: 122-129. |
| 12 | Chang F J, Tuan Tran A, Hassner T, et al. Faceposenet: making a case for landmark-free face alignment[C]∥Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 2017: 1599-1608. |
| 13 | Gecer B, Ploumpis S, Kotsia I, et al. Ganfit: generative adversarial network fitting for high fidelity 3d face reconstruction[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 1155-1164. |
| 14 | Jackson A S, Bulat A, Argyriou V, et al. Large pose 3D face reconstruction from a single image via direct volumetric CNN regression[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1031-1039. |
| 15 | Feng Yao, Wu Fan, Shao Xiao-hu, et al. Joint 3d face reconstruction and dense alignment with position map regression network[C]∥Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 534-551. |
| 16 | Tewari A, Zollhofer M, Kim H, et al. Mofa: model-based deep convolutional face autoencoder for unsupervised monocular reconstruction[C]∥Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 2017: 1274-1283. |
| 17 | Sanyal S, Bolkart T, Feng Hai-wen, et al. Learning to regress 3D face shape and expression from an image without 3D supervision[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 7763-7772. |
| 18 | Tu Xiao-guang, Zhao Jian, Xie Mei, et al. 3D face reconstruction from a single image assisted by 2d face images in the wild[J]. IEEE Transactions on Multimedia, 2020, 23: 1160-1172. |
| 19 | Wu S Z, Rupprecht C, Vedaldi A. Unsupervised learning of probably symmetric deformable 3d objects from images in the wild[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 1-10. |
| 20 | Gao Yuan, Yuille A L. Exploiting symmetry and/or manhattan properties for 3d object structure estimation from single and multiple images[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA,2017:7408-7417. |
| 21 | Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation[C]∥International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 2015: 234-241. |
| 22 | Zhang Ruo, Tsai P S, Cryer J E, et al. Shape-from-shading: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21(8): 690-706. |
| 23 | Kato H, Ushiku Y, Harada T. Neural 3D mesh renderer[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3907-3916. |
| 24 | Yang Mao-ke, Yu Kun, Zhang Chi, et al. Denseaspp for semantic segmentation in street scenes[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3684-3692. |
| 25 | Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]∥Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 3-19. |
| 26 | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition [J]. arXiv preprint arXiv:, 2014. |
| 27 | Liu Zi-wei, Luo Ping, Wang Xiao-gang, et al. Deep learning face attributes in the wild[C]∥Proceedings of the IEEE International Conference on Computer Vision,Santiago, Chile, 2015: 3730-3738. |
| 28 | Paysan P, Knothe R, Amberg B, et al. A 3D face model for pose and illumination invariant face recognition[C]∥The Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance,Genova, Italy, 2009: 296-301. |
| 29 | Zafeiriou S, Hansen M, Atkinson G, et al. The photoface database[C]∥CVPR Workshops, Colorado Springs, USA, 2011: 132-139. |
| 30 | Sengupta S, Kanazawa A, Castillo C D, et al. Sfsnet: learning shape, reflectance and illuminance of facesin the wild[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 44(6): 6296-6305. |
| 31 | Xiao Jian-xiong, Hays J, Ehinger K A, et al. Sun database: large-scale scene recognition from abbey to zoo[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, USA, 2010: 3485-3492. |
| 32 | Eigen D, Puhrsch C, Fergus R. Depth map prediction from a single image using a multi-scale deep network[C]∥Proceedings of the 27th International Conference on Neural Information Processing Systems,Bangkok, Thailand, 2014: 2366-2374. |
| 33 | Sela M, Richardson E, Kimmel R. Unrestricted facial geometry reconstruction using image-to-image translation[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 1576-1585. |
| 34 | Tran A T, Hassner T, Masi I, et al. Extreme 3D face reconstruction: seeing through occlusions[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3935-3944. |
| 35 | Trigeorgis G, Snape P, Kokkinos I, et al. Face normal "in-the-wild" using fully convolutional networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 38-47. |
| [1] | Hong-wei ZHAO,Jian-rong ZHANG,Jun-ping ZHU,Hai LI. Image classification framework based on contrastive self⁃supervised learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(8): 1850-1856. |
| [2] | Yong-jie MA,Min CHEN. Dynamic multi⁃objective optimization algorithm based on Kalman filter prediction strategy [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(6): 1442-1458. |
| [3] | Ji-hong OUYANG,Ze-qi GUO,Si-guang LIU. Dual⁃branch hybrid attention decision net for diabetic retinopathy classification [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(3): 648-656. |
| [4] | Xian-tong LI,Wei QUAN,Hua WANG,Peng-cheng SUN,Peng-jin AN,Yong-xing MAN. Route travel time prediction on deep learning model through spatiotemporal features [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(3): 557-563. |
| [5] | Xiao⁃lei CHEN,Yong⁃feng SUN,Ce LI,Dong⁃mei LIN. Stable anti⁃noise fault diagnosis of rolling bearing based on CNN⁃BiLSTM [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(2): 296-309. |
| [6] | Xiao-ying PAN,De WEI,Yi-zhe ZHAO. Detecetion of lung nodule based on mask R-CNN and contextual convolutional neural network [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(10): 2419-2427. |
| [7] | Hong-wei ZHAO,Dong-sheng HUO,Jie WANG,Xiao-ning LI. Image classification of insect pests based on saliency detection [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(6): 2174-2181. |
| [8] | De-xing WANG,Ruo-you WU,Hong-chun YUAN,Peng GONG,Yue WANG. Underwater image restoration based on multi-scale attention fusion and convolutional neural network [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1396-1404. |
| [9] | Ya-hui ZHAO,Fei-yang YANG,Zhen-guo ZHANG,Rong-yi CUI. Korean text structure discovery based on reinforcement learning and attention mechanism [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1387-1395. |
| [10] | Zhuo-jun XU,Wen-ting YANG,Cheng-zhi YANG,Yan-tao TIAN,Xiao-jun WANG. Improved residual neural network algorithm for radar intra-pulse modulation classification [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1454-1460. |
| [11] | Yuan-ning LIU,Di WU,Xiao-dong ZHU,Qi-xian ZHANG,Shuang-shuang LI,Shu-jun GUO,Chao WANG. User interface components detection algorithm based on improved YOLOv3 [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(3): 1026-1033. |
| [12] | Fu LIU,Lu LIU,Tao HOU,Yun LIU. Night road image enhancement method based on optimized MSR [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(1): 323-330. |
| [13] | Hai-ying ZHAO,Wei ZHOU,Xiao-gang HOU,Xiao-li ZHANG. Double-layer annotation of traditional costume images based on multi-task learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(1): 293-302. |
| [14] | Hong-wei ZHAO,Xiao-han LIU,Yuan ZHANG,Li-li FAN,Man-li LONG,Xue-bai ZANG. Clothing classification algorithm based on landmark attention and channel attention [J]. Journal of Jilin University(Engineering and Technology Edition), 2020, 50(5): 1765-1770. |
| [15] | Dan⁃tong OUYANG,Jun XIAO,Yu⁃xin YE. Distant supervision for relation extraction with weakconstraints of entity pairs [J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(3): 912-919. |
|
||