Journal of Jilin University(Engineering and Technology Edition) ›› 2022, Vol. 52 ›› Issue (3): 666-674.doi: 10.13229/j.cnki.jdxbgxb20200842
Deep reinforcement learning model for text games
Yong LIU( ),Lei XU,Chu-han ZHANG
),Lei XU,Chu-han ZHANG
- School of Computer Science and Technology,Heilongjiang University,Harbin 150080,China
CLC Number:
- TP181
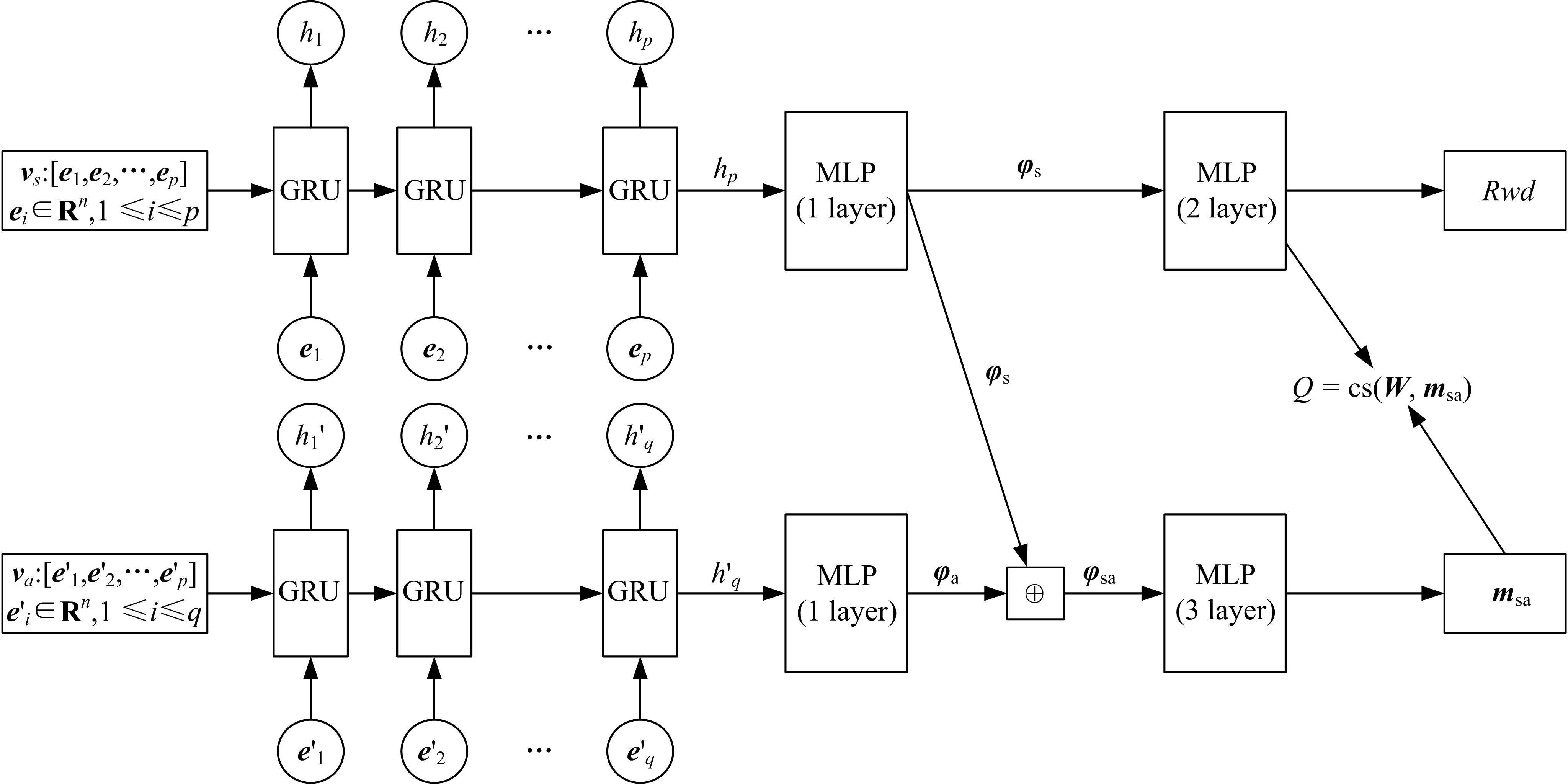
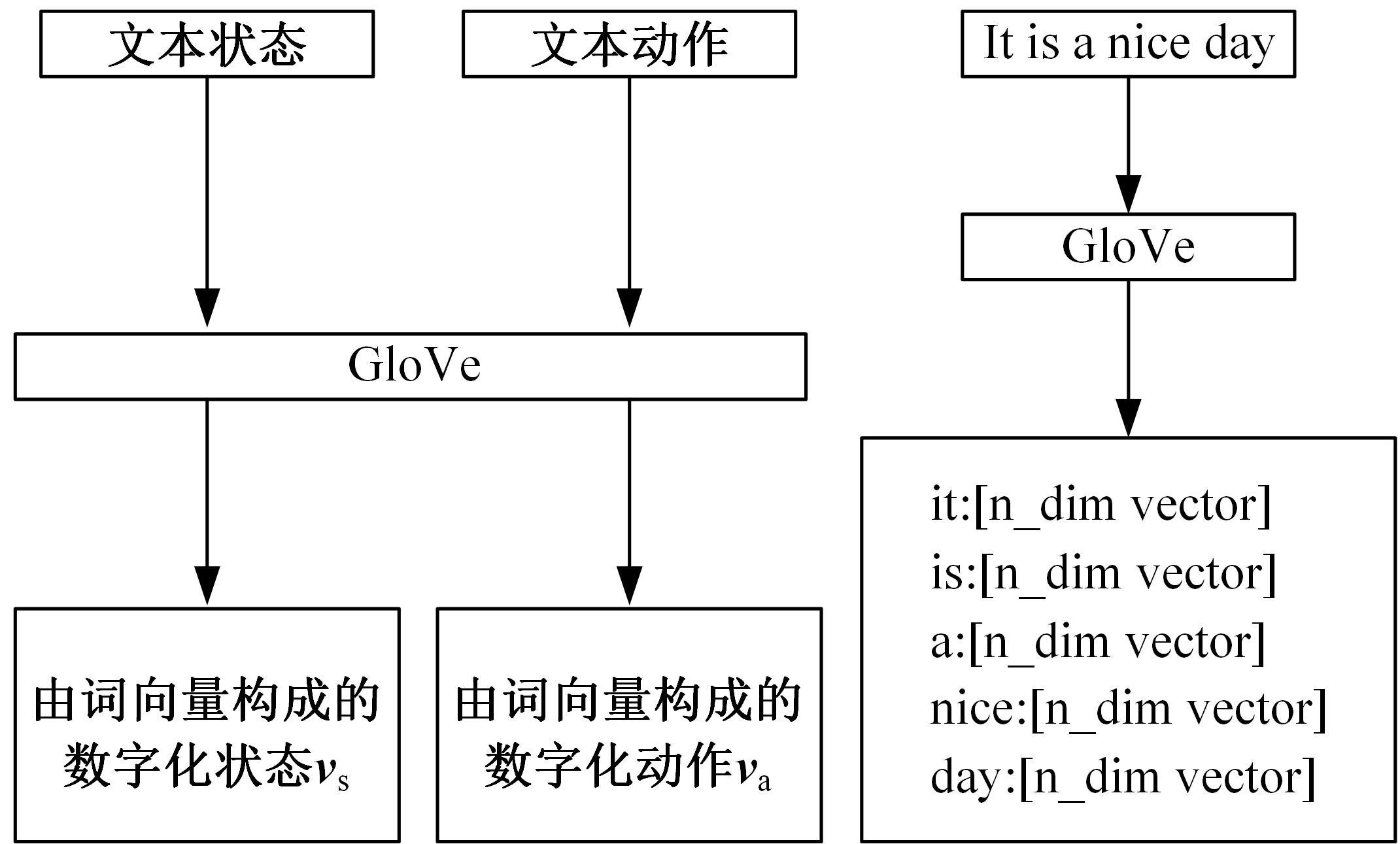
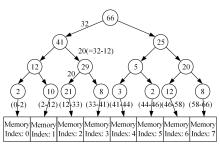
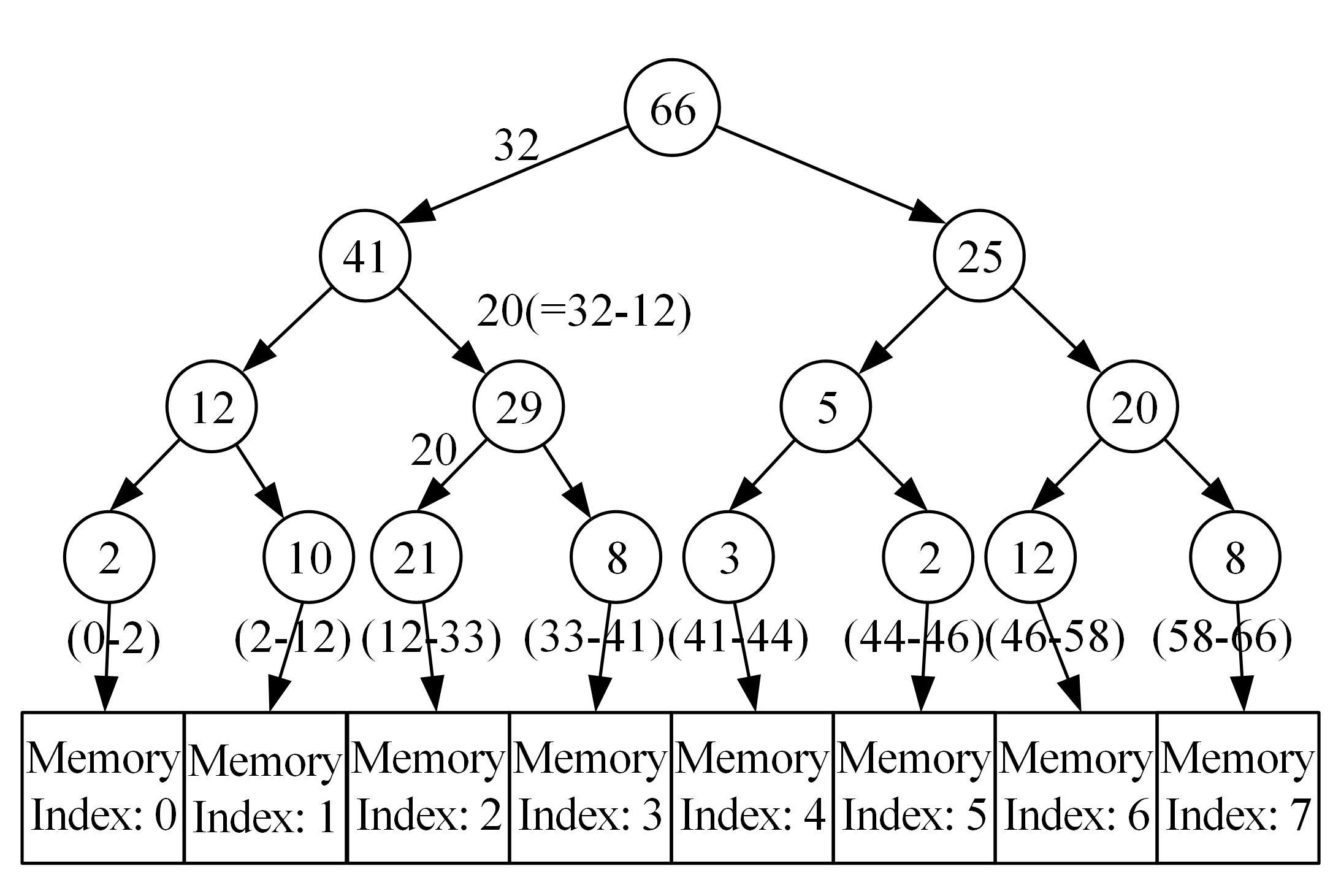
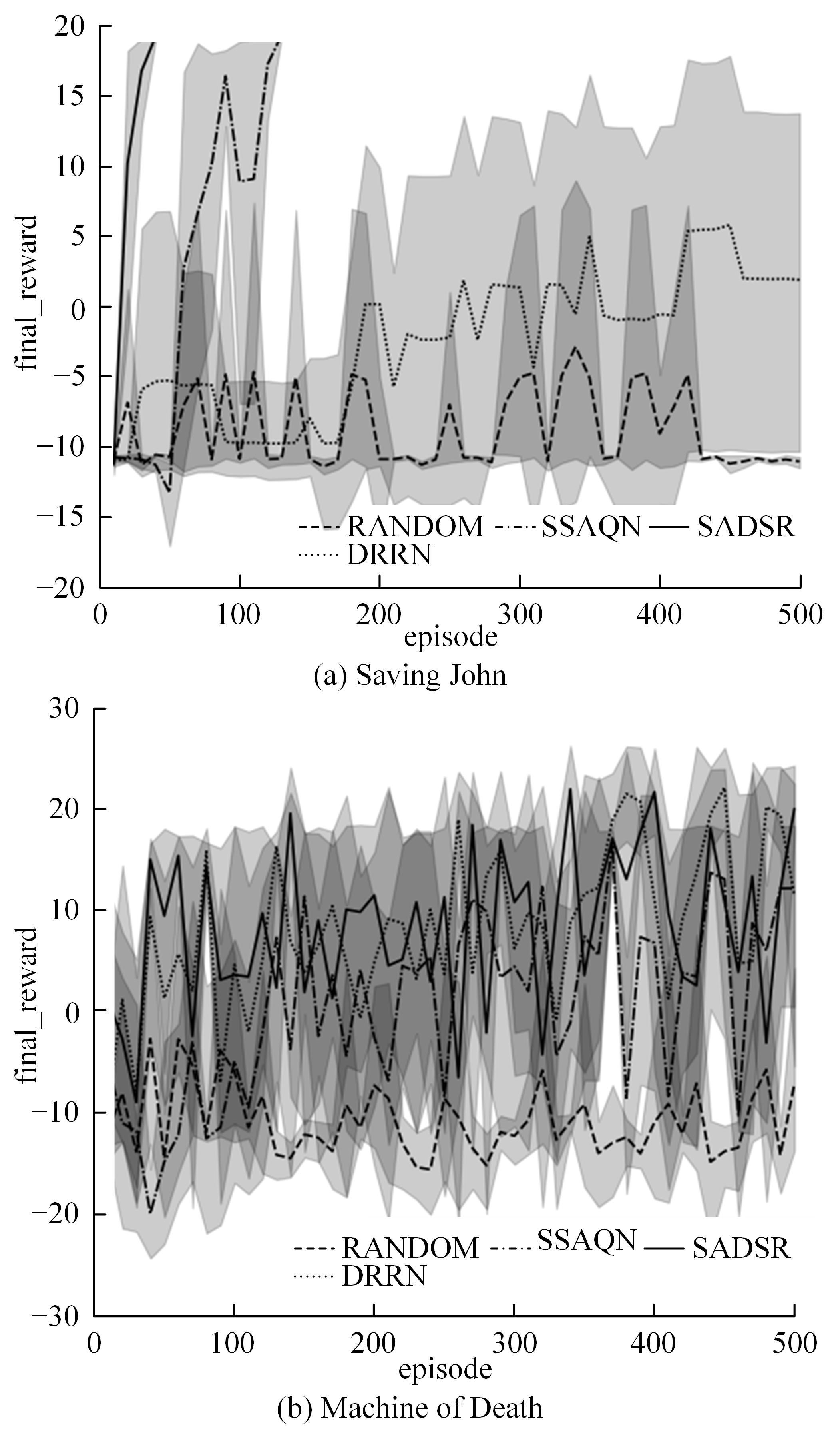
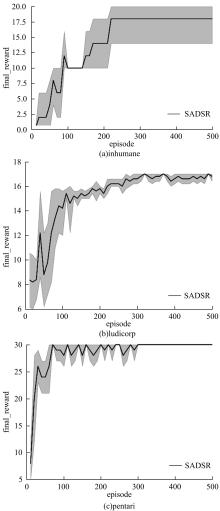
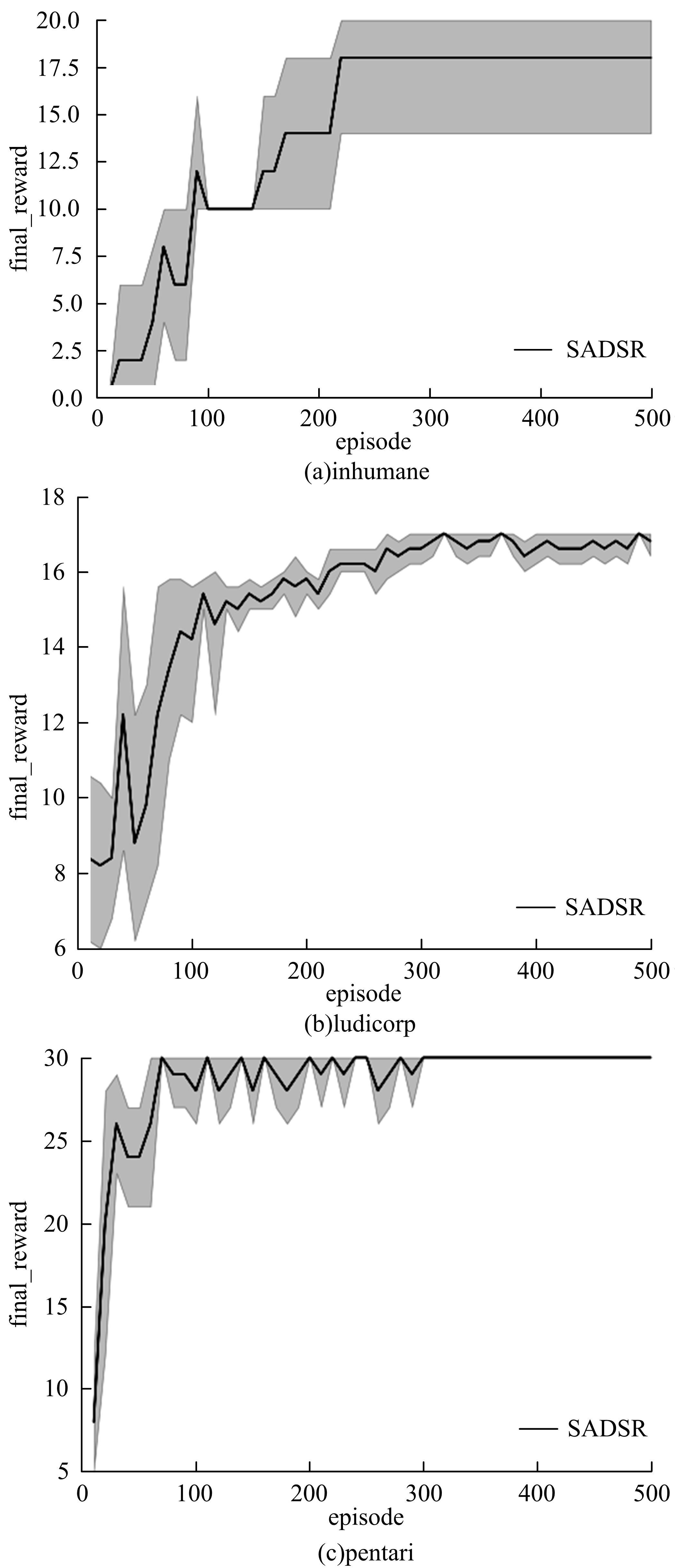
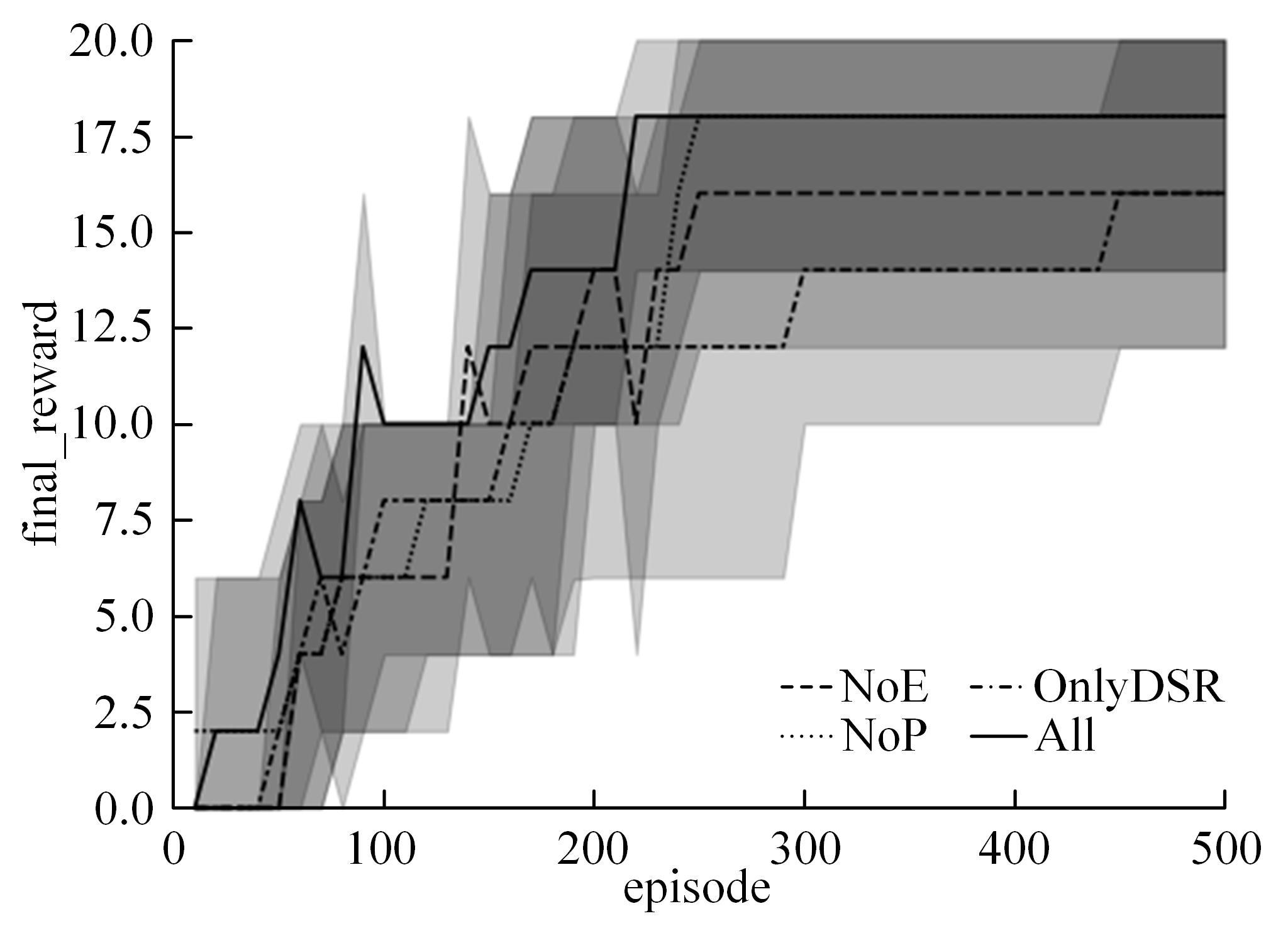
| 1 | 赵亚慧, 杨飞扬, 张振国,等. 基于强化学习和注意力机制的朝鲜语文本结构发现[J]. 吉林大学学报: 工学版, 2021, 51(4): 1387-1395. |
| Zhao Ya-hui, Yang Fei-yang, Zhang Zhen-guo, et al. Korean text structure discovery based on reinforcement learning and attention mechanism[J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1387-1395. | |
| 2 | Coskun-Setirek A, Mardikyan S. Understanding the adoption of voice activated personal assistants[J]. International Journal of E-Services and Mobile Applications, 2017, 9(3): 1-21. |
| 3 | Green S, Wang S, Chuang J, et al. Human effort and machine learnability in computer aided translation[C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1225-1236. |
| 4 | Pietquin O, Renals S. ASR system modeling for automatic evaluation and optimization of dialogue systems[C]∥Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, Florida, USA, 2002: 45-48. |
| 5 | Dolgov D, Thrun S. Detection of principle directions in unknown environments for autonomous navigation[C]∥Robotics: Science and Systems, Zurich, Switzerland, 2009: 73-80. |
| 6 | Sutton R S, Barto A G. Reinforcement Learning: An Introduction[M]. Cambridge, MA, USA: MIT Press, 1998. |
| 7 | Pennington J, Socher R, Manning C D. GloVe: global vectors for word representation[C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1532-1543. |
| 8 | Gershman S, Moore C D, Todd M T, et al. The successor representation and temporal context[J]. Neural Computation, 2012, 24(6): 1553-1568. |
| 9 | Kulkarni T D, Saeedi A, Gautam S, et al. Deep successor reinforcement learning[EB/OL].[2020-11-02]. |
| 10 | Cho K, Merrienboer B V, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1724-1734. |
| 11 | Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J/OL]. [2020-11-02]. |
| 12 | Schaul T, Quan J, Antonoglou I, et al. Prioritized experience replay[J/OL]. [2020-11-03]. |
| 13 | He J, Chen J S, He X D, et al. Deep reinforcement learning with a natural language action space[C]∥Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Washington, Seattle, USA, 2016: 1621-1630. |
| 14 | Zelinka M. Baselines for reinforcement learning in text games[C]∥IEEE 30th International Conference on Tools with Artificial Intelligence, Volos, Greece, 2018: 320-327. |
| 15 | Hausknecht M J, Ammanabrolu P, M-A Côté, et al. Interactive fiction games: a colossal adventure[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 7903-7910. |
| 16 | Brockman G, Cheung V, Pettersson L, et al. Openai gym[J/OL]. [2020-11-08]. |
| 17 | Hausknecht M J, Loynd R, Yang G, et al. NAIL: a general interactive fiction agent[J/OL]. [2020-11-08]. |
| 18 | Narasimhan K, Kulkarni T D, Barzilay R, et al. Language understanding for text-based games using deep reinforcement learning[C]∥Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 2015: 1-11. |
| [1] | Jing-pei LEI,Dan-tong OUYANG,Li-ming ZHANG. Relation domain and range completion method based on knowledge graph embedding [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(1): 154-161. |
| [2] | Zhi-hua LI,Ye-chao ZHANG,Guo-hua ZHAN. Realtime mosaic and visualization of 3D underwater acoustic seabed topography [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(1): 180-186. |
| [3] | Yan-lei XU,Run HE,Yu-ting ZHAI,Bin ZHAO,Chen-xiao LI. Weed identification method based on deep transfer learning in field natural environment [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(6): 2304-2312. |
| [4] | Yong YANG,Qiang CHEN,Fu-heng QU,Jun-jie LIU,Lei ZHANG. SP⁃k⁃means-+ algorithm based on simulated partition [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(5): 1808-1816. |
| [5] | Ya-hui ZHAO,Fei-yang YANG,Zhen-guo ZHANG,Rong-yi CUI. Korean text structure discovery based on reinforcement learning and attention mechanism [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1387-1395. |
| [6] | Yan-hua DONG,Jing-wei LIU,Jing-hua ZHAO,Liang LI,Fang-xi XIE. Real-time torque tracking control based on BPNN online learning prediction model [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1405-1413. |
| [7] | Shuai LYU,Jing LIU. Stochastic local search heuristic method based on deep reinforcement learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1420-1426. |
| [8] | Fu LIU,Yi-xin LIANG,Tao HOU,Yang SONG,Bing KANG,Yun LIU. Improvement of fuzzy c-harmonic mean algorithm on unbalanced data [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1447-1453. |
| [9] | Fu-hua SHANG,Mao-jun CAO,Cai-zhi WANG. Local outlier data mining based on artificial intelligence technology [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(2): 692-696. |
| [10] | Hai-ying ZHAO,Wei ZHOU,Xiao-gang HOU,Xiao-li ZHANG. Double-layer annotation of traditional costume images based on multi-task learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(1): 293-302. |
| [11] | Dan-tong OUYANG,Cong MA,Jing-pei LEI,Sha-sha FENG. Knowledge graph embedding with adaptive sampling [J]. Journal of Jilin University(Engineering and Technology Edition), 2020, 50(2): 685-691. |
| [12] | Yi-bin LI,Jia-min GUO,Qin ZHANG. Methods and technologies of human gait recognition [J]. Journal of Jilin University(Engineering and Technology Edition), 2020, 50(1): 1-18. |
| [13] | Qian XU,Ying LI,Gang WANG. Pedestrian-vehicle detection based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(5): 1661-1667. |
| [14] | Wan-fu GAO,Ping ZHANG,Liang HU. Nonlinear feature selection method based on dynamic change of selected features [J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(4): 1293-1300. |
| [15] | Shun YANG,Yuan⁃de JIANG,Jian WU,Hai⁃zhen LIU. Autonomous driving policy learning based on deep reinforcement learning and multi⁃type sensor data [J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(4): 1026-1033. |
|
||