吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (10): 3169-3179.doi: 10.13229/j.cnki.jdxbgxb.20231428
• 交通运输工程·土木工程 • 上一篇
基于环境表征的强化学习自动驾驶策略
罗玉涛1,2( ),薛志成1,2
),薛志成1,2
- 1.华南理工大学 机械与汽车工程学院,广州 510640
2.广东省汽车工程重点实验室,广州 510640
Autonomous driving policy based on reinforcement learning with environment representation
Yu-tao LUO1,2(),Zhi-cheng XUE1,2
- 1.School of Mechanical and Automotive Engineering,South China University of Technology,Guangzhou 510640,China
2.Guangdong Provincial Key Laboratory of Automotive Engineering,Guangzhou 510640,China
摘要:
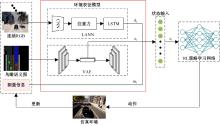
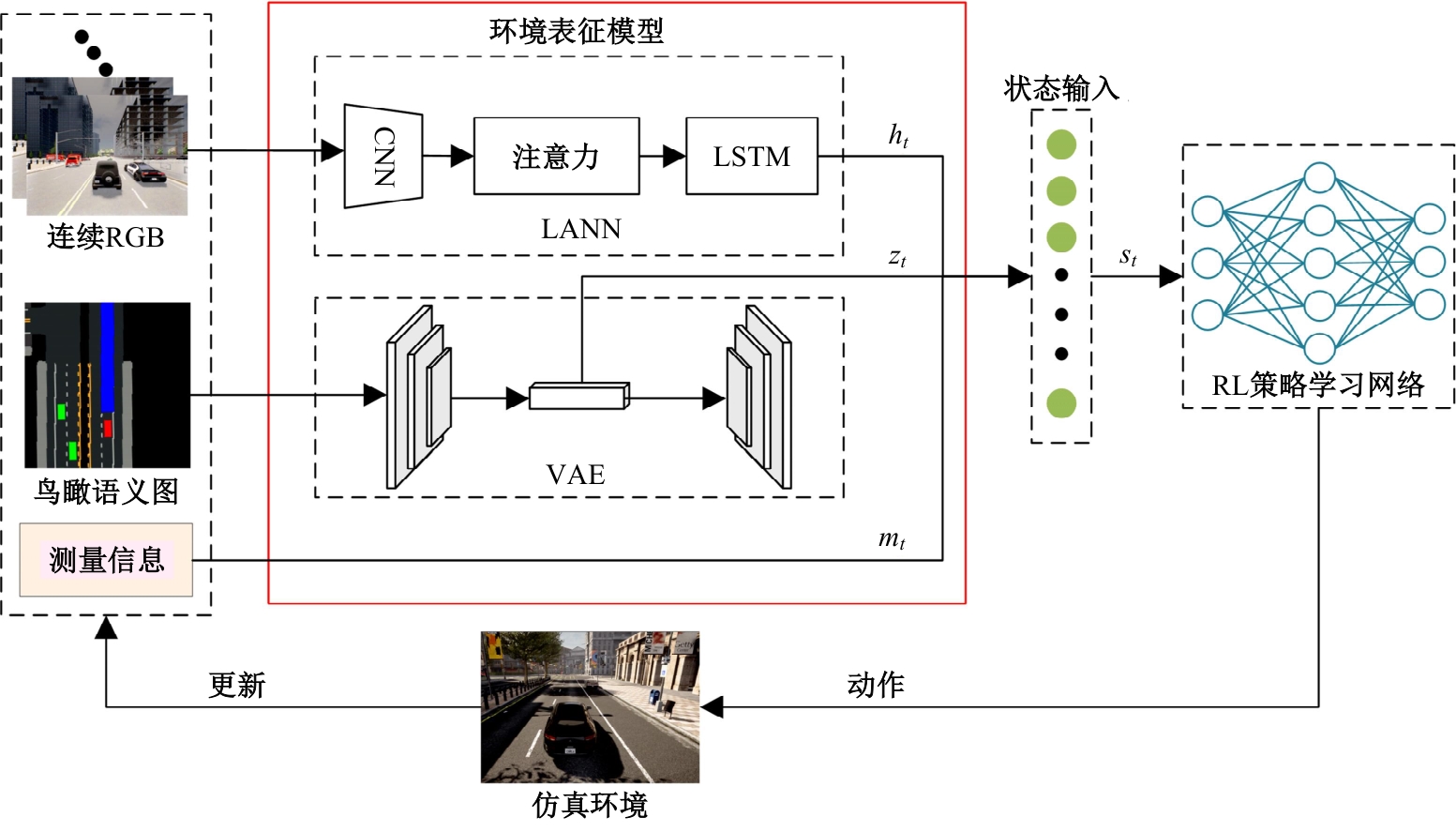
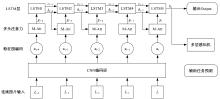
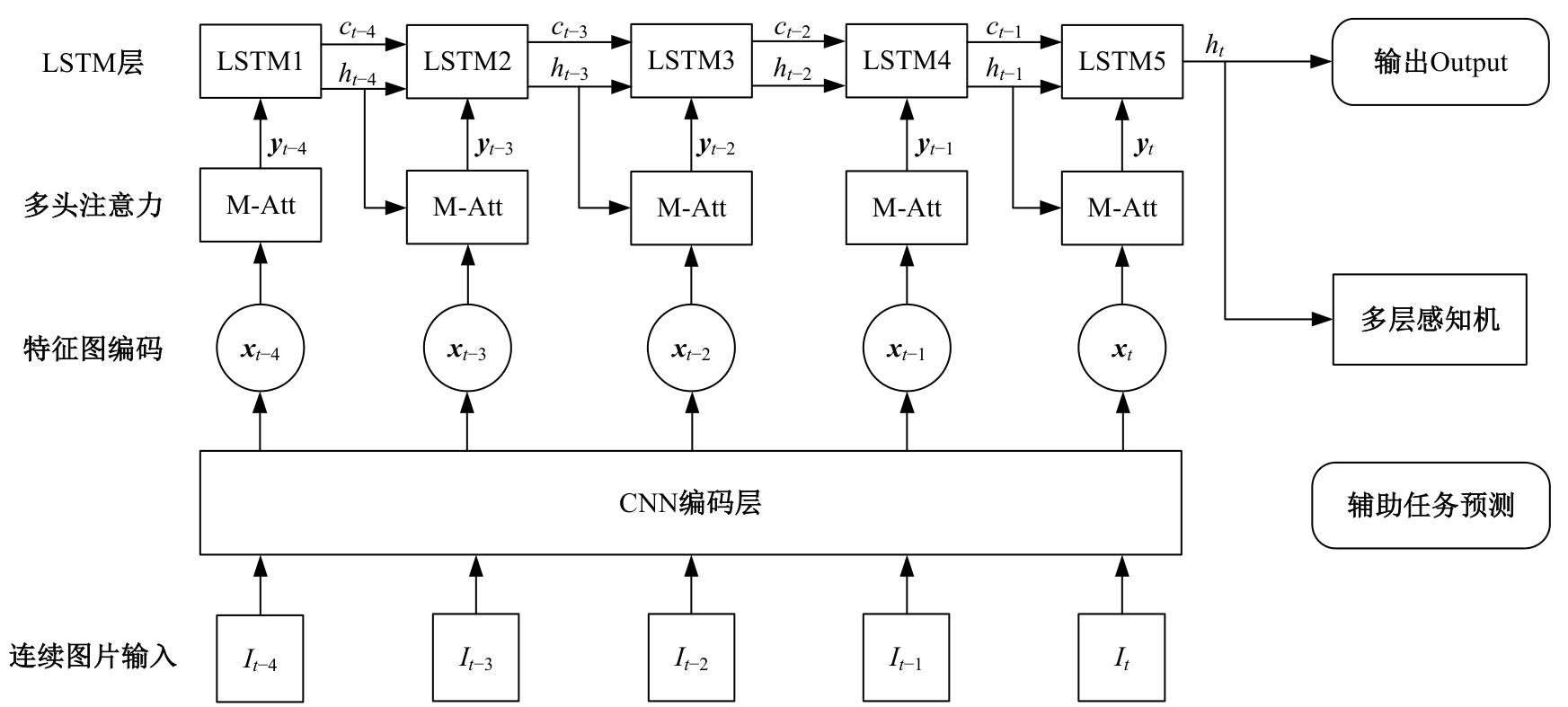
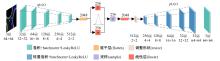
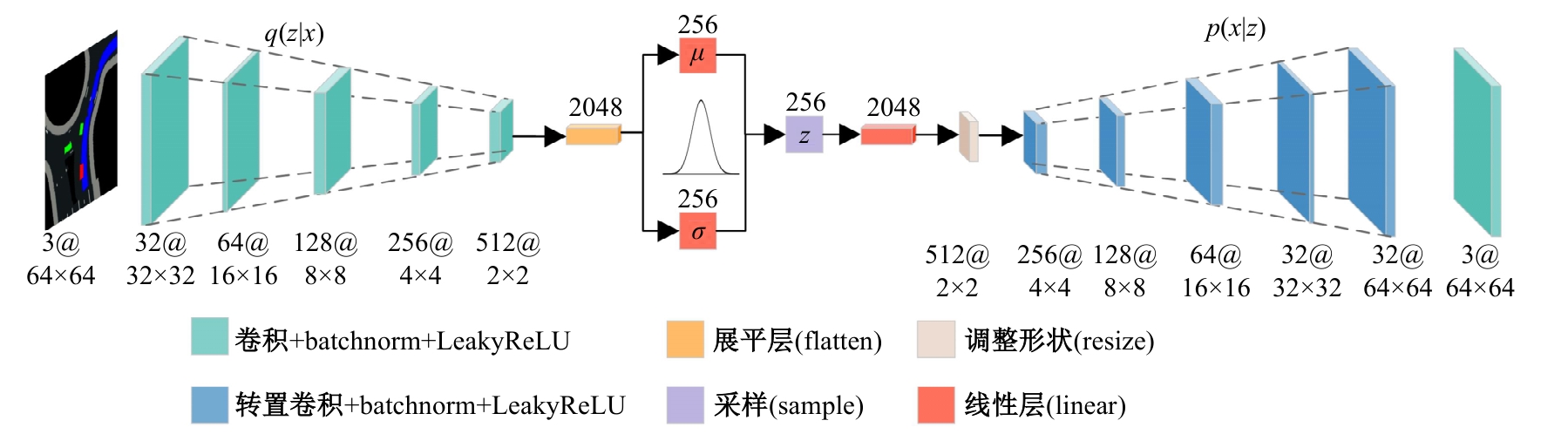
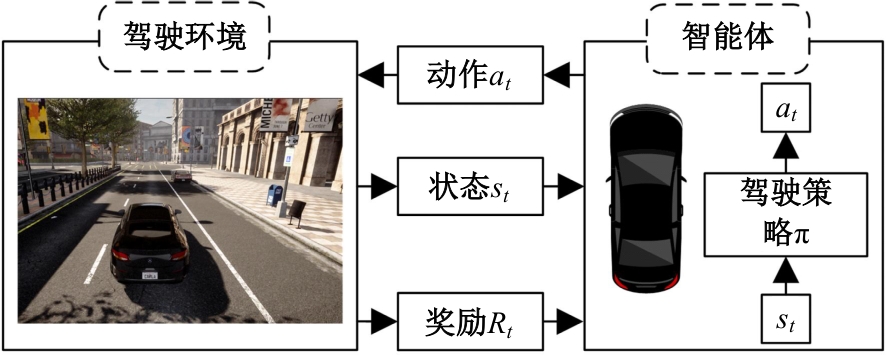
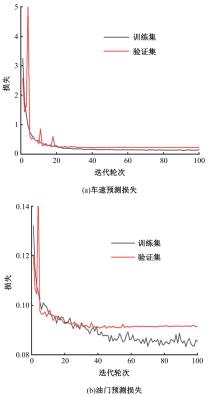
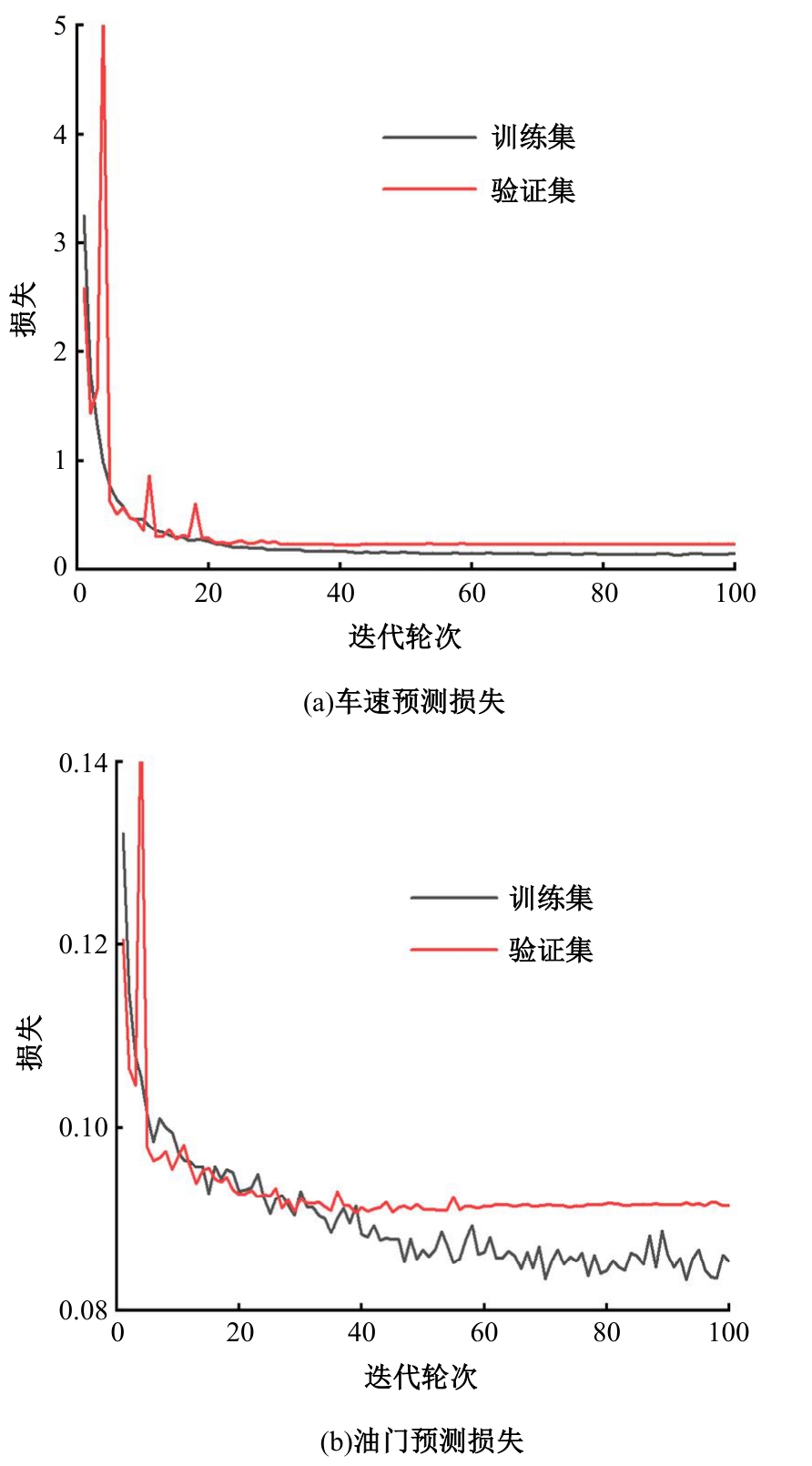
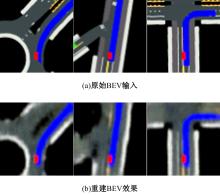
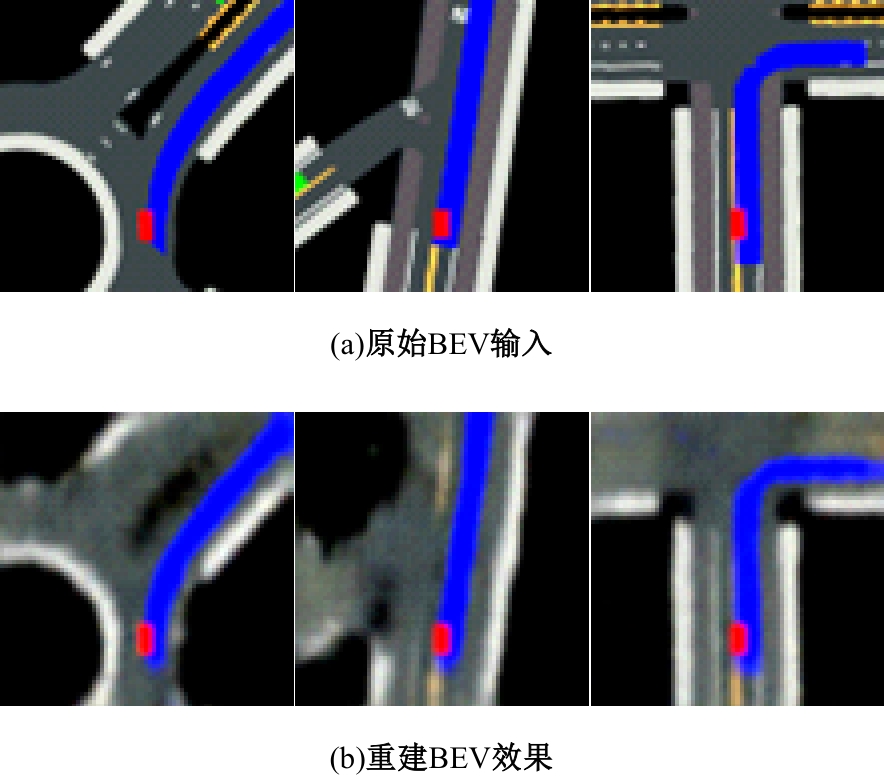
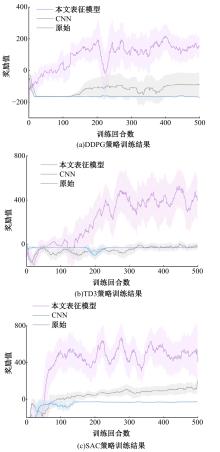
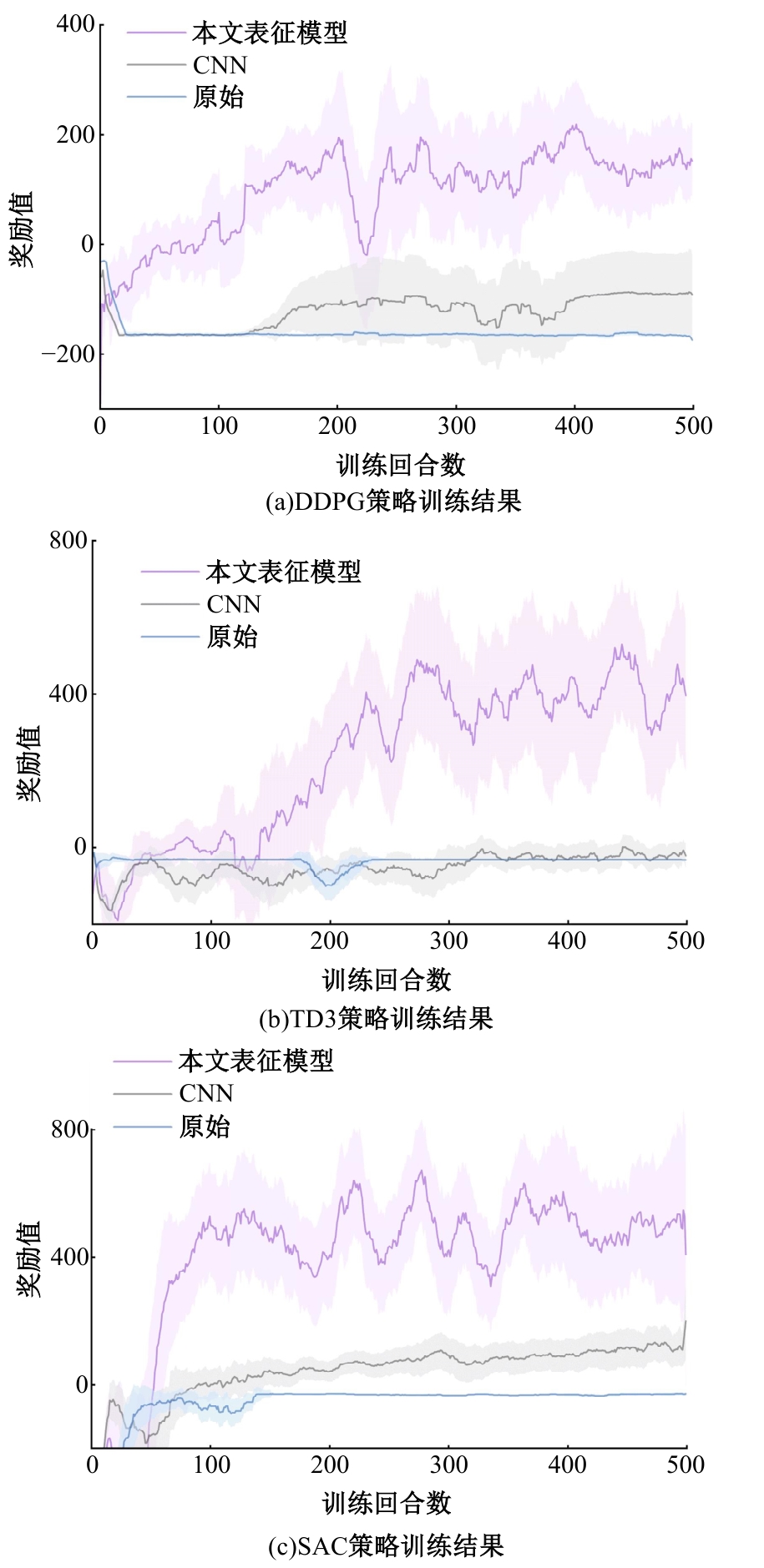
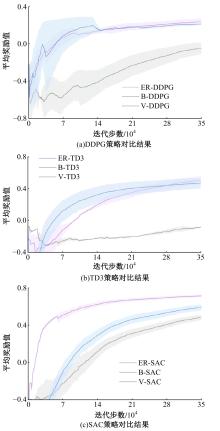
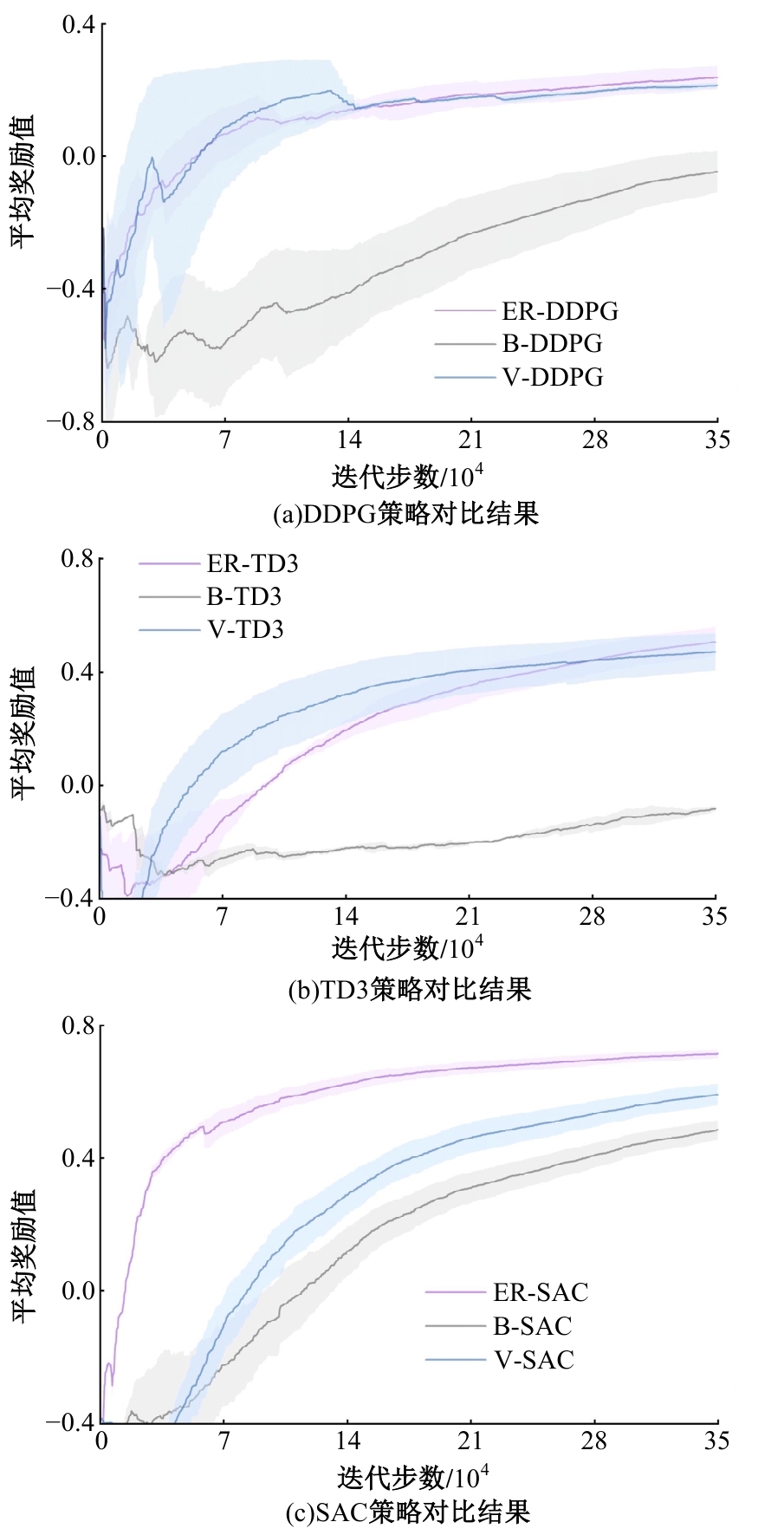
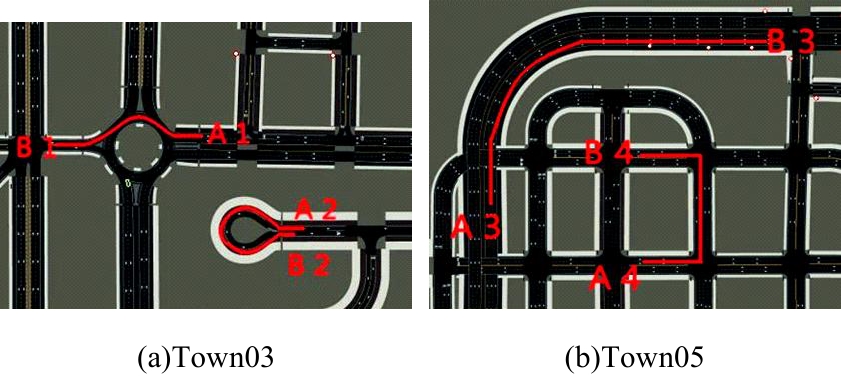
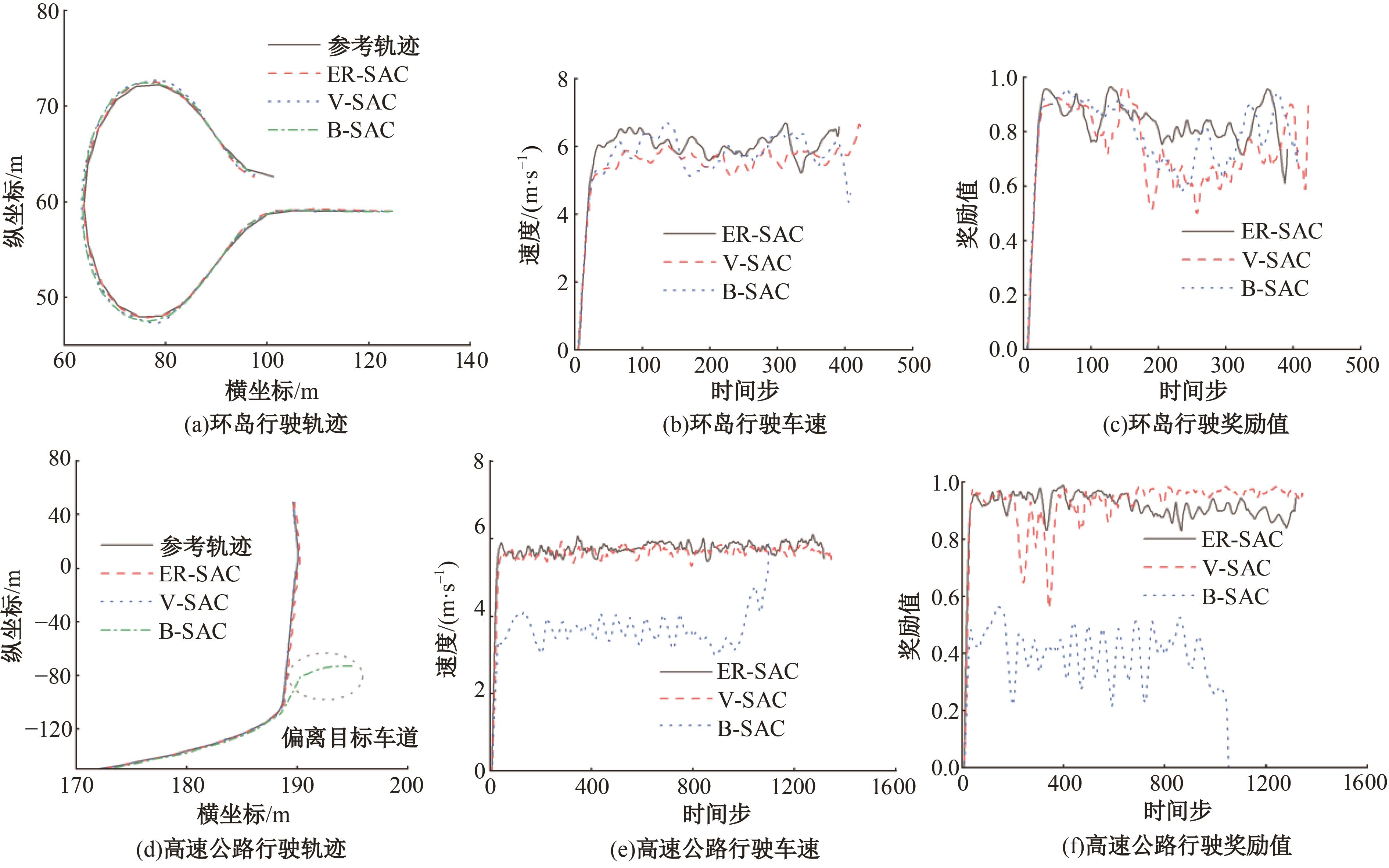
针对现阶段强化学习方法在自动驾驶应用中存在的数据效率低、场景适应性差问题,提出了一种基于环境表征的强化学习自动驾驶策略。首先,设计驾驶环境表征模型,结合多头注意力、卷积神经网络和长短期记忆网络从连续视觉输入中提取时空特征,并采用变分自编码器对鸟瞰图输入进行降维处理。其次,融合测量信息构成驾驶环境的综合表征。最后,将表征模型与多种经典的强化学习方法结合,并在Carla中进行仿真实验。结果表明,本文表征模型能够显著提升驾驶策略的学习效率,完成多种动静态驾驶任务,提升了智能体决策的准确性和不同场景的适应性。
中图分类号:
- U463.6

| [1] | Elallid B B, Benamar N, Hafid A S, et al. A comprehensive survey on the application of deep and reinforcement learning approaches in autonomous driving[J]. Journal of King Saud University-Computer and Information Sciences, 2022, 34(9): 7366-7390. |
| [2] | Aradi S. Survey of deep reinforcement learning for motion planning of autonomous vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 23(2): 740-759. |
| [3] | Kendall A, Hawke J, Janz D, et al. Learning to drive in a day[C]∥International Conference on Robotics and Automation(ICRA), Piscataway, USA, 2019: 8248-8254. |
| [4] | Dosovitskiy A, Ros G, Codevilla F, et al. CARLA: An open urban driving simulator[C]∥Proceedings of the 1st Annual Conference on Robot Learning,New York, USA, 2017: 1-16. |
| [5] | 杨顺, 蒋渊德, 吴坚, 等. 基于多类型传感数据的自动驾驶深度强化学习方法[J]. 吉林大学学报:工学版, 2019, 49(4): 1026-1033. |
| Yang Shun, Jiang Yuan-de, Wu Jian, et al. Autonomous driving policy learning based on deep reinforcement learning and multi-type sensor data[J]. Journal of Jilin University(Engineering and Technology Edition), 2019, 49(4): 1026-1033. | |
| [6] | 陈鑫, 兰凤崇, 陈吉清. 基于改进深度强化学习的自动泊车路径规划[J]. 重庆理工大学学报:自然科学版, 2021, 35(7): 17-27. |
| Chen Xin, Lan Feng-chong, Chen Ji-qing. Deep reinforcement learning based trajectory planning for automatic parking[J]. Journal of Chongqing University of Technology(Natural Science Edition), 2021, 35(7): 17-27. | |
| [7] | Chen J, Yuan B, Tomizuka M. Model-free deep reinforcement learning for urban autonomous driving[C]∥IEEE Intelligent Transportation Systems Conference(ITSC), Piscataway,USA, 2019: 2765-2771. |
| [8] | Wu K Y, Wang H, Esfahani M A, et al. Learn to navigate autonomously through deep reinforcement learning[J]. IEEE Transactions on Industrial Electronics, 2021, 69(5): 5342-5352. |
| [9] | Liang X D, Wang T R, Yang L N, et al. CIRL: controllable imitative reinforcement learning for vision-based self-driving[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 584-599. |
| [10] | Han Y C, Yilmaz A. Learning to drive using sparse imitation reinforcement learning[C]∥The 26th International Conference on Pattern Recognition, Piscataway, USA, 2022: 3736-3742. |
| [11] | Gordon D, Kadian A, Parikh D, et al. SplitNet: Sim2sim and task2task transfer for embodied visual navigation[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision, Piscataway, USA, 2019: 1022-1031. |
| [12] | Toromanoff M, Wirbel E, Moutarde F. End-to-end model-free reinforcement learning for urban driving using implicit affordances[C] ∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Piscataway, USA, 2020: 7151-7160. |
| [13] | Mehta A, Subramanian A, Subramanian A. Learning end-to-end autonomous driving using guided auxiliary supervision[C]∥Proceedings of the 11th Indian Conference on Computer Vision, Graphics and Image Processing, Sofia, Bulgaria, 2020: 1-8. |
| [14] | Agarwal T, Arora H, Schneider J. Learning urban driving policies using deep reinforcement learning[C]∥IEEE International Intelligent Transportation Systems Conference(ITSC), Beijing,China, 2021: 607-614. |
| [15] | Kargar E, Kyrki V. Increasing the efficiency of policy learning for autonomous vehicles by multi-task representation learning[J]. IEEE Transactions on Intelligent Vehicles, 2022, 7(3): 701-710. |
| [16] | 徐国艳, 宗孝鹏, 余贵珍, 等. 基于 DDPG 的无人车智能避障方法研究[J]. 汽车工程, 2019, 41(2): 206-212. |
| Xu Guo-yan, Zong Xiao-peng, Yu Gui-zhen, et al. A research on intelligent obstacle avoidance of unmanned vehicle based on DDPG algorithm[J]. Automotive Engineering, 2019, 41(2): 206-212. | |
| [17] | 王忠立, 王浩, 申艳, 等. 一种多感知多约束奖励机制的驾驶策略学习方法[J]. 吉林大学学报:工学版, 2022, 52(11): 2718-2727. |
| Wang Zhong-li, Wang Hao, Shen Yan, et al. A driving decision⁃making approach based on multi⁃sensing and multi⁃constraints reward function[J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(11): 2718-2727. | |
| [18] | 周治国, 余思雨, 于家宝, 等. 面向无人艇的 T-DQN 智能避障算法研究[J]. 自动化学报, 2023, 49(8): 1645-1655. |
| Zhou Zhi-guo, Yu Si-yu, Yu Jia-bao, et al. Research on T-DPN intelligent obstacle avoidance algorithm of unmanned surface vehicle[J]. Acta Automatica Sinica, 2023, 49(8): 1645-1655. | |
| [19] | Chitta K, Prakash A, Jaeger B, et al. TransFuser: Imitation with transformer-based sensor fusion for autonomous driving[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(11): 12878-12895. |
| [20] | Shao H, Wang L T, Chen R B, et al. Safety-enhanced autonomous driving using interpretable sensor fusion transformer[C]∥Conference on Robot Learning,Auckland, New Zealand, 2023: 726-737. |
| [1] | 高镇海,鲍明喜,赵睿,唐明弘,高菲. 基于目标锚点驱动的多模态轨迹预测方法[J]. 吉林大学学报(工学版), 2026, 56(1): 21-30. |
| [2] | 张向文,王子豪. 电动汽车制动模式切换过程电液协调控制策略[J]. 吉林大学学报(工学版), 2026, 56(1): 31-43. |
| [3] | 兰巍,周政,王冠宇,王伟,张苗苗. 基于机器学习的汽车设计智能拟合方法[J]. 吉林大学学报(工学版), 2025, 55(9): 2858-2863. |
| [4] | 孙天骏,杨惠喆,蔡荣贵,冯嘉仪,冉锐,刘斌. 面向纯电动汽车自适应巡航系统的人性化起停控制策略[J]. 吉林大学学报(工学版), 2025, 55(9): 2847-2857. |
| [5] | 李寿涛,贾湘怡,朱军,郭洪艳,于丁力. 基于Level-K的智能驾驶汽车无信控交叉路口决策方法[J]. 吉林大学学报(工学版), 2025, 55(9): 3069-3078. |
| [6] | 朱冰,孟鹏翔,刘斌,韩嘉懿,赵健,陈志成,宋东鉴,陶晓文. 基于交通环境信息的虚拟车道线拟合方法[J]. 吉林大学学报(工学版), 2025, 55(9): 2935-2945. |
| [7] | 赵俊武,曲婷,胡云峰. 基于自适应采样的智能车辆轨迹规划方法[J]. 吉林大学学报(工学版), 2025, 55(8): 2802-2816. |
| [8] | 于贵申,陈鑫,唐悦,赵春晖,牛艾佳,柴辉,那景新. 激光表面处理对铝-铝粘接接头剪切强度的影响[J]. 吉林大学学报(工学版), 2025, 55(8): 2555-2569. |
| [9] | 高金武,孙少龙,王舜尧,高炳钊. 基于电机转矩补偿的增程器转速波动抑制策略[J]. 吉林大学学报(工学版), 2025, 55(8): 2475-2486. |
| [10] | 朱科,邢志明,康翔宇. 机械手多任务均衡策略[J]. 吉林大学学报(工学版), 2025, 55(8): 2782-2790. |
| [11] | 贾美霞,胡建军,肖凤. 基于多软件联合的车用电机变工况多物理场仿真方法[J]. 吉林大学学报(工学版), 2025, 55(6): 1862-1872. |
| [12] | 肖纯,易子淳,周炳寅,张少睿. 基于改进鸽群优化算法的燃料电池汽车模糊能量管理策略[J]. 吉林大学学报(工学版), 2025, 55(6): 1873-1882. |
| [13] | 宋学伟,于泽平,肖阳,王德平,袁泉,李欣卓,郑迦文. 锂离子电池老化后性能变化研究进展[J]. 吉林大学学报(工学版), 2025, 55(6): 1817-1833. |
| [14] | 王健,贾晨威. 面向智能网联车辆的轨迹预测模型[J]. 吉林大学学报(工学版), 2025, 55(6): 1963-1972. |
| [15] | 李伟东,马草原,史浩,曹衡. 基于分层强化学习的自动驾驶决策控制算法[J]. 吉林大学学报(工学版), 2025, 55(5): 1798-1805. |
|
||