吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (10): 3361-3371.doi: 10.13229/j.cnki.jdxbgxb.20240054
• 计算机科学与技术 • 上一篇
频率和空间特征融合的轻量级多尺度遥感图像场景分类网络
王威( ),孙钰洁,王新()
),孙钰洁,王新()
- 长沙理工大学 计算机与通信工程学院,长沙 410114
Lightweight frequency and spatial feature fused multi-scale remote sensing scene classification network
Wei WANG(),Yu-jie SUN,Xin WANG()
- School of Computer and Communication Engineering,Changsha University of Science and Technology,Changsha 410114,China
摘要:
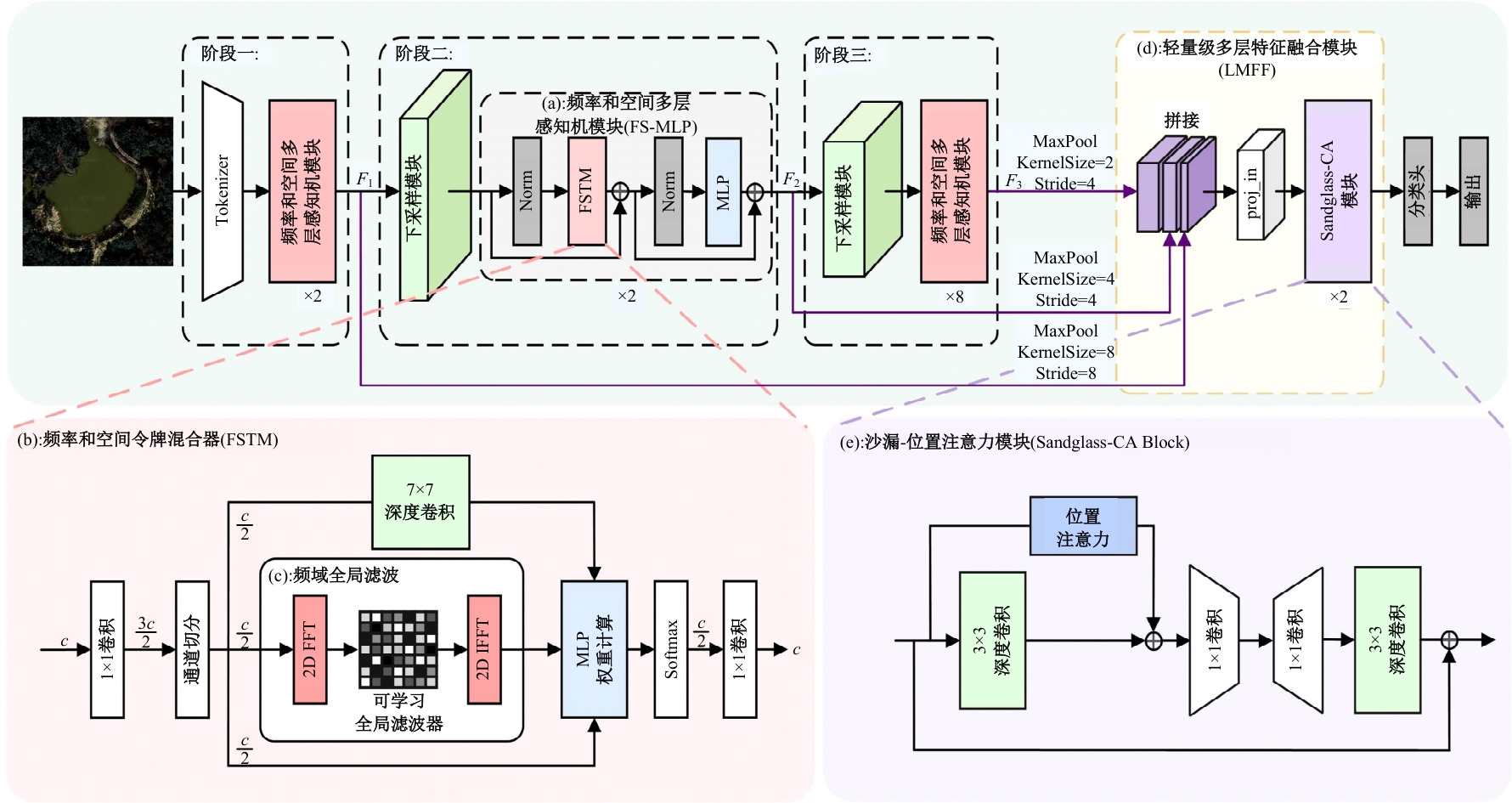
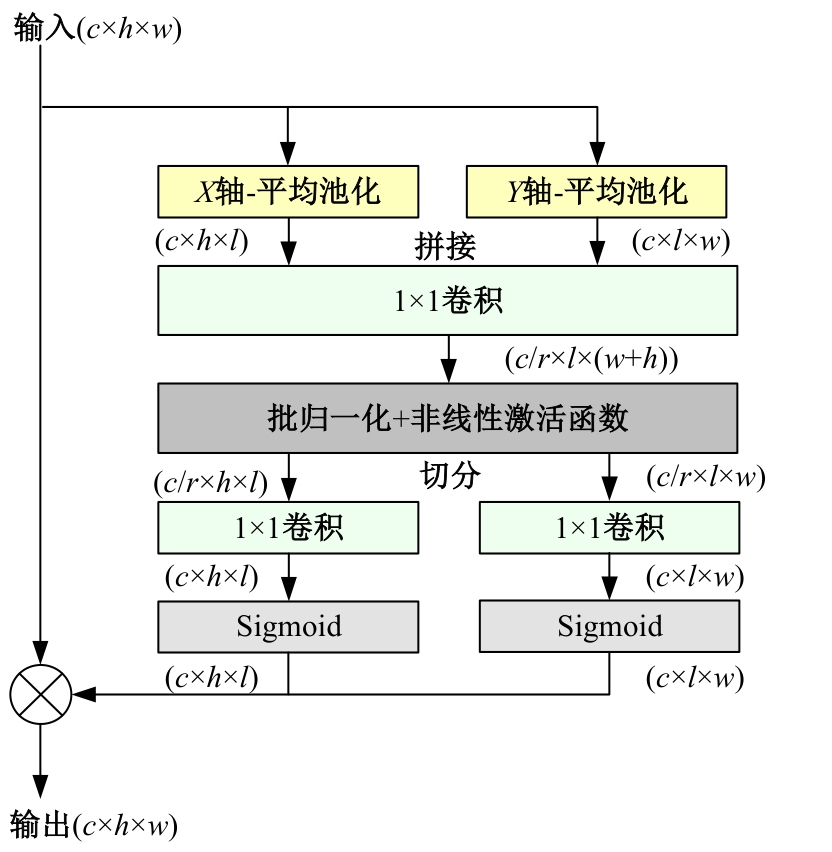
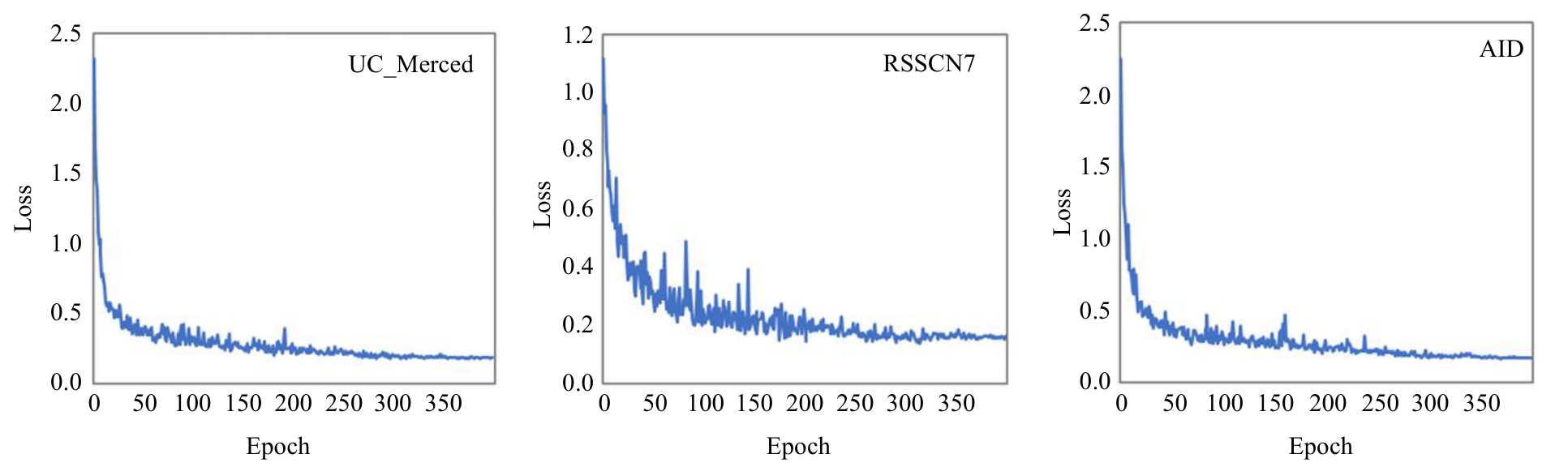
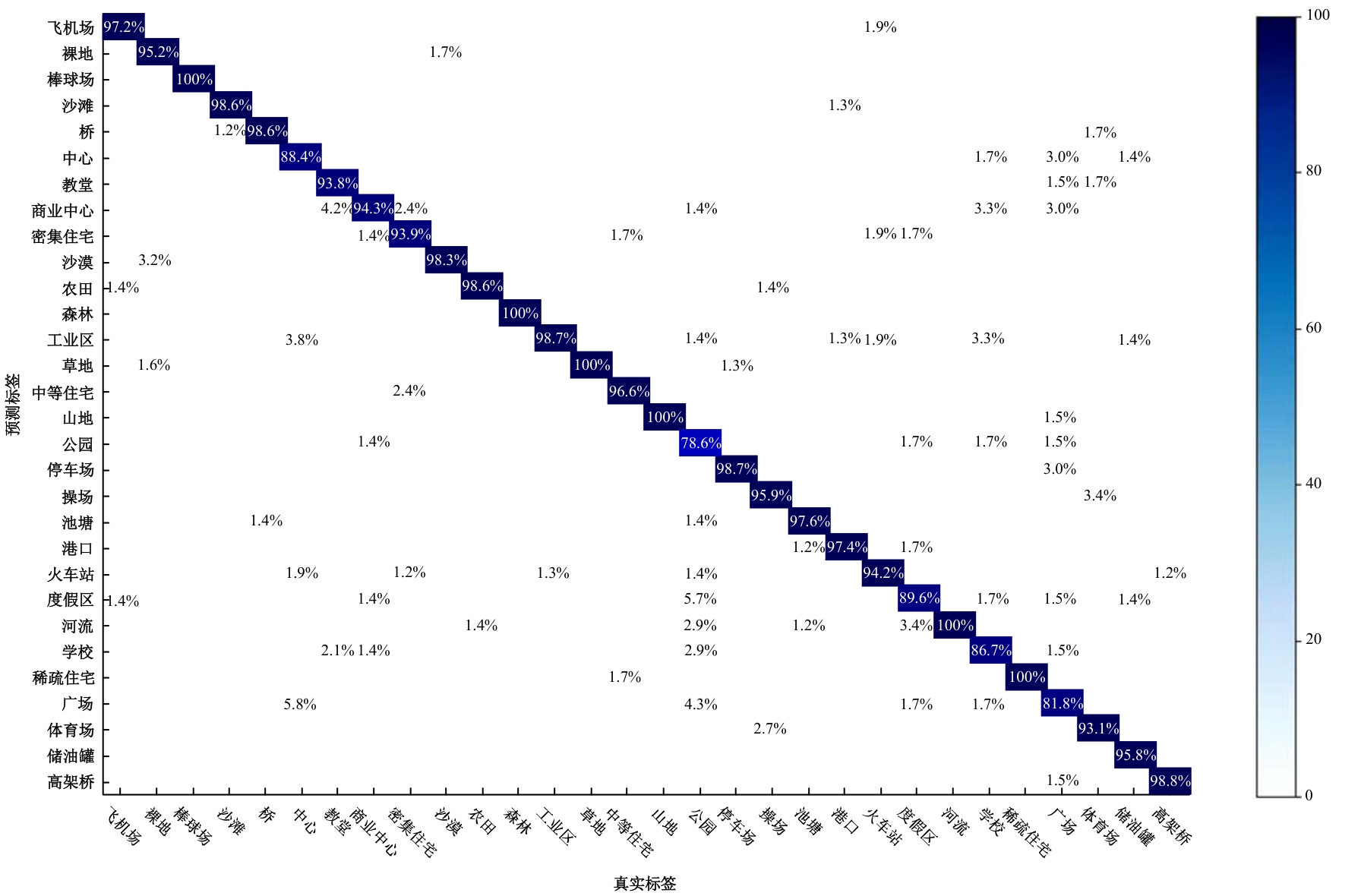
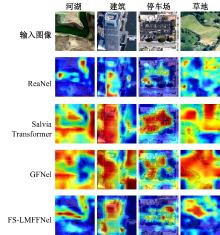
针对遥感图像分类任务中土地覆盖物尺寸和空间组合多种多样、类间相似性高和类内差异性大的问题,从特征的有效提取和多尺度特征的充分融合出发,设计了一种频率和空间特征融合的轻量级多尺度遥感图像场景分类网络(FS-LMFFNet)。首先,为了结合卷积神经网络(CNN)和Transformer的优点,实现局部和全局特征的充分提取,提出了一种频率和空间多层感知机模块(FS-MLP),该模块通过引入频域分析,补充了传统空间操作在提取全局高频纹理特征方面的不足。其次,针对遥感场景图像的多尺度特性,提出了一种轻量级多层特征融合模块(LMFF),该模块采用轻量级卷积块对前3个阶段的多尺度特征进行有效的融合。最后,基于FS-MLP和LMFF模块构建的FS-LMFFNet在3个公开数据集UC_Merced、RSSCN7和AID上进行实验,准确率分别达到99.10%、96.60%和95.48%。实验结果表明,本文提出的FS-LMFFNet能更好地提取和融合多尺度特征,从而取得优于其他先进模型的性能。
中图分类号:
- TP391.4



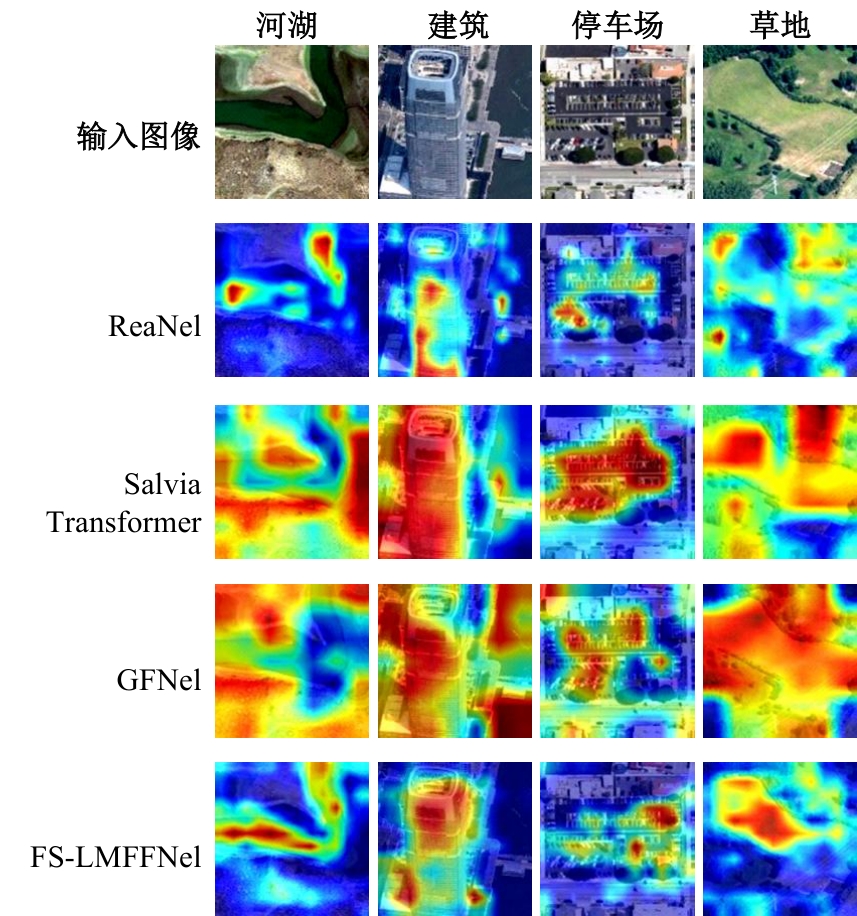
| [1] | 徐从安, 吕亚飞, 张筱晗, 等. 基于双重注意力机制的遥感图像场景分类特征表示方法[J]. 电子与信息学报, 2021, 43(3): 683-691. |
| Xu Cong-an, Ya-fei Lyu, Zhang Xiao-han, et al. A discriminative feature representation method based on dual attention mechanism for remote sensing image scene classification[J]. Journal of Electronics & Information Technology, 2021, 43(3): 683-691. | |
| [2] | Morell-Monzó S, Sebastiá-Frasquet M T, Estornell J. Land use classification of VHR images for mapping small-sized abandoned citrus plots by using spectral and textural information[J]. Remote Sensing, 2021, 13(4): No.681. |
| [3] | Liang S, Cheng J, Zhang J. Maximum likelihood classification of soil remote sensing image based on deep learning[J]. Earth Sciences Research Journal, 2020, 24(3): 357-365. |
| [4] | Fatemighomi H S, Golalizadeh M, Amani M. Object-based hyperspectral image classification using a new latent block model based on hidden Markov random fields[J]. Pattern Anal Applic, 2022, 25: 467-481. |
| [5] | Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. |
| [6] | Dai J, Qi H, Xiong Y, et al. Deformable convolutional networks[C]∥Proceedings of the IEEE International Conference on Computer Vision(ICCV), Venice, Italy, 2017: 764-773. |
| [7] | Ding X, Zhang X, Han J, et al. Scaling up your kernels to 31×31: revisiting large kernel design in CNNs[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR), New Orleans, Louisiana, USA,2022: 11953-11965. |
| [8] | Guo M H, Lu C Z, Liu Z N, et al. Visual attention network[J]. Computational Visual Media, 2022, 9(4):733-752. |
| [9] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]∥Proceedings of 31st Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000-6010. |
| [10] | Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: transformers for image recognition at scale[EB/OL]. [2022-10-18].. |
| [11] | Bazi Y, Bashmal L, Rahhal M M A, et al. Vision transformers for remote sensing image classification[J]. Remote Sensing, 2021, 13(3): No. 516. |
| [12] | Yu W H, Luo M, Zhou P, et al. Meta former is actually what you need for vision[C]∥Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10809-10819. |
| [13] | 王威, 李希杰, 王新. ADC-CPANet: 一种局部-全局特征融合的遥感图像分类方法[J]. 遥感学报, 2024, 28(10): 2661-2672. |
| Wang Wei, Li Xi-jie, Wang Xin. ADC-CPANet:a remote sensing image classification method based on local-global feature fusion[J]. National Remote Sensing Bulletin, 2024, 28(10): 2661-2672. | |
| [14] | Wang W, Hu T, Wang X, et al. BFRNet: bidimensional feature representation network for remote sensing images classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 1-13. |
| [15] | Huang Z, Zhang Z, Lan C, et al. Adaptive frequency filters as efficient global token mixers[EB/OL].[2023-03-22]. . |
| [16] | Cao R, Fang L, Lu T, et al. Self-attention -based deep feature fusion for remote sensing scene classification[J]. IEEE Geoscience and Remote Sensing Letters, 2021, 18(1): 43-47. |
| [17] | 王威, 邓纪伟, 王新, 等. 面向遥感图像场景分类的GLFFNet模型[J]. 测绘学报, 2023, 52(10): 1693-1702. |
| Wang Wei, Deng Ji-wei, Wang Xin, et al. GLFFNet model for remote sensing image scene classification[J]. Acta Geodaetica ET Cartographica Sinica, 2023, 52(10): 1693-1702. | |
| [18] | Hendrycks D, Gimpel K. Gaussian error linear units (GELUs)[EB/OL]. [2024-01-10]. . |
| [19] | Sandler M, Howard A, Zhu M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA,2018:4510-4520. |
| [20] | Zhou D, Hou Q, Chen Y, et al. Rethinking bottleneck structure for efficient mobile network design[J]. In Computer Vision-ECCV 2020, Lecture Notes in Computer Science, 2020, 12348: 680-697. |
| [21] | Sergey I, Christian S. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]∥Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 2015:448-456. |
| [22] | Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Montreal, Canada,2021: 13713-13722. |
| [23] | Yang Y, Shawn N. Bag-of-visual-words and spatial extensions for land-use classification[C]∥Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose California, USA, 2010: 270-279. |
| [24] | Zou Q, Ni L H, Zhang T, et al. Deep learning based feature selection for remote sensing scene classification[J]. IEEE Geoscience and Remote Sensing Letters, 2015, 12(11): 2321-2325. |
| [25] | Xia G S, Hu J, Hu F, et al. AID: a benchmark data set for performance evaluation of aerial scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(7): 3965-3981. |
| [26] | Liu Z, Lin Y, Cao Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]∥ IEEE/CVF International Conference on Computer Vision(ICCV), Montreal, Canada, 2021: 10012-10022. |
| [27] | Cao G, Luo S, Huang W, et al. Strip-MLP: efficient token interaction for vision MLP[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France,2023: 1494-1504. |
| [28] | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[EB/OL].[2023-03-18]. . |
| [29] | He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770-778. |
| [30] | Qin Z, Zhang P, Wu F, et al. FcaNet: frequency channel attention networks[C]∥Proceedings of the IEEE International Conference on Computer Vision, Xi'an, China, 2020: 763-772. |
| [31] | Rao Y, Zhao W, Zhu Z, et al. Global filter networks for image classification[J]. Advances in Neural Information Processing Systems, 2021, 2: 980-993. |
| [32] | Tang Y, Han K, Guo J, et al. An image patch is a wave: phase-aware vision MLP[EB/OL].[2023-03-18]. . |
| [33] | Li J, Hassani A, Walton S, et al. ConvMLP: Hierarchical Convolutional MLPs for Vision[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Vancouver,Canada, 2023: 6307-6316. |
| [34] | Wang X, Duan L, Ning C, et al. Relation-attention networks for remote sensing scene classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 422-439. |
| [35] | Tang X, Li M, Ma J, et al. EMTCAL: efficient multiscale transformer and cross-level attention learning for remote sensing scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-15. |
| [36] | Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[C]∥Proceedings of 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 618-626. |
| [1] | 姚宗伟,陈辰,高振云,靳鸿鹏,荣浩,李学飞,黄虹溥,毕秋实. 基于合成图像数据集的挖掘机关键点识别[J]. 吉林大学学报(工学版), 2026, 56(1): 76-85. |
| [2] | 王琳虹,刘宇阳,刘子昱,鹿应佳,张宇恒,黄桂树. 基于YOLOv5的轻量化桥梁缺陷识别[J]. 吉林大学学报(工学版), 2025, 55(9): 2958-2968. |
| [3] | 廉敬,张继保,刘冀钊,张家骏,董子龙. 基于文本引导的人脸图像修复[J]. 吉林大学学报(工学版), 2025, 55(8): 2732-2740. |
| [4] | 刘元宁,王星喆,黄子彧,张家晨,刘震. 基于多模态数据融合的胃癌患者生存预测模型[J]. 吉林大学学报(工学版), 2025, 55(8): 2693-2702. |
| [5] | 李文辉,杨晨. 基于对比学习文本感知的小样本遥感图像分类[J]. 吉林大学学报(工学版), 2025, 55(7): 2393-2401. |
| [6] | 袁靖舒,李武,赵兴雨,袁满. 基于BERTGAT-Contrastive的语义匹配模型[J]. 吉林大学学报(工学版), 2025, 55(7): 2383-2392. |
| [7] | 徐慧智,郝东升,徐小婷,蒋时森. 基于深度学习的高速公路小目标检测算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2003-2014. |
| [8] | 于营,王春平,寇人可,杨博雄,王雷,赵福军,付强. 多时相高分辨率卫星遥感图像语义分割算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2131-2137. |
| [9] | 张汝波,常世淇,张天一. 基于深度学习的图像信息隐藏方法综述[J]. 吉林大学学报(工学版), 2025, 55(5): 1497-1515. |
| [10] | 文斌,丁弈夫,杨超,沈艳军,李辉. 基于自选择架构网络的交通标志分类算法[J]. 吉林大学学报(工学版), 2025, 55(5): 1705-1713. |
| [11] | 田丽,贾煜辉. 改进YOLOv5s算法的高光谱遥感图像目标检测[J]. 吉林大学学报(工学版), 2025, 55(5): 1742-1748. |
| [12] | 李健,刘欢,李艳秋,王海瑞,关路,廖昌义. 基于THGS算法优化ResNet-18模型的图像识别[J]. 吉林大学学报(工学版), 2025, 55(5): 1629-1637. |
| [13] | 李振江,万利,周世睿,陶楚青,魏巍. 基于时空Transformer网络的隧道交通运行风险动态辨识方法[J]. 吉林大学学报(工学版), 2025, 55(4): 1336-1345. |
| [14] | 李学军,权林霏,刘冬梅,于树友. 基于Faster-RCNN改进的交通标志检测算法[J]. 吉林大学学报(工学版), 2025, 55(3): 938-946. |
| [15] | 赵孟雪,车翔玖,徐欢,刘全乐. 基于先验知识优化的医学图像候选区域生成方法[J]. 吉林大学学报(工学版), 2025, 55(2): 722-730. |
|
||