吉林大学学报(工学版) ›› 2024, Vol. 54 ›› Issue (11): 3327-3337.doi: 10.13229/j.cnki.jdxbgxb.20230003
• 计算机科学与技术 • 上一篇
时间显著注意力孪生跟踪网络
毛琳( ),苏宏阳,杨大伟()
),苏宏阳,杨大伟()
- 大连民族大学 机电工程学院,辽宁 大连 116600
Temporal salient attention siamese tracking network
Lin MAO(),Hong-yang SU,Da-wei YANG()
- School of Electromechanical Engineering,Dalian Minzu University,Dalian 116600,China
摘要:
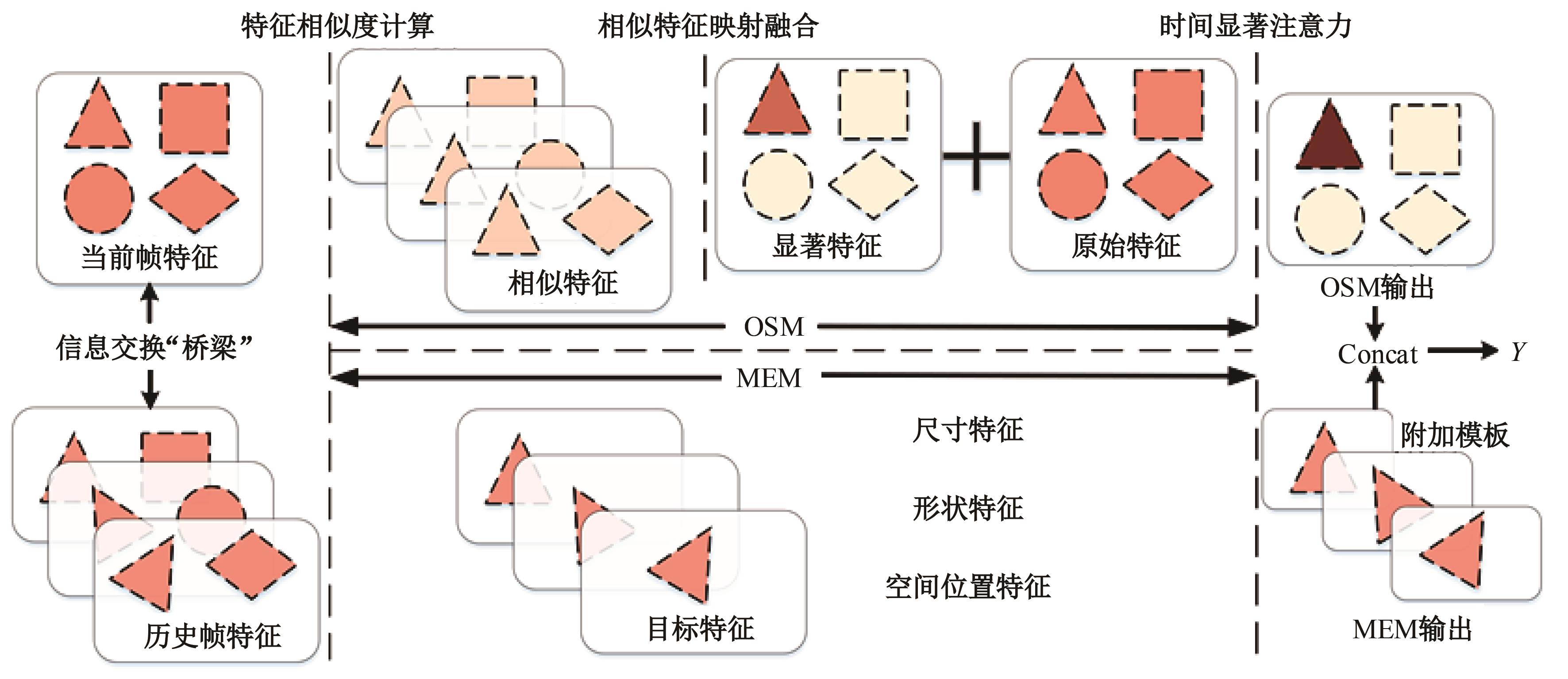
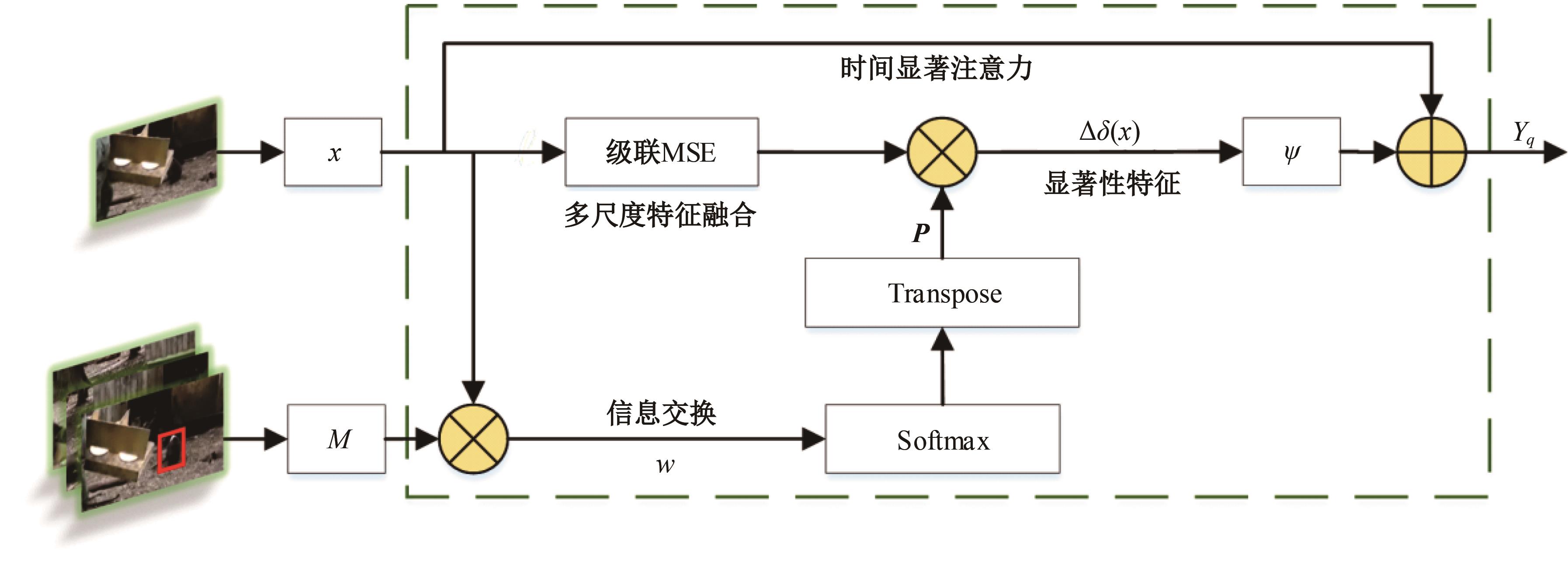
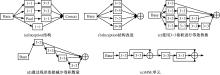
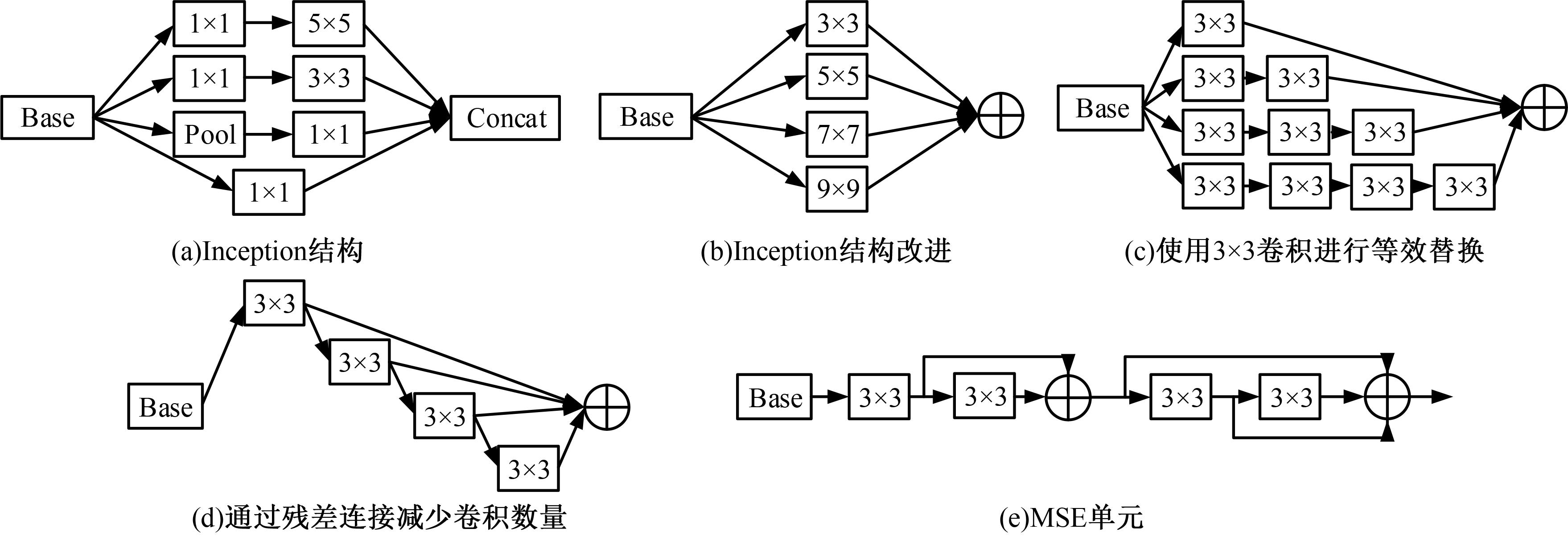
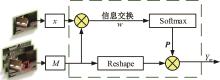
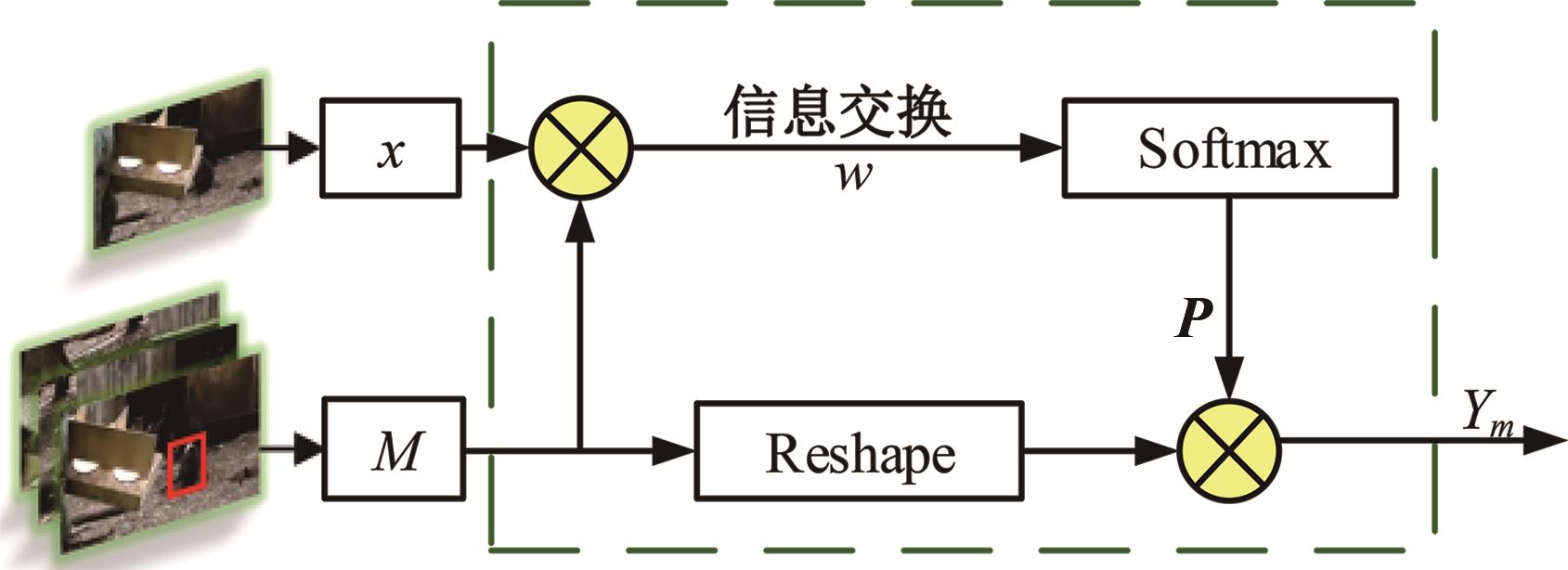
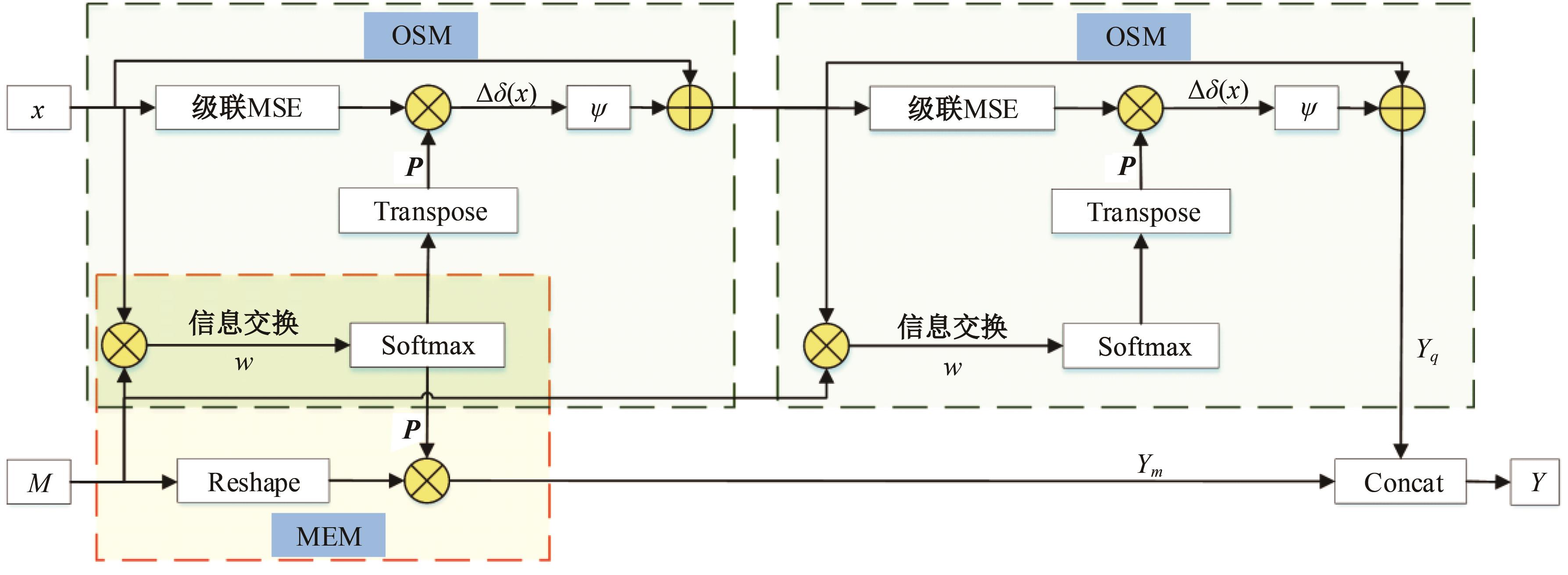
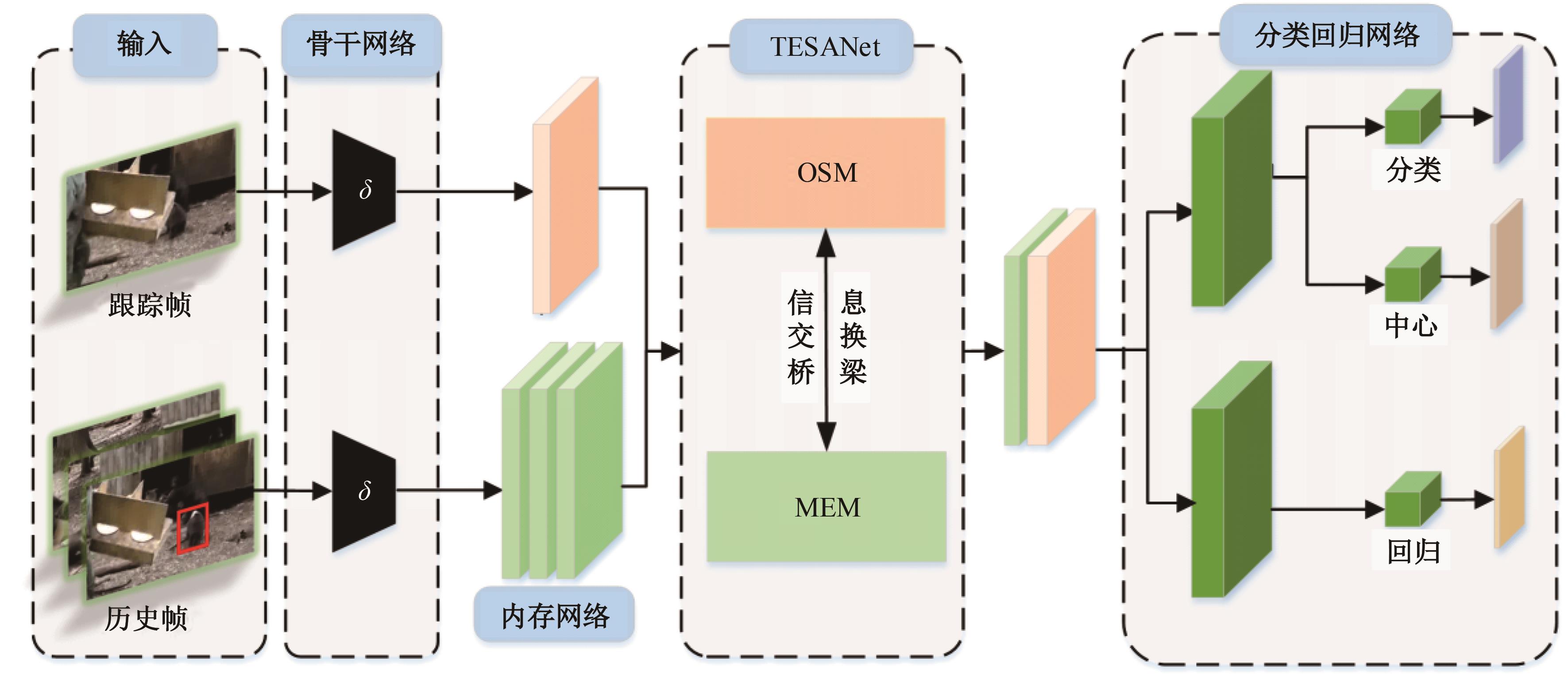
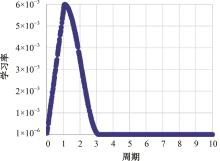
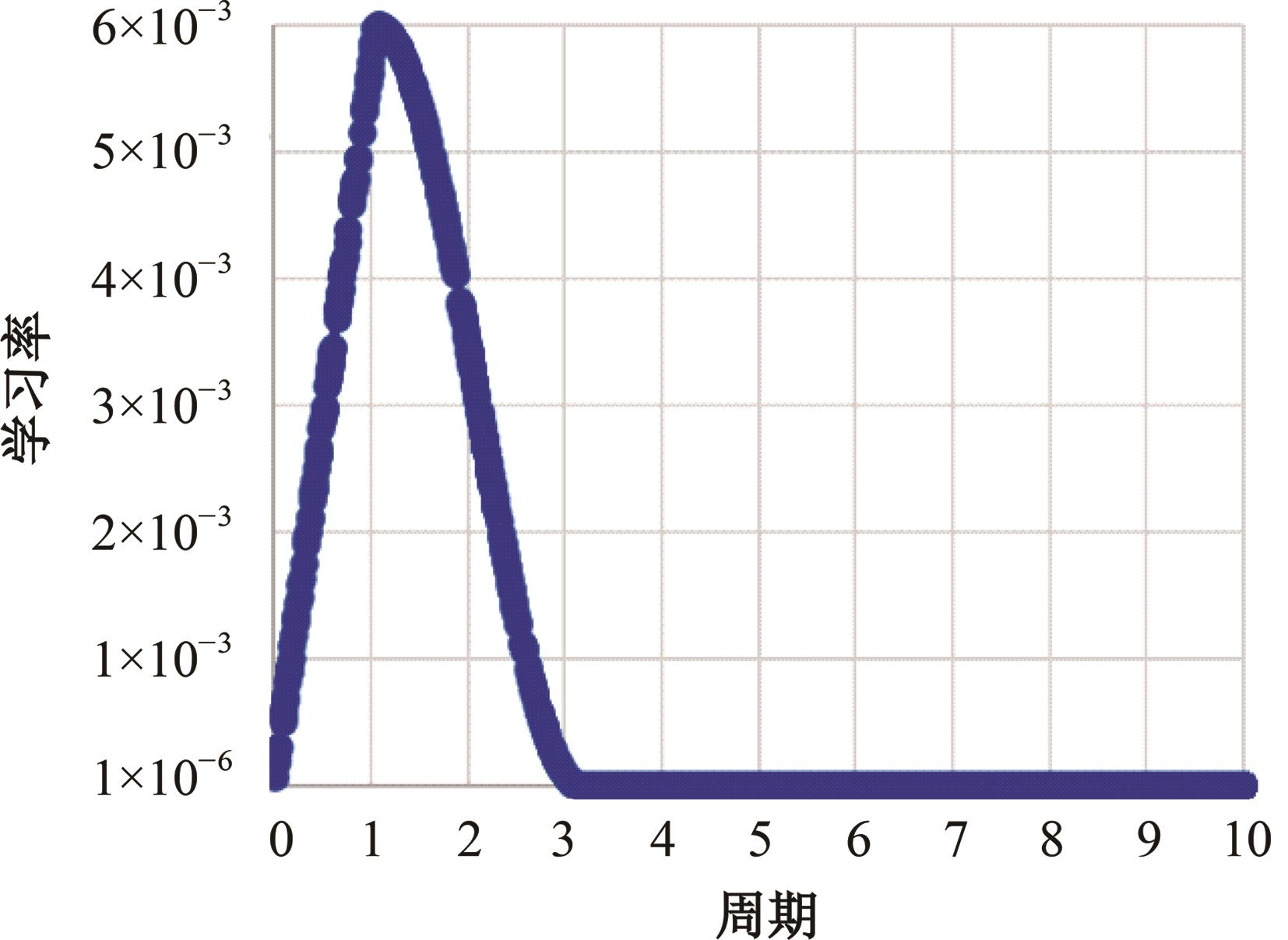
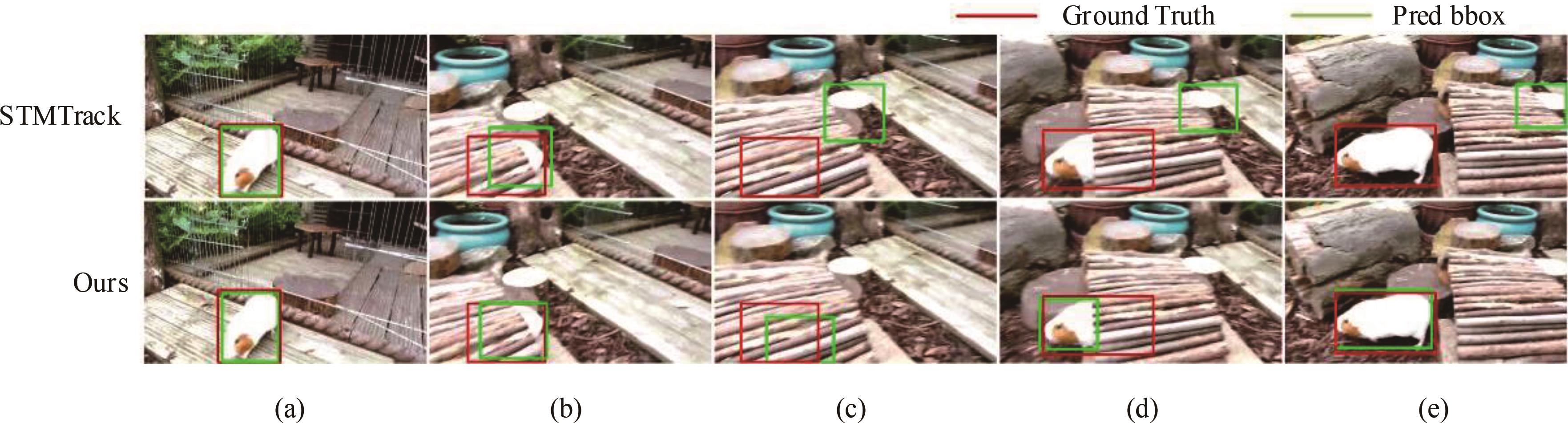
针对现有孪生神经网络仅利用空间信息,面对目标遮挡、消失、表观剧烈形变等挑战造成跟踪准确度下降问题,提出一种时间显著注意力孪生跟踪网络。该网络通过信息交换“桥梁”,一方面为当前帧添加时间显著注意力,引导网络重点学习目标特征;另一方面对内存网络中历史目标特征进行筛选,将其作为附加模板,提供目标额外表观信息,同时遵循学习目标表观信息与空间位置的变化规律,指导后续检测、分类过程。为提高时间显著注意力能力,提出多尺度特征提取单元,解决骨干网络特征提取不充分的问题。在Got-10k数据集上进行模型测试,与目标跟踪算法时空记忆网络(STMTrack)相比,
中图分类号:
- TP391





| 1 | Bertinetto L, Valmadre J, Henriques J F, et al. Fully-convolutional siamese networks for object tracking[C]∥ European Conference on Computer Vision, Berlin, Germany, 2016: 850-865. |
| 2 | Li B, Yan J J, Wu W, et al. High performance visual tracking with siamese region proposal network[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8971-8980. |
| 3 | Fan H, Ling H B. Siamese cascaded region proposal networks for real-time visual tracking[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 7952-7961. |
| 4 | Li B, Wu W, Wang Q, et al. Siamrpn++: evolution of siamese visual tracking with very deep networks[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 4282-4291. |
| 5 | Xu Y D, Wang Z Y, Li Z X, et al. Siamfc++: towards robust and accurate visual tracking with target estimation guidelines[C]∥ Proceedings of the AAAI Conference on Artificial Intelligence, New York, USA, 2020: 12549-12556. |
| 6 | Gupta D K, Arya D, Gavves E. Rotation equivariant siamese networks for tracking[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 12362-12371. |
| 7 | Yang T Y, Chan A B. Learning dynamic memory networks for object tracking[C]∥ Proceedings of the European Conference on Computer Vision (ECCV), Munichi, Germany, 2018: 152-167. |
| 8 | Yan B, Peng H W, Fu J L, et al. Learning spatio-temporal transformer for visual tracking[C]∥ Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 10448-10457. |
| 9 | Fu Z H, Liu Q J, Fu Z H, et al. Stmtrack: template-free visual tracking with space-time memory networks[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 13774-13783. |
| 10 | Zhang Z P, Peng H W, Fu J L, et al. Ocean: object-aware anchor-free tracking[C]∥European Conference on Computer Vision, Berlin, Germany, 2020: 771-787. |
| 11 | Voigtlaender P, Luiten J, Torr P H, et al. Siam R-CNN: visual tracking by re-detection[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 6578-6588. |
| 12 | Eom C, Lee G, Lee J, et al. Video-based person re-identification with spatial and temporal memory networks[C]∥ Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 12036-12045. |
| 13 | Oh S W, Lee J Y, Xu N, et al. Video object segmentation using space-time memory networks[C]∥ Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 9226-9235. |
| 14 | Xie H Z, Yao H X, Zhou S C, et al. Efficient regional memory network for video object segmentation[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 1286-1295. |
| 15 | Paul M, Danelljan M, Van G L, et al. Local memory attention for fast video semantic segmentation[C]∥ 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 2021: 1102-1109. |
| 16 | Wang H, Wang W N, Liu J. Temporal memory attention for video semantic segmentation[C]∥ 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, USA, 2021: 2254-2258. |
| 17 | Yu F, Wang D Q, Shelhamer E, et al. Deep layer aggregation[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 2403-2412. |
| 18 | Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2818-2826. |
| 19 | Tian Z, Shen C H, Chen H, et al. Fully convolutional one-stage object detection[C]∥ 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 2019: 9626-9635. |
| 20 | Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]∥ Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2980-2988. |
| 21 | Huang L H, Zhao X, Huang K Q. Got-10k: a large high-diversity benchmark for generic object tracking in the wild[J]. IEEE Transactions on Pattern Analysis, Intelligence Machine, 2019, 43(5): 1562-1577. |
| 22 | Cui Y T, Jiang C, Wang L M, et al. Mixformer: end-to-end tracking with iterative mixed attention[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 13608-13618. |
| 23 | Xie F, Wang C Y, Wang G T, et al. Correlation-aware deep tracking[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 8751-8760. |
| 24 | Wang N, Zhou W G, Wang J, et al. Transformer meets tracker: exploiting temporal context for robust visual tracking[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 1571-1580. |
| 25 | Zhang Z P, Liu Y H, Wang X, et al. Learn to match: automatic matching network design for visual tracking[C]∥ Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 13339-13348. |
| 26 | Cui Y T, Jiang C, Wang L M, et al. Fully convolutional online tracking[J]. Computer Vision and Image Understanding, 2022, 224: 103547. |
| 27 | Lukezic A, Matas J, Kristan M. D3S-a discriminative single shot segmentation tracker[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 7133-7142. |
| 28 | Mayer C, Danelljan M, Bhat G, et al. Transforming model prediction for tracking[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 8731-8740. |
| 29 | Zhou Z K, Pei W J, Li X, et al. Saliency-associated object tracking[C]∥ Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 9866-9875. |
| 30 | Bhat G, Danelljan M, Gool L V, et al. Know your surroundings: exploiting scene information for object tracking[C]∥ European Conference on Computer Vision, Berlin, Germany, 2020: 205-221. |
| 31 | Yu Y C, Xiong Y L, Huang W L, et al. Deformable siamese attention networks for visual object tracking[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 6728-6737. |
| 32 | Bhat G, Johnander J, Danelljan M, et al. Unveiling the power of deep tracking[C]∥ Proceedings of the European Conference on Computer Vision (ECCV), Munichi, Germany, 2018: 483-498. |
| 33 | Chen Z D, Zhong B E, Li G R, et al. SiamBAN: target-aware tracking with siamese box adaptive network[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(4): 5158-5173. |
| 34 | Bhat G, Danelljan M, Gool L V, et al. Learning discriminative model prediction for tracking[C]∥ Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 6182-6191. |
| [1] | 曹毅,夏宇,高清源,叶培涛,叶凡. 基于超连接图卷积网络的骨架行为识别方法[J]. 吉林大学学报(工学版), 2025, 55(2): 731-740. |
| [2] | 赵孟雪,车翔玖,徐欢,刘全乐. 基于先验知识优化的医学图像候选区域生成方法[J]. 吉林大学学报(工学版), 2025, 55(2): 722-730. |
| [3] | 才华,郑延阳,付强,王晟宇,王伟刚,马智勇. 基于多尺度候选融合与优化的三维目标检测算法[J]. 吉林大学学报(工学版), 2025, 55(2): 709-721. |
| [4] | 蔡晓东,周青松,张言言,雪韵. 基于动静态和关系特征全局捕获的社交推荐模型[J]. 吉林大学学报(工学版), 2025, 55(2): 700-708. |
| [5] | 郑利民,陈双,李刚. YOLOv5网络算法下交通监控视频违章车辆多目标检测[J]. 吉林大学学报(工学版), 2025, 55(2): 693-699. |
| [6] | 车翔玖,武宇宁,刘全乐. 基于因果特征学习的有权同构图分类算法[J]. 吉林大学学报(工学版), 2025, 55(2): 681-686. |
| [7] | 郭晓然,王铁君,闫悦. 基于局部注意力和本地远程监督的实体关系抽取方法[J]. 吉林大学学报(工学版), 2025, 55(1): 307-315. |
| [8] | 汪豪,赵彬,刘国华. 基于时间和运动增强的视频动作识别[J]. 吉林大学学报(工学版), 2025, 55(1): 339-346. |
| [9] | 张曦,库少平. 基于生成对抗网络的人脸超分辨率重建方法[J]. 吉林大学学报(工学版), 2025, 55(1): 333-338. |
| [10] | 刘俊杰,董佳怡,杨勇,刘丹,曲福恒,吕彦昌. 基于HM-OLS逐步回归模型的学生网络学习成绩关联因素分析[J]. 吉林大学学报(工学版), 2024, 54(12): 3755-3762. |
| [11] | 苏育挺,景梦瑶,井佩光,刘先燚. 基于光度立体和深度学习的电池缺陷检测方法[J]. 吉林大学学报(工学版), 2024, 54(12): 3653-3659. |
| [12] | 胡尧,涂碧波. 高级持续性威胁攻击下多域互操作动态访问控制算法[J]. 吉林大学学报(工学版), 2024, 54(12): 3620-3625. |
| [13] | 易晓宇,易绵竹. 基于兴趣信息深度融合的网络图书资源推荐[J]. 吉林大学学报(工学版), 2024, 54(12): 3614-3619. |
| [14] | 程鑫,刘升贤,周经美,周洲,赵祥模. 融合密集连接和高斯距离的三维目标检测算法[J]. 吉林大学学报(工学版), 2024, 54(12): 3589-3600. |
| [15] | 拉巴顿珠,扎西多吉,珠杰. 藏语文本标准化方法[J]. 吉林大学学报(工学版), 2024, 54(12): 3577-3588. |
|
||