吉林大学学报(工学版) ›› 2024, Vol. 54 ›› Issue (11): 3318-3326.doi: 10.13229/j.cnki.jdxbgxb.20221635
• 计算机科学与技术 • 上一篇
基于新型损失函数DV-Softmax的声纹识别方法
曹毅( ),李平,吴伟官,夏宇,高清源
),李平,吴伟官,夏宇,高清源
- 江南大学 机械工程学院,江苏 无锡 214122
Voiceprint recognition method based on novel loss function DV-Softmax
Yi CAO(),Ping LI,Wei-guan WU,Yu XIA,Qing-yuan GAO
- School of Mechanical Engineering,Jiangnan University,Wuxi 214122,China
摘要:
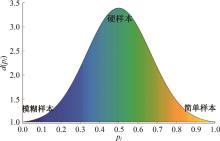
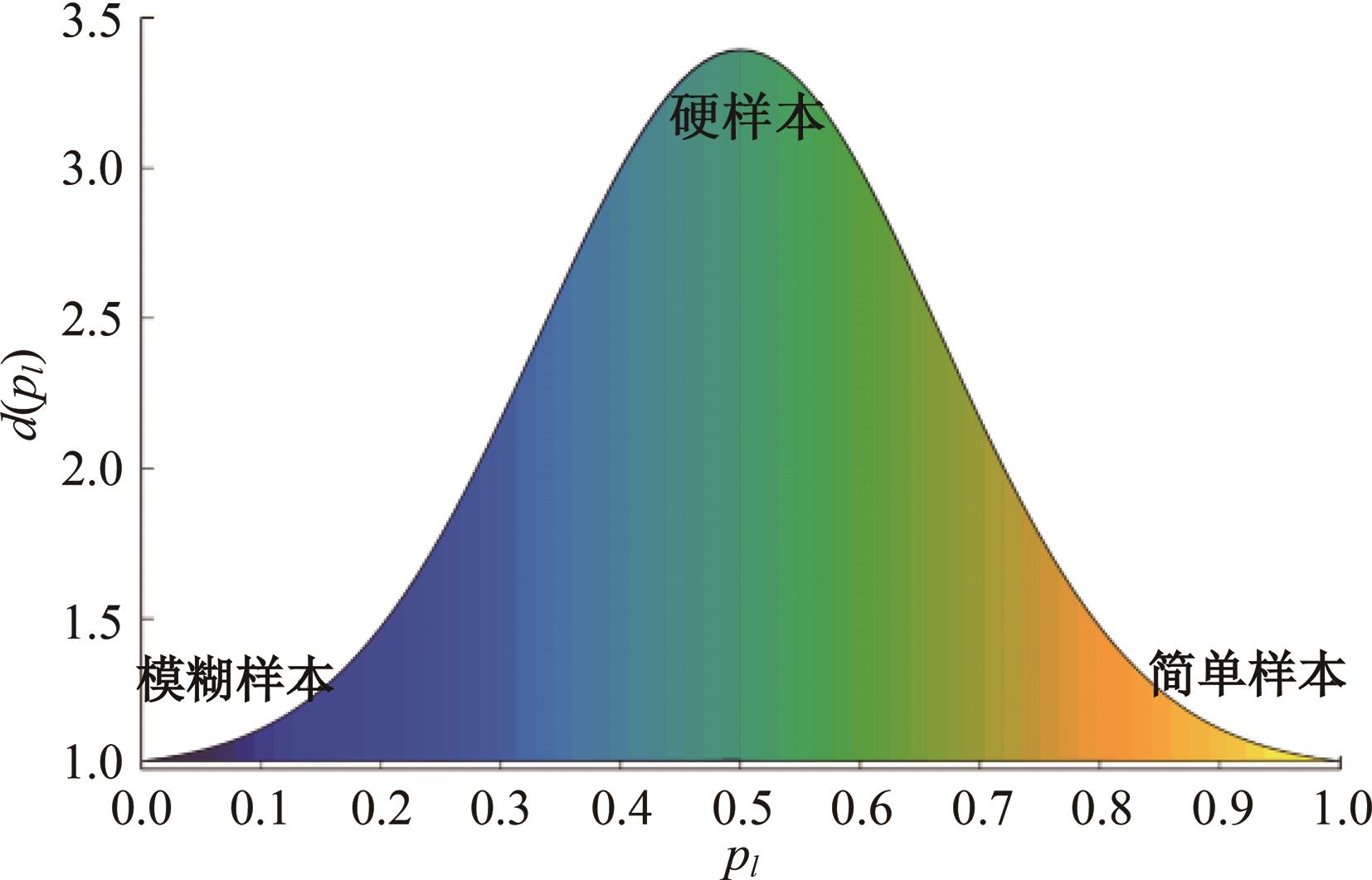
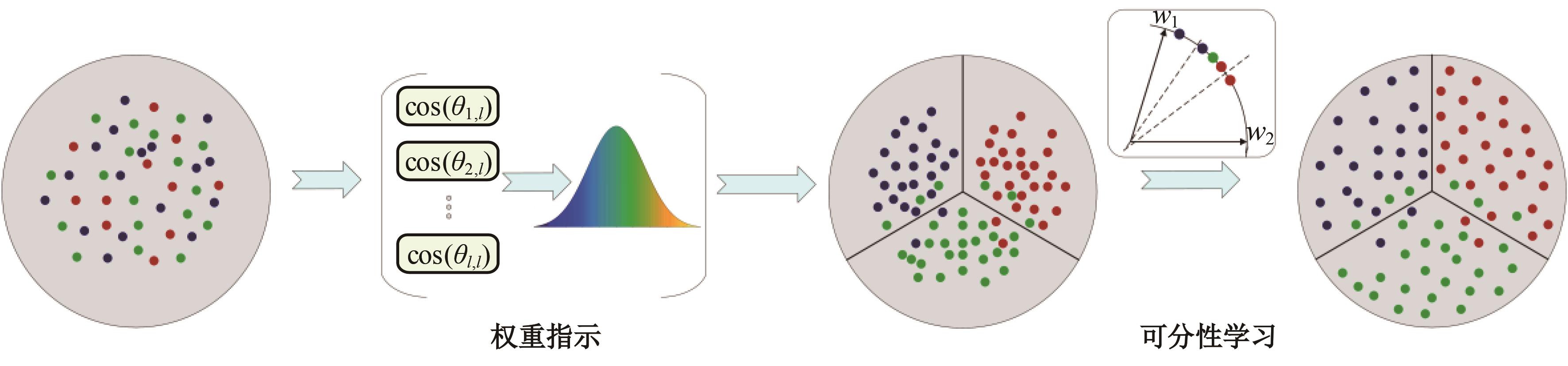
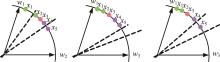
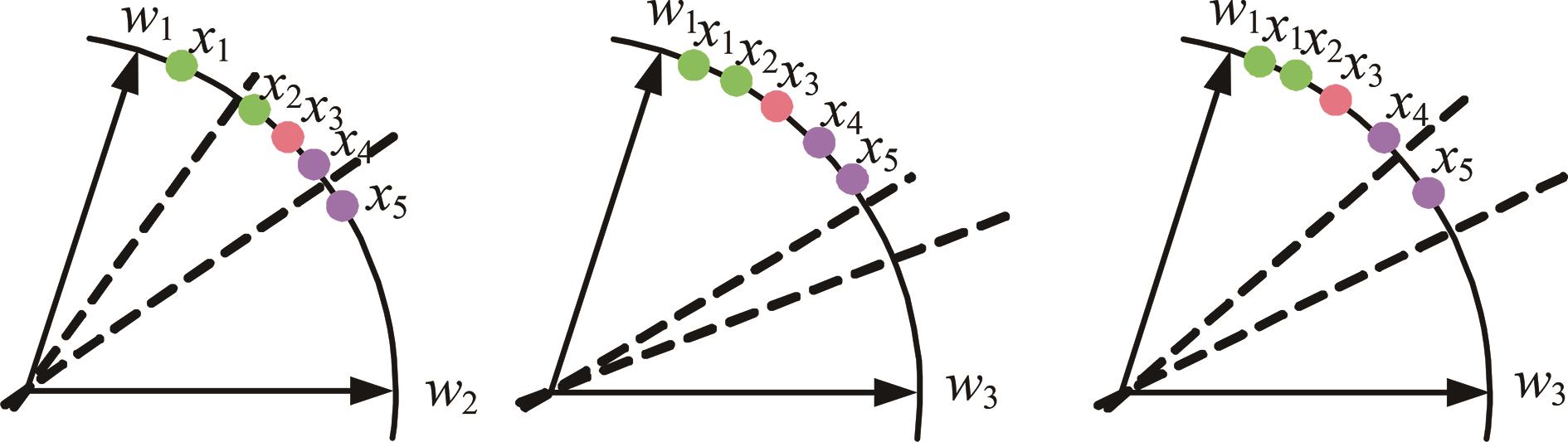
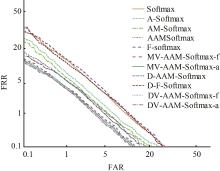
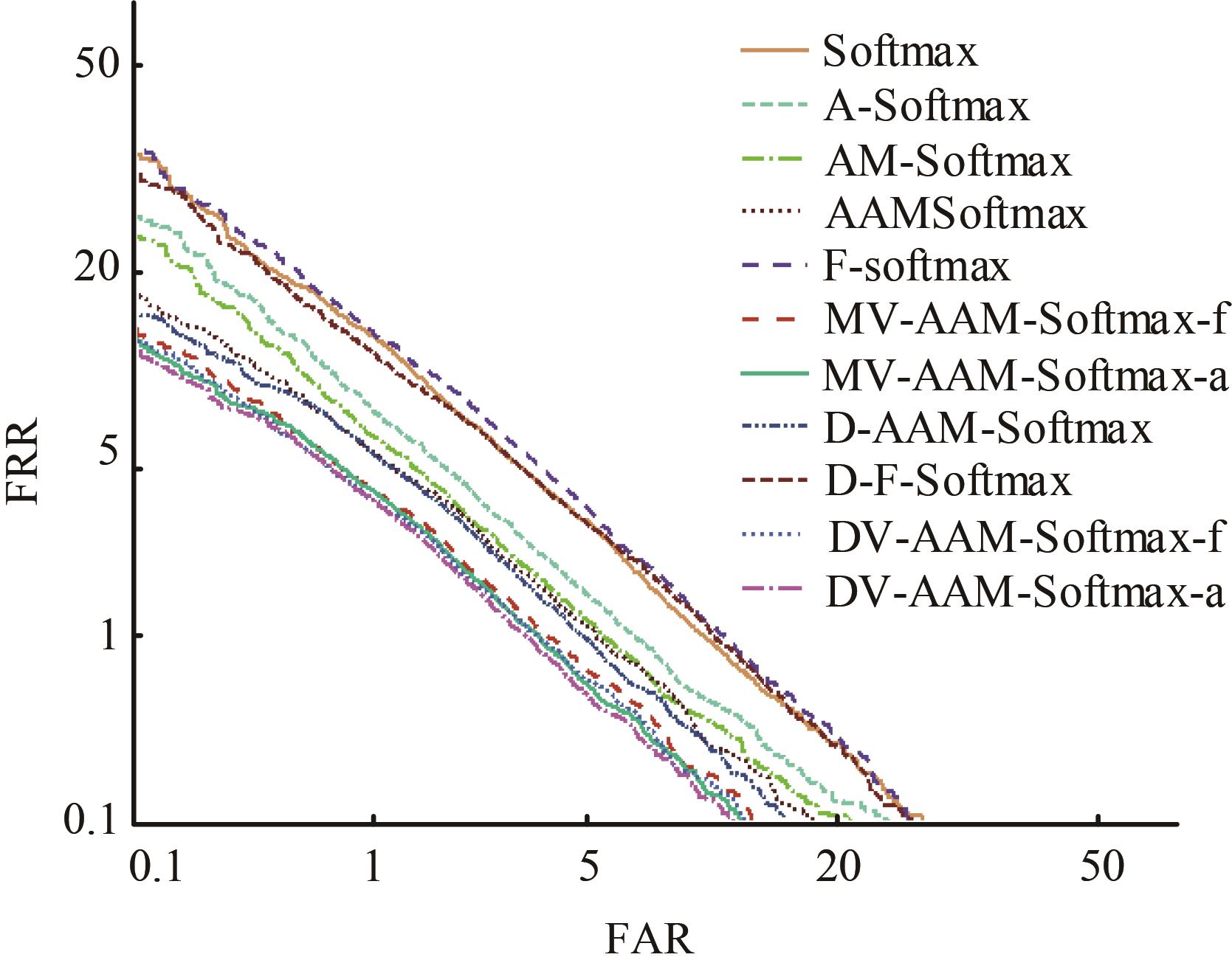
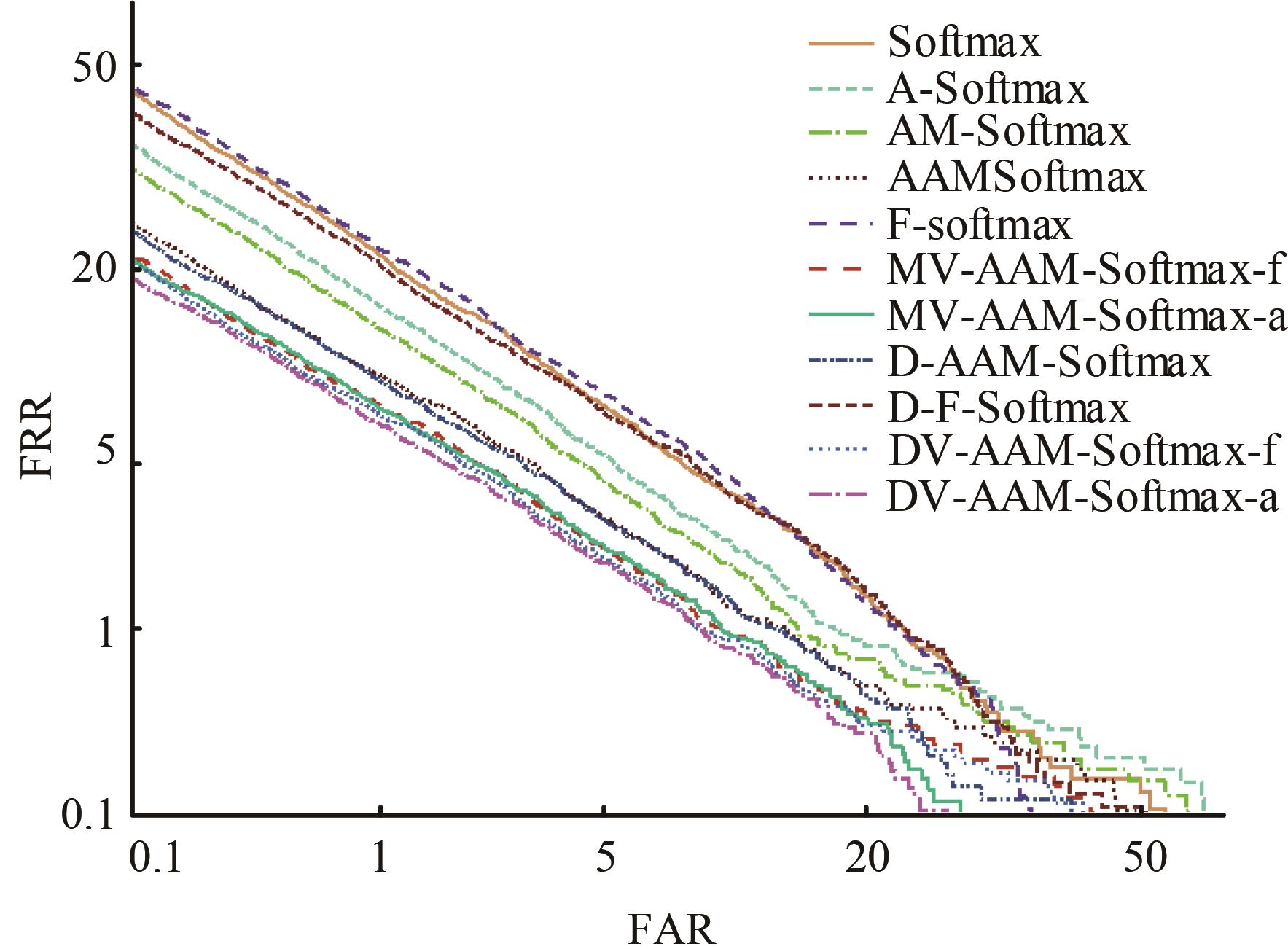
针对声纹识别领域中现有模型分类损失函数无法有效区分类别之间的可分性与缺乏对声纹数据质量关注的问题,本文提出一种新的分类损失函数DV-Softmax。首先,介绍了声纹领域现有边界损失函数工作原理;其次,介绍目标检测领域的挖掘损失函数,并在其基础上提出模糊样本的概念;再次,引入人脸识别领域的MV-Softmax损失函数,并加入模糊样本,使其能自适应强调不同样本之间的区别并指导特征学习;最后,分别在Voxceleb1和SITW数据集进行声纹识别的研究。实验结果表明,DV-Softmax损失函数相较于现有边界损失函数,等错误率分别下降8%和5.4%,其验证了该损失函数有效解决类别之间的可分性及对样本声纹数据质量的关注,并在声纹识别领域具有良好的性能。
中图分类号:
- TN912.34
| 1 | Ranjan R, Castillo C D, Chellappa R. L2-constrained softmax loss for discriminative face verification[J]. Arxiv Preprint, 2017, 3: No.170309507. |
| 2 | Liu W, Wen Y, Yu Z, et al. Sphereface: deep hypersphere embedding for face recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hololulu, USA, 2017: 212-220. |
| 3 | Wang F, Cheng J, Liu W, et al. Additive margin softmax for face verification[J]. IEEE Signal Processing Letters, 2018, 25(7): 926-930. |
| 4 | Deng J, Guo J, Xue N, et al. Arcface: additive angular margin loss for deep face recognition[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 4690-4699. |
| 5 | Thienpondt J, Desplanques B, Demuynck K. Cross-lingual speaker verification with domain-balanced hard prototype mining and language-dependent score normalization[J]. Arxiv Preprint, 2020, 7: No. 200707689. |
| 6 | Li X, Wang W, Wu L J, et al. Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection[J]. Advances in Neural Information Processing Systems, 2020, 33: 21002-21012. |
| 7 | Ma C, Sun H, Zhu J, et al. Normalized maximal margin loss for open-set image classification[J]. IEEE Access, 2021, 9: 54276-54285. |
| 8 | Lee J, Wang Y, Cho S. Angular margin-mining softmax loss for face recognition[J]. IEEE Access, 2022, 10: 43071-43080. |
| 9 | Boutros F, Damer N, Kirchbuchner F, et al. Elasticface: elastic margin loss for deep face recognition[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 1578-1587. |
| 10 | Wang X, Zhang S, Wang S, et al. Mis-classified vector guided softmax loss for face recognition[C]∥ Proceedings of the AAAI Conference on Artificial Intelligence, New York, USA, 2020, 34(7): 12241-12248. |
| 11 | Nagrani A, Chung J S, Zisserman A, et al. Voxceleb: a large-scale speaker identification dataset[J]. Arxiv Preprint, 2017, 6: No.170608612. |
| 12 | Mclaren M, Ferrer L, Castan D, et al. The speakers in the wild (SITW) speaker recognition database[C]∥ Proceedings of the Interspeech, San Francisco, USA, 2016: 818-822. |
| 13 | Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 761-769. |
| 14 | Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2980-2988. |
| 15 | Desplanques B, Thienpondt J, Demuynck K, et al. Ecapa-tdnn: emphasized channel attention, propagation and aggregation in tdnn based speaker verification[C]∥Interspeech, Shanghai, China, 2020: 3830-3834. |
| 16 | Shen H, Yang Y, Sun G, et al. Improving fairness in speaker verification via group-adapted fusion network[C]∥ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 2022: 7077-7081. |
| [1] | 赵孟雪,车翔玖,徐欢,刘全乐. 基于先验知识优化的医学图像候选区域生成方法[J]. 吉林大学学报(工学版), 2025, 55(2): 722-730. |
| [2] | 刘元宁,臧子楠,张浩,刘震. 基于深度学习的核糖核酸二级结构预测方法[J]. 吉林大学学报(工学版), 2025, 55(1): 297-306. |
| [3] | 张曦,库少平. 基于生成对抗网络的人脸超分辨率重建方法[J]. 吉林大学学报(工学版), 2025, 55(1): 333-338. |
| [4] | 徐慧智,蒋时森,王秀青,陈爽. 基于深度学习的车载图像车辆目标检测和测距[J]. 吉林大学学报(工学版), 2025, 55(1): 185-197. |
| [5] | 李路,宋均琦,朱明,谭鹤群,周玉凡,孙超奇,周铖钰. 基于RGHS图像增强和改进YOLOv5网络的黄颡鱼目标提取[J]. 吉林大学学报(工学版), 2024, 54(9): 2638-2645. |
| [6] | 张磊,焦晶,李勃昕,周延杰. 融合机器学习和深度学习的大容量半结构化数据抽取算法[J]. 吉林大学学报(工学版), 2024, 54(9): 2631-2637. |
| [7] | 乔百友,武彤,杨璐,蒋有文. 一种基于BiGRU和胶囊网络的文本情感分析方法[J]. 吉林大学学报(工学版), 2024, 54(7): 2026-2037. |
| [8] | 郭昕刚,何颖晨,程超. 抗噪声的分步式图像超分辨率重构算法[J]. 吉林大学学报(工学版), 2024, 54(7): 2063-2071. |
| [9] | 张丽平,刘斌毓,李松,郝忠孝. 基于稀疏多头自注意力的轨迹kNN查询方法[J]. 吉林大学学报(工学版), 2024, 54(6): 1756-1766. |
| [10] | 孙铭会,薛浩,金玉波,曲卫东,秦贵和. 联合时空注意力的视频显著性预测[J]. 吉林大学学报(工学版), 2024, 54(6): 1767-1776. |
| [11] | 陆玉凯,袁帅科,熊树生,朱绍鹏,张宁. 汽车漆面缺陷高精度检测系统[J]. 吉林大学学报(工学版), 2024, 54(5): 1205-1213. |
| [12] | 李雄飞,宋紫萱,朱芮,张小利. 基于多尺度融合的遥感图像变化检测模型[J]. 吉林大学学报(工学版), 2024, 54(2): 516-523. |
| [13] | 杨国俊,齐亚辉,石秀名. 基于数字图像技术的桥梁裂缝检测综述[J]. 吉林大学学报(工学版), 2024, 54(2): 313-332. |
| [14] | 赵彬,吴成东,张雪娇,孙若怀,姜杨. 基于注意力机制的机械臂目标抓取网络技术[J]. 吉林大学学报(工学版), 2024, 54(12): 3423-3432. |
| [15] | 王勇,边宇霄,李新潮,徐椿明,彭刚,王继奎. 基于多尺度编码-解码神经网络的图像去雾算法[J]. 吉林大学学报(工学版), 2024, 54(12): 3626-3636. |
|
||