吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (10): 3337-3345.doi: 10.13229/j.cnki.jdxbgxb.20231369
• 计算机科学与技术 • 上一篇
资源高效的聚类协同联邦学习客户端选择方法
李强( ),张凌羽,孟祥宇()
),张凌羽,孟祥宇()
- 吉林大学 计算机科学与技术学院,长春 130012
Resource-efficient clustering collaborative federated learning client selection method
Qiang LI(),Ling-yu ZHANG,Xiang-yu MENG()
- College of Computer Science and Technology,Jilin University,Changchun 130012,China
摘要:
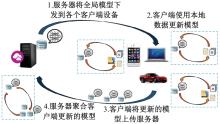
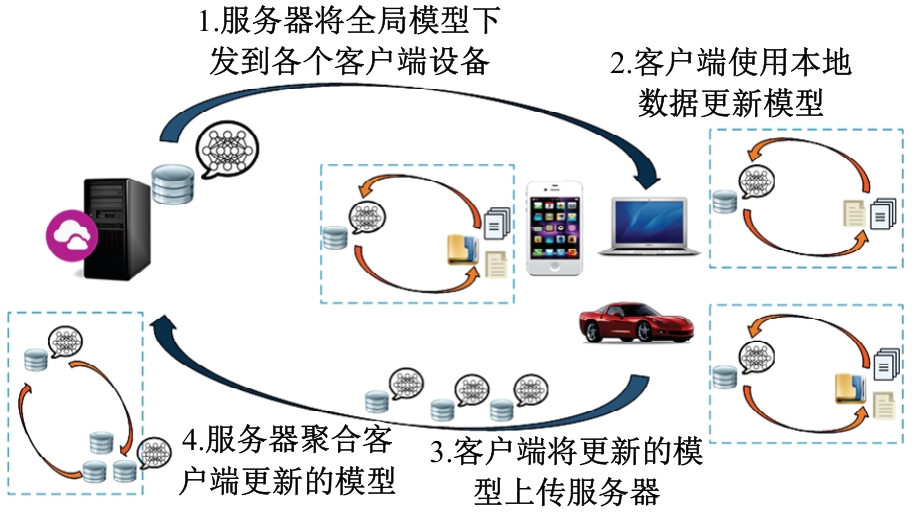
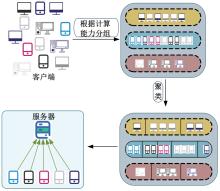
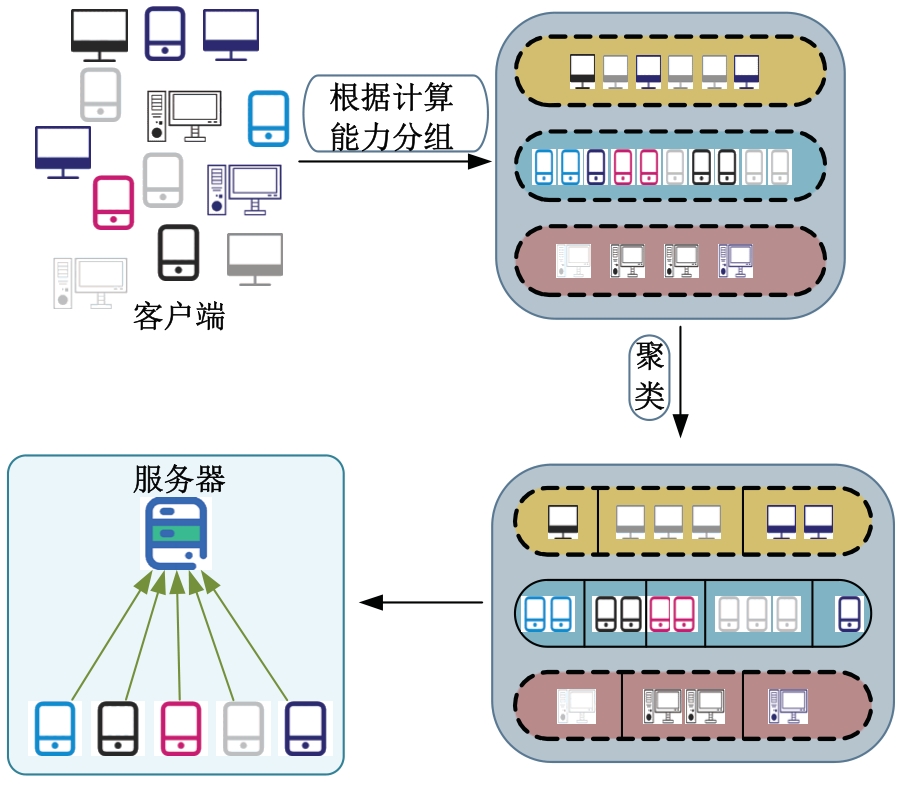
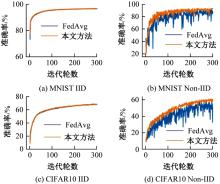
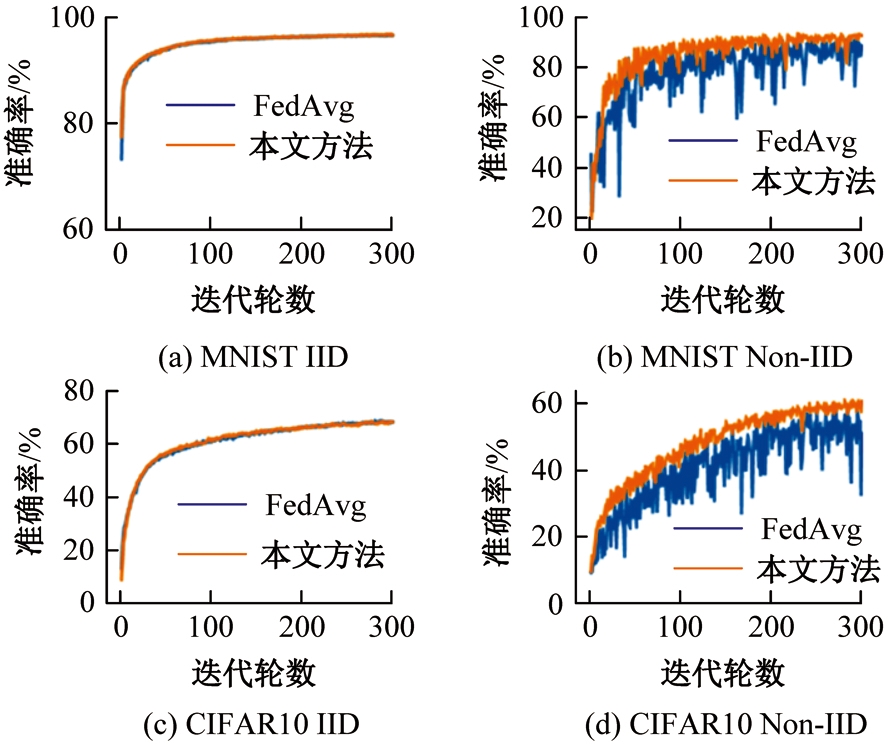
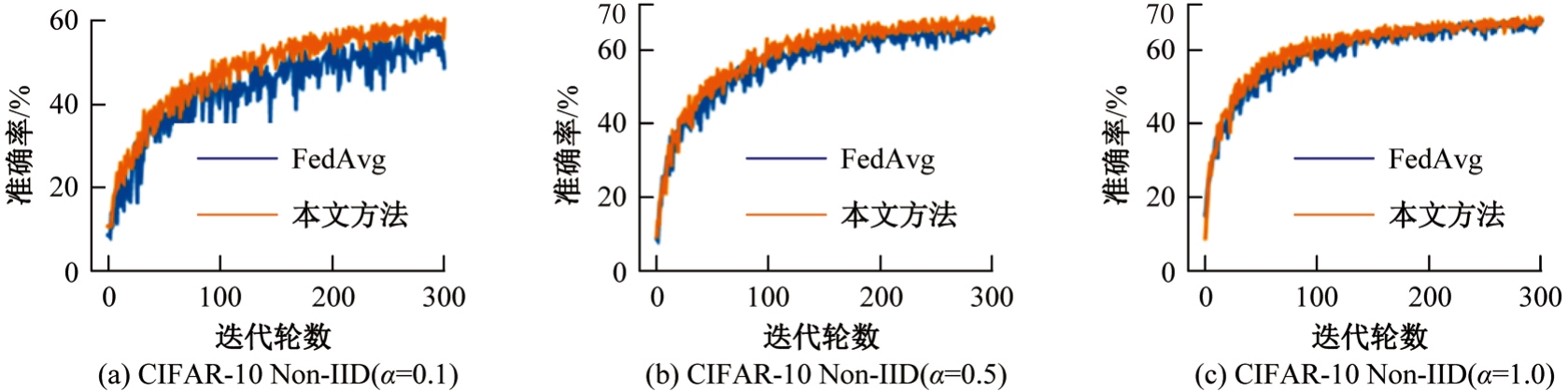
针对联邦学习中各客户端存在资源异构性和数据异构性的关键问题,提出了一种资源高效的聚类协同联邦学习客户端选择方法。首先,根据各客户端的计算能力将其分组,在每轮训练中,以每组客户端的平均准确率作为间接度量选择同组客户端;其次,在每组内根据各客户端的模型相似性对客户端进行聚类,选择每组内不同聚类的客户端;最后在真实数据集上评估本文方法的性能。实验结果表明:该方法可以减少全局训练时间,获得更快速、更平滑的收敛,实现训练效率和全局模型准确率之间的良好平衡。
中图分类号:
- TP301

| [1] | Tankard C. What the GDPR means for businesses[J].Network Security, 2016,2016(6): 5-8. |
| [2] | McMahan H B, Mcore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]∥Proceeding of the 20th Tnternational Conference on Artificial Intelligence and Statistics,Ft. Lauderdale,USA, 2017. |
| [3] | Abadi M, Chu A, Goodfellow L, et al. Deep learning with differential privacy[C]∥Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security,Vienna, Austria, 2016:308-318. |
| [4] | Bonawitz K, Ivanow V, Kreuter B, et al. Practical secure aggregation for privacy-preserving machine learning[C]∥Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security,Dallas, USA, 2017: 1175-1191. |
| [5] | McMahan H B, Ramage D, Kunal T, et al. Learning differentially private recurrent language models[J/OL].[2022-11-22]. ,2017. |
| [6] | Chai Z, Ali A, Zawad S, et al. Tifl: A tier-based federated learning system[C]∥Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing,Stockholm, Sweden, 2020: 125-136. |
| [7] | Nishio T, Yonetani R. Client selection for federated learning with heterogeneous resources in mobile edge[C]∥IEEE International Conference on Communications(ICC), Piscataway, USA, 2019:1-7. |
| [8] | Karimireddy S P, Kale S, Mohri M, et al. SCAFFOLD: Stochastic controlled averaging for federated learning[C]∥International Conference on Machine Learning,Online, 2020:5132-5143. |
| [9] | Fraboni Y, Vidal R, Kamenl L, et al. Clustered sampling: Low-variance and improved representativity for clients selection in federated learning[C]∥Preceeding of the 38th International Conference on Machine Learning, Online, 2021: 3407-3416. |
| [10] | Li T, Sahu A K, Zaheer M, et al. Federated optimization in heterogeneous networks[J]. Proceedings of Machine Learning and Systems, 2020, 2: 429-450. |
| [11] | Shu J G, Zhong W Z, Zhou Y, et al. FLAS: Computation and communication efficient federated learning via adaptive sampling[J]. IEEE Transactions on Network Science and Engineering,2021,9(4): 2003-2014. |
| [12] | Bonawitz K, Eichner H, Grieskamp W, et al. Towards federated learning at scale: System design[J]. Proceedings of Machine Learning and Systems, 2019, 1: 374-388. |
| [13] | Ward J H. Hierarchical grouping to optimize an objective function[J]. Journal of the American Statistical Association,1963, 58(301): 236-244. |
| [14] | Sattler F, Müller K R, Samek W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 32(8): 3710-3722. |
| [15] | LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| [16] | Krizhevsk, Hinton G. Learning multiple layers of features from tiny images[R]. Toronto: University of Toronto, 2009. |
| [17] | Hsu T M H, Qi H, Brown M. Measuring the effects of non-identical data distribution for federated visual classification[J/OL].[2022-11-22]. ,2019. |
| [1] | 周求湛,李新萌,沈皓庆子,武慧南,李媛媛,荣静,胡春华,刘萍萍. 基于注意力机制的不平衡数据的非侵入式负荷分解[J]. 吉林大学学报(工学版), 2026, 56(1): 239-246. |
| [2] | 赵庶旭,孙治朝,王小龙. 移动边缘计算场景中的动态身份认证协议[J]. 吉林大学学报(工学版), 2025, 55(3): 1050-1060. |
| [3] | 朱齐亮,余雪婷. k-prototype聚类算法和相对熵下敏感数据重发布隐私安全保护[J]. 吉林大学学报(工学版), 2025, 55(3): 1009-1014. |
| [4] | 马书红,张俊杰,陈西芳,廖国美. 利用出租车时序数据识别城市功能区[J]. 吉林大学学报(工学版), 2025, 55(2): 603-613. |
| [5] | 郭昕刚,王嵩,程超,范珍. 联合博弈论与驾驶风格的混合交通流变道决策模型[J]. 吉林大学学报(工学版), 2025, 55(12): 3875-3884. |
| [6] | 李松,刘晓楠,刘娟. 基于JS散度的不确定数据密度峰值聚类算法[J]. 吉林大学学报(工学版), 2024, 54(7): 2038-2048. |
| [7] | 张玺君,余光杰,崔勇,尚继洋. 基于聚类算法和图神经网络的短时交通流预测[J]. 吉林大学学报(工学版), 2024, 54(6): 1593-1600. |
| [8] | 魏晓辉,王晨洋,吴旗,郑新阳,于洪梅,岳恒山. 面向脉动阵列神经网络加速器的软错误近似容错设计[J]. 吉林大学学报(工学版), 2024, 54(6): 1746-1755. |
| [9] | 曲福恒,潘曰涛,杨勇,胡雅婷,宋剑飞,魏成宇. 基于加权空间划分的高效全局K-means聚类算法[J]. 吉林大学学报(工学版), 2024, 54(5): 1393-1400. |
| [10] | 吕莉,朱梅子,康平,韩龙哲. 二阶K近邻和多簇合并的密度峰值聚类算法[J]. 吉林大学学报(工学版), 2024, 54(5): 1417-1425. |
| [11] | 张西广,张龙飞,马钰锡,樊银亭. 基于密度峰值的海量云数据模糊聚类算法设计[J]. 吉林大学学报(工学版), 2024, 54(5): 1401-1406. |
| [12] | 陈桂珍,程慧婷,朱才华,李昱燃,李岩. 考虑驾驶员生理信息的城市交叉口风险评估方法[J]. 吉林大学学报(工学版), 2024, 54(5): 1277-1284. |
| [13] | 刘迪,孙耀,胡云峰,陈虹. 基于密度聚类的商用车编队策略[J]. 吉林大学学报(工学版), 2024, 54(5): 1459-1468. |
| [14] | 李德林,陈俊先,王永岗,王露,沈照庆. 基于潜在类别模型的急陡弯路段驾驶行为辨析[J]. 吉林大学学报(工学版), 2024, 54(12): 3526-3533. |
| [15] | 易晓宇,易绵竹. 基于兴趣信息深度融合的网络图书资源推荐[J]. 吉林大学学报(工学版), 2024, 54(12): 3614-3619. |
|
||