吉林大学学报(工学版) ›› 2022, Vol. 52 ›› Issue (3): 666-674.doi: 10.13229/j.cnki.jdxbgxb20200842
• 计算机科学与技术 • 上一篇
面向文本游戏的深度强化学习模型
刘勇( ),徐雷,张楚晗
),徐雷,张楚晗
- 黑龙江大学 计算机科学技术学院,哈尔滨 150080
Deep reinforcement learning model for text games
Yong LIU(),Lei XU,Chu-han ZHANG
- School of Computer Science and Technology,Heilongjiang University,Harbin 150080,China
摘要:
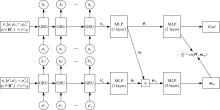
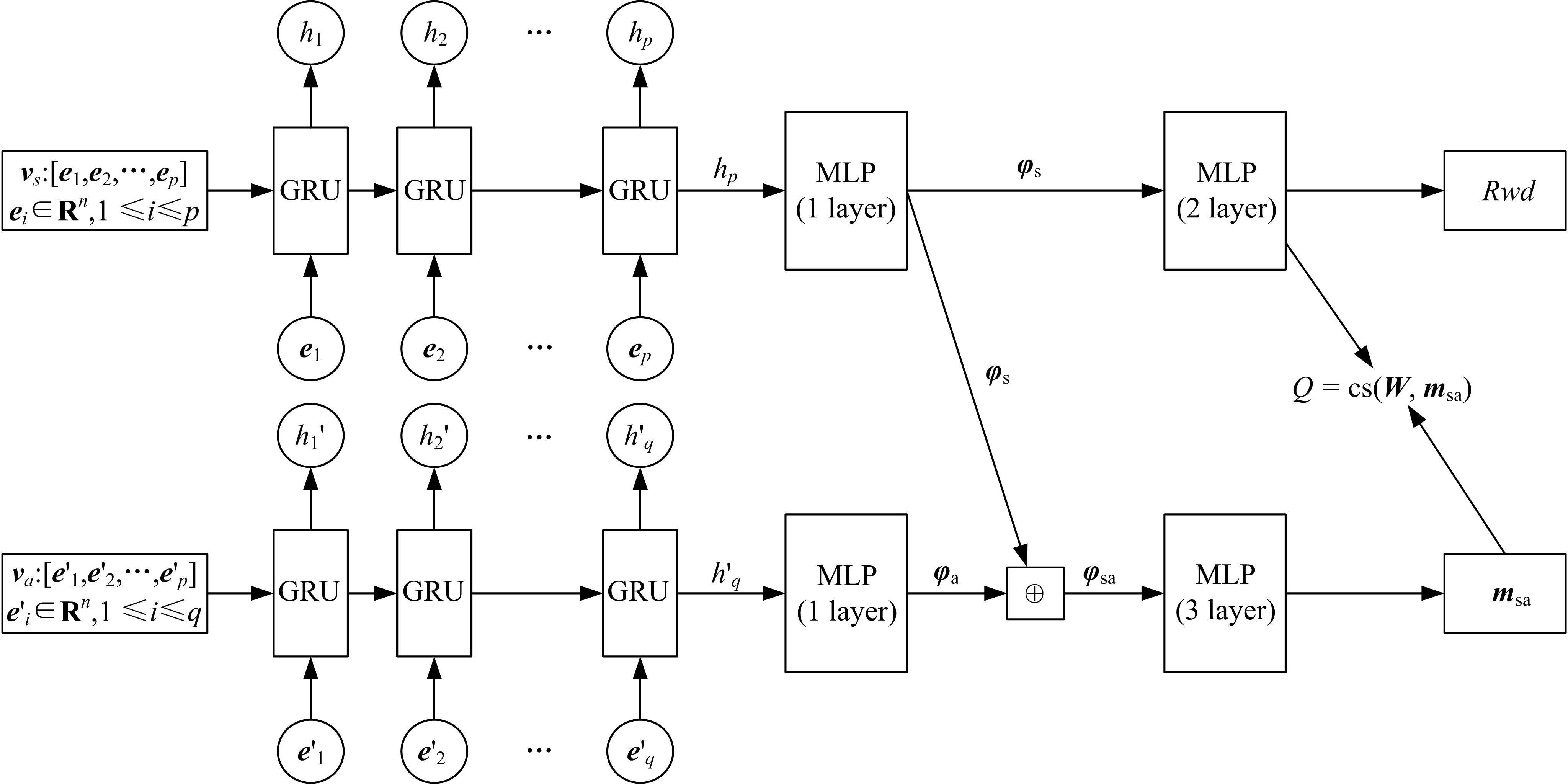
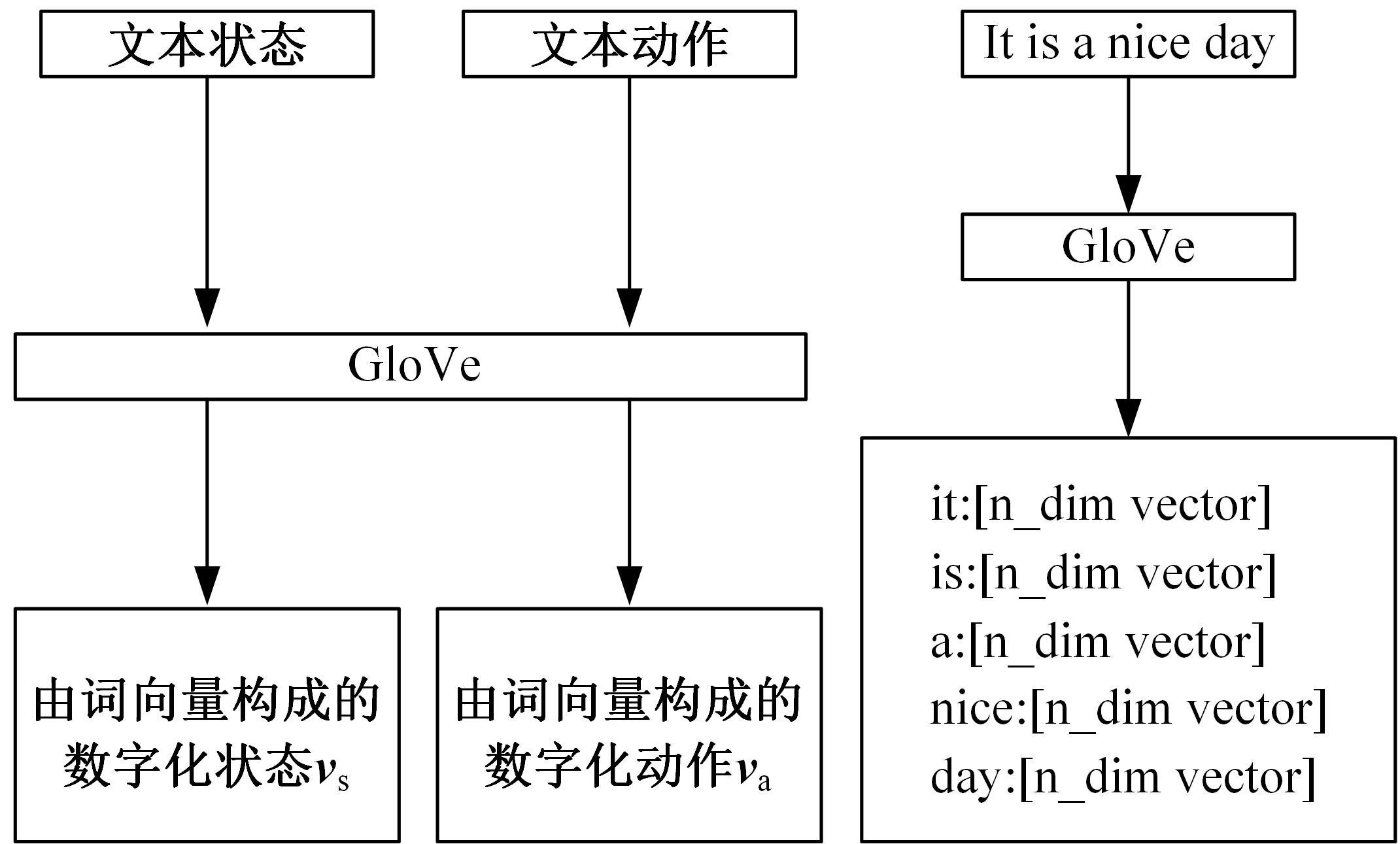
为了提高文本游戏中智能体的表现性能,提出了一种基于孪生网络和深度后继表示的深度强化学习模型SADSR。首先,使用自然语言处理技术对文本信息进行处理,得到词的嵌入向量,有效地将文本信息转化为数字向量。然后,利用孪生网络分别对状态和动作信息进行特征提取,通过提取到的状态特征向量预测即时奖励,使用状态和动作的联合向量预测后继表示。最后,将后继表示与特定层的权重向量通过交互函数进行计算得到动作价值。实验结果表明:该模型可以有效对价值函数进行拟合,与目前的主流模型相比,SADSR可以将文本游戏中智能体的表现性能提高10%~60%。
中图分类号:
- TP181
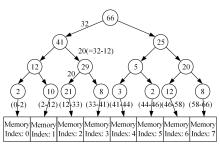
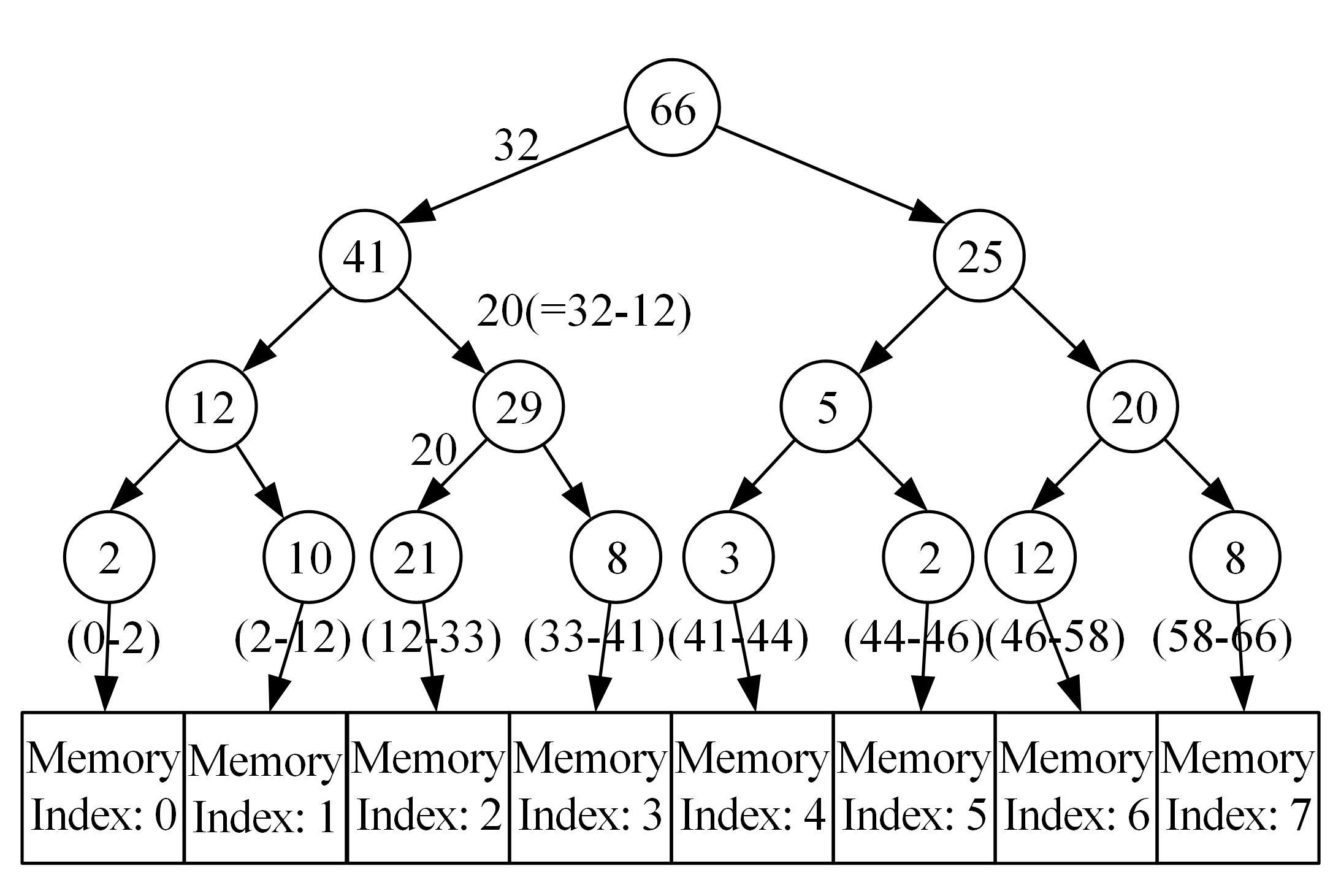
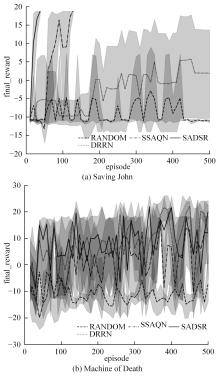
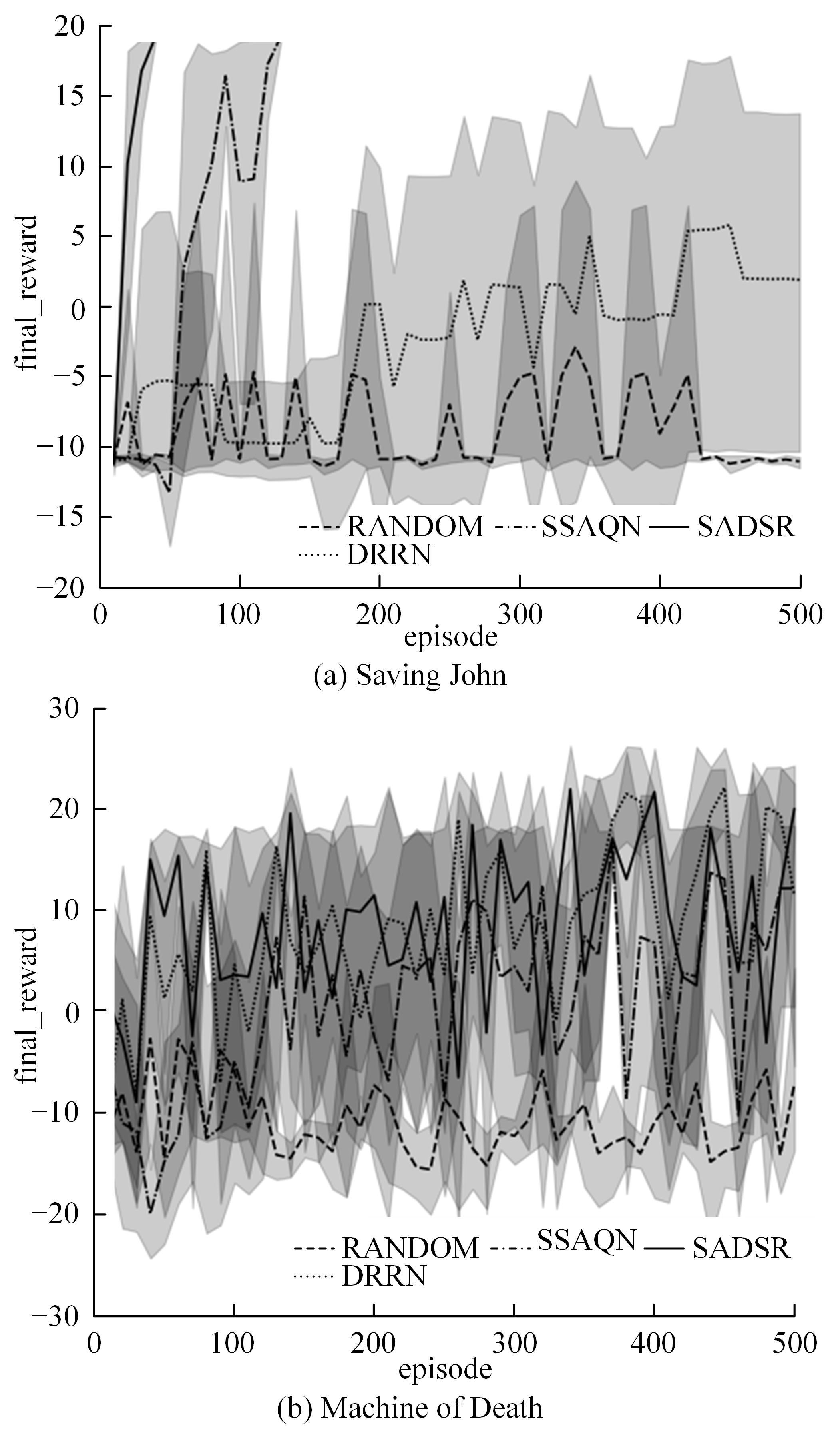
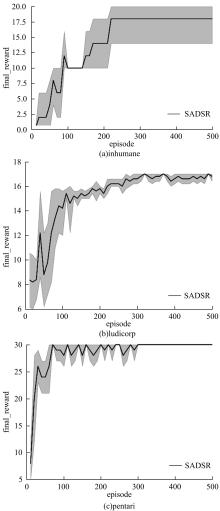
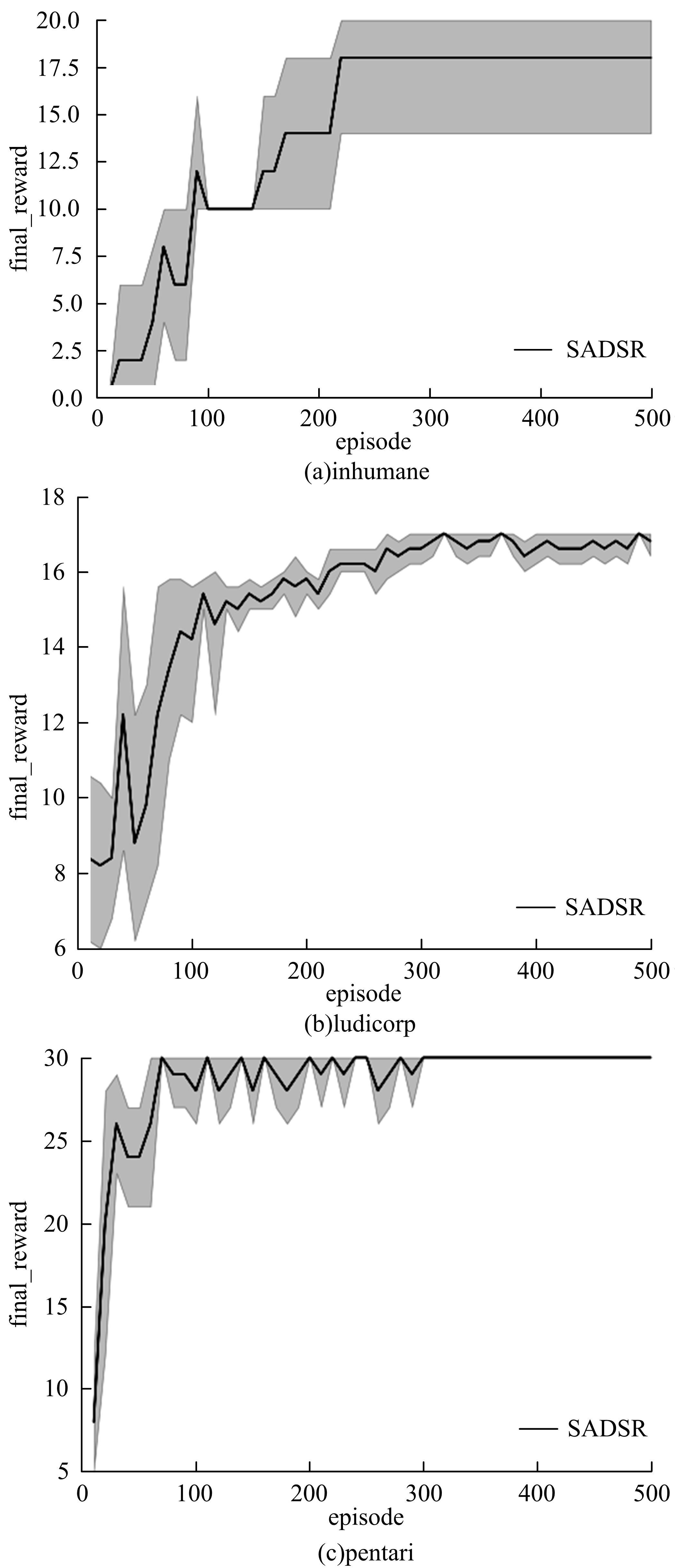
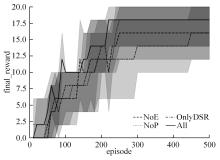
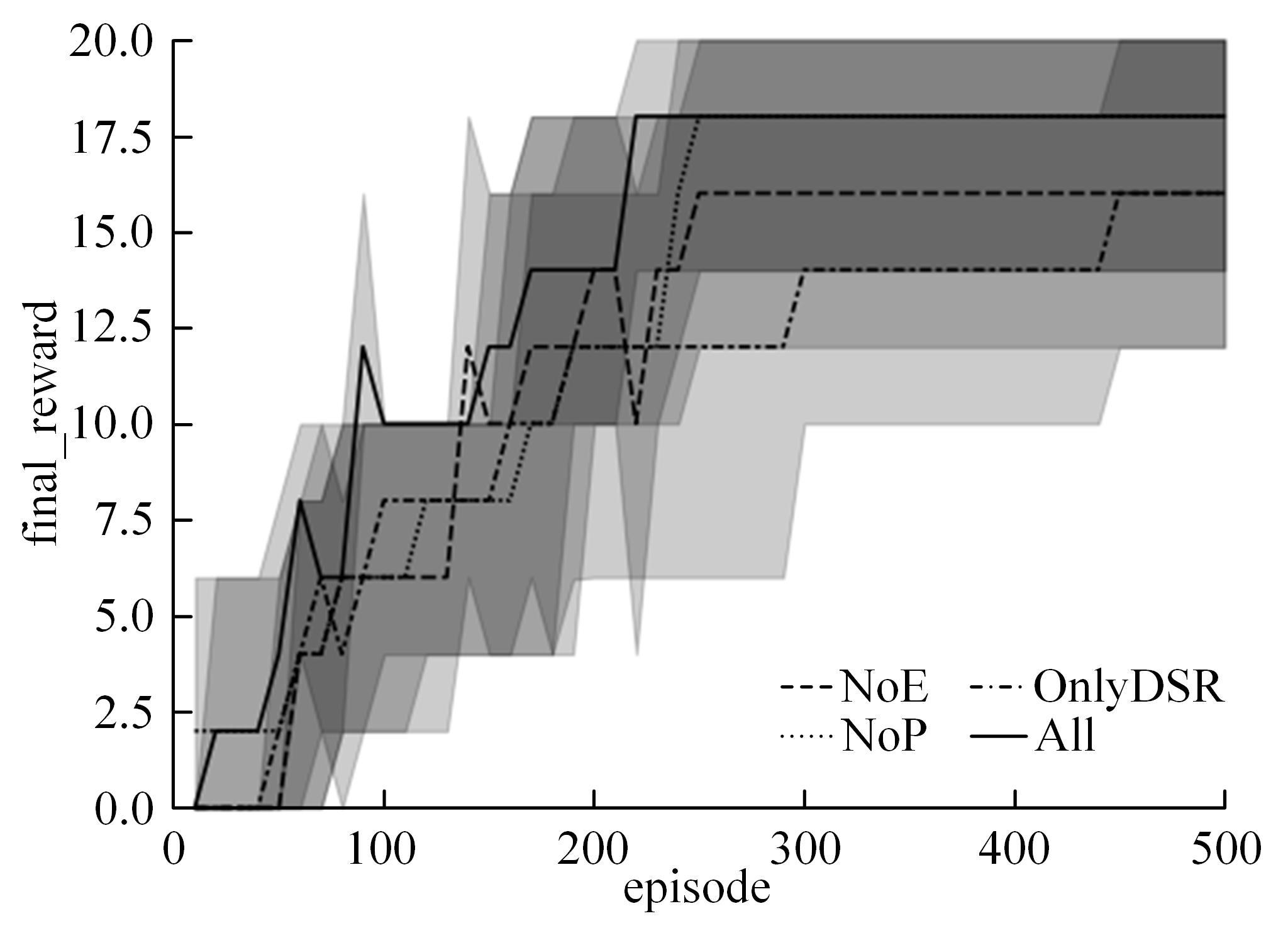
| 1 | 赵亚慧, 杨飞扬, 张振国,等. 基于强化学习和注意力机制的朝鲜语文本结构发现[J]. 吉林大学学报: 工学版, 2021, 51(4): 1387-1395. |
| Zhao Ya-hui, Yang Fei-yang, Zhang Zhen-guo, et al. Korean text structure discovery based on reinforcement learning and attention mechanism[J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(4): 1387-1395. | |
| 2 | Coskun-Setirek A, Mardikyan S. Understanding the adoption of voice activated personal assistants[J]. International Journal of E-Services and Mobile Applications, 2017, 9(3): 1-21. |
| 3 | Green S, Wang S, Chuang J, et al. Human effort and machine learnability in computer aided translation[C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1225-1236. |
| 4 | Pietquin O, Renals S. ASR system modeling for automatic evaluation and optimization of dialogue systems[C]∥Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, Florida, USA, 2002: 45-48. |
| 5 | Dolgov D, Thrun S. Detection of principle directions in unknown environments for autonomous navigation[C]∥Robotics: Science and Systems, Zurich, Switzerland, 2009: 73-80. |
| 6 | Sutton R S, Barto A G. Reinforcement Learning: An Introduction[M]. Cambridge, MA, USA: MIT Press, 1998. |
| 7 | Pennington J, Socher R, Manning C D. GloVe: global vectors for word representation[C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1532-1543. |
| 8 | Gershman S, Moore C D, Todd M T, et al. The successor representation and temporal context[J]. Neural Computation, 2012, 24(6): 1553-1568. |
| 9 | Kulkarni T D, Saeedi A, Gautam S, et al. Deep successor reinforcement learning[EB/OL].[2020-11-02]. |
| 10 | Cho K, Merrienboer B V, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 2014: 1724-1734. |
| 11 | Mnih V, Kavukcuoglu K, Silver D, et al. Playing atari with deep reinforcement learning[J/OL]. [2020-11-02]. |
| 12 | Schaul T, Quan J, Antonoglou I, et al. Prioritized experience replay[J/OL]. [2020-11-03]. |
| 13 | He J, Chen J S, He X D, et al. Deep reinforcement learning with a natural language action space[C]∥Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Washington, Seattle, USA, 2016: 1621-1630. |
| 14 | Zelinka M. Baselines for reinforcement learning in text games[C]∥IEEE 30th International Conference on Tools with Artificial Intelligence, Volos, Greece, 2018: 320-327. |
| 15 | Hausknecht M J, Ammanabrolu P, M-A Côté, et al. Interactive fiction games: a colossal adventure[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 7903-7910. |
| 16 | Brockman G, Cheung V, Pettersson L, et al. Openai gym[J/OL]. [2020-11-08]. |
| 17 | Hausknecht M J, Loynd R, Yang G, et al. NAIL: a general interactive fiction agent[J/OL]. [2020-11-08]. |
| 18 | Narasimhan K, Kulkarni T D, Barzilay R, et al. Language understanding for text-based games using deep reinforcement learning[C]∥Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 2015: 1-11. |
| [1] | 雷景佩,欧阳丹彤,张立明. 基于知识图谱嵌入的定义域值域约束补全方法[J]. 吉林大学学报(工学版), 2022, 52(1): 154-161. |
| [2] | 李志华,张烨超,詹国华. 三维水声海底地形地貌实时拼接与可视化[J]. 吉林大学学报(工学版), 2022, 52(1): 180-186. |
| [3] | 欧阳丹彤,张必歌,田乃予,张立明. 结合格局检测与局部搜索的故障数据缩减方法[J]. 吉林大学学报(工学版), 2021, 51(6): 2144-2153. |
| [4] | 徐艳蕾,何润,翟钰婷,赵宾,李陈孝. 基于轻量卷积网络的田间自然环境杂草识别方法[J]. 吉林大学学报(工学版), 2021, 51(6): 2304-2312. |
| [5] | 杨勇,陈强,曲福恒,刘俊杰,张磊. 基于模拟划分的SP⁃k⁃means-+算法[J]. 吉林大学学报(工学版), 2021, 51(5): 1808-1816. |
| [6] | 赵亚慧,杨飞扬,张振国,崔荣一. 基于强化学习和注意力机制的朝鲜语文本结构发现[J]. 吉林大学学报(工学版), 2021, 51(4): 1387-1395. |
| [7] | 董延华,刘靓葳,赵靖华,李亮,解方喜. 基于BPNN在线学习预测模型的扭矩实时跟踪控制[J]. 吉林大学学报(工学版), 2021, 51(4): 1405-1413. |
| [8] | 吕帅,刘京. 基于深度强化学习的随机局部搜索启发式方法[J]. 吉林大学学报(工学版), 2021, 51(4): 1420-1426. |
| [9] | 刘富,梁艺馨,侯涛,宋阳,康冰,刘云. 模糊c-harmonic均值算法在不平衡数据上改进[J]. 吉林大学学报(工学版), 2021, 51(4): 1447-1453. |
| [10] | 尚福华,曹茂俊,王才志. 基于人工智能技术的局部离群数据挖掘方法[J]. 吉林大学学报(工学版), 2021, 51(2): 692-696. |
| [11] | 赵海英,周伟,侯小刚,张小利. 基于多任务学习的传统服饰图像双层标注[J]. 吉林大学学报(工学版), 2021, 51(1): 293-302. |
| [12] | 欧阳丹彤,马骢,雷景佩,冯莎莎. 知识图谱嵌入中的自适应筛选[J]. 吉林大学学报(工学版), 2020, 50(2): 685-691. |
| [13] | 李贻斌,郭佳旻,张勤. 人体步态识别方法与技术[J]. 吉林大学学报(工学版), 2020, 50(1): 1-18. |
| [14] | 徐谦,李颖,王刚. 基于深度学习的行人和车辆检测[J]. 吉林大学学报(工学版), 2019, 49(5): 1661-1667. |
| [15] | 高万夫,张平,胡亮. 基于已选特征动态变化的非线性特征选择方法[J]. 吉林大学学报(工学版), 2019, 49(4): 1293-1300. |
|
||