吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (6): 2082-2088.doi: 10.13229/j.cnki.jdxbgxb.20230964
基于数据增强的半监督单目深度估计框架
赵宏伟( ),周伟民
),周伟民
- 吉林大学 软件学院,长春 130012
Semi⁃supervised monocular depth estimation framework based on data augmentation
Hong-wei ZHAO(),Wei-min ZHOU
- College of Software,Jilin University,Changchun 130012,China
摘要:
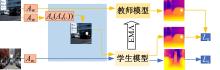
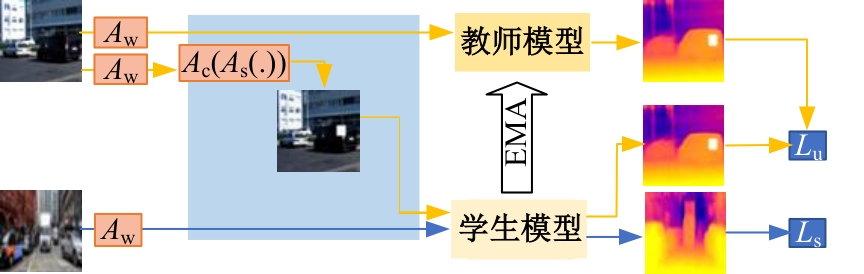
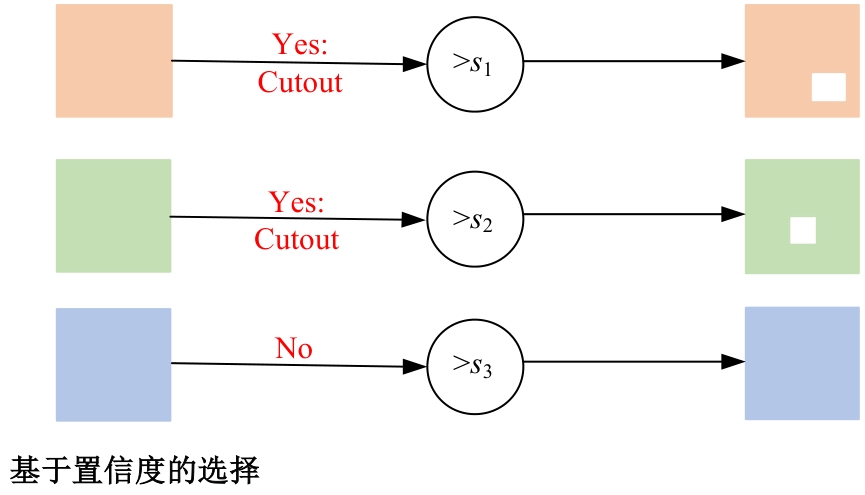
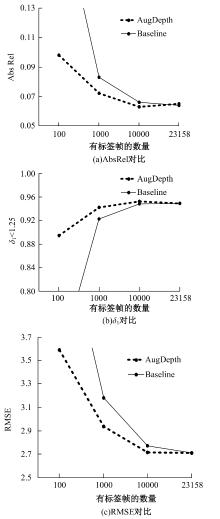
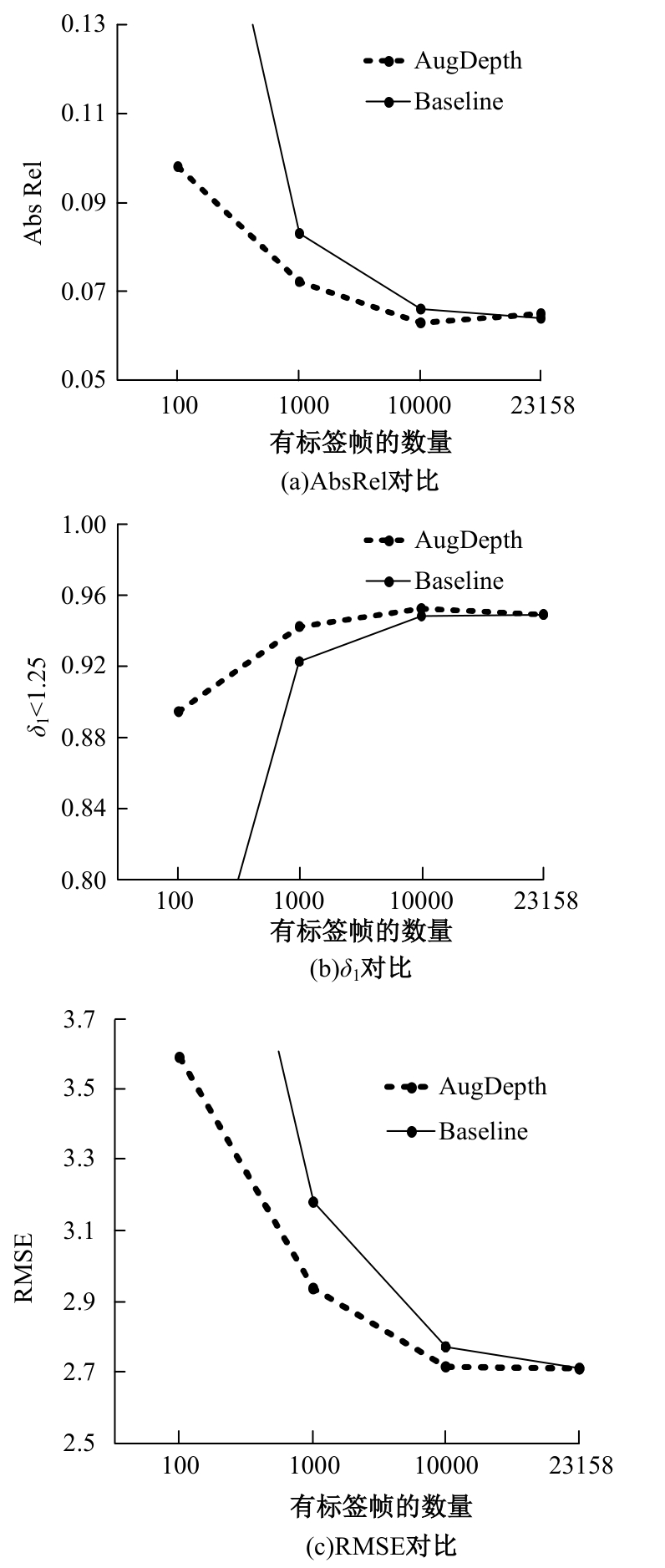
为解决监督学习在单目深度估计中需要大量标签数据的问题,提出了一种基于教师-学生模型的半监督深度估计框架AugDepth。其通过对数据进行扰动,训练模型学习扰动前、后的深度一致性。首先,采用平滑随机强度增强方法从连续域中采样强度,随机选择多个操作以增加数据随机性,并混合强弱增强输出,防止过度扰动。然后,考虑到不同无标签样本的训练难度不同,在通过Cutout提高模型对全局信息推理的前提下,根据对无标签样本的置信度,自适应地调整Cutout策略,以提高模型的泛化和学习能力。在KITTI和NYU-Depth数据集上的实验结果表明:AugDepth能够显著提高半监督深度估计的准确性,并在有标签数据稀缺的情况下表现出良好的鲁棒性。
中图分类号:
- TP391
| [1] | Eigen D, Puhrsch C, Fergus R. Depth map predictionfrom a single image using a multi-scale deep network[C]∥Advances in Neural Information Processing Systems,Montreal, Canada, 2014: 2366-2374. |
| [2] | Song M, Lim S, Kim W. Monocular depth estimation using laplacian pyramid-based depth residuals[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(11): 4381-4393. |
| [3] | Lee J H, Han M K, Ko D W, et al. From big to small: multi-scale local planar guidance for monocular depth estimation[J/OL].[2023-08-26]. |
| [4] | Ji R, Li K, Wang Y, et al. Semi-supervised adversarial monocular depth estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2410-2422. |
| [5] | Cho J, Min D, Kim Y, et al. A large RGB-D dataset for semi-supervised monocular depth estimation[J/OL]. [2023-08-27]. |
| [6] | Guo X, Li H, Yi S, et al. Learning monocular depth by distilling cross-domain stereo networks[C]∥Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 506-523. |
| [7] | Cubuk E D, Zoph B, Shlens J, et al. Randaugment: practical automated data augmentation with a reduced search space[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops,Seattle, USA, 2020: 702-703. |
| [8] | Zhao Z, Yang L, Long S, et al. Augmentation matters: a simple-yet-effective approach to semi-supervisedsemantic segmentation[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Vancouver, Canada,2023: 11350-11359. |
| [9] | Zhao Z, Long S, Pi J, et al. Instance-specific and model-adaptive supervision for semi-supervised semantic segmentation[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada,2023: 23705-23714. |
| [10] | de Vries T, Taylor G W. Improved regularization of convolutional neural networks with cutout[J/OL].[2023-08-28]. |
| [11] | Tarvainen A, Valpola H. Mean teachers are better rolemodels: weight-averaged consistency targets improve semi-supervised deep learning results[C]∥Advances in Neural Information Processing System,Vancouver, Canada, 2017: 1195-1204. |
| [12] | Yuan J, Liu Y, Shen C, et al. A simple baseline for semi-supervised semantic segmentation with strong data augmentation[C]∥IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 8209-8218. |
| [13] | Poggi M, Aleotti F, Tosi F, et al. On the uncertainty of self-supervised monocular depth estimation[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,Seattle, USA, 2020: 3227-3237. |
| [14] | Baek J, Kim G, Park S, et al. MaskingDepth: masked consistency regularization for semi-supervised monocular depth estimation[J/OL]. [2023-08-29]. |
| [15] | Fu H, Gong M, Wang C, et al. Deep ordinal regression network for monocular depth estimation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Los Alamitos,USA, 2018: 2002-2011. |
| [16] | Godard C, Aodha O M, Firman M, et al. Digging into self-supervised monocular depth estimation[C]∥IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 2019: 3827-3837. |
| [17] | Shu C, Yu K, Duan Z, et al. Feature-metric loss for self-supervised learning of depth and egomotion[C]∥European Conference on Computer Vision,Glasgow, UK, 2020: 572-588. |
| [18] | Amiri A J, Loo S Y, Zhang H. Semi-supervised monocular depth estimation with left-right consistency using deep neural network[C]∥IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali,China,2019: 602-607. |
| [19] | Ranftl R, Bochkovskiy A, Koltun V. Vision transformers for dense prediction[C]∥IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 12159-12168. |
| [1] | 王健,贾晨威. 面向智能网联车辆的轨迹预测模型[J]. 吉林大学学报(工学版), 2025, 55(6): 1963-1972. |
| [2] | 车翔玖,孙雨鹏. 基于相似度随机游走聚合的图节点分类算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2069-2075. |
| [3] | 刘萍萍,商文理,解小宇,杨晓康. 基于细粒度分析的不均衡图像分类算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2122-2130. |
| [4] | 周丰丰,郭喆,范雨思. 面向不平衡多组学癌症数据的特征表征算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2089-2096. |
| [5] | 陈海鹏,张世博,吕颖达. 多尺度感知与边界引导的图像篡改检测方法[J]. 吉林大学学报(工学版), 2025, 55(6): 2114-2121. |
| [6] | 申自浩,高永生,王辉,刘沛骞,刘琨. 面向车联网隐私保护的深度确定性策略梯度缓存方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1638-1647. |
| [7] | 王友卫,刘奥,凤丽洲. 基于知识蒸馏和评论时间的文本情感分类新方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1664-1674. |
| [8] | 赵宏伟,周明珠,刘萍萍,周求湛. 基于置信学习和协同训练的医学图像分割方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1675-1681. |
| [9] | 程德强,王伟臣,韩成功,吕晨,寇旗旗. 基于改进密集网络和小波分解的自监督单目深度估计[J]. 吉林大学学报(工学版), 2025, 55(5): 1682-1691. |
| [10] | 侯越,郭劲松,林伟,张迪,武月,张鑫. 分割可跨越车道分界线的多视角视频车速提取方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1692-1704. |
| [11] | 王军,司昌馥,王凯鹏,付强. 融合集成学习技术和PSO-GA算法的特征提取技术的入侵检测方法[J]. 吉林大学学报(工学版), 2025, 55(4): 1396-1405. |
| [12] | 徐涛,孔帅迪,刘才华,李时. 异构机密计算综述[J]. 吉林大学学报(工学版), 2025, 55(3): 755-770. |
| [13] | 赵孟雪,车翔玖,徐欢,刘全乐. 基于先验知识优化的医学图像候选区域生成方法[J]. 吉林大学学报(工学版), 2025, 55(2): 722-730. |
| [14] | 蔡晓东,周青松,张言言,雪韵. 基于动静态和关系特征全局捕获的社交推荐模型[J]. 吉林大学学报(工学版), 2025, 55(2): 700-708. |
| [15] | 车翔玖,武宇宁,刘全乐. 基于因果特征学习的有权同构图分类算法[J]. 吉林大学学报(工学版), 2025, 55(2): 681-686. |
|