吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (7): 2409-2417.doi: 10.13229/j.cnki.jdxbgxb.20230881
• 计算机科学与技术 • 上一篇
基于三维卷积与自注意力机制的视频行人重识别
庄珊娜1,2( ),王君帅1,2,白晶1,2(),杜京瑾1,2,王正友1,2
),王君帅1,2,白晶1,2(),杜京瑾1,2,王正友1,2
- 1.石家庄铁道大学 信息科学与技术学院,石家庄 050043
2.河北省电磁环境效应与信息处理重点实验室,石家庄 050043
Video-based person re-identification based on three-dimensional convolution and self-attention mechanism
Shan-na ZHUANG1,2(),Jun-shuai WANG1,2,Jing BAI1,2(),Jing-jin DU1,2,Zheng-you WANG1,2
- 1.School of Information Science and Technology,Shijiazhuang Tiedao University,Shijiazhuang 050043,China
2.Hebei Provincial Key Laboratory of Electromagnetic Environmental Effects and Information Processing,Shijiazhuang 050043,China
摘要:
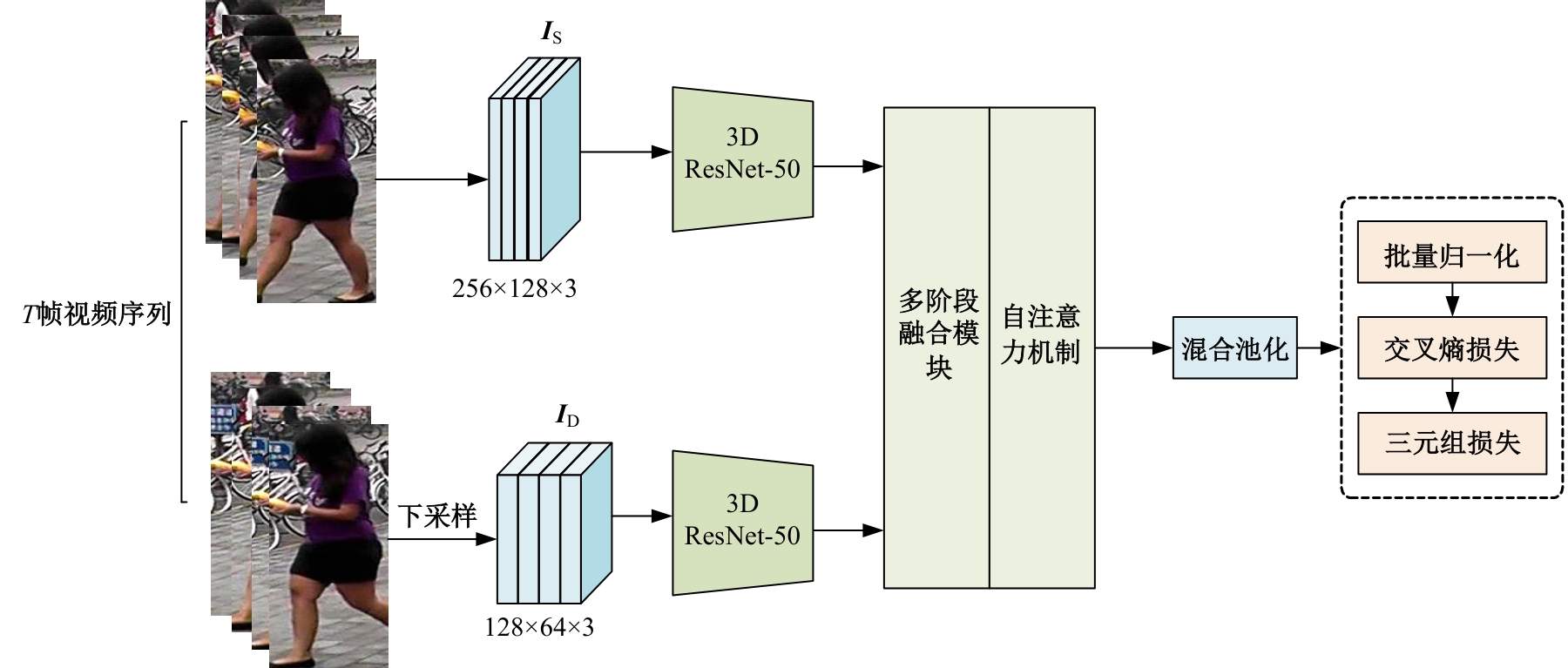
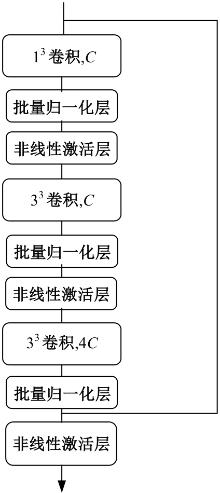
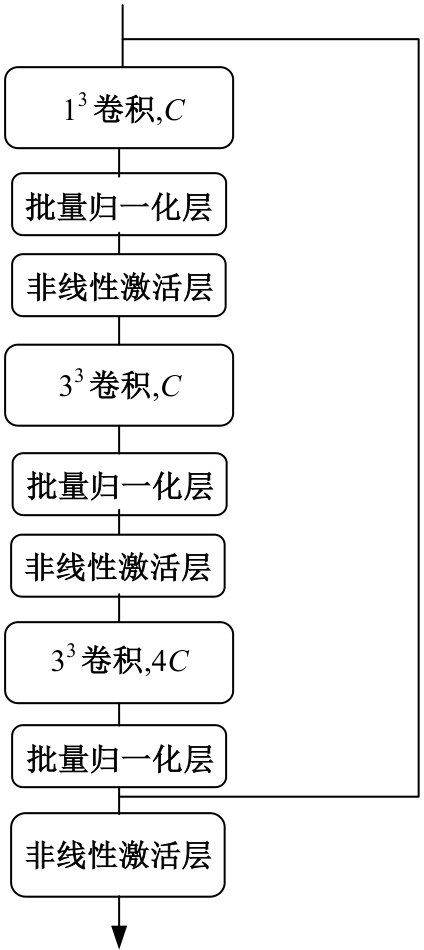
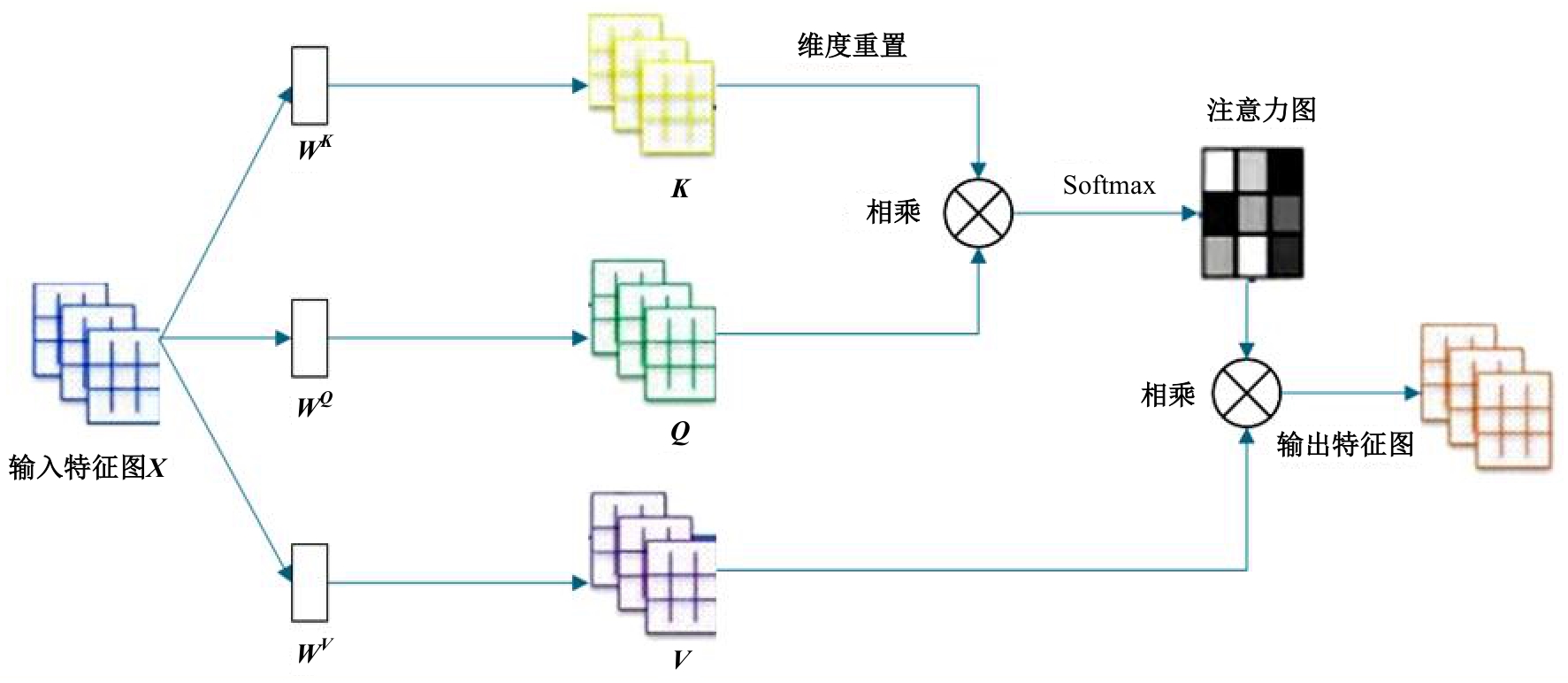
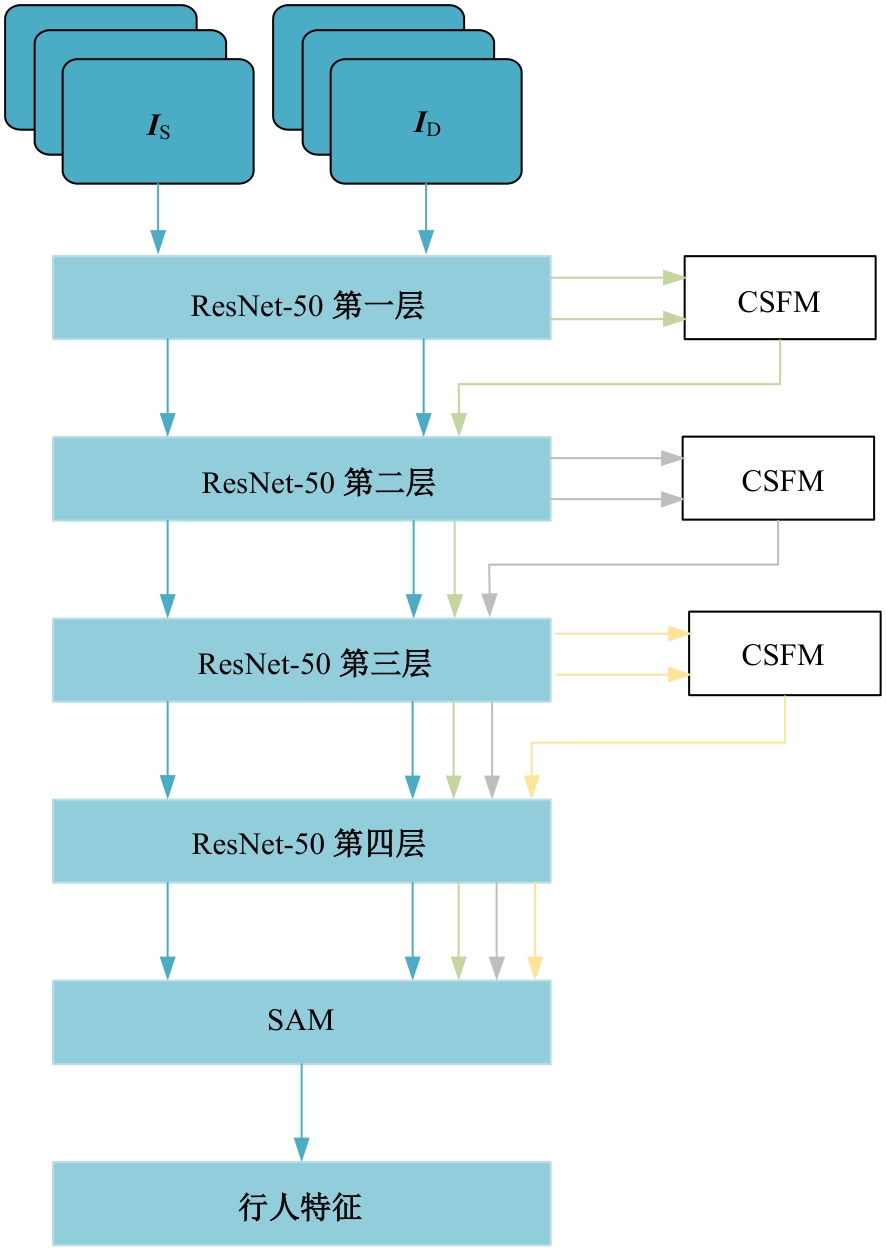
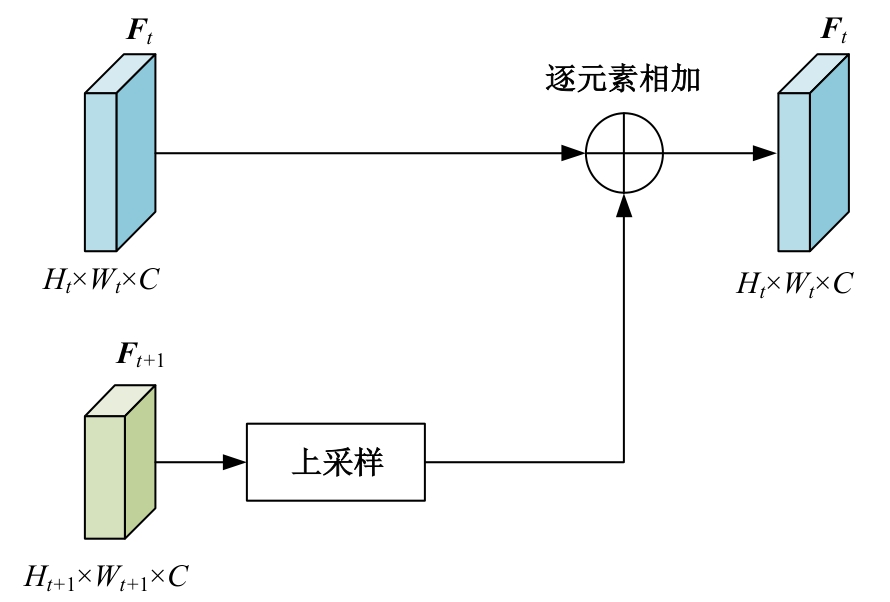
针对视频行人重识别通常存在行人姿势多变、特征融合损失和遮挡干扰等问题,本文提出了三维卷积与自注意力机制融合的网络模型。该模型首先通过三维卷积获取相邻帧之间的短期运动特征和局部细节特征;其次提出多分支结构的跨尺度融合模块,融合时间和语义维度的多阶段特征;最后利用自注意力机制模块捕获长时信息。本文所提网络在3个经典公开数据集上实验,并与其他方法进行对比,实验结果表明,该网络可有效利用视频长、短时信息,获得较优性能。
中图分类号:
- TP391.4
| [1] | 于鹏, 朴燕. 基于多尺度特征的行人重识别属性提取新方法[J]. 吉林大学学报: 工学版, 2023, 53(4): 1155-1162. |
| Yu Peng, Yan Piao. New method for extracting person re-identification attributes based on multi-scale features[J]. Journal of Jilin University (Engineering and Technology Edition), 2023, 53(4): 1155-1162. | |
| [2] | Isobe T, Han J, Zhuz F, et al. Intra-clip aggregation for video person re-identification[C]∥Proceeding of the IEEE International Conference on Image Processing (ICIP). Piscatanay, NJ: IEEE, 2020: 2336-2340. |
| [3] | Li X, Zhou W, Zhou Y, et al. Relation-guided spatialattention and temporal refinement for video-based person re-identification[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11434-11441. |
| [4] | Hou R, Chang H, Ma B, et al. Temporal complementary learning for video person re-identification[C]∥The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 388-405. |
| [5] | Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[C]∥Proceeding of the 53rd Annual Meeting of the Association for Computation Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 2015: 1556-1566. |
| [6] | Carreira J, Zisserman A. Quo vadis, action recogniti-on? A new model and the kinetics dataset[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii,USA,2017: 6299-6308. |
| [7] | Li J, Zhang S, Huang T. Multi-scale 3d convolution network for video based person re-identification[C]∥Proceedings of the AAAI Conference on Artificial Int-elligence, Hawaii,USA, 2019, 33(1): 8618-8625. |
| [8] | Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, Los Angeles,USA, 2017: 30-38. |
| [9] | 侯春萍, 杨庆元, 黄美艳, 等. 基于语义耦合和身份一致性的跨模态行人重识别方法[J]. 吉林大学学报:工学版, 2022, 52(12): 2954-2963. |
| Hou Chun-ping, Yang Qing-yuan, Huang Mei-yan, et al. Cross⁃modality person re⁃identification based on semantic coupling and identity⁃consistence constraint[J]. Journal of Jilin University (Engineering and Technology Edition), 2022, 52(12): 2954-2963. | |
| [10] | Zheng L, Bie Z, Sun Y, et al. Mars: a video benchmark for large-scale person re-identification[C]∥The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 868-884. |
| [11] | Wu Y, Lin Y, Dong X, et al. Exploit the unknown gradually: One-shot video-based person re-identification by stepwise learning[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 5177-5186. |
| [12] | Wang T, Gong S, Zhu X, et al. Person re-identification by video ranking[C]∥The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 688-703. |
| [13] | Zhong Z, Zheng L, Kang G, et al. Random erasing data augmentation[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, New York,USA, 2020, 34(7): 13001-13008. |
| [14] | Kingma D P, Ba J. Adam: a method for stochastic optimization[J/OL].[2014-03-22]. . |
| [15] | Chen Z, Zhou Z, Huang J, et al. Frame-guided regi-on-aligned representation for video person re-identification[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, New York,USA, 2020: 10591-10598. |
| [16] | Hou R, Ma B, Chang H, et al. Vrstc: occlusion-free video person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Angeles,USA, 2019: 7183-7192. |
| [17] | Yang J, Zheng W S, Yang Q, et al. Spatial-temporal graph convolutional network for video-based person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 3289-3299. |
| [18] | Zhang Z, Lan C, Zeng W, et al. Multi-granularity reference-aided attentive feature aggregation for video-based person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle,USA, 2020: 10407-10416. |
| [19] | Chen G, Rao Y, Lu J,et al.Temporal coherence or temporal motion:Which is more critical for video-based person re-identification?[C]∥The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 660-676. |
| [20] | Liu X, Zhang P, Yu C,et al.Watching you: global-guided reciprocal learning for video-based person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Shenzhen, China, 2021: 13334-13343. |
| [21] | Hou R, Chang H, Ma B, et al. Learning efficient spatial-temporal representation for video person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 21-24. |
| [22] | Jiang X, Qiao Y, Yan J,et al. SSN3D: self-separated network to align parts for 3D convolution in video person re-identification[C]∥Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2021, 35(2): 1691-1699. |
| [23] | Bai S, Ma B, Chang H, et al. Salient-to-broad transition for video person re-identification[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans,USA, 2022: 7339-7348. |
| [24] | Ning J, Li F, Liu R, et al. Temporal extension topology learning for video-based person reidentificat-ion[C]∥Proceedings of the Asian Conference on Co-mputer Vision, Macao, China, 2022: 207-219. |
| [25] | Pan H, Chen Y, He Z. Multi-granularity graph pooling for video-based person re-identification[J]. Neural Networks, 2023, 160: 22-33. |
| [26] | Yang F, Li W, Liang B, et al. Spatiotemporal interaction transformer network for video-based person re-identification in internet of things[J]. IEEE Internet of Things Journal, 2023,10(14):12537-12547. |
| [27] | Wang K, Ding C, Pang J, et al. Context sensing att-ention network for video-based person re-identification[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2023, 19(4): 1-20. |
| [1] | 车翔玖,李良. 融合全局与局部细粒度特征的图相似度度量算法[J]. 吉林大学学报(工学版), 2025, 55(7): 2365-2371. |
| [2] | 李文辉,杨晨. 基于对比学习文本感知的小样本遥感图像分类[J]. 吉林大学学报(工学版), 2025, 55(7): 2393-2401. |
| [3] | 赵宏伟,周伟民. 基于数据增强的半监督单目深度估计框架[J]. 吉林大学学报(工学版), 2025, 55(6): 2082-2088. |
| [4] | 陈海鹏,张世博,吕颖达. 多尺度感知与边界引导的图像篡改检测方法[J]. 吉林大学学报(工学版), 2025, 55(6): 2114-2121. |
| [5] | 周丰丰,郭喆,范雨思. 面向不平衡多组学癌症数据的特征表征算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2089-2096. |
| [6] | 王健,贾晨威. 面向智能网联车辆的轨迹预测模型[J]. 吉林大学学报(工学版), 2025, 55(6): 1963-1972. |
| [7] | 车翔玖,孙雨鹏. 基于相似度随机游走聚合的图节点分类算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2069-2075. |
| [8] | 刘萍萍,商文理,解小宇,杨晓康. 基于细粒度分析的不均衡图像分类算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2122-2130. |
| [9] | 侯越,郭劲松,林伟,张迪,武月,张鑫. 分割可跨越车道分界线的多视角视频车速提取方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1692-1704. |
| [10] | 赵宏伟,周明珠,刘萍萍,周求湛. 基于置信学习和协同训练的医学图像分割方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1675-1681. |
| [11] | 申自浩,高永生,王辉,刘沛骞,刘琨. 面向车联网隐私保护的深度确定性策略梯度缓存方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1638-1647. |
| [12] | 王友卫,刘奥,凤丽洲. 基于知识蒸馏和评论时间的文本情感分类新方法[J]. 吉林大学学报(工学版), 2025, 55(5): 1664-1674. |
| [13] | 王军,司昌馥,王凯鹏,付强. 融合集成学习技术和PSO-GA算法的特征提取技术的入侵检测方法[J]. 吉林大学学报(工学版), 2025, 55(4): 1396-1405. |
| [14] | 徐涛,孔帅迪,刘才华,李时. 异构机密计算综述[J]. 吉林大学学报(工学版), 2025, 55(3): 755-770. |
| [15] | 赵孟雪,车翔玖,徐欢,刘全乐. 基于先验知识优化的医学图像候选区域生成方法[J]. 吉林大学学报(工学版), 2025, 55(2): 722-730. |
|
||