吉林大学学报(工学版) ›› 2025, Vol. 55 ›› Issue (8): 2732-2740.doi: 10.13229/j.cnki.jdxbgxb.20240051
• 计算机科学与技术 • 上一篇
基于文本引导的人脸图像修复
廉敬1( ),张继保1,刘冀钊2,张家骏1,董子龙1
),张继保1,刘冀钊2,张家骏1,董子龙1
- 1.兰州交通大学 电子与信息工程学院,兰州 730030
2.兰州大学 信息科学与工程学院,兰州 730030
Text-based guided face image inpainting
Jing LIAN1(),Ji-bao ZHANG1,Ji-zhao LIU2,Jia-jun ZHANG1,Zi-long DONG1
- 1.School of Electronic and Information Engineering,Lanzhou Jiaotong University,Lanzhou 730030,China
2.School of Information Science and Engineering,Lanzhou University,Lanzhou 730030,China
摘要:
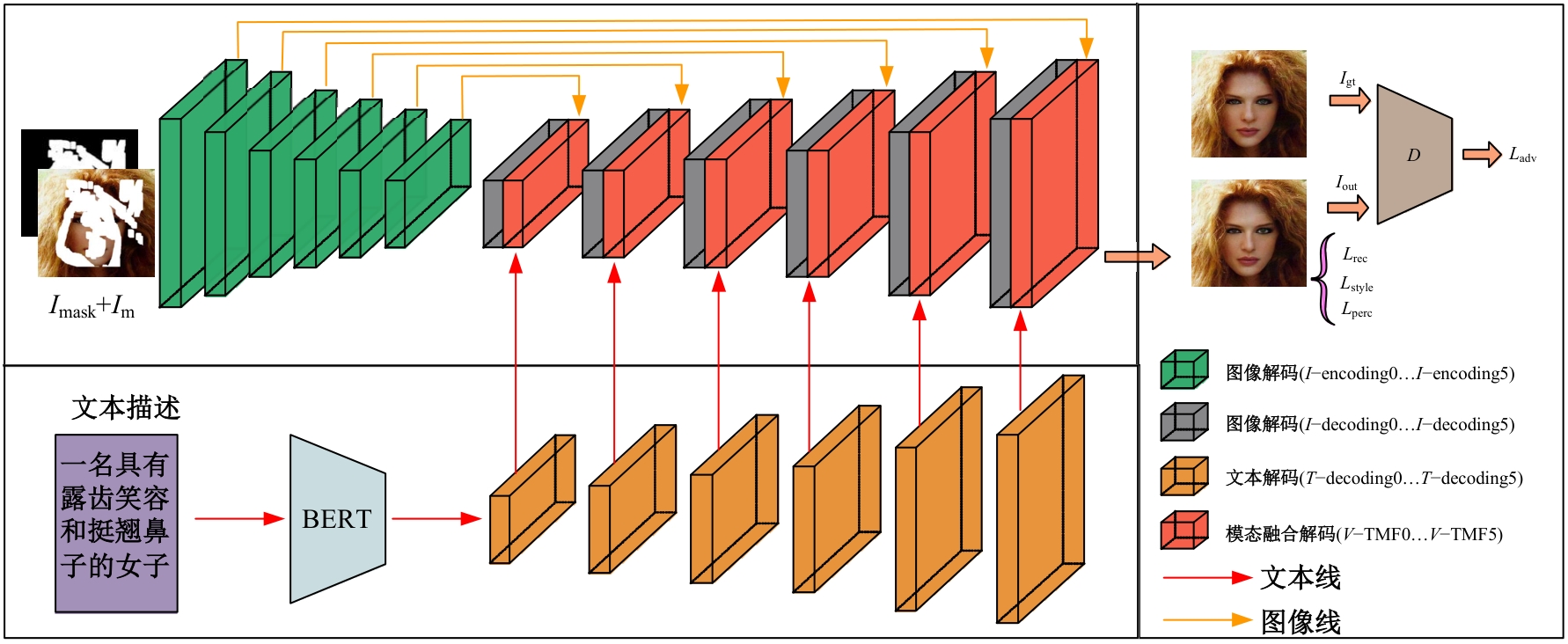
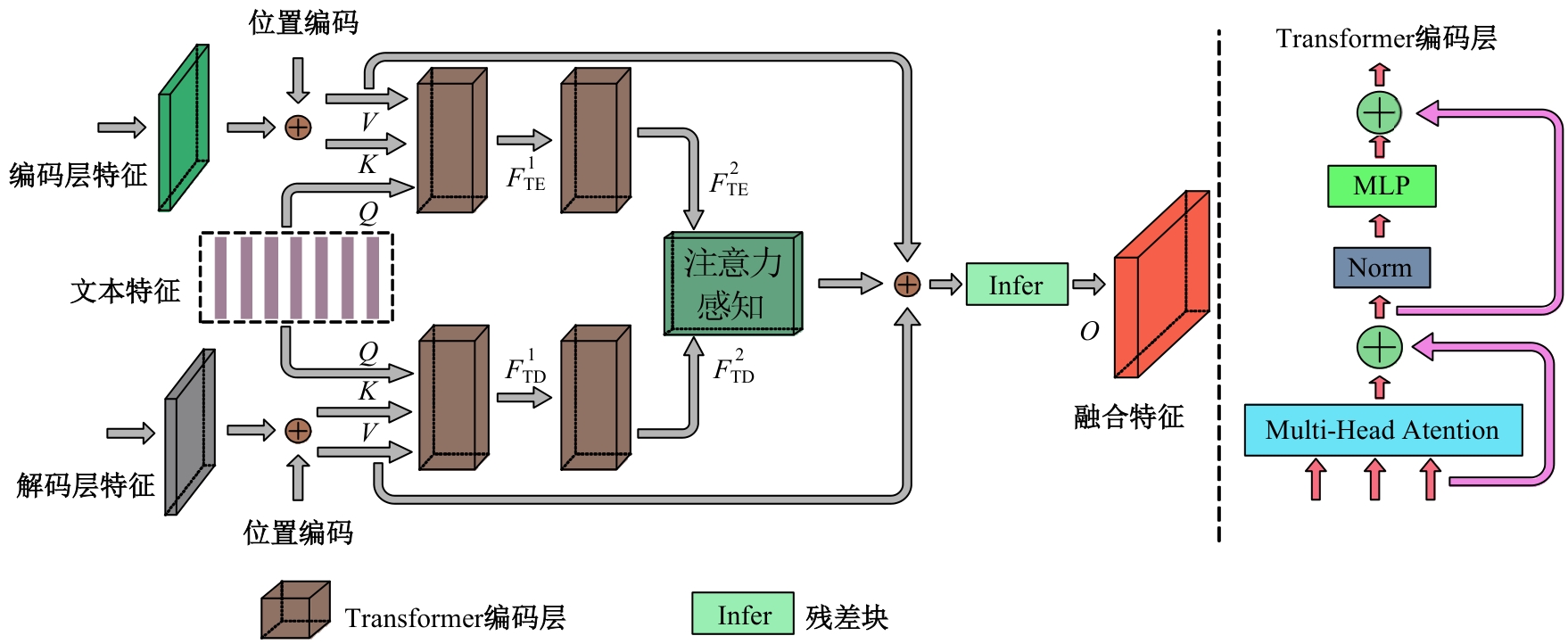
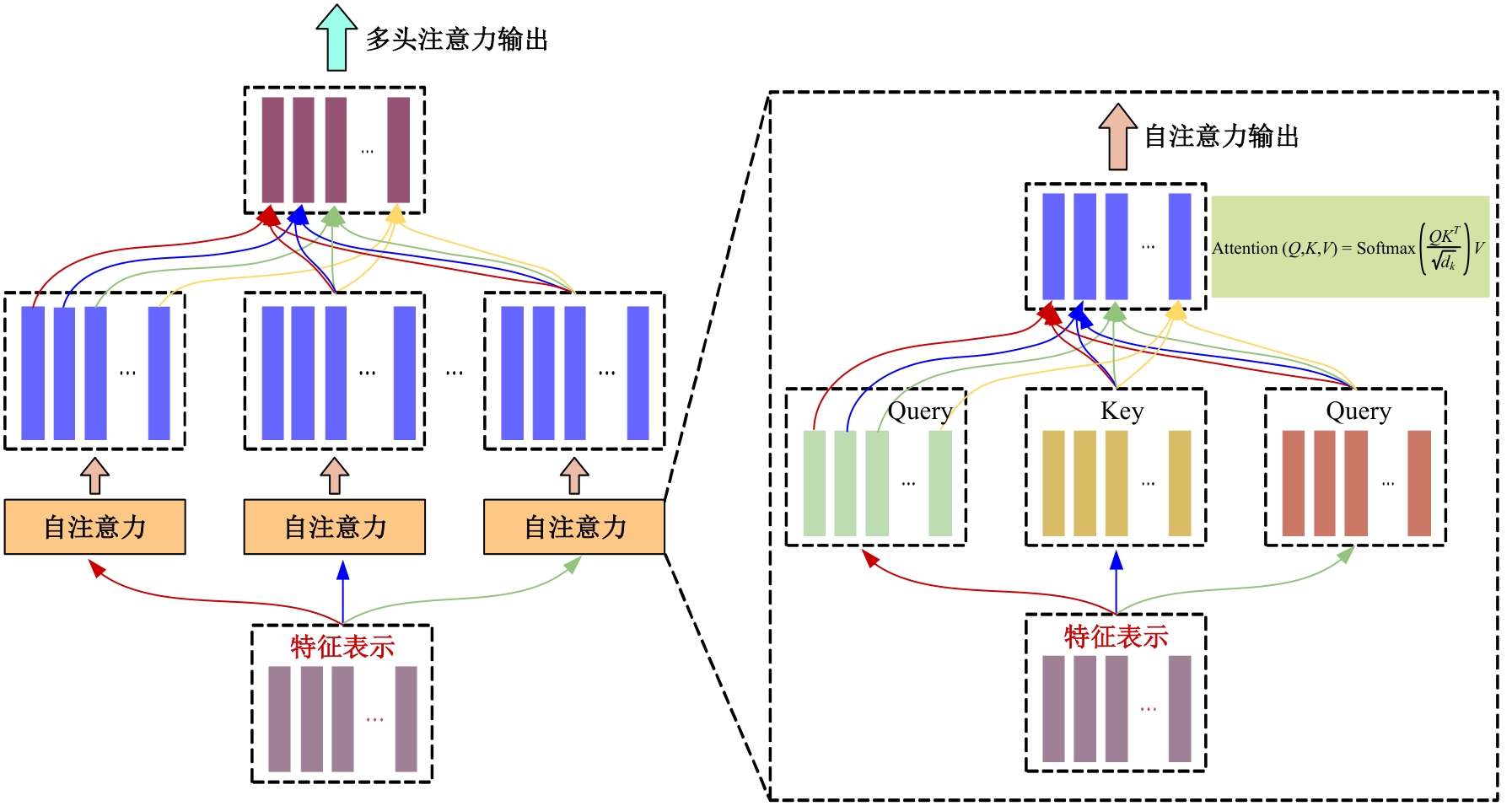
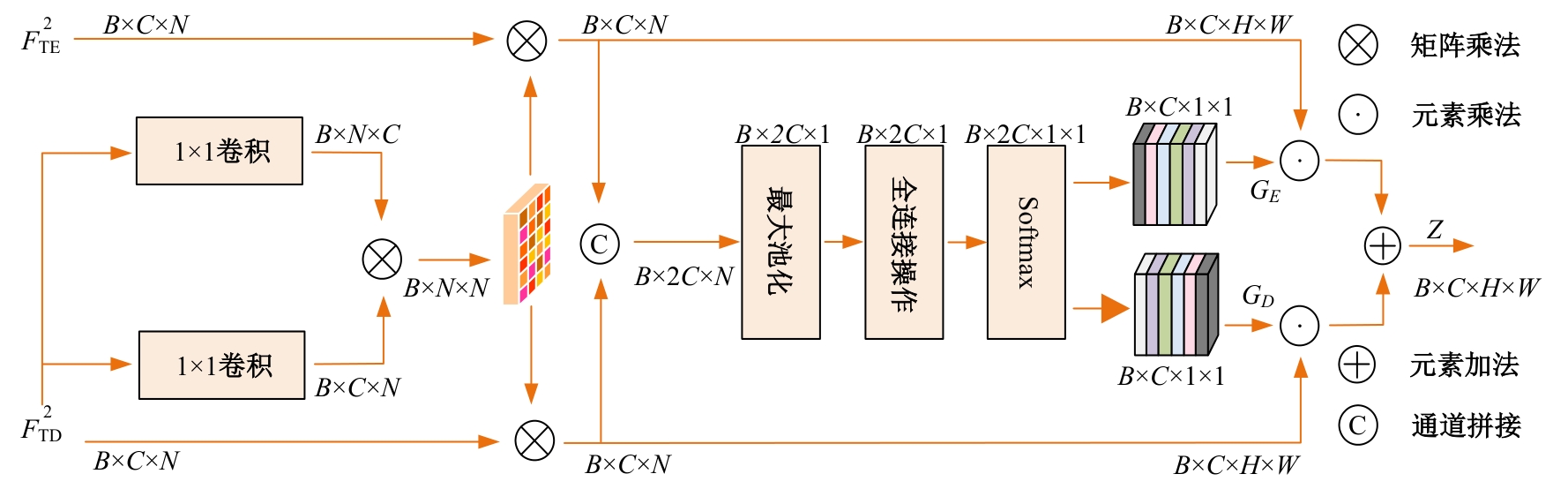
针对目前人脸修复方法存在结构扭曲、纹理模糊以及不可控等问题,提出了一种文本引导的人脸图像修复方法。该方法通过融合图像特征和相应的文本特征来重建图像中的缺失区域。在网络训练中,设计了视觉-文本模态融合模块,用于关联图像和文本特征,使重建人脸缺失区域不仅以图像中可见的视觉语义为基础,还以具有丰富的文本语义为指导。在编码和解码特征之间添加了一个注意力感知层,以提高可见区域和生成区域外观的一致性。在CelebA-HQ人脸数据集上的实验结果表明:本文方法能够得到在纹理和结构上更自然且符合文本语义的修复结果,其视觉效果和评价指标均优于对比算法。
中图分类号:
- TP391




| [1] | 周大可, 张超, 杨欣. 基于多尺度特征融合及双重注意力机制的自监督三维人脸重建[J]. 吉林大学学报: 工学版, 2022, 52(10): 2428-2437. |
| Zhou Da-ke, Zhang Chao, Yang Xin.Self-supervised 3D face reconstruction based on multi-scale feature fusion and dual attention mechanism[J]. Journal of Jilin University (Engineering and Technology Edition), 2022, 52(10): 2428-2437. | |
| [2] | 王小玉, 胡鑫豪, 韩昌林. 基于生成对抗网络的人脸铅笔画算法[J].吉林大学学报: 工学版, 2021, 51(1): 285-292. |
| Wang Xiao-yu, Hu Xin-hao, Han Chang-lin. Face pencil drawing algorithms based on generative adversarial network[J]. Journal of Jilin University (Engineering and Technology Edition), 2021, 51(1): 285-292. | |
| [3] | Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders: feature learning by inpainting[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2536-2544. |
| [4] | Iizuka S, Simo S E, Ishikawa H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics (ToG), 2017, 36(4): 1-14. |
| [5] | Yan Z, Li X, Li M, et al. Shift-net: image inpainting via deep feature rearrangement[C]∥Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2018: 1-17. |
| [6] | Liu H, Wan Z, Huang W, et al. Pd-gan: probabilistic diverse gan for image inpainting[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 9371-9381. |
| [7] | Wan Z, Zhang J, Chen D, et al. High-fidelity pluralistic image completion with transformers[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, USA, 2021: 4692-4701. |
| [8] | Li W, Lin Z, Zhou K, et al. Mat: mask-aware transformer for large hole image inpainting[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10758-10768. |
| [9] | Huang W, Deng Y, Hui S, et al. Sparse self-attention transformer for image inpainting[J]. Pattern Recognition, 2024, 145: 109897. |
| [10] | Lian J, Zhang J, Liu J, et al. Guiding image inpainting via structure and texture features with dual encoder[J]. The Visual Computer, 2024, 40: 4303-4317. |
| [11] | Devlin J, Chang M W, Lee K, et al. Bert: pre-training of deep bidirectional transformers for language understanding[J/OL]. [2023-12-16]. arXiv preprint arXiv:. |
| [12] | Johnson J, Alahi A, Fei F L. Perceptual losses for real-time style transfer and super-resolution[C]∥14th European Conference, Amsterdam, The Netherlands, 2016: 694-711. |
| [13] | Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115: 211-252. |
| [14] | Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J/OL].[2023-12-17]. arXiv preprint arXiv:. |
| [15] | Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2794-2802. |
| [16] | Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2414-2423. |
| [17] | Liu G, Reda F A, Shih K J, et al. Image inpainting for irregular holes using partial convolutions[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 85-100. |
| [18] | Li J, Wang N, Zhang L, et al. Recurrent feature reasoning for image inpainting[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 7760-7768. |
| [19] | Lugmayr A, Danelljan M, Romero A, et al. Repaint: inpainting using denoising diffusion probabilistic models[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 11461-11471. |
| [20] | Chen L, Yuan C, Qin X, et al. Contrastive structure and texture fusion for image inpainting[J]. Neurocomputing, 2023, 536: 1-12. |
| [21] | Li A, Zhao L, Zuo Z, et al. MIGT: multi-modal image inpainting guided with text[J]. Neurocomputing, 2023, 520: 376-385. |
| [22] | Zhang L, Chen Q, Hu B, et al. Text-guided neural image inpainting[C]∥Proceedings of the 28th ACM International Conference on Multimedia, New York, USA, 2020: 1302-1310. |
| [1] | 刘元宁,王星喆,黄子彧,张家晨,刘震. 基于多模态数据融合的胃癌患者生存预测模型[J]. 吉林大学学报(工学版), 2025, 55(8): 2693-2702. |
| [2] | 袁靖舒,李武,赵兴雨,袁满. 基于BERTGAT-Contrastive的语义匹配模型[J]. 吉林大学学报(工学版), 2025, 55(7): 2383-2392. |
| [3] | 徐慧智,郝东升,徐小婷,蒋时森. 基于深度学习的高速公路小目标检测算法[J]. 吉林大学学报(工学版), 2025, 55(6): 2003-2014. |
| [4] | 张汝波,常世淇,张天一. 基于深度学习的图像信息隐藏方法综述[J]. 吉林大学学报(工学版), 2025, 55(5): 1497-1515. |
| [5] | 李健,刘欢,李艳秋,王海瑞,关路,廖昌义. 基于THGS算法优化ResNet-18模型的图像识别[J]. 吉林大学学报(工学版), 2025, 55(5): 1629-1637. |
| [6] | 文斌,丁弈夫,杨超,沈艳军,李辉. 基于自选择架构网络的交通标志分类算法[J]. 吉林大学学报(工学版), 2025, 55(5): 1705-1713. |
| [7] | 李振江,万利,周世睿,陶楚青,魏巍. 基于时空Transformer网络的隧道交通运行风险动态辨识方法[J]. 吉林大学学报(工学版), 2025, 55(4): 1336-1345. |
| [8] | 赵孟雪,车翔玖,徐欢,刘全乐. 基于先验知识优化的医学图像候选区域生成方法[J]. 吉林大学学报(工学版), 2025, 55(2): 722-730. |
| [9] | 徐慧智,蒋时森,王秀青,陈爽. 基于深度学习的车载图像车辆目标检测和测距[J]. 吉林大学学报(工学版), 2025, 55(1): 185-197. |
| [10] | 刘元宁,臧子楠,张浩,刘震. 基于深度学习的核糖核酸二级结构预测方法[J]. 吉林大学学报(工学版), 2025, 55(1): 297-306. |
| [11] | 张磊,焦晶,李勃昕,周延杰. 融合机器学习和深度学习的大容量半结构化数据抽取算法[J]. 吉林大学学报(工学版), 2024, 54(9): 2631-2637. |
| [12] | 李路,宋均琦,朱明,谭鹤群,周玉凡,孙超奇,周铖钰. 基于RGHS图像增强和改进YOLOv5网络的黄颡鱼目标提取[J]. 吉林大学学报(工学版), 2024, 54(9): 2638-2645. |
| [13] | 郭昕刚,何颖晨,程超. 抗噪声的分步式图像超分辨率重构算法[J]. 吉林大学学报(工学版), 2024, 54(7): 2063-2071. |
| [14] | 乔百友,武彤,杨璐,蒋有文. 一种基于BiGRU和胶囊网络的文本情感分析方法[J]. 吉林大学学报(工学版), 2024, 54(7): 2026-2037. |
| [15] | 张丽平,刘斌毓,李松,郝忠孝. 基于稀疏多头自注意力的轨迹kNN查询方法[J]. 吉林大学学报(工学版), 2024, 54(6): 1756-1766. |
|
||