Journal of Jilin University(Engineering and Technology Edition) ›› 2024, Vol. 54 ›› Issue (3): 797-806.doi: 10.13229/j.cnki.jdxbgxb.20220523
LSTM⁃MADDPG multi⁃agent cooperative decision algorithm based on asynchronous collaborative update
Jing-peng GAO1( ),Guo-xuan WANG1,Lu GAO2
),Guo-xuan WANG1,Lu GAO2
- 1.College of Information and Communication Engineering,Harbin Engineering University,Harbin 150001,China
2.National Key Laboratory of Science and Technology on Test Physics and Numerical Mathematics,Beijing Institute of Space Long March Vehicle,Beijing 100076,China
CLC Number:
- TP18
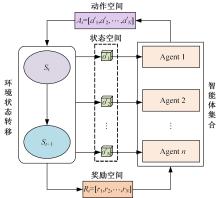
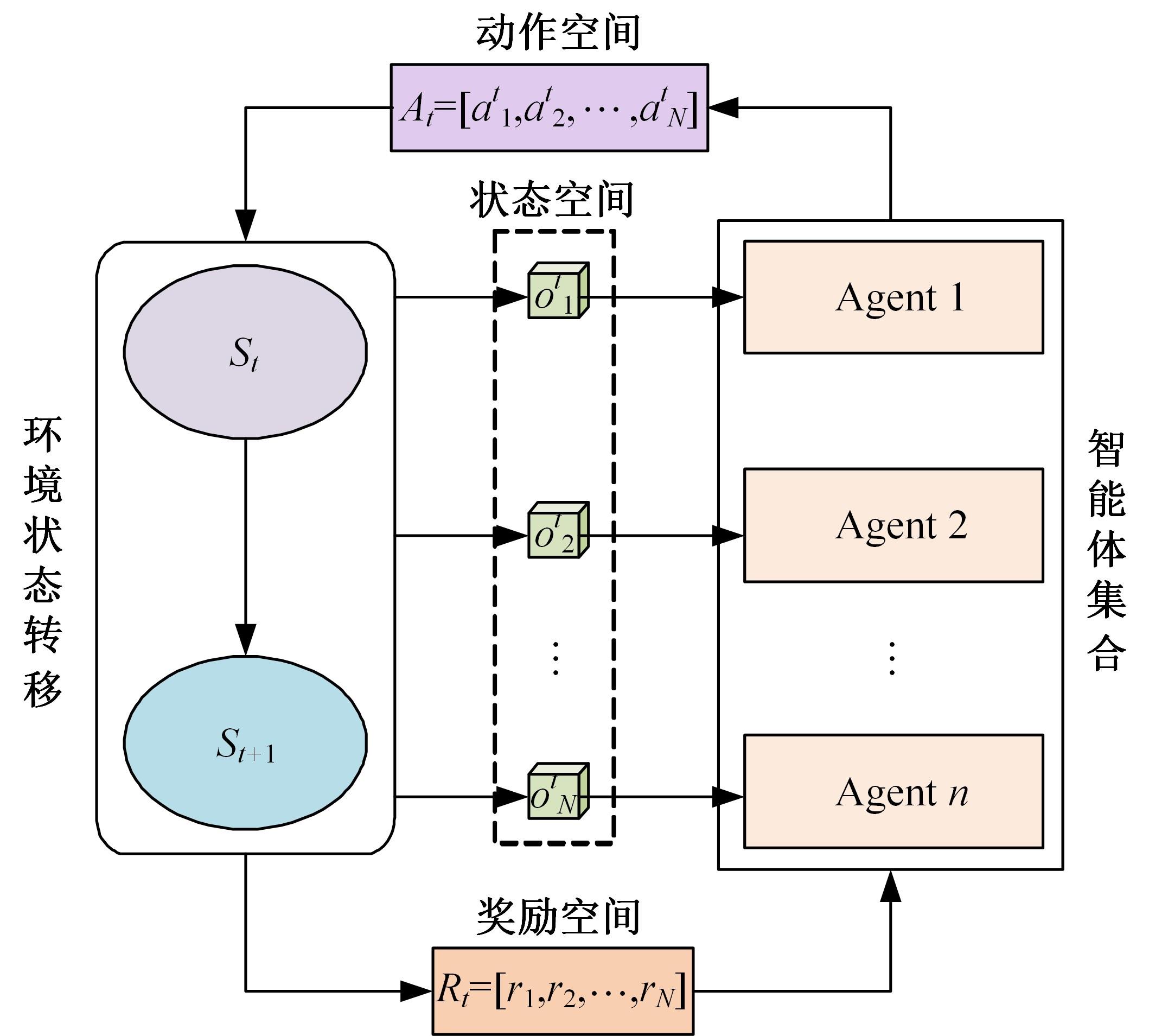

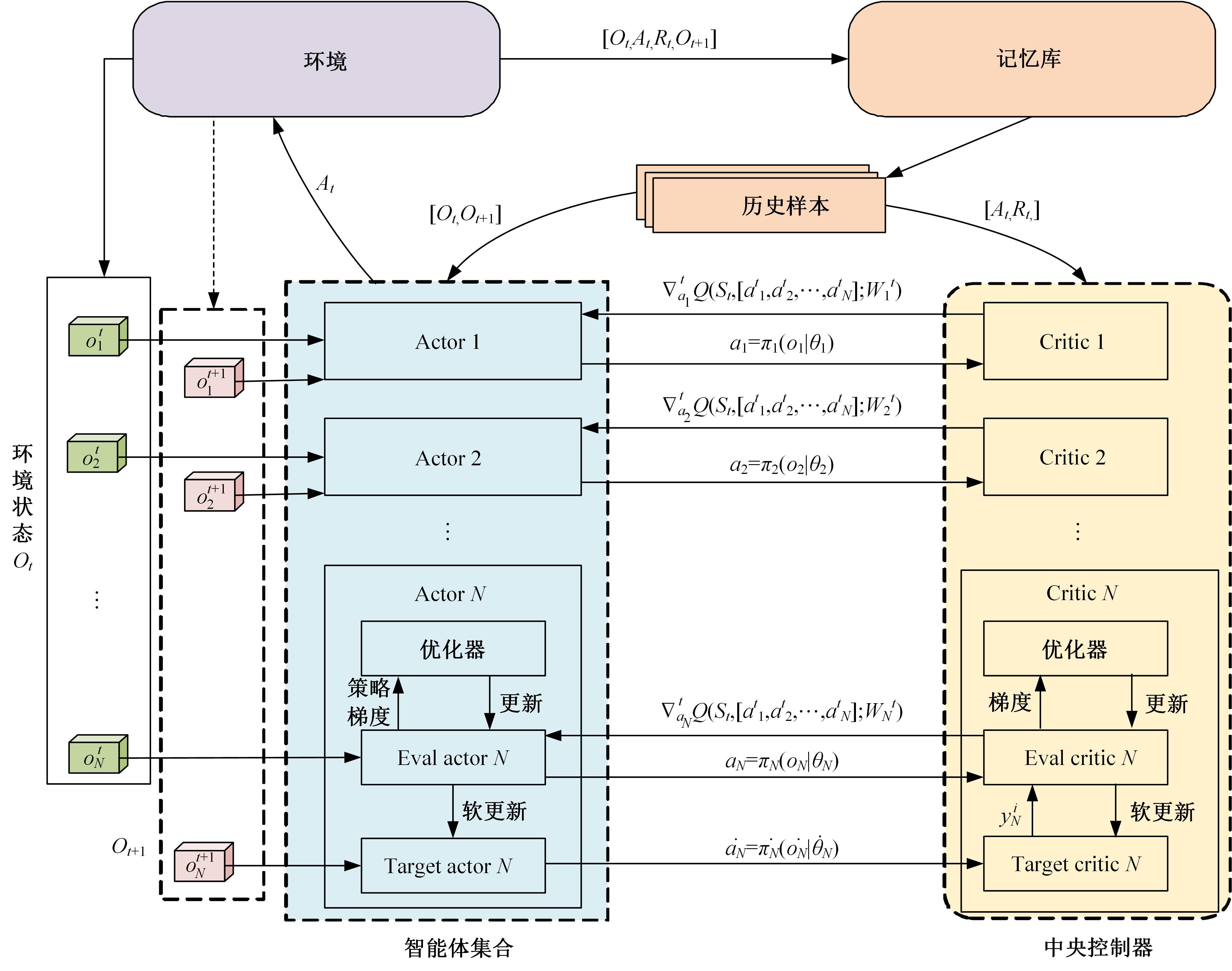
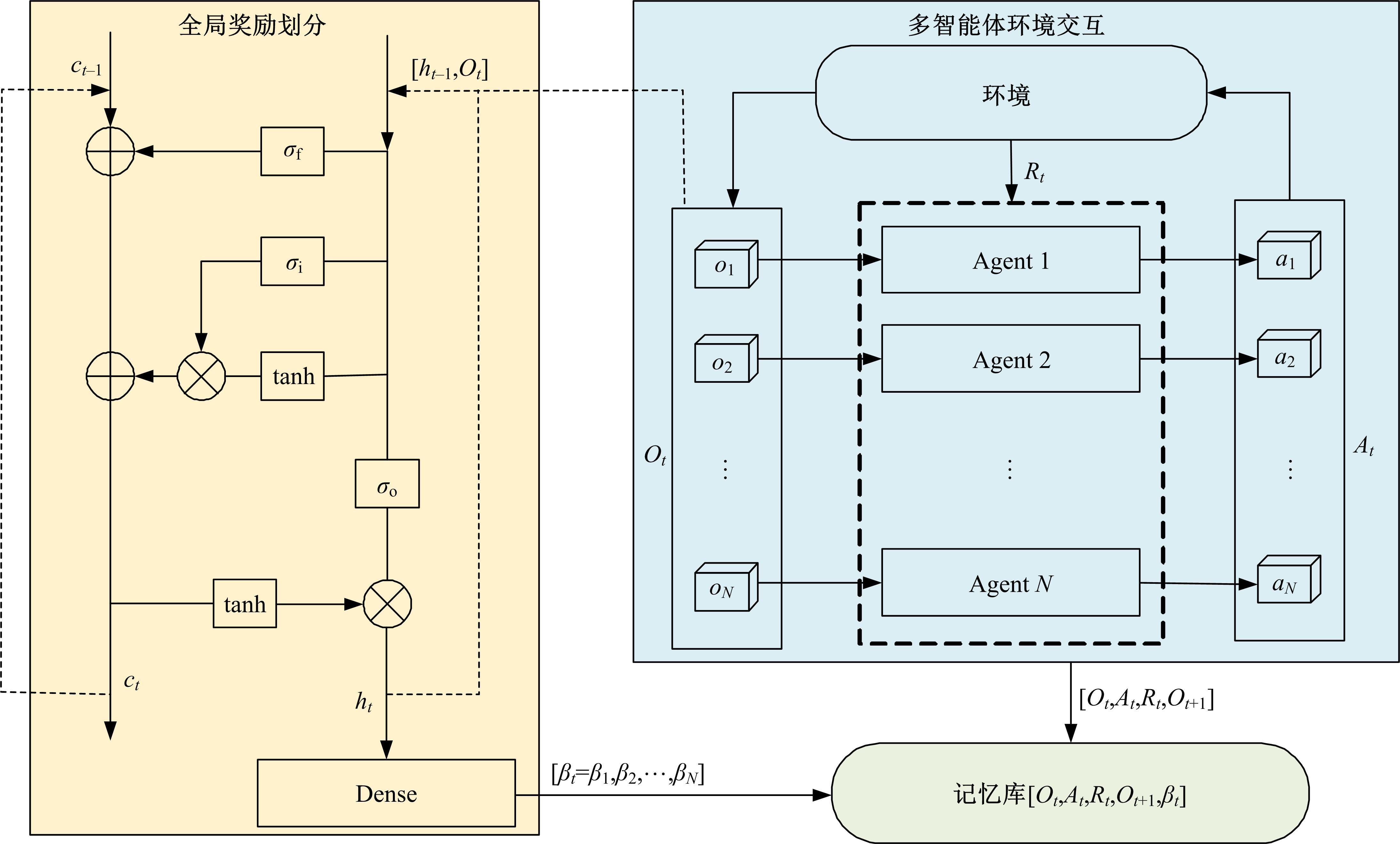
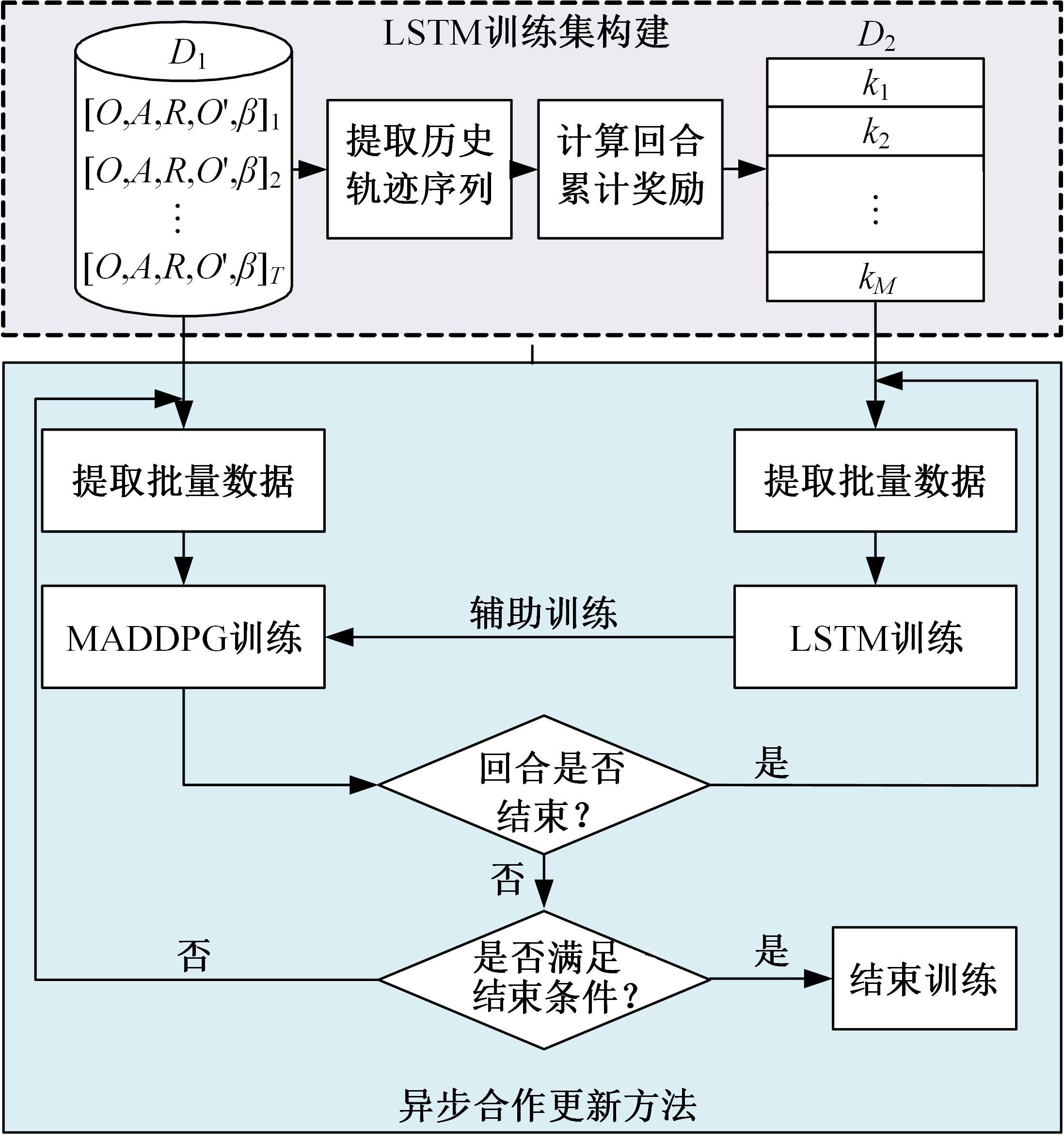
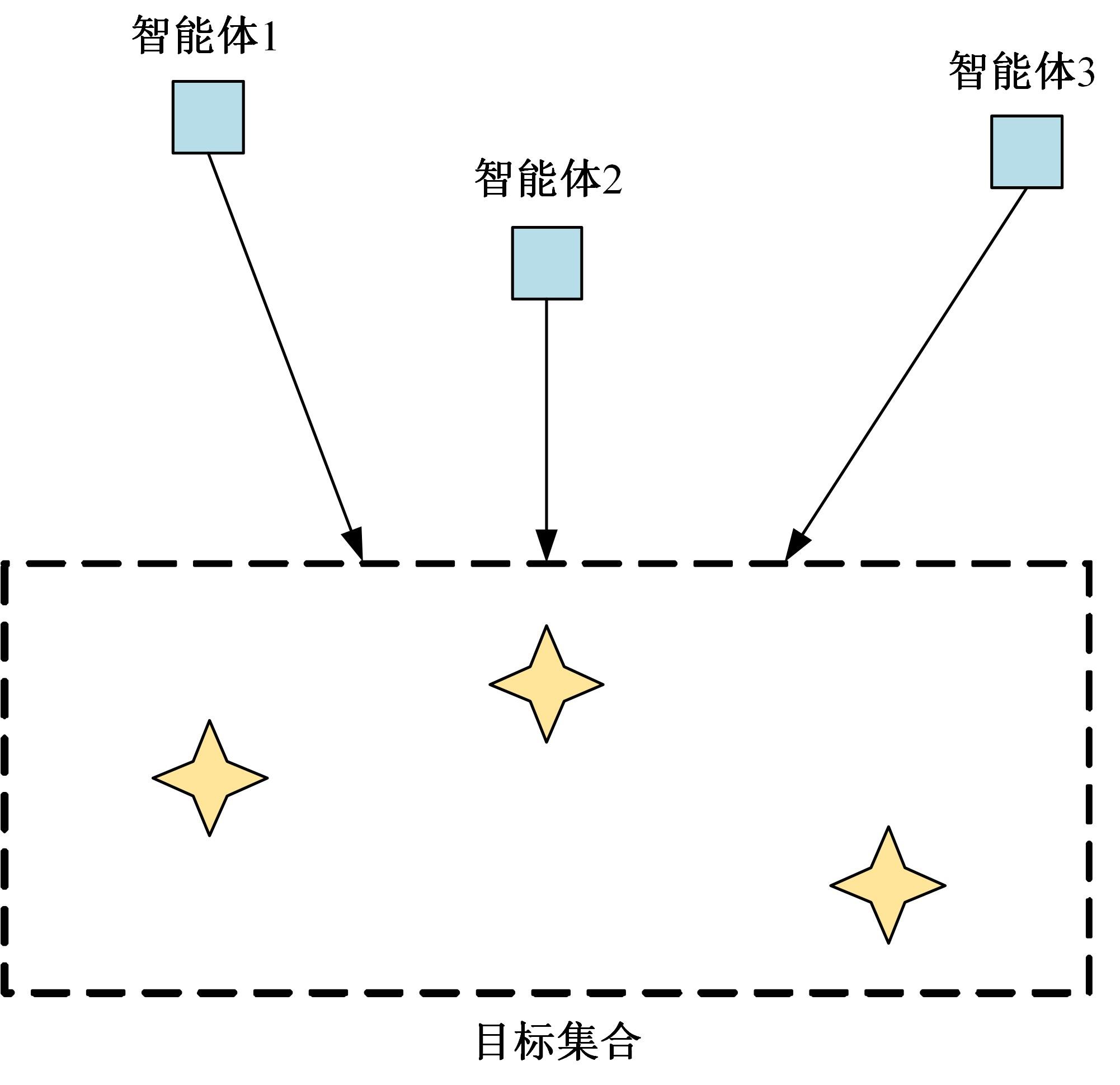
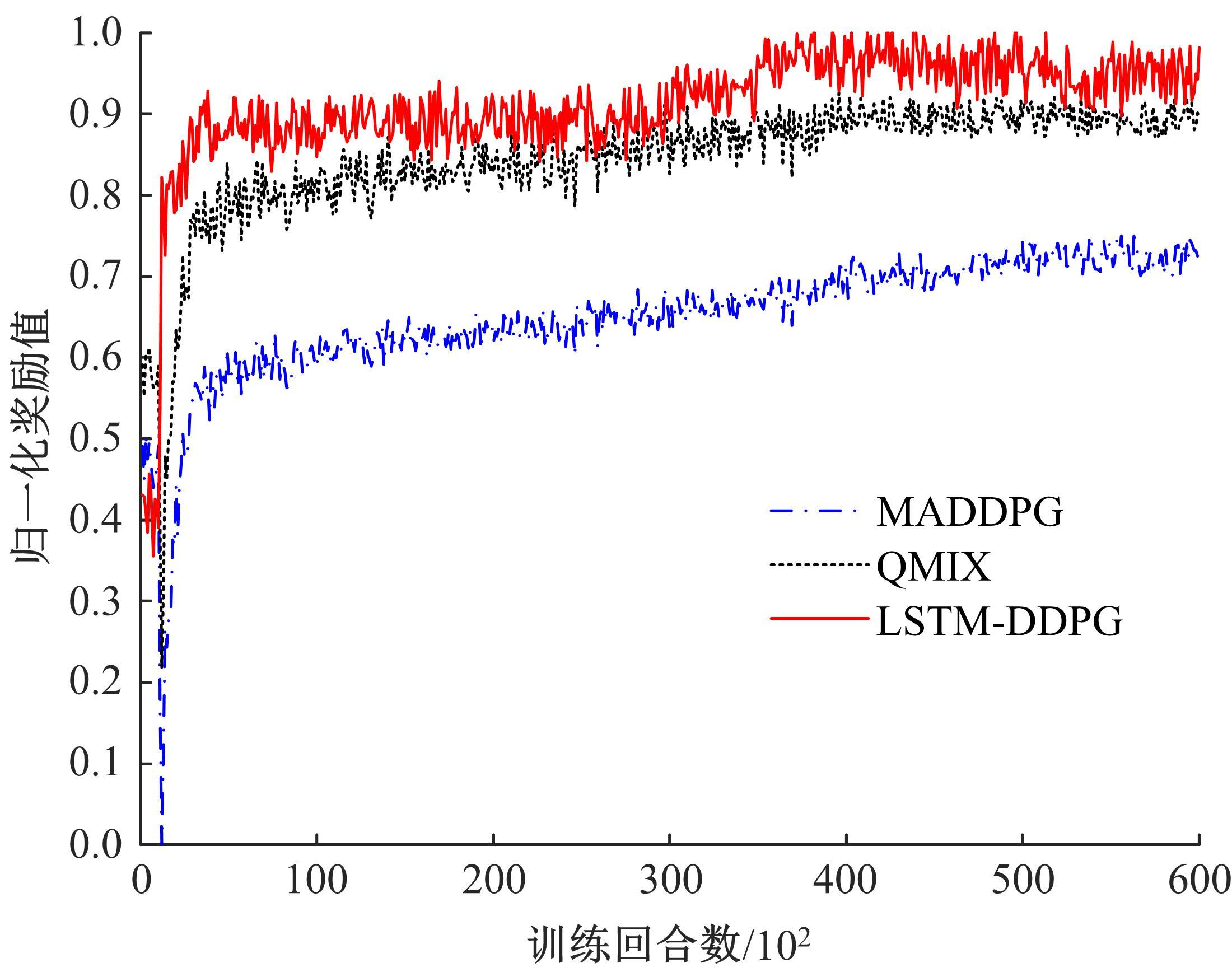
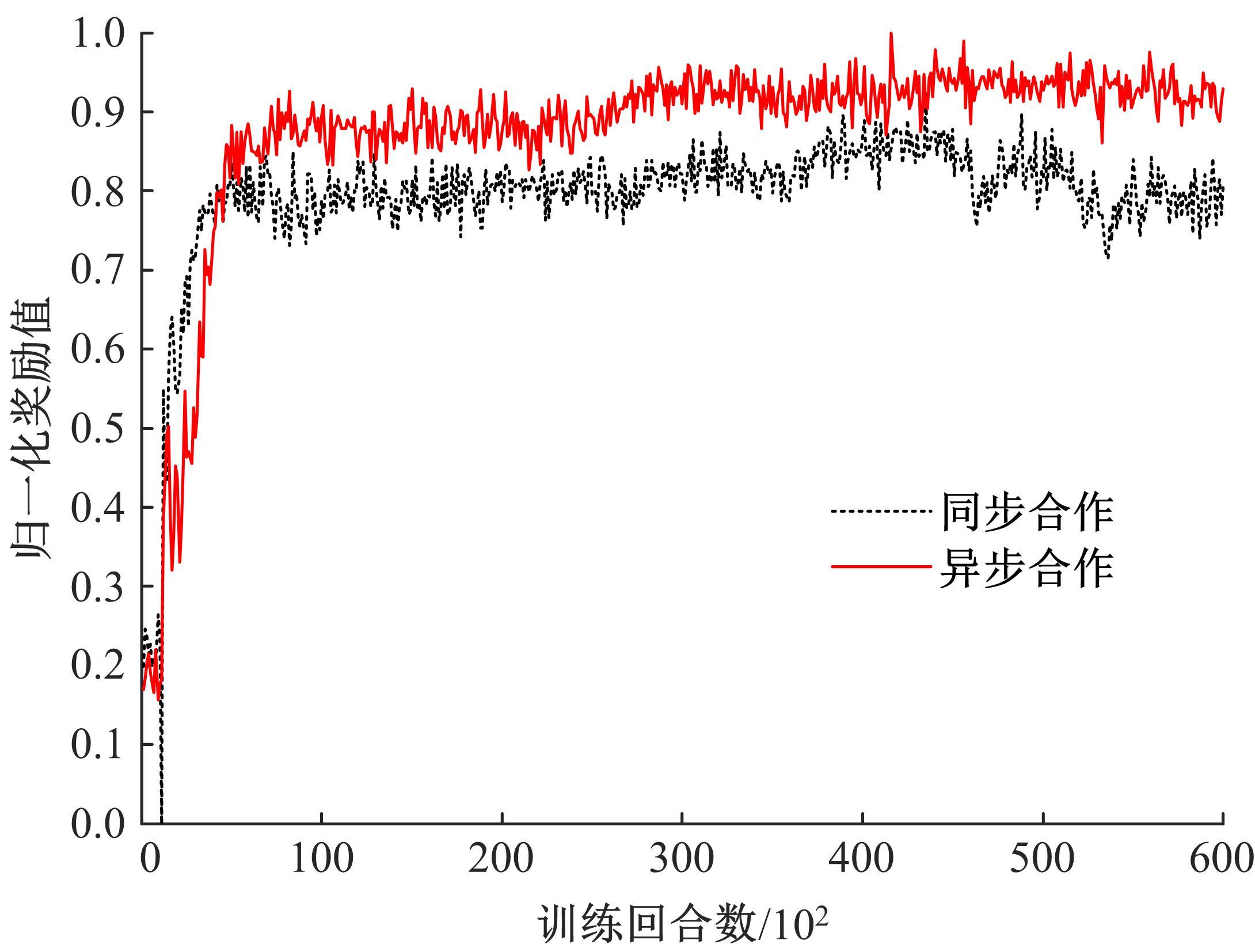
| 1 | Feng J, Li H, Huang M, et al. Learning to collaborate: multi-scenario ranking via multi-agent reinforcement learning[C]∥Proceedings of the 2018 World Wide Web Conference, Lyon, France, 2018: 1939-1948. |
| 2 | 杨顺, 蒋渊德, 吴坚, 等. 基于多类型传感数据的自动驾驶深度强化学习方法[J]. 吉林大学学报: 工学版, 2019, 49(4): 1026-1033. |
| Yang Shun, Jiang Yuan-de, Wu Jian, et al. Autonomous driving policy learning based on deep reinforcement learning and multi-type sensor data[J]. Journal of Jilin University (Engineering and Technology Edition), 2019, 49(4): 1026-1033. | |
| 3 | Hernandez-Leal P, Kartal B, Taylor M E. A survey and critique of multi-agent deep reinforcement learning[J]. Auto Agent Multi-Agent Systems, 2019, 33(6): 750-797. |
| 4 | Lowe R, Wu Y, Tamar Aviv, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]∥Proceedings of the 31th International Conference on Neural Information Processing Systems, New York, USA, 2017: 6382-6393. |
| 5 | Nguyen T T, Nguyen N D, Nahavandi S. Deep reinforcement learning for multi-agent systems: a review of challenges, solutions, and applications[J]. IEEE Transactions on Cybernetics, 2020, 50(9): 3826-3839. |
| 6 | Holmesparker C, Taylor M E, Agogino A, et al. Cleaning the reward: counterfactual actions to remove exploratory action noise in multi-agent learning[C]∥Proceedings of the 2014 International Conference on Autonomous Agents and Multi-agent Systems, Paris, France, 2014: 1353-1354. |
| 7 | Chang Y H, Ho T, Kaelbling L P. All learning is local: multi-agent learning in global reward games[C]∥Proceedings of the 17th Advances in Neural Information Processing Systems, Cambridge, USA,2004: 807-814. |
| 8 | Devlin S, Yliniemi L, Kudenko D, et al. Potential based difference rewards for multi-agent reinforcement learning[C]∥Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 2014: 165-172. |
| 9 | Foerster J N, Farquhar G, Afouras T, et al. Counterfactual multi-agent policy gradients[C]∥Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018: 2974-2982. |
| 10 | Chen J, Guo L, Jia J, et al. Resource allocation for IRS assisted SGF NOMA transmission: a MADRL approach[J]. IEEE Journal on Selected Areas in Communications, 2022, 40(4): 1302-1316. |
| 11 | Sunehag P, Lever G, Gruslys A, et al. Value decomposition networks for cooperative multi-agent learning based on team reward[C]∥Proceedings of the 17th International Conference on Autonomous Agents and Multi-agent Systems, Stockholm, Sweden, 2018: 2085-2087. |
| 12 | Rashid T, Samvelyan M, Schroeder C, et al. QMIX: monotonic value function factorization for deep multi-agent reinforcement learning[C]∥Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 2018: 4295-4304. |
| 13 | Son K, Kim D, Kang W J, et al. QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning[C]∥Proceedings of the 36th International Conference on Machine Learning, Long Beach, USA, 2019: 5887-5896. |
| 14 | 施伟, 冯旸赫, 程光权, 等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021, 47(7): 1610-1623. |
| Shi Wei, Feng Yang-he, Cheng Guang-quan, et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning[J]. Acta Automation Sinica, 2021, 47(7): 1610-1623. | |
| 15 | Wan K, Wu D, Li B, et al. ME-MADDPG: an efficient learning based motion planning method for multiple agents in complex environments[J]. International Journal of Intelligent Systems, 2022, 37(3): 2393-2427. |
| 16 | 王乃钰, 叶育鑫, 刘露, 等. 基于深度学习的语言模型研究进展[J]. 软件学报, 2021, 32(4): 1082-1115. |
| Wang Nai-yu, Ye Yu-xin, Liu Lu, et al. Language models based on deep learning: a review[J]. Journal of Software, 2021, 32(4): 1082-1115. | |
| 17 | Pan Z Y, Zhang Z Z, Chen Z X. Asynchronous value iteration network[C]∥Proceedings of the 25th International Conference on Neural Information Processing, Red Hook, USA, 2018: 169-180. |
| [1] | Liu LIU,Kun DING,Shan-shan LIU,Ming LIU. Event detection method as machine reading comprehension [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(2): 533-539. |
| [2] | Jian ZHANG,Qing-yang LI,Dan LI,Xia JIANG,Yan-hong LEI,Ya-ping JI. Merging guidance of exclusive lanes for connected and autonomous vehicles based on deep reinforcement learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(9): 2508-2518. |
| [3] | Jian LI,Qi XIONG,Ya-ting HU,Kong-yu LIU. Chinese named entity recognition method based on Transformer and hidden Markov model [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(5): 1427-1434. |
| [4] | Yan-tao TIAN,Yan-shi JI,Huan CHANG,Bo XIE. Deep reinforcement learning augmented decision⁃making model for intelligent driving vehicles [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(3): 682-692. |
| [5] | Chun-hui LIU,Si-chang WANG,Ce ZHENG,Xiu-lian CHEN,Chun-lei HAO. Obstacle avoidance planning algorithm for indoor navigation robot based on deep learning [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(12): 3558-3564. |
| [6] | Wei-chao ZHUANG,Hao-nan Ding,Hao-xuan DONG,Guo-dong YIN,Xi WANG,Chao-bin ZHOU,Li-wei XU. Learning based eco⁃driving strategy of connected electric vehicle at signalized intersection [J]. Journal of Jilin University(Engineering and Technology Edition), 2023, 53(1): 82-93. |
| [7] | Tian BAI,Ming-wei XU,Si-ming LIU,Ji-an ZHANG,Zhe WANG. Dispute focus identification of pleading text based on deep neural network [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(8): 1872-1880. |
| [8] | Sheng-sheng WANG,Lin-yan JIANG,Yong-bo YANG. Transfer learning of medical image segmentation based on optimal transport feature selection [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(7): 1626-1638. |
| [9] | Hao-yu TIAN,Xin MA,Yi-bin LI. Skeleton-based abnormal gait recognition: a survey [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(4): 725-737. |
| [10] | Yong LIU,Lei XU,Chu-han ZHANG. Deep reinforcement learning model for text games [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(3): 666-674. |
| [11] | Zhong-li WANG,Hao WANG,Yan SHEN,Bai-gen CAI. A driving decision⁃making approach based on multi⁃sensing and multi⁃constraints reward function [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(11): 2718-2727. |
| [12] | Jing-pei LEI,Dan-tong OUYANG,Li-ming ZHANG. Relation domain and range completion method based on knowledge graph embedding [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(1): 154-161. |
| [13] | Zhi-hua LI,Ye-chao ZHANG,Guo-hua ZHAN. Realtime mosaic and visualization of 3D underwater acoustic seabed topography [J]. Journal of Jilin University(Engineering and Technology Edition), 2022, 52(1): 180-186. |
| [14] | Yan-lei XU,Run HE,Yu-ting ZHAI,Bin ZHAO,Chen-xiao LI. Weed identification method based on deep transfer learning in field natural environment [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(6): 2304-2312. |
| [15] | Yong YANG,Qiang CHEN,Fu-heng QU,Jun-jie LIU,Lei ZHANG. SP⁃k⁃means-+ algorithm based on simulated partition [J]. Journal of Jilin University(Engineering and Technology Edition), 2021, 51(5): 1808-1816. |
|
||